以下文章摘录自:
《机器学习观止——核心原理与实践》
京东: https://item.jd.com/13166960.html
当当:http://product.dangdang.com/29218274.html
(由于博客系统问题,部分公式、图片和格式有可能存在显示问题,请参阅原书了解详情)
————————————————
版权声明:本文为CSDN博主「林学森」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xuesen_lin/
1.1 Tensorflow分布式训练
1.1.1 Tensorflow的分布式原理
1.1.1.1 Google DisBelief
我们分析tensorflow的分布式原理,不得不先提到Google的另一个系统DisBelief——因为tensorflow的一些分布式核心理念都来源于后者。简单来讲,DisBelief是Google内部开发的第一代面向深度学习的分布式系统。虽然DisBelief具备较好的扩展性,但它对一些研究场景的支持却不够灵活,所以Google才又设计出了第二代深度学习分布式系统——也就是大家所熟知的TensorFlow。它相比第一代系统不仅速度更快,更为灵活,而且更能满足新的研究场景需求。据悉这两套系统都被广泛应用于Google的技术产品中,例如语音识别,图像识别及翻译等。
在DisBelief的设计框架中,主要包含了如下两个核心元素:
l Parameter servers
Parameter servers负责保存和更新模型状态(例如参数),同时可以根据worker计算出的梯度下降数值来更新参数
l Worker replicas
Worker replicas的主要任务是执行具体的计算工作,它会计算神经网络的loss函数以及梯度下降值
Tensorflow作为Google的第二代深度学习分布式系统,不但很好地继承了DisBelief的上述设计,而且做了不少功能上的扩展改进和性能上的优化。例如在灵活性方面,Tensorflow与DisBelief最大的区别在于:后者的ps和worker是两个不同的程序,而在tensorflow中ps和worker的运行代码几乎完全相同。
DisBelief的核心实现可以参考下图的描述。
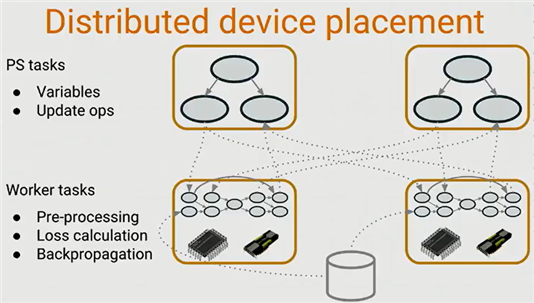
图 ‑ Google DisBelief系统
引用自Tensorflow dev summit
下图是Tensorflow的分布式示意图:
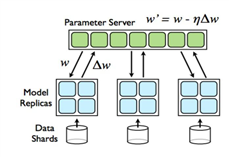
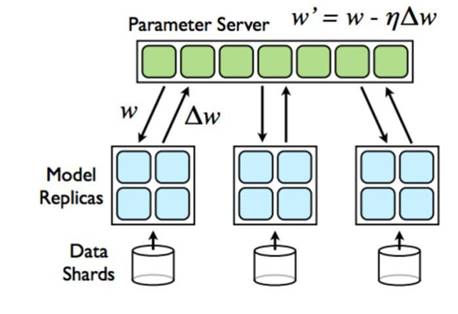
图 ‑ Tensorflow分布式示意图
1.1.1.2 分布式TF的基本概念
我们先针对tensorflow分布式实现中的几个重要概念进行讲解,这样大家后续再遇到它们时就不会“一头雾水”了。
(1) Tensorflow Cluster
Tensorflow cluster指的是一系列针对graph进行分布式计算的task任务,其中每一个task又和server相关联——而server则包含了一个用于创建session的master节点和一个用于graph计算的worker节点。
(2) Task
前面我们提到了Cluster是task的集合,大家肯定会有疑问——那么task又是什么呢?简单来讲,task就是主机上的一个进程。而且大多数情况下,一台机器只运行一个task。
(3) Job
Tensorflow的一个cluster也可以被划分为1个或者多个jobs,然后每个job则包含了1个或者多个tasks,所以job是task的集合。那么为什么会有job这个概念,它想解决什么样的问题呢?
