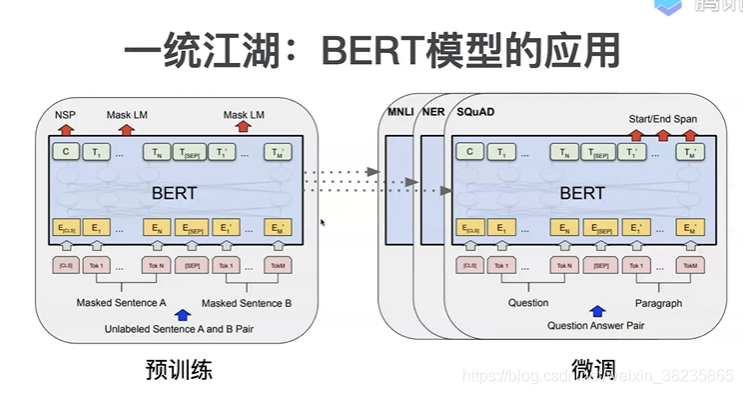
bert模型是Google在2018年10月发布的语言表示模型,在NLP领域横扫了11项任务的最优结果,可以说是现今最近NLP中最重要的突破。Bert模型的全称是Bidirectional Encoder Representations from Transformers,是通过训练Masked Language Model和预测下一句任务得到的模型。
bert作为预训练模型有两种用法:提取包含上下文意义的向量,对特定任务做微调
同GPT采用两阶段模式:利用双向transformer语言模型进行预训练,通过fine-tuning模式解决下游任务。(它和gpt的区别就是gpt,更适用于文本生成,通过前文去预测当前的字
BERT创新: Masked语言模型和Next Sentence Prediction。
BERT详解https://plmsmile.github.io/2018/12/15/52-bert/
https://blog.csdn.net/weixin_42001089/article/details/97657149
实践
一、安装环境
安装Anaconda,打开Anaconda prompt
创建python=3.7版本的环境,取名叫py36
conda create -n DP python=3.7
激活环境
conda activate DP (conda4之前的版本是:source activate py36 )
退出环境
conda deactivate
下载如下包:
xlwd,xlrd 1.2.0
transformers 4.1.1
pytorch 1.6
numpy 1.19.4
pandas 1.1.4
pytorch 1.6.0+cu101
torch可在官网下载https://pytorch.org/
安装pycharm,新建项目时选择创建的环境(用anaconda 的工具切换环境需要下载包,网络可能不通)
二、token代码
文本转成词向量、 编码、解码功能代码实现
vacab.txt是字典,每行一个字符
import torch
# 自定义token
class Token(object):
def __init__(self, vocab_file_path, max_len=510):#512-2
self.vocab_file_path = vocab_file_path
self.max_len = max_len
self.word2id, self.id2word = self._load_vovab_file() # 得到词典
# 进行参数验证
if self.max_len > 510: # 表示超过了bert限定长度512
