1 概述
| 测试类型 |
本质 |
数据类型 |
| 接口测试 |
数据流动和验证 |
csv
yaml
json |
| UI测试 |
用户操作的指令 |
excel数据驱动+关键字驱动 |
- 测试用例中如何驱动excel中的数据
- 如何把excel数据变为测试用例
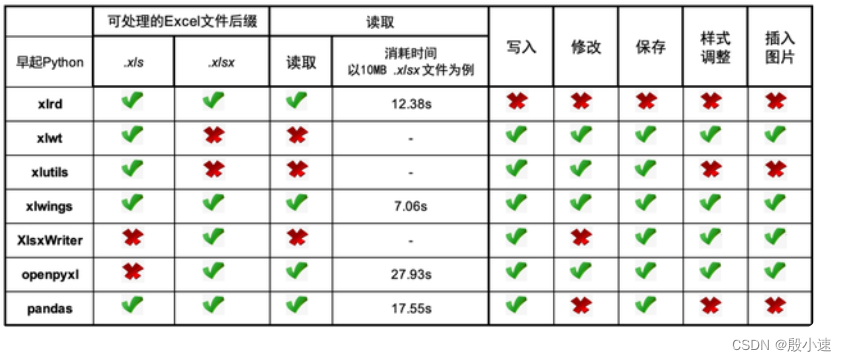
Python中有很多库可以操作Excel,像xlsxwriter、openpyxl、pandas、xlwings等。
官网:http://www.python-excel.org/
2 xlrd
-
介绍
xlrd是python语言中,读取Excel的拓展工具;
支持读取.xls和.xlsx格式的Excel文件,只支持读取,不支持写入。
安装xlrd库:pip3 install xlrd==1.2.0
注意:现在直接pip install xlrd下载的是2.0.1版本的,运行会报错:xlrd.biffh.XLRDError: Excel xlsx file; not supported
-
读取Excel文件
1)导包:import xlrd
2)打开Excel文件:wb = xlrd.open_workbook(filename)
3)打开工作表:ws = sheet_by_name(sheet_name) ws = sheet_by_index(index_num)
4)读取工作表的属性信息(工作表名,工作表所有行数和列数)ws.name ws.nrows ws.ncols
5)读取工作表的内容:
读取一行:ws.row_values(rowx=index_num)
读取一列:ws.col_values(colx=index_num)
读取单元格:ws.cell(rowx, colx).value
import xlrd
wb = xlrd.open_workbook('../data/login.xlsx') # 打开Excel文件
ws1 = wb.sheet_by_name('Sheet1') # 打开工作表
rows = ws1.nrows
cols = ws1.ncols
name = ws1.name
print('总行数:{}, 总列数:{}, 工作表名:{}'.format(rows, cols, name))
# 按行读取
row1 = ws1.row_values(0) # 行的索引值是从0开始
print('第一行内容:', row1)
# 按列读取
col1 = ws1.col_values(0) # 列的索引值是从0开始
print('第一列内容:', col1)
# 单元格读取
cell1 = ws1.cell(1, 0).value
print('A2单元格内容:', cell1)
3 openpyxl
-
介绍
全称:openpythonexcel
官网:https://openpyxl.readthedocs.io/en/stable/
安装openpyxl库:pip install openpyxl
-
读取Excel文件
1)导包:import openpyxl
2)打开Excel文件:wb = openpyxl.load_workbook(filename)
3)打开工作表:ws = wb.sheet_by_name(sheet_name) ws = wb.active ws = wb[sheet_name]
4)读取工作表的属性信息(工作表所有行数和列数)ws.max_row ws.max_colomn
5)读取工作表的内容:
读取一行:ws.iter_rows(max_row=1)
读取一列:ws.iter_cols(max_col=1)
读取单元格:ws.cell(row, col).value ws[单元格].value
读取所有内容:ws.values
import openpyxl
wb = openpyxl.load_workbook('../data/login.xlsx')
ws = wb.active # 获取当前的工作表
rows = ws.max_row
cols = ws.max_column
print('总行数:{}, 总列数:{}'.format(rows, cols))
# 按行读取
print('---------第一行内容---------')
for i in ws.iter_rows(max_row=1):
for j in i:
print(j.value, end='\t')
print()
print('---------第一列内容---------')
for i in ws.iter_cols(max_col=1):
