一、概述
- 软件界一直希望建立一种可重复利用的东西;
- c++的面向对象和泛型编程思想,目的是复用性的提升
- 大多情况下,数据结构和算法都未能有一套标准,导致被迫从事大量重复工作
- 建立数据结构和算法的一套标准,所以诞生了STL
二、STL基本概念
- STL(标准模板库),是一种泛型编程。面向对象编程关注的是编程的数据方面,而泛型编程关注的是算法,它们之间的共同点是抽象和创建可重用代码,但理念决然不同。
- 泛型编程旨在编写独立于数据类型的代码。在c++中,完成通用程序的工具是模板。模板使得能够按泛型定义函数或类,而STL通过通用算法更进了一步。模板让这一切成为可能。
- STL三大组件:容器,算法,迭代器;(算法操作数据,容器存储数据,迭代器是算法操作器的桥梁,迭代器和容器一一对应)
- STL几乎所有的代码都采用了模板或模板函数。

三、STL六大组件
六大组件:
- 容器:各种数据结构,是一个概念化的抽象基类,容器不真正使用继承机制,容器概念指定了所有STL容器类都必须满足的一系列要求。如:vector,list,deque,set,map等,用来存放数据;
- 算法:各种常用的算法,如:sort,find,copy,for_each等;
- 迭代器:容器和算法直接的桥梁;
- 仿函数:为算法提供更多的策略;
- 适配器:为算法提供更多的参数接口;
- 空间适配器:管理容器和算法的空间;
四、STL中容器,算法,迭代器
1.容器:容器是存储其他对象的对象,被存储的对象必须是同一种类型的,它们可以是面向对象意义上的对象,也可以是内置类型值。STL容器就是将运用最广泛的一些数据结构实现出来,常用的数据结构:数组,链表,树,队列,集合,映射表等;容器分为:序列式容器和关联式容器:

不能将任何类型的对象存储在容器中,类型必须是可复制构造的和可赋值的。基本类型满足。 类定义没有将复制构造函数和赋值运算符声明为私有或保护的,也满足。 c++11改进了这些概念,添加术语可复制插入和可移动插入。
基本类型不能保证其元素都按特定的顺序存储,也不能保证元素的顺序不变,但概念进行改变进行后,则可以增加这样的保证。
所有的容器都提供某些特征和操作。下表是一些特征进行了总结。X:容器;T:对象类型;a,b:类型为X的值;r:类型为X&的值;u:类型为X的标识符。

五、C++11新增的容器种类
下图列出新增的通用容器要求,rv表示类型为X的非常量右值,如函数的返回值。另外,要求X::iterator满足正向迭代器的要求,而以前只要求它不是输出迭代器。
复制构造和复制赋值以及移动构造和移动赋值之间的区别在于,复制操作保留源对象,而移动操作可修改源对象,还可能转让所有权,而不做任何复制。如果源对象是临时的,移动操作的效率将高于常规复制。
六、序列
- 添加要求来改进基本的容器概念。序列就是重要的改进。因为STL(
deque,forward_list,list,queue,priority_queue,stack,vector,array(虽然不满足序列要求))都是序列。
- 序列概念增加迭代器至少是正向迭代器这样的要求,保证元素按特定顺序排列。
- 序列要求元素按严格的行线顺序排列,即存在第一个元素和最后一个元素,除第一和最后元素外,每个元素前后都分别有一个元素。数组和链表都是序列,分支结构不是。
- 序列都有确定的顺序,因此可以执行诸如将值插入到特定位置,删除特定区间等操作。
下表列出这些操作以及序列必须完成的其他操作。(t:类型为T的值,n表示整数,p,q,i,j:迭代器)

模板类deque,list,queue,priority_queue,stack,vector都是序列概念的模型,所以都支持上表的运算符。且还可以使用其他操作。

注:
a[n]和a.at(n)都返回一个指向容器中第n个元素的引用,之间区别在于,如果n落在容器的有效区间外,则a.at(n)将指行边界检查,引发out_of_range异常。
为什么vector没有定义push_front(),假设将一个新值插入到变化100个元素的矢量的最前面,必须将第99个移100,把98移到99,依次类推,这种操作的复杂为线性时间,因为移动100个元素时间是单个的100倍,但表中操作被假设为仅其复杂度为固定时间才被发现。
链表和双端列队列的设计允许将元素添加到前端,而不用移动其他元素,所以它们以固定时间的复杂度来实现push_front()。
七、算法
有限的步骤,解决逻辑或数学上的问题,叫算法,算法分为:质变算法和非质变算法。
- 质变算法:是指运算过程中会更改区间内的元素的内容。例如:拷贝,替换,删除等等。
- 非质变算法:是指运算过程中不会更改区间内的元素内容,例如:查找,计算,遍历,寻找极值等等。
八、迭代器
迭代器是STL的关键,模板使得算法独立于存储的数据类型,而迭代器使算法独立于使用的容器类型,因此,都是STL通用方法的重要组成部分。迭代器能够用来遍历容器的对象,与能够遍历数组的指针类似,是广义指针。
1.迭代器的种类