raise Exception(print('设置序列最大长度超过bert限制长度,建议设置max_len<=510'))
# 加载词表生成word2id和id2word列表
def _load_vovab_file(self):
with open(self.vocab_file_path, 'r', encoding='utf-8') as fp:
vocab_list = [i.replace('\n', '') for i in fp.readlines()]
word2id = {}
id2word = {}
for index, i in enumerate(vocab_list):
word2id[i] = index
id2word[index] = i
return word2id, id2word
# 定义数据编码encode并生成pytorch所需的数据格式
def encode_str(self, txt_list: list):
# 针对所有的输入数据进行编码
return_txt_id_list = []
return_segment_id_list = []
return_mask_id_list = []
for txt in txt_list:
inner_str = txt
# 进行判断数据是否超过最大长度
if len(txt) > self.max_len:
inner_str = inner_str[:self.max_len] # 截取
inner_str_list = list(inner_str)
# 开始构建各种索引
inner_seq_list = [self.word2id.get('[CLS]')]
inner_segment_list = [0] * (self.max_len + 2) # 构建segment
inner_mask_list = [1] * (len(inner_str_list) + 2) + \
[0] * (self.max_len - len(inner_str_list)) # 计算mask
for char in inner_str_list:
char_index = self.word2id.get(char, False)
if char_index == False: # 表示该字符串不认识
inner_seq_list.append(self.word2id.get('[UNK]')) #开头
else:
inner_seq_list.append(char_index)
inner_seq_list.append(self.word2id.get('[SEP]')) # 跟上结尾token
# 执行padding操作
if len(inner_seq_list) < 512:
