爬虫爬取信息,无xpath,带源码
前言
爬虫利用requests 库爬取网址页面,包括文章标题,作者名,图片网址,评论数等,本打算利用xpath从页面爬取,但是新闻页面信息只能抓包,暂时写不出来用xpath的版本
操作步骤
1.在python中下载必要的库
本次需要的库只有两个,分别为requests库和json库,requests库用来发起请求,json库用来提取网页中的json文件
requests下载的时候使用pip即可

json库为原本就有的库,不需要手动安装
2.完善运行环境
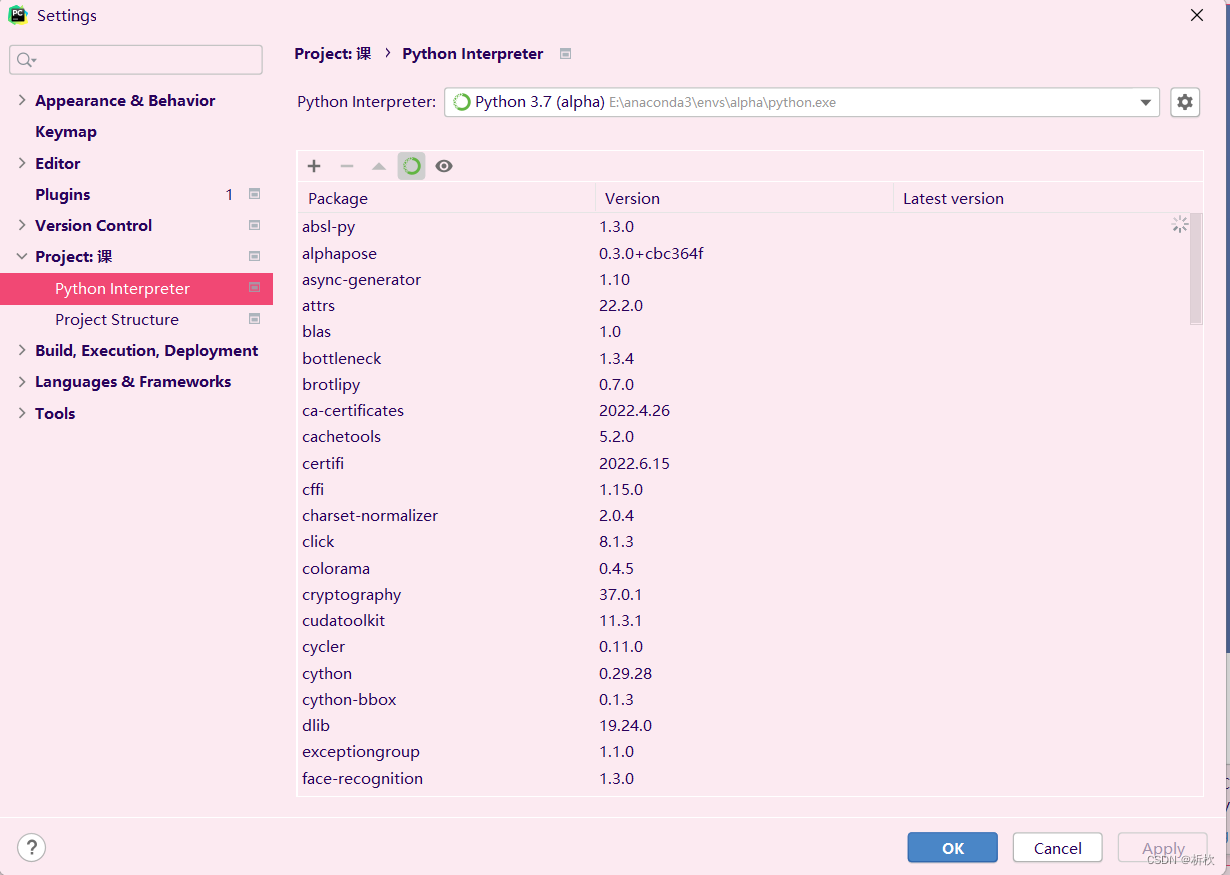
本次使用的软件位pycharm,使用时,点击左上角file->settings
我的操作用的是anaconda环境,也可以直接导入库函数
3.在网页中寻找到资源
打开网页,右击空白处,点击检查,也可以直接按住F12,进入检查界面
会出现如图状况,没有资源的话刷新页面即可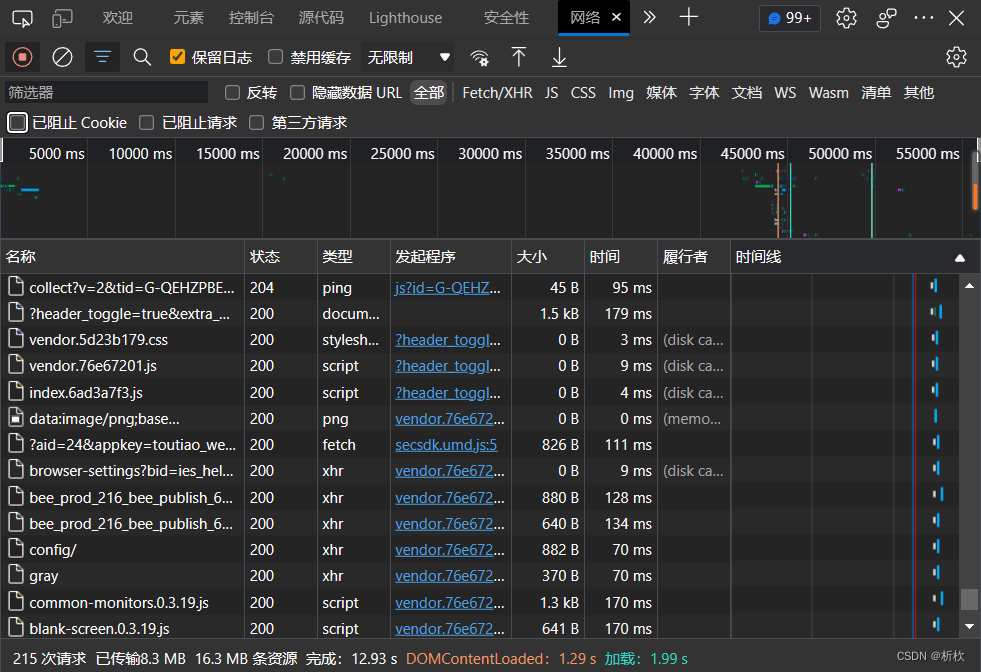
过滤Fetch/XHR,找到这种feed文件,feed文件有两类,我们选择channel_id这种,要爬取的内容就包括在里面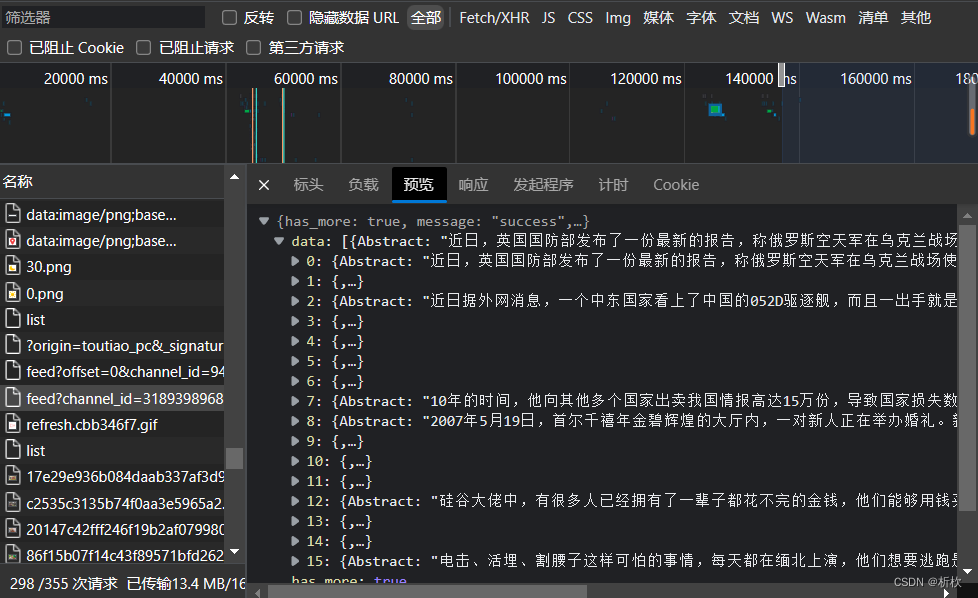
可以点击预览查看包里面的信息是否是自己想要的信息,如果没有的话可以点击原本页面中的各种事件,让页面渲染出来,渲染出来后包会随之更新
4.写代码
代码如下(示例):
url为抓出的包中表头中的请求url,不同包的url内容不同,视情况爬取,点击预览可以看到包中所包含的信息。