2.随机访问迭代器
X:随机迭代器类型;T:指向的类型;a,b:迭代器值;n:整数;r:随机迭代器变量或引用。 有些算法要求能够直接跳到容器的任何一个元素,这叫随机访问,需要随机迭代器。随机访问迭代器具有双向迭代器的所有特性,同时添加了支持随机访问的操作和用于对元素进行排序的关系运算符。上图也支持随机访问迭代器。
有些算法要求能够直接跳到容器的任何一个元素,这叫随机访问,需要随机迭代器。随机访问迭代器具有双向迭代器的所有特性,同时添加了支持随机访问的操作和用于对元素进行排序的关系运算符。上图也支持随机访问迭代器。
3.迭代器层次结构
迭代器类型形成了一个层次结构。正向迭代器具有输入迭代器和输出迭代器的全部功能,同时还有自己的功能。双向迭代器具有正向迭代器的全部功能,同时还有自己的功能;随机访问迭代器具有正向迭代器的全部功能,同时还有自己的功能。下图总结了主要迭代器功能:i:迭代器;n:整数;

注:各种迭代器的类型并不确定,而只是一种概念性叙述。
九、概念,改进和模型
- 概念可以具有类似继承的关系。例如:双向迭代器继承了正向迭代器的功能。
- 不能将c++继承机制用于迭代器。例如:可以将迭代器实现一个类,而将双向迭代器实现为一个常规指针。因此,对C++而言,这种双向迭代器是一种内置类型,不能从类派生而来。
- 概念上看,STL确实能够继承,有些STL文献使用术语改进来表示这种概念上的继承,因此,双向迭代器是对正向迭代器概念的一种改进。
- 概念的具体实现被称为模型。因此,指向int的常规指针是一个随机访问迭代器模型,也是一个正向迭代器模型,因为它满足该概念的所有要求。
十、将指针用作迭代器
迭代器是广义指针,而指针满足所有的迭代器要求。迭代器是STL算法的接口,而指针是迭代器,因此STL算法可以使用指针来对基于指针的非STL容器进行操作。
例如:可将STL算法用于数组,假设Receipts是一个double数组,并要按升序对它进行排序:
const int SIZE=100;
double Receipts[SIZE];
STL sort()函数接受指向容器第一个元素和迭代器和指向超尾的迭代器作为参数。&Receipts[0]是第一个元素的地址,&Receipts[SIZE](或Receipts+SIZE)是数组最后一个元素后面的元素的地址。因此,下面的函数调用对数组进行排序:
sort(Receipts,Receipts+SIZE);
c++确保了表达式Receipts+n是被定义的,只要该表达式的结果位于数组中。只要该表达式的结果位于数组中,因此c++支持将超尾概念用于数组,使得可以将STL算法用于常规数组。只要提供适当的迭代器和超尾指示器即可。
copy(),ostream_iterator和istream_iterator
STL提供预定义迭代器。可以将数据从一个容器复制到另一个容器中。甚至可以在数组之间复制,因为可以将指向数组的指针用作迭代器。例如:
int casts[10]={6,7,9,4,11,8,7,10,5};
vector <int> dice[10];
copy(casts,casts+10,dice.begin());
将信息复制到显示器上,如果有一个表示输出流的迭代器,则可以使用copy()。STL为这种迭代器提供了ostream_iterator模板。这也是个适配器:一个类或函数,可以将其他接口转换为STL使用的接口。包含头文件:iterator,并作下面的声明来创建这种迭代器:
#include<iterator>
...
ostream_iterator<int,char>out_iter(cout," ");
out_iter迭代器现在是个接口,能使用cout显示信息。int参数:输出流的数据类型;char参数:输出流使用的字符类型。构造函数的第一个参数(指cout)指出了要使用的输出流,最后一个字符串参数是在发送给输出流的每个数据项后显示的分隔符。
可以这样使用迭代器:
*out_iter++=15;
常规指针表示15赋给指针指向的位置,然后指针加1.但ostream_iterator表示将15和空格组成的字符串发送到cout管理的输出中。可以将copy()用于迭代器,例:
copy(dice.begin(),dice.end(),ostream_iterator<int,char>(cout," "));
iterator头文件还定义个istream_iterator模板,使istream输入可用作迭代器接口。它是个输入迭代器概念的模型,可以使用两个istream_iterator对象来定义copy()的输入范围:
copy(istream_iterator<int,char>(cin),
istream_iterator<int,char>(),dice.begin());
与ostream_iterator相似,istream_iterator也使用两个模板参数。
十一、其他有用的迭代器
除了ostream_iterator和istream_iterator之外,头文件iterator还提供其他专用的预定义迭代器类型:reverse_iterator,back_insert_iterator,front_insert和insert_iterator。
对reverse_iterator 执行递增操作将导致它被递减。为什么不直接对常规迭代器进行递减?因为为了简化对已有的函数的使用。假设要显示dice容器的内容,正如上面介绍的,可以使用copy()和ostream_iterator来将内容复制到输出流中:
ostream_iterator<int,char>out_iter(cout," ");