inner_seq_list += [self.word2id.get('[PAD]')] * (self.max_len - len(inner_str_list))
return_txt_id_list.append(inner_seq_list)
#类似[[101, 100, 131, 120, 100, 167, 162, 150, 157, 156, 148, 151, 154, 147, 120, 158, 160, 157, 152, 147, 145, 162, 120, 100, 100, 120, 162, 147, 161, 162, 119, 162, 166, 162, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
return_segment_id_list.append(inner_segment_list)
return_mask_id_list.append(inner_mask_list)
# 构建成为pytorch的数据返回结构
return_data = {
'input_ids': torch.tensor(return_txt_id_list),# 就是一连串 token 在字典中的对应id。形状为 (batch_size, sequence_length)
'token_type_ids': torch.tensor(return_segment_id_list),#就是 token 对应的句子id,值为0或1(0表示对应的token属于第一句,1表示属于第二句)。形状为(batch_size, sequence_length)。
'attention_mask': torch.tensor(return_mask_id_list)#各元素的值为 0 或 1 ,避免在 padding 的 token 上计算 attention(1不进行masked,0则masked)。形状为(batch_size, sequence_length)。
}
return return_data
# 定义解码操作
def decode_str(self, index_list):
return ''.join([self.id2word.get(i) for i in index_list])
三、案例
原理
什么是BERT
词嵌入模型
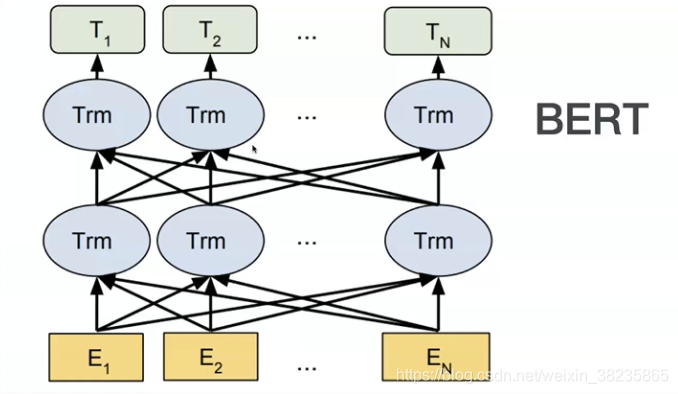
优势
bert 与gpt模型原型

BERT输入表示详解和输出
每个输入有三个embedding,词的Embedding(字向量),Segment的Embedding(文本向量),position的Embedding(位置向量)。
词的Embedding:句子开头有一个特殊的Token [CLS],句子结束有一个特殊的Token [SEP]。如果是两个句子同时输入,则只有开头有[CLS],后面那个句子没有[CLS],只有[SEP]。
