
环境:Win11x64+Vscode+Python3.7.2x64+Pytorch1.9(CPU or GPU)
本文默认Win11,Win10 100%素可以得,默认向下兼容!
首先,你得把Vscode弄好(python 插件安装),py环境搭好,我们用默认得base py环境即可,当然,你也可以在conda创建py环境
然后在https://huggingface.co/speechbrain/asr-transformer-aishell/tree/main,下载

下载完自己改文件名以及后缀,改得和这个框内一模一样的(必须)!
然后vscode创建py工程文件夹,在里面新建pretrained_models/asr-transformer-aishell文件夹,把下载的全部丢进去:
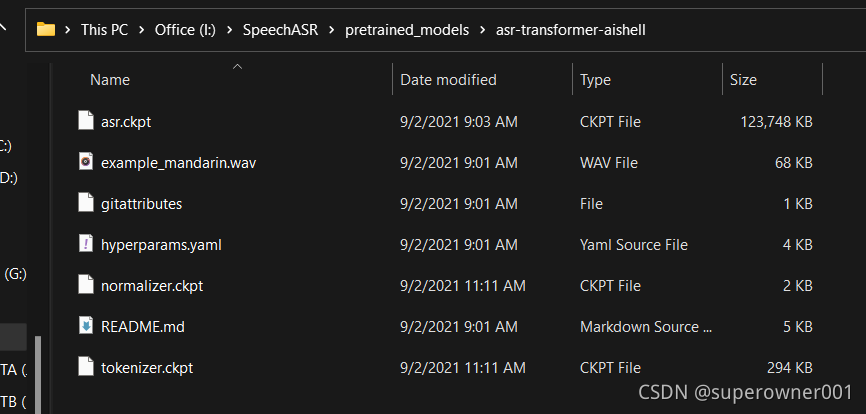
pip安装环境:
pip install speechbrain
PS:这个命令会安装90%的环境(默认安装 cup版 Pytorch),但是还有一个没得装,就是torchaudio后端,因为这个torchaudio就是一个套壳api,所以手动安装SoundFile或SoX后端,如果已安装可以跳过
pip install SoundFile
or
pip install sox
然后。。。
参考谷歌在线代码编辑器
https://colab.research.google.com/drive/1hX5ZI9S4jHIjahFCZnhwwQmFoGAi3tmu?usp=sharing#scrollTo=OKI0SovKtbZm
我们创建py脚本:
from speechbrain.pretrained import EncoderDecoderASR
import torch
import torchaudio
# https://huggingface.co/speechbrain/asr-transformer-aishell/tree/main
# https://colab.research.google.com/drive/1hX5ZI9S4jHIjahFCZnhwwQmFoGAi3tmu?usp=sharing#scrollTo=PPB0K9z3B43c
//PS:CPU版本和GPU版本Pytorch加载参数不同,具体参考下面谷歌在线代码
asr_model = EncoderDecoderASR.from_hparams(source="speechbrain/asr-transformer-aishell", savedir="pretrained_models/asr-transformer-aishell")
# asr_model.transcribe_file("speechbrain/asr-transformer-aishell/example_mandarin.wav")
audio_1 = "F:/CSharpProject/KaldiDemo/KaldiDemo/bin/x64/Release/妹妹就是爱.flac"
#error:No audio IO backend is available