for j in i:
print(j.value, end='\t')
print()
print('---------A2单元格内容---------')
cell1 = ws.cell(2, 1).value
print('通过单元格坐标:', cell1)
cell2 = ws['A2'].value
print('通过单元格名称:', cell2)
print('---------sheet所有内容---------')
print(list(ws.values)) # ws.values输出结果为generator生成器, 使用list()函数对生成器进行迭代
-
向Excel文件写入数据
# 向Excel文件写入数据
from openpyxl import Workbook
wb = Workbook() # 实例化:wb新的工作簿,工作簿里至少有一个工作表
ws = wb.active # 获取当前的工作表
# new_ws = wb.create_sheet() # 创建新的工作表
# append 数据追加
ws.append([1, 2, 3]) # 以行为单位进行数据追加
ws.append([4, 5, 6])
#单元格追加
ws.cell(1,4).value = 'Pass'
ws.cell(2,4).value = 'Fail'
wb.save('excel.xlsx') # 保存工作簿到指定位置,注意后缀为xlsx;没写路劲表示当前目录。
4 pandas
-
介绍
安装pandas库:pip install pandas
-
读取Excel文件
1)导包:import pandas
2)读取Excel文件:wb = pd.read_excel(filename, sheet_name='sheet_name', header=0)
3)读取工作表的属性信息(行索引和列索引):wb.index wb.columns
4)读取工作表的内容:
根据行索引选择数据:
读取一行:wb.loc[[0]]
读取多行:wb.loc[[0, 2]]
读取连续的多行:wb.iloc[0:2] # 读取0到1行;iloc[行切边,列切片]
根据列索引选择数据:
读取一列:wb['col_name']
读取多列:wb[['col_name1', 'col_name2']]
读取连续的多列:wb.iloc[:, 1:6] # 读取所有行,列是1到5列;iloc[行切边,列切片]
读取单元格:wb.iloc[row, col]
读取所有内容:wb.values
5)按条件选取表格数据:rows = wb[wb['col_name'] == 'col_value']
import pandas as pd
file = '../data/wf_Login.xlsx'
wb = pd.read_excel(file, sheet_name='TestLogin_WF', header=0)
print(wb)
# 获取行索引
print(wb.index)
print(wb.index[0])
# 获取列索引
print(wb.columns)
print(wb.columns[1])
# 根据列索引选择数据
print(wb['wfName']) # 读取'wfName'列
# 选择多列
print(wb[['index', 'wfName']]) # 读取'index'和'wfName'列
# 选择连续的多列
print(wb.iloc[:, 1:6]) # 读取所有行,列是1到5列;iloc[行切边,列切片]
# 根据行索引选择数据
row = [1]
print(wb.loc[row]) # 读取行索引为1的一行(行索引从0开始),即读取第2行
# 选择多行
rows = [0, 2]
print(wb.loc[rows]) # 读取行索引为0和2的多行, 即读取第1行和第3行
# 选择连续的多行
print(wb.iloc[0:2]) # 读取行索引从0到1的连续行,即读取第1行到第2行
# 读取所有内容
print(wb.values)
# 读取指定单元格
print(wb.iloc[1, 2]) # 读取行索引=1,第2个列索引的单元格,即读第2行第3列的单元格
# 按条件选取表格数据
prority = wb['prority'] == 'High' # prority列的值是否等于High
print(prority) # 返回bool值,将bool值作为参数传入原数据
print(wb[prority])
# 合并写法
print(wb[wb['prority'] == 'High']) # 返回prority列的值等于High的所有行