Segment的Embedding:为了将多个句子区分,第一个句子可能用0表示,第二个用1,只有一个句子的时候可能只用0,第一个token [CLS]很有用,在进行self-attention时,会获取下文所有信息(编码整个句子的语义)。
position的Embedding:保证序列的顺序性。由于出现在文本不同位置的字/词所携带的语义信息存在差异,因此,BERT模型对不同位置的字/词分别附加一个不同的向量以作区分。有两种。Position Embeddings layer 实际上就是一个大小为 (512, 768) 的lookup表,在BERT中,每个词会被转换成768维的向量表示。第一行是代表第一个序列的第一个位置,第二行代表序列的第二个位置,以此类推。因此,如果有这样两个句子“Hello world” 和“Hi there”, “Hello” 和“Hi”会由完全相同的position embeddings,因为他们都是句子的第一个词。同理,“world” 和“there”也会有相同的position embedding。
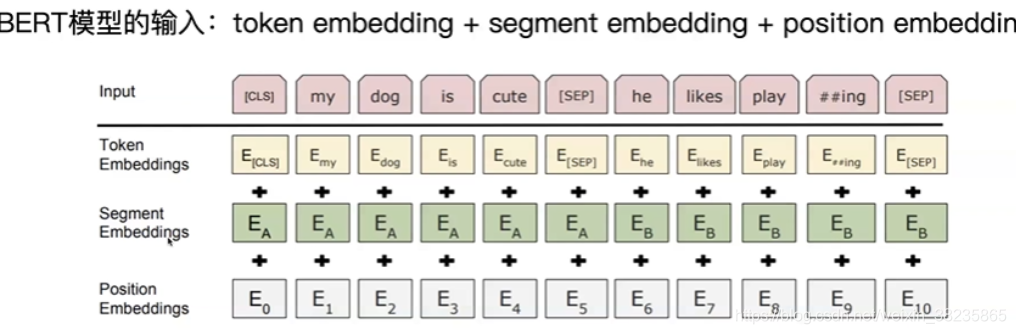
注意这里的分词会把”playing”分成”play”和”##ing”两个Token,这种把词分成更细粒度的Word Piece的方法是一种解决未登录词的常见办法
模型输出则是输入各字对应的融合全文语义信息后的向量表示。
BERT预训练
Masked语言模型
在预训练的时候,随机mask掉15%的单词,让语言模型去预测这个单词。

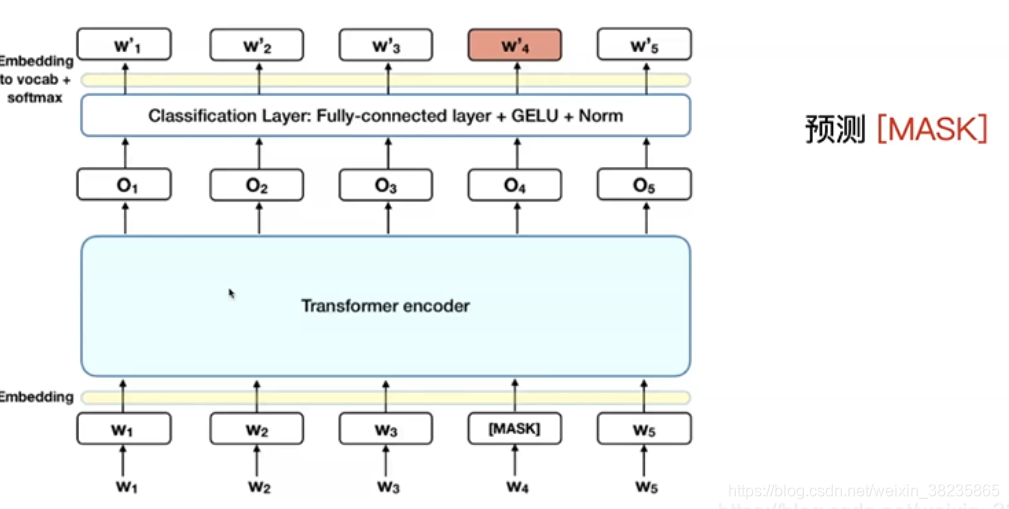
问题1:
大量mask标记,造成预训练和finetune时候的差距,因为finetune没有mask,finetune的时候用的是自己的数据集收敛很慢,但是效果好(比单向语言模型慢)
解决方案:

BERT并不知道[MASK]替换的是哪一个词,而且任何一个词都有可能是被替换掉的,比如它看到的词可能是被替换的词。这样强迫模型在编码当前时刻的时候不能太依赖于当前的词,而要考虑它的上下文,甚至更加上下文进行”纠错”。
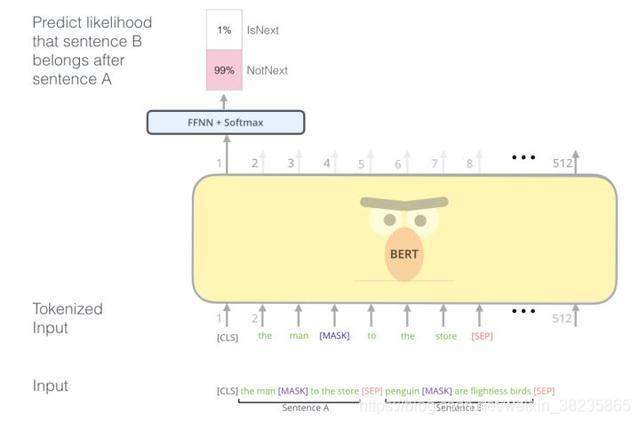
Next Sentence Prediction
从文本语料库中随机选择50%正确语句对和50%错误语句对进行训练,与Masked LM任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。对于像QA、NLI等需要理解多个句子之间关系的下游任务,只靠语言模型是不够的。还需要提前学习到句子之间的关系。是一个二分类任务。输入是A和B两个句子,标记是IsNext或NotNext,用来判断B是否是A后面的句子。这样,就能从大规模预料中学习到一些句间关系。
