目录
1、插件的实现方式
1.1 Toolformer
1.2 OpenAI插件文档
1.3 个人感想
2、一些有意思的点
2.1 知识和价值观
2.2 算法的研究方向
OpenAI近期公开了GPT-4,除了各方面性能的大幅度提升,最大的惊喜应该来自于插件模式的引入,GPT-4可以执行代码、搜索引擎、以及集成其他App的功能了。
这无疑是对于AI后续应用模式的一次突破性的尝试,同时,也引发了业界对于AI的探讨。因此,本篇基于插件模式展开讨论。
总体来说,插件模式的模型本身并没有革新,仍然保持着原有的局限性。而AI的安全性问题也仍然在探讨中,目前需要相信人大于AI。
1、插件的实现方式
OpenAI并没有公开插件的具体实现原理。因此,对于原理的探究,可以从两个方面来展开:1)meta的公开论文Toolformer;2)OpenAI的插件开发文档。
下面分别来展开:
1.1 Toolformer
我曾经说过,目前GPT的两个最大缺陷在于:没有记忆 和 无法直接学习知识。
将LLM和一些其他工具相结合,显然是一种解决当前局限性的思路。就像人类学习中,我们往往并不需要知道所有问题的答案,但是需要知道如何利用工具(书本、计算机、搜索引擎等)去找到答案。
这个观点也并不绝对。将答案嵌入到脑海中,对于提升效率和思考复杂度是至关重要的。就好比在做题过程中,如果所有公式都是临时查询的,那可能无法灵活应用,组合成精妙的答案。
因此,meta在2023年2月,发表了相关论文Toolformer。具体原理其实相当符合直觉,因此推测其他LLM等也是使用的类似原理。
回顾一下Transformer的实现原理:
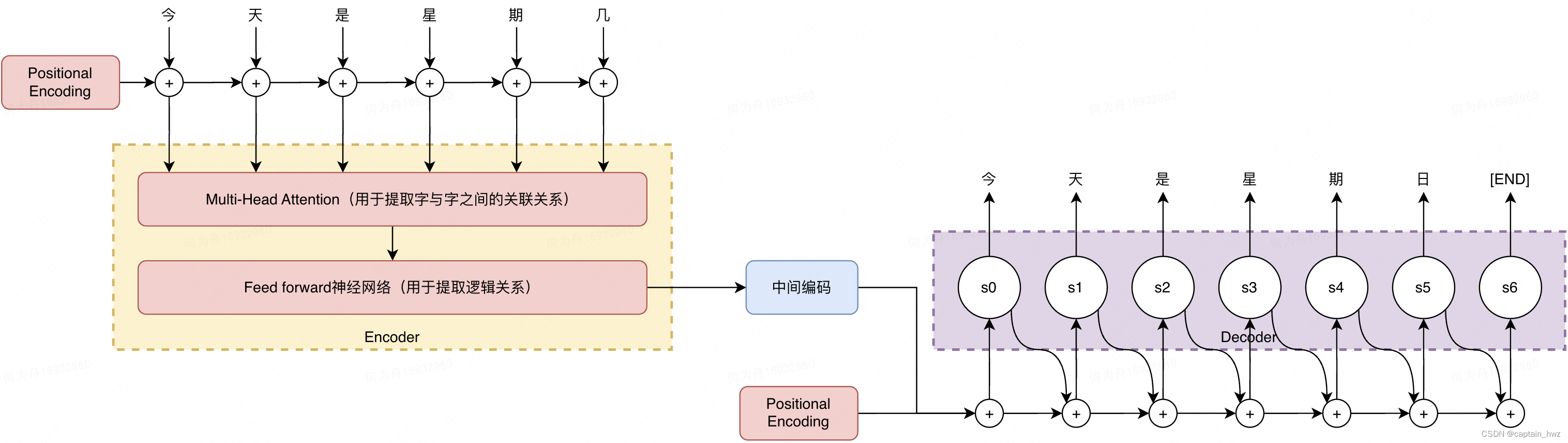
这篇文章需要关注的部分是,输入输出的token化表示。GPT将一段文字,拆解成了若干个token。所谓token,大致对应英文语法中的词根,在汉字中,应当是对应单个文字。而GPT的学习过程,就是依靠大量的训练集,去学习token和token之间的复杂关系。
因此Transformer本身可以应用在大部分领域,只要寻求一种token化表达方式即可。比如在图像领域,可以把一个3x3的像素认为是一个token。
显然,token可以是文字之外的东西。GPT本身就定义了许多类似[START]、[END]等特征信息,用于方便算法去识别关键的位置。同样的,插件也可以被定义为一种token。
Toolformer中的表达方式类似于:今天是<API>Calendar(当前日期)</API>
算法会根据训练集,学习什么时候应该调用API,并生成对应的调用语句,用<API>包裹起来。在实际执行的时候,程序会识别到这段<API>,并发起调用,返回执行结果。算法在接收到执行结果后,在执行一遍Encoder、Decoder流程,就可以继续输出了。大致效果如下:
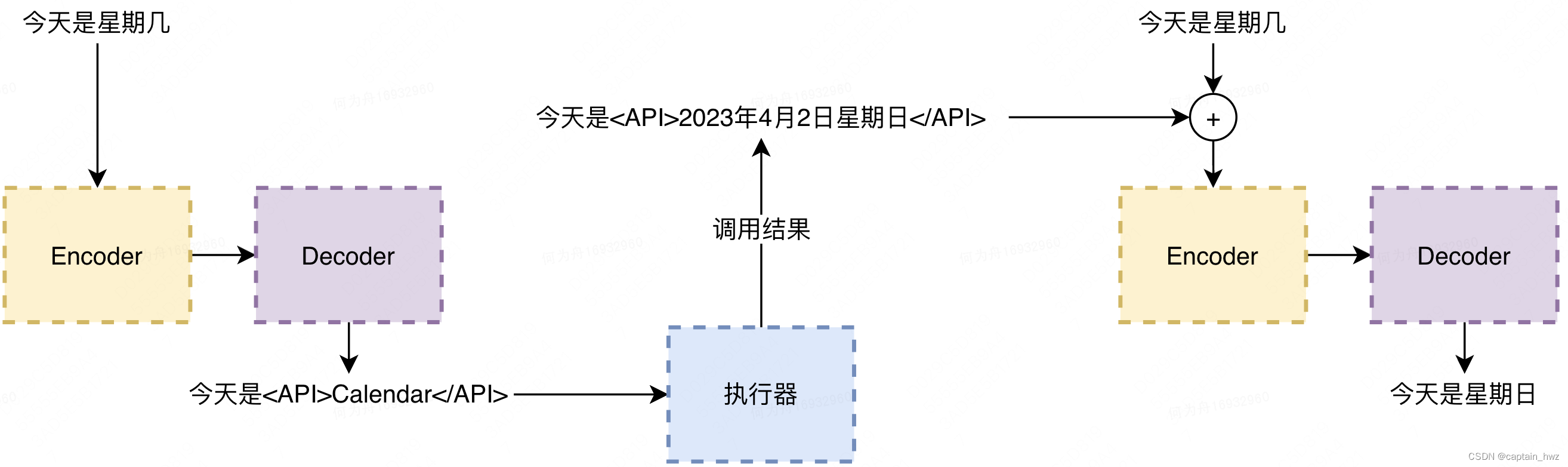
个人认为,之所以插件功能可以实现,是因为Transformer架构极大的扩增了可输入的token长度,从而可以增加很多上下文信息来进行更准确的应答。这些上下文信息包括:精心构造的Prompt信息,对话过程中的持续输入,以及插件执行返回的信息等。