# 按条件选取表格数据并操作
rows = wb[wb['prority'] == 'High']
for row in rows.iterrows(): # 行遍历
# do what you want with the row
print(row[1]['wfName'])
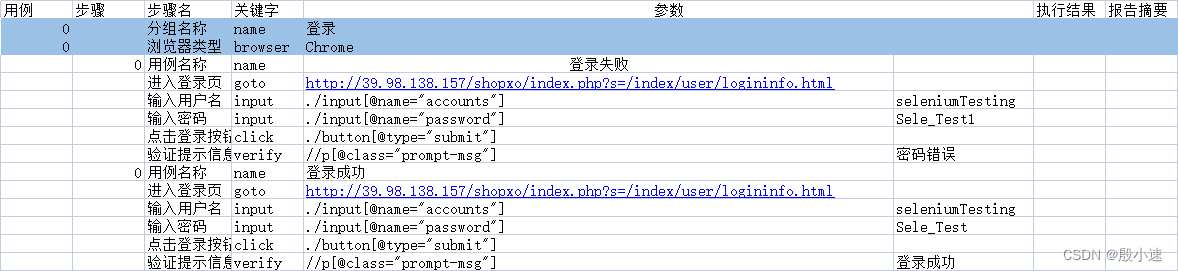
5 如何在excel表格中描述多个用例
-
用Excel来表示测试用例
Excel中描述的信息不是单一的:
- 测试步骤:调用关键字,实现测试用例执行
- 测试属性:用例名称、前置条件、参数、变量、关系
框架除了要读取数据内容,还要解析数据内容。
5.1 制定解析规则
从excel加载复杂的数据结构,可以变为:dict, json, yaml
例如:
# -*- coding:utf-8 -*-
# 读取Excel数据
from openpyxl import load_workbook
from openpyxl.worksheet.worksheet import Worksheet
def read_excel(xls_path):
wb = load_workbook(xls_path)
ws = wb.active # 获取当前的工作表
return ws
re = read_excel('../data/test_excel.xlsx')
# Excel内容格式
# 第一行:表头
# 第x行:(用例ID为0)测试套件的信息
# 第x行:(步骤ID为0)测试用例的信息
# 第x行:测试执行步骤(关键字)
'''
重构目标:
1. 封装为函数,函数返回处理后的数据。
2. 清理垃圾数据,移除没用的None
3. 让数据更有可读性。
'''
def handle_excel(ws: Worksheet):
_suite = { # 套件,本工作表中所有的测试用例
'info': {}, # 套件的属性信息
'case_list': [] # 用例列表
}
_case_list = _suite['case_list']
_case = { # 用例
'info': {}, # 用例的属性信息
'steps': [] # 本用例的所有步骤
}
# top_keys = [i for i in list(re.iter_rows(max_row=1, values_only=True))[0] if i is not None]
# print(top_keys)
# 使用高阶函数filter过滤垃圾数据
top_keys = filter(
lambda x: x is not None,
list(ws.iter_rows(max_row=1, values_only=True))[0])
# print(list(top_keys))
# 使用python解包
for (
用例,
步骤,
步骤名,
关键字,
参数1,
参数2,
执行结果,
报告摘要
) in ws.iter_rows(min_row=2, values_only=True):
if 用例 == 0: # 用例id==0,是分组信息
_suite['info'][步骤名] = 参数1
elif 步骤 == 0: # 步骤id==0,是用例信息
_case = {
'info': {},
'steps': [],
}
_suite['case_list'].append(_case)
_case['info'][步骤名] = 参数1
else:
_case['steps'].append(
{
'步骤名': 步骤名,
'关键字': 关键字,
'参数1': list(
filter(
lambda x: x is not None,
[
参数1,
参数2
]
)
)
}
)
return _suite
print(handle_excel(re))
'''
data = list(re.values)
data = data[1:] # 干掉第一行:切片
for d in data: # 逐行打印 >> 打包数据
if d[0] == 0:
# 这是分组信息
print('suite info:', d)
elif d[1] == 0 :
# 这是用例信息
print(' test case info:', d)
else:
# 这是用例步骤
print(' step:', d)
new_data = {} # 数据打包之后,传递给测试框架,创建测试用例并执行
'''
5.2 创建测试用例
ddt:已经有测试用例了,数据只是通过函数,决定用例的数量。
关键字驱动:没有测试用例,根据关键字自动创建测试用例。