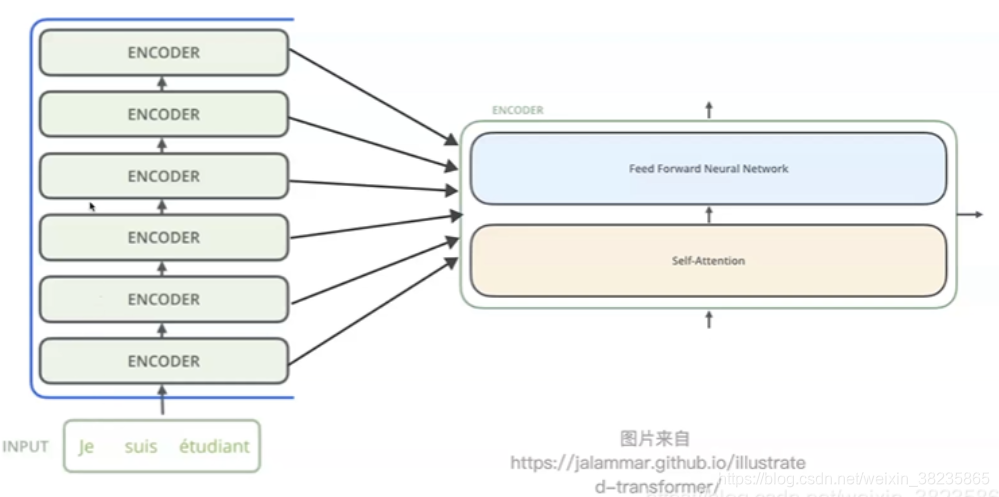
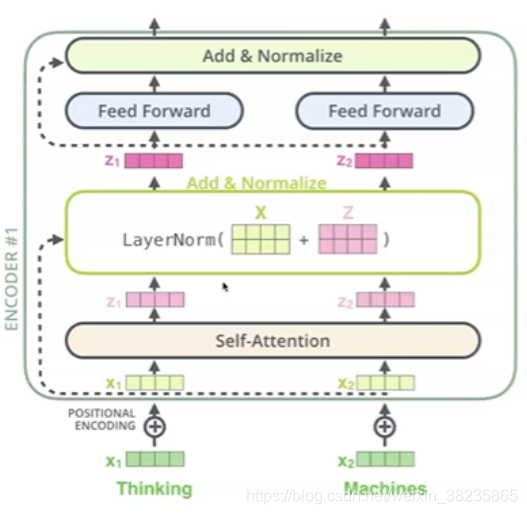
模型结构
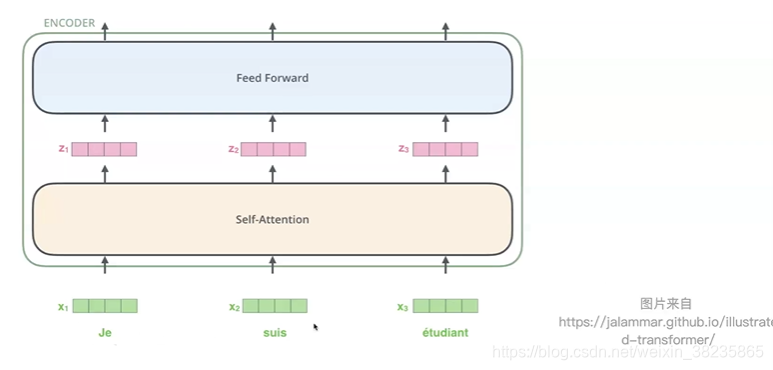
每层encoder由一个feed forward ,一个multi-head attention, 以及两层layerNorm构成
自注意力机制self attention
Transformer是组成BERT的核心模块,而Attention机制又是Transformer中最关键的部分,因此,下面我们从Attention机制开始,介绍如何利用Attention机制构建Transformer模块,在此基础上,用多层Transformer组装BERT模型。
Attention机制的中文名叫“注意力机制”,顾名思义,它的主要作用是让神经网络把“注意力”放在一部分输入上,即:区分输入的不同部分对输出的影响。
Attention机制主要涉及到三个概念:Query、Key和Value。在增强字的语义表示应用场景中,目标字及其上下文的字都有各自的原始Value,Attention机制将目标字作为Query、其上下文的各个字作为Key,并将Query与各个Key的相似性作为权重,把上下文各个字的Value融入目标字的原始Value中.
如下图所示,Attention机制将目标字和上下文各个字的语义向量表示作为输入,首先通过线性变换获得目标字的Query向量表示、上下文各个字的Key向量表示以及目标字与上下文各个字的原始Value表示,然后计算Query向量与各个Key向量的相似度作为权重,加权融合目标字的Value向量和各个上下文字的Value向量,作为Attention的输出,即:目标字的增强语义向量表示
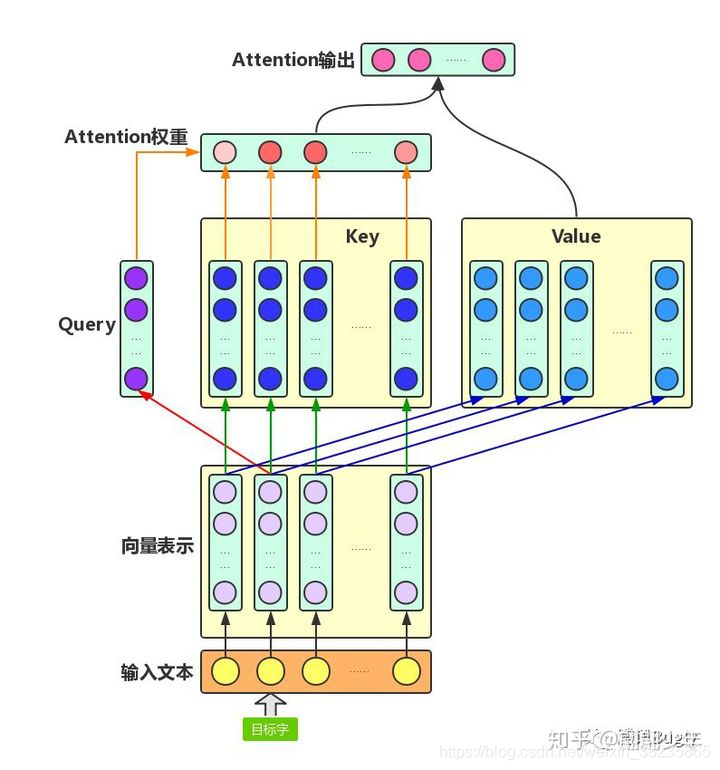
计算每个token词向量和别的词向量的某种权重关系

Self-Attention:对于输入文本,我们需要对其中的每个字分别增强语义向量表示,因此,我们分别将每个字作为Query,加权融合文本中所有字的语义信息,得到各个字的增强语义向量,如下图所示。在这种情况下,Query、Key和Value的向量表示均来自于同一输入文本,因此,该Attention机制也叫Self-Attention。
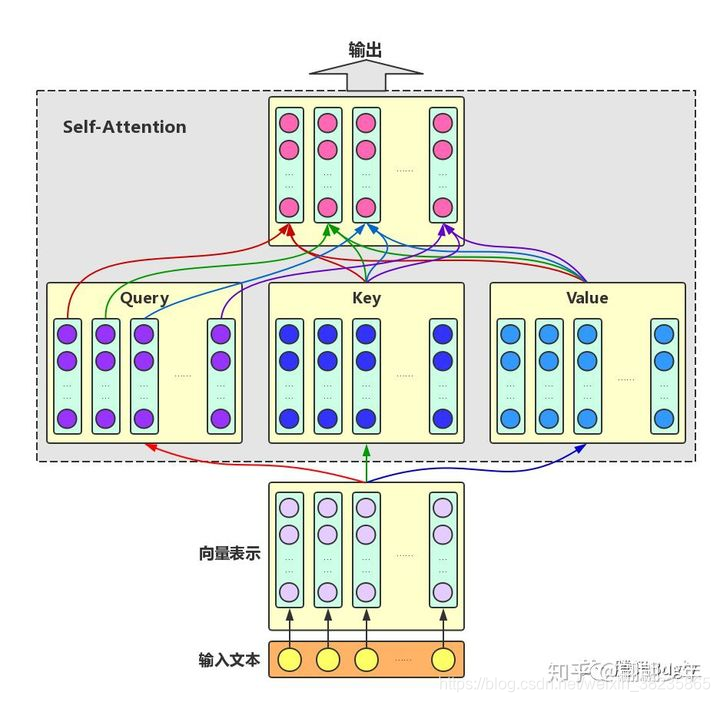
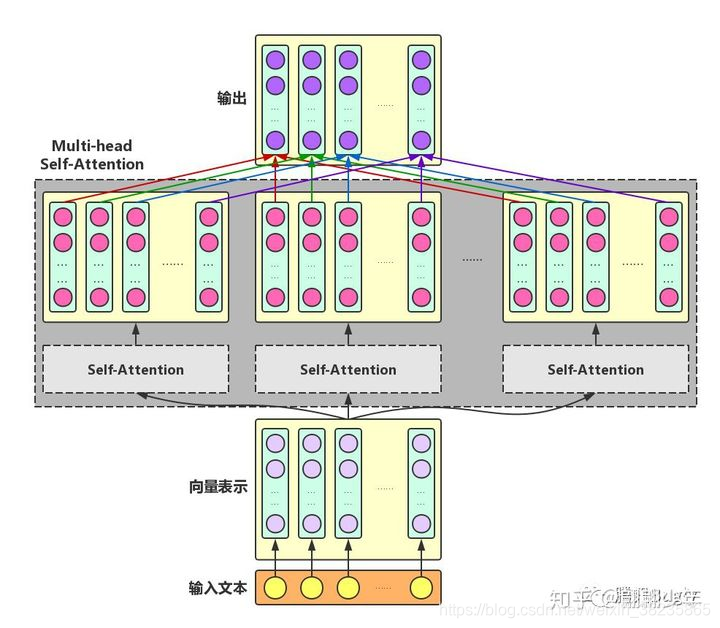
multi-headed attention