1.2 OpenAI插件文档
有了插件的执行方案,接下来就是去让算法学习去使用插件。
Toolformer中,采用的是简单粗暴的训练逻辑,直接给予大量输入和带API执行的输出,让算法去学习什么时候该调用API。这显然需要较大的训练量,在论文中,Toolformer提到了,他们为每个API都设计了2.5万个训练数据。同样的,这种训练模式也存在几个缺陷:
-
不会链式调用API,无法用一个API的输出当作另一个输入。因为API的训练过程是依靠训练集独立训练的,算法无法学习API之间的相关性。
-
无法支持交互式的API调用,类似搜索引擎返回后,再浏览返回的内容数据。
-
算法对于是否调用API,非常依赖关键词的判断。这应该是训练集的构造本身导致的,没能给算法看到更多的调用场景。
而OpenAI在GPT-4的效果表现中,似乎解决掉了上述的问题。因此,可以简单探究一下其实现原理。API文档:https://platform.openai.com/docs/plugins/examples
一个插件的定义,大致会包含两个内容:
{
"schema_version": "v1",
"name_for_human": "TODO Plugin (no auth)",
"name_for_model": "todo",
"description_for_human": "Plugin for managing a TODO list, you can add, remove and view your TODOs.",
"description_for_model": "Plugin for managing a TODO list, you can add, remove and view your TODOs.",
"auth": {
"type": "none"
},
"api": {
"type": "openapi",
"url": "PLUGIN_HOSTNAME/openapi.yaml",
"is_user_authenticated": false
},
"logo_url": "PLUGIN_HOSTNAME/logo.png",
"contact_email": "support@example.com",
"legal_info_url": "https://example.com/legal"
}
openapi: 3.0.1
info:
title: TODO Plugin
description: A plugin that allows the user to create and manage a TODO list using ChatGPT. If you do not know the user's username, ask them first before making queries to the plugin. Otherwise, use the username "global".
version: 'v1'
servers:
- url: PLUGIN_HOSTNAME
paths:
/todos/{username}:
get:
operationId: getTodos
summary: Get the list of todos
parameters:
- in: path
name: username
schema:
type: string
required: true
description: The name of the user.
responses:
"200":
description: OK
content:
application/json:
schema:
$ref: '#/components/schemas/getTodosResponse'
post:
operationId: addTodo
summary: Add a todo to the list
parameters:
- in: path
name: username
schema:
type: string
required: true
description: The name of the user.
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/addTodoRequest'
responses:
"200":
description: OK
delete:
operationId: deleteTodo
summary: Delete a todo from the list
parameters:
- in: path
name: username
schema:
type: string
required: true
description: The name of the user.
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/deleteTodoRequest'
responses:
"200":
description: OK
components:
schemas:
getTodosResponse:
type: object
properties:
todos:
type: array
items:
type: string
description: The list of todos.
addTodoRequest:
type: object
required:
- todo
properties:
todo:
type: string
description: The todo to add to the list.
required: true
deleteTodoRequest:
type: object
required:
- todo_idx
properties:
todo_idx:
type: integer
description: The index of the todo to delete.