#安装SoundFile : 运行指令 pip install SoundFile
#or者安装SoX : 运行指令: pip install sox
ddd=torchaudio.list_audio_backends()
print(ddd)
snt_1, fs = torchaudio.load(audio_1)
wav_lens=torch.tensor([1.0])
print('snt_1:',snt_1," wav_lens:",wav_lens)
res=asr_model.transcribe_batch(snt_1, wav_lens)
print('res:',res)
#对于用GPU版pytorch的小伙伴,加载模型可以参考以下代码
# Uncomment for using another pre-trained model
#asr_model = EncoderDecoderASR.from_hparams(source="speechbrain/asr-crdnn-rnnlm-librispeech", savedir="pretrained_models/asr-crdnn-rnnlm-librispeech", run_opts={"device":"cuda"})
#asr_model = EncoderDecoderASR.from_hparams(source="speechbrain/asr-crdnn-transformerlm-librispeech", savedir="pretrained_models/asr-crdnn-transformerlm-librispeech", run_opts={"device":"cuda"})
asr_model = EncoderDecoderASR.from_hparams(source="speechbrain/asr-transformer-transformerlm-librispeech", savedir="pretrained_models/asr-transformer-transformerlm-librispeech", run_opts={"device":"cuda"})
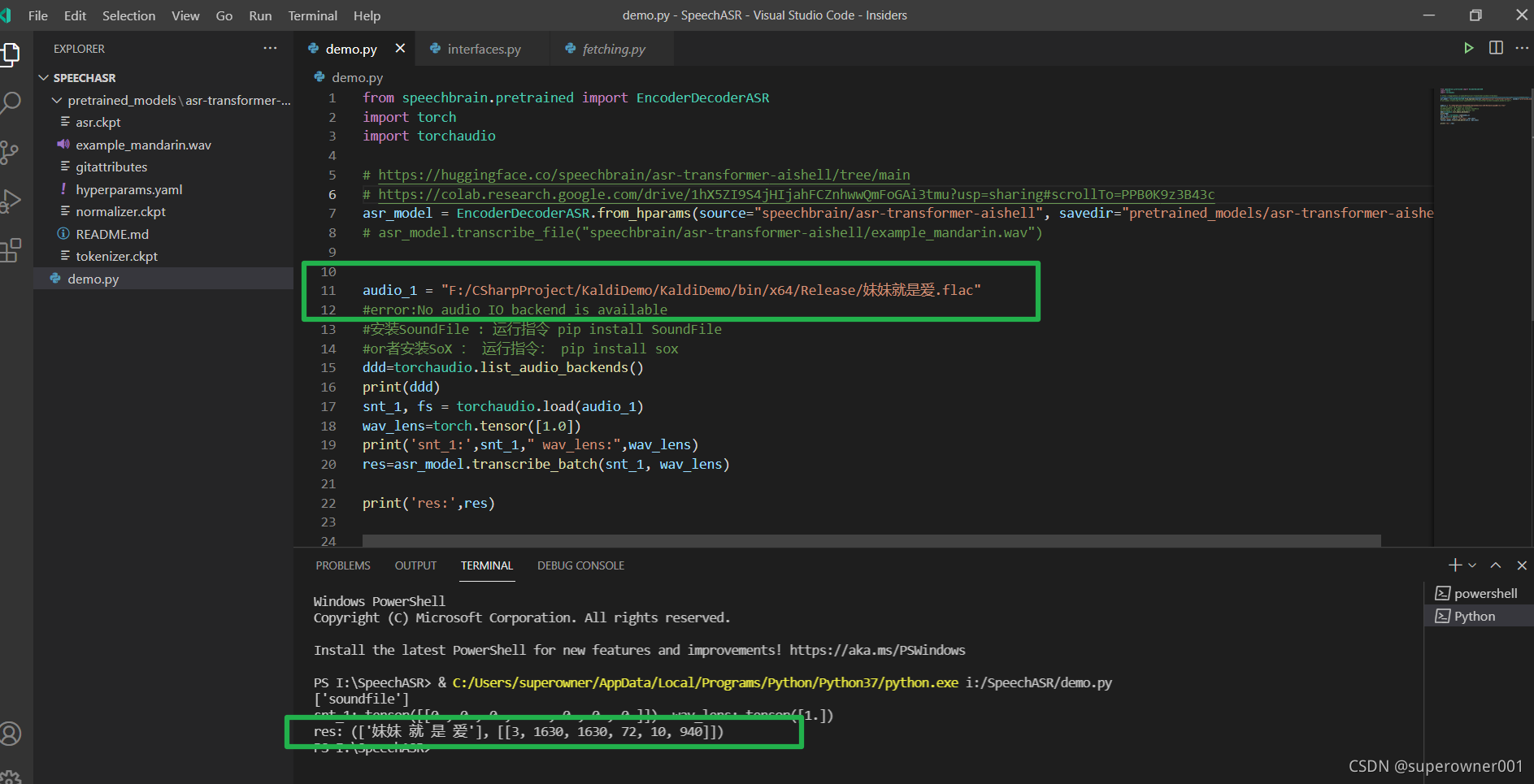
PS:这个识别效率还是灰常高的,在cpu下都很快,gpu应该会更快!
如果你素这样类似得输出,那么恭喜你,你の手中已经抓住了未来

完整代码和模型文件我已经上传群共享和CSDN,想学习的进群,不想的自己TB几毛钱买个代下即可
https://download.csdn.net/download/weixin_44029053/32726942
安装好pytorch和Python环境,vscode设置Python程序根目录直接运行,不需要改任何代码
下一步,我们要用这个来训练我们的唤醒词,进行语音唤醒实战,敬请期待我的博客,记得三连(没有)!
PS:本人并非语音方面专业人士,不过也在学习,大家可以加群一起探讨一下,集思广益,群号:558174476(游戏与人工智能生命体)