为了增强Attention的多样性,文章作者进一步利用不同的Self-Attention模块获得文本中每个字在不同语义空间下的增强语义向量,并将每个字的多个增强语义向量进行线性组合,从而获得一个最终的与原始字向量长度相同的增强语义向量,如下图所示
Feed Forward
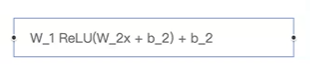
应用
预训练模型、文本分类、命名实体识别、机器翻译,问答系统,文本摘要、知识图谱、聊天机器人等
- 文本分类
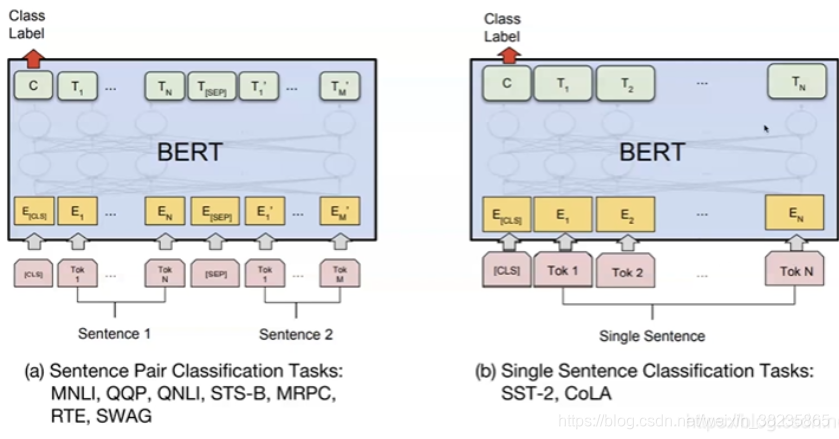
单句子分类(CLS+句子):
输入是一个序列,所有的Token都是属于同一个Segment(Id=0),我们用第一个特殊Token [CLS]的最后一层输出接上softmax进行分类,用分类的数据来进行Fine-Tuning。利用CLS进行分类。
多句子分类(CLS+句子A+SEP+句子B):
对于相似度计算等输入为两个序列的任务,过程如图左上所示。两个序列的Token对应不同的Segment(Id=0/1)。我们也是用第一个特殊Token [CLS]的最后一层输出接上softmax进行分类,然后用分类数据进行Fine-Tuning。利用CLS分类。
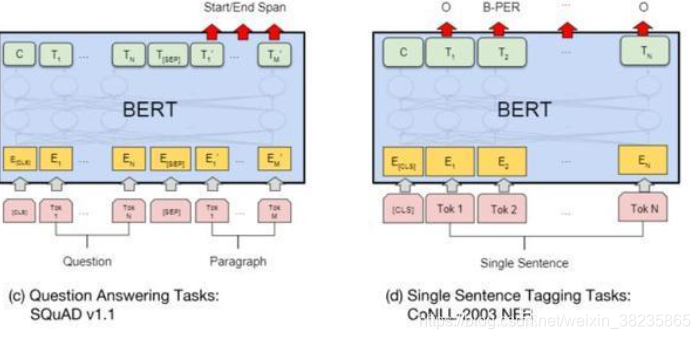
NER(CLS+句子):序列标注,比如命名实体识别,输入是一个句子(Token序列),除了[CLS]和[SEP]的每个时刻都会有输出的Tag,然后用输出的Tag来进行Fine-Tuning利用句子单词做标记。QA:CLS+问题+SEP+文章。比较麻烦,比如比如SQuAD v1.1数据集,输入是一个问题和一段很长的包含答案的文字(Paragraph),输出在这段文字里找到问题的答案。
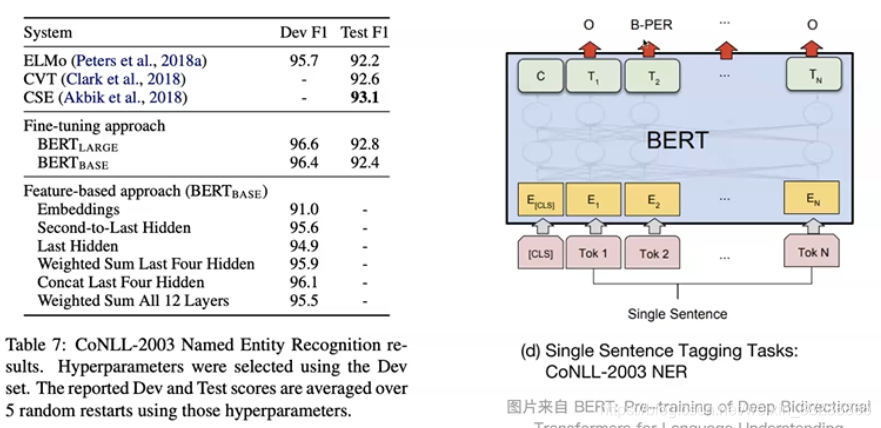
- 命名实体识别
使用预训练模型实践
预测词语
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-uncased')
unmasker("Hello I'm a [MASK] model.")

获取文本的特征
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained("bert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
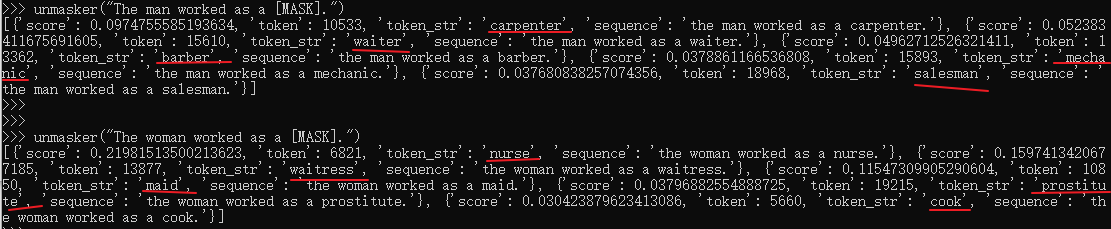
模型存在一定偏见
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-uncased')
unmasker("The man worked as a [MASK].")
unmasker("The woman worked as a [MASK].")