required: true
因此,可以推断OpenAI在GPT-4的插件功能中,应当是按照“通用API接口”的思路去进行的设计。GPT在训练过程中,学习的是如何阅读接口文档,并自行判断何时去调用。推测大体的执行过程类似于:

值得注意的是,OpenAI文档中并没有提到插件开发者需要提供训练集去做fine-tuning,而是更加强调开发者需要设计合适的Prompt。
1.3 个人感想
插件模式并不代表AI智能的提升,但会是短期内主流的应用方
从OpenAI的插件模式可以看出,GPT-4学会的是如何调用接口。但对于GPT-4是否“理解”调用接口背后的含义,我个人持否认观点。
从另一个角度来看,GPT的两个缺陷,没有记忆 和 无法直接学习知识,并没有被解决,而是通过外力弥补了。这就像在RNN之上也会引入Attention来提升性能一样,并没有带来本质原理的革新,尚不能称之为革命性变化。
下一个阶段,我更期待看到GPT在研究领域内的积极作用(效果类似于钢铁侠在“贾维斯”的帮助下发现了新的元素)。GPT所储备的海量知识,结合专业研究人员的问答互动,形成良性的观点碰撞。AI提效的作用从改善生活演变到促进思考,应当是一个非常值得期待的领域,甚至有可能让AI来帮助AI自身迭代算法,探索出下一阶段的算法模型。
功能的扩增必然带来安全性的风险,Human in the Loop仍然是需要遵守的原则。
在初中教材中,有一篇《寡人之于国也》,里面有一句话:刺人而杀之曰:‘非我也,兵也’。本意是说,兵器是一种工具,没有思想,所以问题是出在使用兵器的人身上。
狗彘食人食而不知检,涂有饿莩而不知发,人死,则曰:‘非我也,岁也。’是何异于刺人而杀之曰:‘非我也,兵也’?王无罪岁,斯天下之民至焉
但随着AI的功能性逐渐拓展,工具开始具备一定的自控能力了。这个时候,应该去怪谁呢?这显然是一个暂时无解的问题。
关于AI的安全性问题探讨,本篇不做展开。在此,仅仅表达一个观点,无论当前的AI多么炫酷,Human in the Loop仍然是必须要遵守的准则。尤其是在医学、法律、安全等敏感领域上,把决策权交由AI是一个不负责任的做法(哪怕人的出错概率比AI高,但人能够负责,就会比AI可靠)。
2、一些有意思的点
随着近期的AI热点大爆发,关于AI本身的各种讨论也涌现出来。对个人觉得有意思的一些点,展开讨论。
2.1 知识和价值观
我们知道,GPT的整体训练模式是base model和fine tuning。前者主要用来学习知识,后者用来学习如何正确的作答(类比于“价值观”)。