这是因为在分布式深度学习框架中,存在两种job——即Parameter Job和Worker Job。根据之前的讲解,我们应该知道前者用于执行参数的存储和更新工作,而后者则负责实际的图计算。当参数数量太大时,就需要多个tasks来协同了。
(4) Parameter server和Worker replicas
Parameter server和worker replicas的概念我们在前面DisBelief小节已经做过解释,这里就不再赘述了。
(5) Client
Client一般由Python或者C++编写,它通过构建Tensorflow graph和Session来与cluster交互。
(6) Master service
Master service实现了tensorflow::Session接口,同时负责协调1或3个worker services。
(7) Worker service
Worker service实现了worker_service.proto,它利用本地设备来执行Tensorflow graph中的一部分。Tensorflow中的所有server都会实现Master service和Worker service。
如下示意图所示:
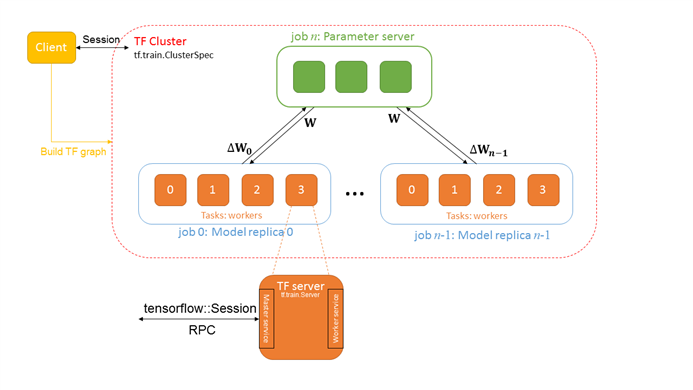
图 ‑ Tensorflow分布式核心元素示意图
1.1.2 单机多GPU下的并行计算
Tensorflow相比于其它机器学习平台的一个明显优势还在于其强大的并行计算能力。那么应该怎么理解这个“并行”的概念呢?通俗来讲,“并行”就是指任务可以被拆分成多份,同步执行计算过程,从而有效降低任务耗时。
不过在机器学习这个场景下,我们认为“并行”还可以被进一步细分。下面我们为大家逐一分析各种可能的Tensorflow程序的运行情况。
(1) 一对一的情况(任务不拆分)
也就是1个任务(不拆分)在1个CPU/GPU上运行的情况,此时并不涉及并行计算。如下示例图所示:
图 ‑ 一对一的情况(任务不拆分)
那么我们怎么指定一个Task是在CPU上或者GPU上运行呢?事实上Tensorflow已经帮大家充分考虑到了这一点,并提供了tf.device接口来满足开发者的需求。而且Tensorflow还提供了log_device_placement选项来打印出每步运算操作的硬件承载体。
下面我们结合范例来做详细讲解。如下代码段所示:
import tensorflow as tf
var_a = tf.constant([2], name='var_a')
var_b = tf.constant([3], name='var_b')
var_c = var_a + var_b
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print (sess.run(var_c))
如果你的tensorflow程序是在CPU上执行了的话,那么会有类似如下的输出:
Device mapping: no known devices.
add: (Add): /job:localhost/replica:0/task:0/device:CPU:0
var_b: (Const): /job:localhost/replica:0/task:0/device:CPU:0
var_a: (Const): /job:localhost/replica:0/task:0/device:CPU:0
…
而如果是在GPU上执行了的话,输出就变成了:
Device mapping:
/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: GeForce GT 650M, pci bus id: 0000:01:00.0, compute capability: 3.0
add: (Add): /job:localhost/replica:0/task:0/device:GPU:0
var_b: (Const): /job:localhost/replica:0/task:0