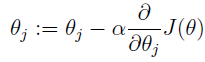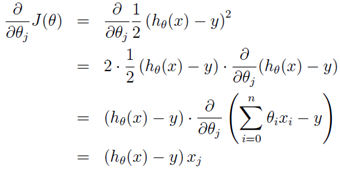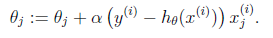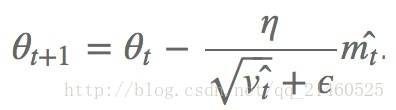e) Nesterov Momentum
仅仅有一个追求速度的球往山下滚是不能令人满意的,我们需要一个球,它能知道往前一步的信息,并且当山坡再次变陡时他能够减速。因此,带有nesterov的出现了!
在momentum里,先计算当前的梯度(短蓝色线),然后结合以前的梯度执行更新(长蓝色线)。而在nesterov momentum里,先根据事先计算好的梯度更新(棕色),然后在预计的点处计算梯度(红色),结合两者形成真正的更新方向(绿色)。
这是对之前的Momentum的一种改进,大概思路就是,先对参数进行估计(先往前看一步,探路),然后使用估计后的参数来计算误差
具体实现:
需要:学习速率 ϵ, 初始参数 θ, 初始速率v, 动量衰减参数α
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差,并更新速度v和参数θ:
ĝ ←+1m∇θ∑iL(f(xi;θ+αv),yi)
v←αv−ϵĝ
θ←θ+v
注意在估算ĝ 的时候,参数变成了θ+αv而不是之前的θ
推荐好文——揭开nesters momentum的面纱
f) AdaGrad
AdaGrad可以自动变更学习速率,只是需要设定一个全局的学习速率ϵ,但是这并非是实际学习速率,实际的速率是与以往参数的模之和的开方成反比的.也许说起来有点绕口,不过用公式来表示就直白的多:
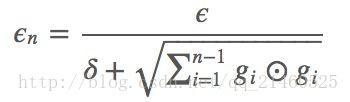
其中δ是一个很小的常亮,大概在10−7,防止出现除以0的情况.
核心思想:对于频繁出现的参数使用更小的更新速率,对于不频繁出现的参数使用更大的更新速率。
正因为如此,该优化函数脚适用于稀疏的数据,比如在Google从YouTube视频上识别猫时,该优化函数大大提升了SGD的鲁棒性。在训练GloVe词向量时该优化函数更加适用。
具体实现:
需要:全局学习速率 ϵ, 初始参数 θ, 数值稳定量δ
中间变量: 梯度累计量r(初始化为0)
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差,更新r,再根据r和梯度计算参数更新量
在SGD中,我们对所有参数进行同时更新,这些参数都使用同样的学习速率。
比图用gt,i表示在t时间点,对i参数求得的偏导。
那么在SGD中就会用同一个学习速率对i参数进行更新:
但是在adagrad里,会综合考虑i之前的所有梯度值来更新学习速率,其中Gt,ii是一个对角矩阵,i行i列存储了目前时间点为止的所有i参数的偏导的平方和。后面的项是一个很小的值(1e−8),为了防止除0错误。
优点:
能够实现学习率的自动更改。如果这次梯度大,那么学习速率衰减的就快一些;如果这次梯度小,那么学习速率衰减的就慢一些。
缺点:
最大的缺点在于分母中那个G是偏导的累积,随着时间的推移,分母会不断的变大,最后会使得学习速率变的非常小,而此时会使得模型不再具备学习其他知识的能力。
经验表明,在普通算法中也许效果不错,但在深度学习中,深度过深时会造成训练提前结束。因为它到后面的衰减可能越来越慢,然后就提前结束了。为了解决提前结束的问题,引入了如下的算法:Adadelta!RMSprop!
Adadelta
adadelta是adagrad的延伸,不同于adadelta将以前所有的偏导都累加起来,adadelta控制了累加的范围到一定的窗口中。
但是,并非简单的将窗口大小设置并且存储,我们是通过下式动态改变的上述的G:
这里面的gamma类似于momentum里面的项(通常取值0.9),用来控制更新的权重。
因此以前的:
将被改变为:
RMSprop
RMSProp通过引入一个衰减系数,让r每回合都衰减一定比例,类似于Momentum中的做法。(我觉得和Adadelta没啥区别)
具体实现:
需要:全局学习速率 ϵ, 初始参数 θ, 数值稳定量δ,衰减速率ρ
中间变量: 梯度累计量r(初始化为0)
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差,更新r,再根据r和梯度计算参数更新量
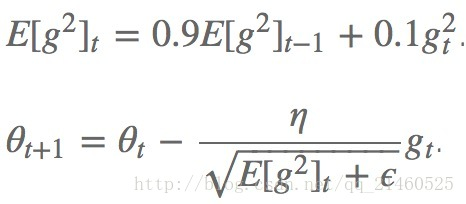
算法的提出者建议如上式所示,gamma取0.9,学习速率为0.001
优点:
相比于AdaGrad,这种方法很好的解决了深度学习中过早结束的问题
适合处理非平稳目标,对于RNN效果很好
缺点:
又引入了新的超参,衰减系数ρ
依然依赖于全局学习速率
Adam
Adam(Adaptive Moment Estimation)是另外一种给每个参数计算不同更新速率的方法,其本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。它和上述的adadelta和RMSprop一样,都存储了以前的偏导平方衰减平均值,此外,它还存储以前的偏导衰减平均值。
具体实现:
需要:步进值 ϵ, 初始参数 θ, 数值稳定量δ,一阶动量衰减系数ρ1, 二阶动量衰减系数ρ2
其中几个取值一般为:δ=10−8,ρ1=0.9,ρ2=0.999
中间变量:一阶动量s,二阶动量r,都初始化为0
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差,更新r和s,再根据r和s以及梯度计算参数更新量
其中的Mt和Vt分别表示平均值角度和非中心方差角度的偏导。
才方法的作者建议 β1取0.9, β2取0.999 ,ϵ取10-8。并且声称Adam在实践中比其他的自适应算法有更好的表现。