scratch实践-文本分类
参考https://zhuanlan.zhihu.com/p/72448986
import os
import sys
import pickle
import pandas as pd
import numpy as np
from concurrent.futures import ThreadPoolExecutor
import torch
import pickle
from sklearn.preprocessing import LabelEncoder
from torch.optim import optimizer
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler, TensorDataset
from torch.nn import CrossEntropyLoss,BCEWithLogitsLoss
from tqdm import tqdm_notebook, trange
from pytorch_pretrained_bert import BertTokenizer, BertModel, BertForMaskedLM, BertForSequenceClassification
from pytorch_pretrained_bert.optimization import BertAdam, WarmupLinearSchedule
from sklearn.metrics import precision_recall_curve,classification_report
import matplotlib.pyplot as plt
# 加载数据
data = pd.read_table('data/dev.tsv')
data = data.iloc[:,[3,1]]
# 列名重新命名
data.columns = ['text','label']
# 标签编码
# 因为label为中文格式,为了适应模型的输入需要进行ID化,此处调用sklearn中的label encoder方法快速进行变换。
le = LabelEncoder()
le.fit(data.label.tolist())
data['label'] = le.transform(data.label.tolist())
# 分词工具
bert_tokenizer = BertTokenizer.from_pretrained('bert-base-chinese', do_lower_case=False)
# 封装类
class DataPrecessForSingleSentence(object):
"""
对文本进行处理
"""
def __init__(self, bert_tokenizer, max_workers=10):
"""
bert_tokenizer :分词器
dataset :包含列名为'text'与'label'的pandas dataframe
"""
self.bert_tokenizer = bert_tokenizer
# 创建多线程池
self.pool = ThreadPoolExecutor(max_workers=max_workers)
# 获取文本与标签
def get_input(self, dataset, max_seq_len=30):
"""
通过多线程(因为notebook中多进程使用存在一些问题)的方式对输入文本进行分词、ID化、截断、填充等流程得到最终的可用于模型输入的序列。
入参:
dataset : pandas的dataframe格式,包含两列,第一列为文本,第二列为标签。标签取值为{0,1},其中0表示负样本,1代表正样本。
max_seq_len : 目标序列长度,该值需要预先对文本长度进行分别得到,可以设置为小于等于512(BERT的最长文本序列长度为512)的整数。
出参:
seq : 在入参seq的头尾分别拼接了'CLS'与'SEP'符号,如果长度仍小于max_seq_len,则使用0在尾部进行了填充。
seq_mask : 只包含0、1且长度等于seq的序列,用于表征seq中的符号是否是有意义的,如果seq序列对应位上为填充符号,
那么取值为1,否则为0。
seq_segment : shape等于seq,因为是单句,所以取值都为0。
labels : 标签取值为{0,1},其中0表示负样本,1代表正样本。
"""
sentences = dataset.iloc[:, 0].tolist()
labels = dataset.iloc[:, 1].tolist()
# 切词
tokens_seq = list(
self.pool.map(self.bert_tokenizer.tokenize, sentences))
# 获取定长序列及其mask
result = list(
self.pool.map(self.trunate_and_pad, tokens_seq,
[max_seq_len] * len(tokens_seq)))
seqs = [i[0] for i in result]
seq_masks = [i[1] for i in result]
seq_segments = [i[2] for i in result]
return seqs, seq_masks, seq_segments, labels
def trunate_and_pad(self, seq, max_seq_len):
"""
1. 因为本类处理的是单句序列,按照BERT中的序列处理方式,需要在输入序列头尾分别拼接特殊字符'CLS'与'SEP',
因此不包含两个特殊字符的序列长度应该小于等于max_seq_len-2,如果序列长度大于该值需要那么进行截断。
2. 对输入的序列 最终形成['CLS',seq,'SEP']的序列,该序列的长度如果小于max_seq_len,那么使用0进行填充。
入参:
seq : 输入序列,在本处其为单个句子。
max_seq_len : 拼接'CLS'与'SEP'这两个特殊字符后的序列长度
出参:
seq : 在入参seq的头尾分别拼接了'CLS'与'SEP'符号,如果长度仍小于max_seq_len,则使用0在尾部进行了填充。
seq_mask : 只包含0、1且长度等于seq的序列,用于表征seq中的符号是否是有意义的,如果seq序列对应位上为填充符号,
那么取值为1,否则为0。
seq_segment : shape等于seq,因为是单句,所以取值都为0。
"""
# 对超长序列进行截断
if len(seq) > (max_seq_len - 2):
seq = seq[0:(max_seq_len - 2)]
# 分别在首尾拼接特殊符号
seq = ['[CLS]'] + seq + ['[SEP]']
# ID化
seq = self.bert_tokenizer.convert_tokens_to_ids(seq)
# 根据max_seq_len与seq的长度产生填充序列
padding = [0] * (max_seq_len - len(seq))
# 创建seq_mask
seq_mask = [1] * len(seq) + padding
# 创建seq_segment
seq_segment = [0] * len(seq) + padding
# 对seq拼接填充序列
seq += padding
assert len(seq) == max_seq_len
assert len(seq_mask) == max_seq_len
assert len(seq_segment) == max_seq_len
return seq, seq_mask, seq_segment
# 类初始化
processor = DataPrecessForSingleSentence(bert_tokenizer= bert_tokenizer)
# 产生输入ju 数据
seqs, seq_masks, seq_segments, labels = processor.get_input(
dataset=data, max_seq_len=30)