而在GPT-4的技术文档中,OpenAI提到了一些比价有意思的研究:他们发现,如果不经过fine-tunine,GPT回答的准确性是更高的。但是经过了fine-tunine之后,尽管答案更合理了,但准确性却下降了,导致经常给出hallucination的答案(即GPT认为正确,但实际错误的认知)。
下面是对这个现象的具体描述
-
在预训练阶段,base model就已经能够很好完成考试了(注意,不是对话。考试更接近于传统的分类场景)。经过RLHF强化学习之后,考试成绩下降了。在经过post-training后,base model甚至不知道要回答问题,必须构造相应的promt,才能完成作答。
-
GPT在回答的时候,会confidently wrong(哪怕错了,它也对自己的答案很自信)。而事实上,这个自信来源于,在预训练的阶段,它对答案的准确率判断确实达到了非常高的水平(如下左图所示,当一个答案只有50%概率是对的时候,base model的预测结果也表示这个答案只有50%是对的)。但经过post-traning后,这个匹配度下降了,这也导致GPT会对一些错误答案,给出过高的准确率判断。
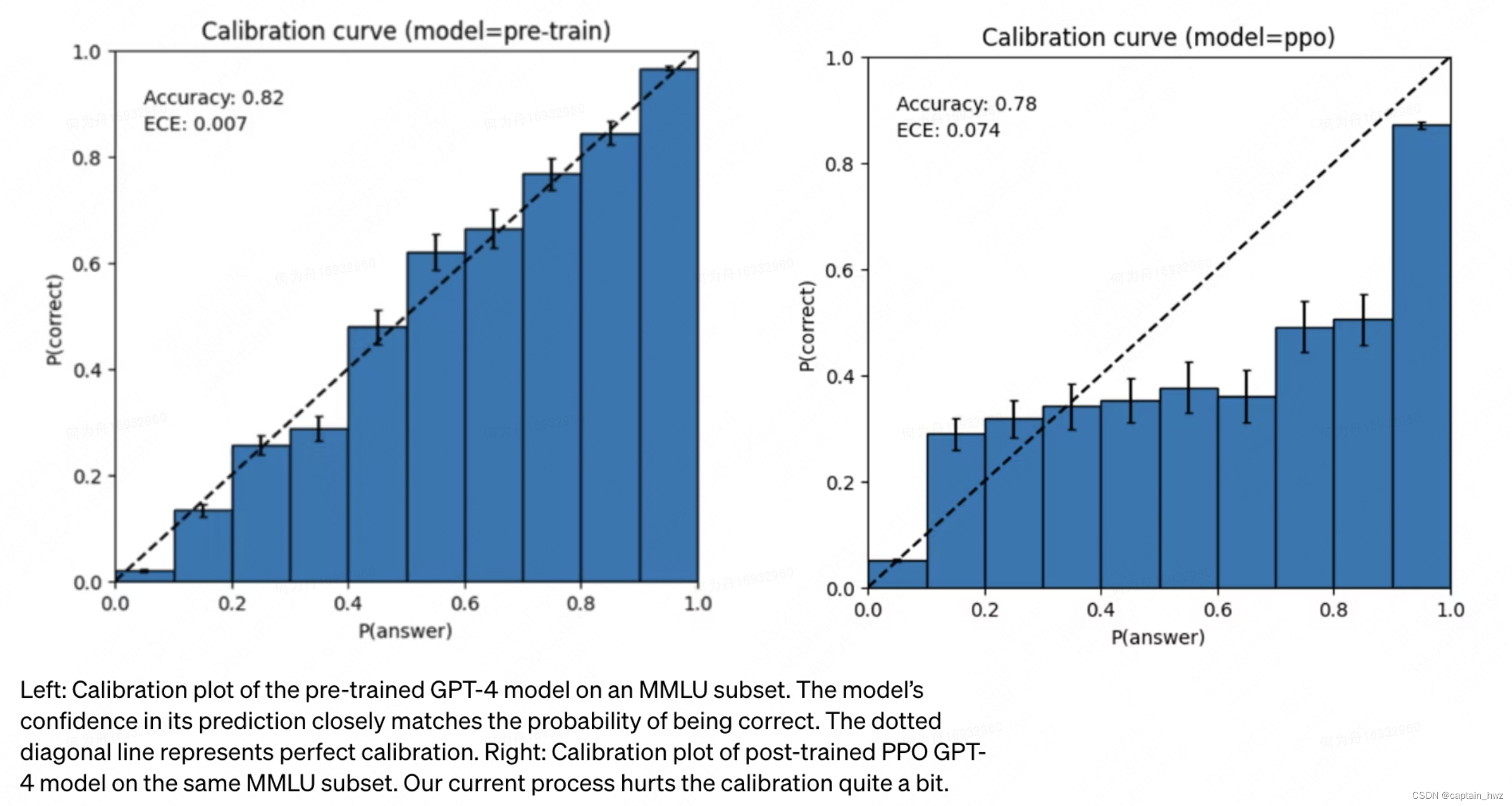
就像人类理性和感性的思考结果。GPT的预训练阶段,能够学会大量的知识,进行绝对理性的回答。但人们希望它能够更加感性,判断正误,具备价值观,因此进行了强化学习,但反而牺牲了理性的判断结果。
从这一点上来看,GPT和人类思维的相似性,再一次得到了印证。
2.2 算法的研究方向
这个话题源自于Twitter上,知名教授BernhardSchölkopf反应说,LLM方向的学生突然想转方向了。原因是觉得LLM已经到头了,剩下的都是小修小补的工作,很难产出突破性成果取得PhD博士学位了。
个人推测,部分原因也可能是大语言模型的训练成本越来越高,小玩家很难入场。只能学习学习理论,然后在这些AI大厂训练出来的结果上做微调。
同样的,教授也表达了自己的看法,鼓励学生们继续努力。
 最后,引用一下原文:The future depends on some graduate student who is deeply suspicious of everything I have said.
最后,引用一下原文:The future depends on some graduate student who is deeply suspicious of everything I have said.