headers为最下方的user-agent。
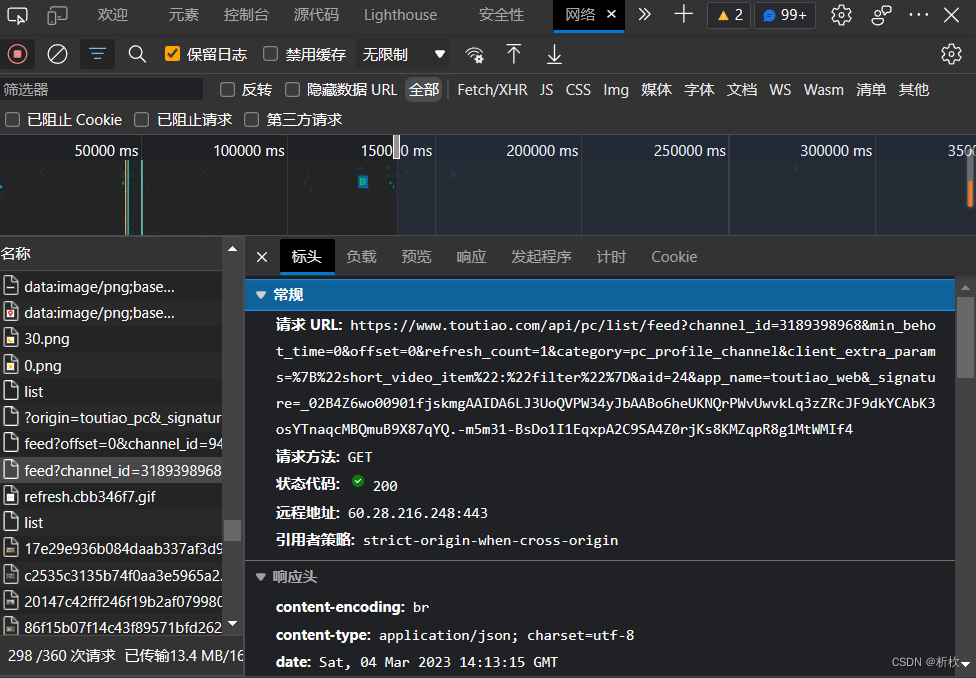
将其作为参数放入requests中,并将url和header结果通过json包转为为python字典模式方便信息提取
之后依靠字典知识依次循环过滤有用信息即可
过滤过程中包含字典列表,使用for循环即可
import requests
import json
url="https://www.toutiao.com/api/pc/list/feed?channel_id=3189398968&min_behot_time=0&offset=0&refresh_count=1&category=pc_profile_channel&client_extra_params=%7B%22short_video_item%22:%22filter%22%7D&aid=24&app_name=toutiao_web&_signature=_02B4Z6wo00901fjskmgAAIDA6LJ3UoQVPW34yJbAABo6heUKNQrPWvUwvkLq3zZRcJF9dkYCAbK3osYTnaqcMBQmuB9X87qYQ.-m5m31-BsDo1I1EqxpA2C9SA4Z0rjKs8KMZqpR8g1MtWMIf4"
header={
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.57"
}
resp=requests.get(url=url,headers=header)
res=json.loads(resp.text)
# 新闻标题
# for i in res["data"]:
# print(i["Abstract"])
#
# # 图片链接
# for i in res["data"]:
# for i in i["share_large_image"]['url_list']:
# print(i["url"])
#文章地址
# for i in res["data"]:
# print(i["display_url"])
#作者名字
# for i in res["data"]:
# print(i["media_name"])
#评论数
# for i in res["data"]:
# print(i["comment_count"])
for i in res["data"]:
print("文章标题:"+i["Abstract"])
print("作品地址:"+i["display_url"])
print("作者名字:"+i["media_name"])
print("评论数: "+str(i["comment_count"]))
for i in i["share_large_image"]['url_list']:
print("图片网址:"+i["url"])
print("\n")
5.结果展示

总结
本来该文章想要使用的是xpath,但是显然xpath并没有用到,且本代码只是将爬取的信息显示出来,如需要保存,需要自己加上代码。
此外,url可能失效,如若代码上方附带代码无法运行,修改url即可,如果运行出来没有结果可能是抓包错误,重新选择要抓的包即可。