# 加载预训练的bert模型
# model = BertForSequenceClassification.from_pretrained('C:\Users\LENOVO\Desktop\AI_\bert-base-chinese', num_labels=28)
model = BertForSequenceClassification.from_pretrained(r'C:\Users\LENOVO\Desktop\AI_\bert-base-chinese', num_labels=2)
#数据格式化
# 转换为torch tensor
t_seqs = torch.tensor(seqs, dtype=torch.long)
t_seq_masks = torch.tensor(seq_masks, dtype = torch.long)
t_seq_segments = torch.tensor(seq_segments, dtype = torch.long)
t_labels = torch.tensor(labels, dtype = torch.long)
train_data = TensorDataset(t_seqs, t_seq_masks, t_seq_segments, t_labels)
train_sampler = RandomSampler(train_data)
train_dataloder = DataLoader(dataset= train_data, sampler= train_sampler,batch_size = 256)
# 将模型转换为trin mode
model.train()
# 待优化的参数
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{
'params':
[p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
'weight_decay':
0.01
},
{
'params':
[p for n, p in param_optimizer if any(nd in n for nd in no_decay)],
'weight_decay':
0.0
}
]
optimizer = BertAdam(optimizer_grouped_parameters,
lr=2e-05,
warmup= 0.1 ,
t_total= 2000)
device = 'cpu'
## 存储每一个batch的loss
loss_collect = []
for i in trange(10, desc='Epoch'):
for step, batch_data in enumerate(
tqdm_notebook(train_dataloder, desc='Iteration')):
batch_data = tuple(t.to(device) for t in batch_data)
batch_seqs, batch_seq_masks, batch_seq_segments, batch_labels = batch_data
# 对标签进行onehot编码
one_hot = torch.zeros(batch_labels.size(0), 2).long()
one_hot_batch_labels = one_hot.scatter_(
dim=1,
index=torch.unsqueeze(batch_labels, dim=1),
src=torch.ones(batch_labels.size(0), 2).long())
logits = model(
batch_seqs, batch_seq_masks, batch_seq_segments, labels=None)
logits = logits.softmax(dim=1)
loss_function = CrossEntropyLoss()
loss = loss_function(logits, batch_labels)
loss.backward()
loss_collect.append(loss.item())
print("\r%f" % loss, end='')
optimizer.step()
optimizer.zero_grad()
plt.figure(figsize=(12,8))
plt.plot(range(len(loss_collect)), loss_collect,'g.')
plt.grid(True)
plt.show()
#验证集合
torch.save(model,open("fine_tuned_chinese_bert.bin","wb"))
#加载测试数据
test_data = pd.read_table('data/dev.tsv')
test_data = data.iloc[:,[3,1]]
test_data.columns = ['text','label']
# test_data = pd.read_pickle("title_category_valid.pkl")
# test_data.columns = ['text','label']
# 标签ID化
test_data['label'] = le.transform(test_data.label.tolist())
# 转换为tensor
test_seqs, test_seq_masks, test_seq_segments, test_labels = processor.get_input(
dataset=test_data, max_seq_len=30)
test_seqs = torch.tensor(test_seqs, dtype=torch.long)
test_seq_masks = torch.tensor(test_seq_masks, dtype = torch.long)
test_seq_segments = torch.tensor(test_seq_segments, dtype = torch.long)
test_labels = torch.tensor(test_labels, dtype = torch.long)
test_data = TensorDataset(test_seqs, test_seq_masks, test_seq_segments, test_labels)
test_dataloder = DataLoader(dataset= train_data, batch_size = 256)
# 用于存储预测标签与真实标签
true_labels = []
pred_labels = []
model.eval()
# 预测
with torch.no_grad():
for batch_data in tqdm_notebook(test_dataloder, desc = 'TEST'):
batch_data = tuple(t.to(device) for t in batch_data)
batch_seqs, batch_seq_masks, batch_seq_segments, batch_labels = batch_data
logits = model(
batch_seqs, batch_seq_masks, batch_seq_segments, labels=None)
logits = logits.softmax(dim=1).argmax(dim = 1)
pred_labels.append(logits.detach().numpy())
true_labels.append(batch_labels.detach().numpy())
# 查看各个类别的准召
print(classification_report(np.concatenate(true_labels), np.concatenate(pred_labels)))
参考:
腾讯视频bert模型深度修炼指南
词向量详解:从word2vec、glove、ELMo到BERT
Bert输入输出是什么