copy(dice.begin(),dice.end(),out_iter);//向前显示
假设要打印容器的内容,很多方法不管用,但vector类提供个名为rbegin()的成员函数和一个名为rend()的成员函数,前者返回一个指向超尾的反向迭代器,后者返回个指向第一个元素的反向迭代器。
因为对迭代器执行递增操作将导致它被递减,所以可以使用下面的语句显示:
copy(dice.rbegin(),dice.rend(),out_iter);//相反顺序显示
甚至不必声明反向迭代器。
注:rbegin()和end()返回相同的值(超尾),但类型不同(reverse_iterator和iterator),rend()和begin()也返回相同的值(指向第一个元素的迭代器),但类型不同。
必须对反向指针做一种特殊补偿,假设rp是一个被初始化为dice.rbegin()的反转指针。那么*rp是声明什么呢?因为rbegin()返回超尾,因此不能对该地址进行解除引用。
若rend()是第一个元素的位置,则copy()必须提早一个位置停止,因为区间的结尾不包括在区间中。
反向指针通过先递减,在解除引用解决了这两个问题。即*rp将在*rp的当前值之前对迭代器执行解除引用。也就是说,如果rp指向位置6,则*rp将是位置5的值,依次类推。
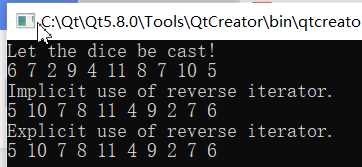
下面程序演示如何使用copy(),istream迭代器和反向迭代器。
#include <iostream>
#include<iterator>
#include<vector>
using namespace std;
int main()
{
int casts[10]={6,7,2,9,4,11,8,7,10,5};
vector<int>dice(10);
copy(casts,casts+10,dice.begin());
cout<<"Let the dice be cast!\n";
ostream_iterator<int, char>out_iter(cout," ");
copy(dice.begin(),dice.end(),out_iter);
cout<<endl;
cout<<"Implicit use of reverse iterator.\n";
copy(dice.rbegin(),dice.rend(),out_iter);
cout<<endl;
cout<<"Explicit use of reverse iterator.\n";
vector<int>::reverse_iterator ri;
for(ri=dice.rbegin();ri !=dice.rend();++ri)
cout<<*ri<<' ';
cout<<endl;
return 0;
}
如果可以在显示声明迭代器和使用STL函数来处理内部问题(通过将rbegin()返回值传递给函数)直接选择,应该采用后者。
另外三种迭代器(back_insert_iterator,front_insert_iterator和insert_iterator)也将提高STL算法的通用性,很多STL函数都与copy()相似,将结果发送到输出迭代器指示的位置。下面的语句将值复制到从dice.begin()开始的位置:
copy(casts,casts+10,dice.begin());
注:如果dice有足够空间,能够容纳这些值,即copy()不能自动根据发送值调整目标容器的长度。如果不知道dice长度或者将元素添加到dice中,而不覆盖已有的内容,又怎么办呢?
三种插入迭代器通过将复制转换为插入解决这些问题。插入将添加新的元素,而不覆盖已有的数据,并使用自动内存分配来确保能够容纳新的信息。
-
back_insert_iterator :将元素插入到容器尾部。
-
front_insert_iterator:将元素插入到容器的前端。
-
insert_iterator:将元素插入到insert_iterator构造函数的参数指定的位置前面。
三个都是输出容器概念的模型。
这里存在一些限制:
-
back_insert_iterator只能用于允许在尾部快速插入的容器,vector类符合这种要求。
-
front_insert_iterator只能用于允许在起始位置做时间固定插入的容器类型,vector类不能满足这种要求,但queue满足。
-
insert_iterator没有这些限制,所以用它把信息插入到矢量的前端。
-
front_insert_iterator对于那些支持他的容器来说没完成任务速度更快。
提示:可以用insert_iterator将复制数据的算法转换为插入数据的算法。
这些迭代器将容器类型作为模板参数,将实际的容器标识作为构造函数参数。也就是说,要为名为dice的vector<int>容器创建一个back_insert_iterator,这样做:
back_insert_iterator<vector<int> >back_iter(dice);
必须声明容器的类型原因是,迭代器必须使用合适的容器方法。back_insert_iterator的构造函数将假设传递给它的类型有一个push_back()方法。copy()是个独立的函数,那样调整容器大小的权限。但back_iter能够使用方法vector<int>::push_back(),该方法有权限。
声明front_insert_iterator的方式与此相同 ,对于insert_iterator声明,还需一个指示插入位置的构造函数参数:
insert_iterator<vector<int> >insert_iter(dice,dice.begin());
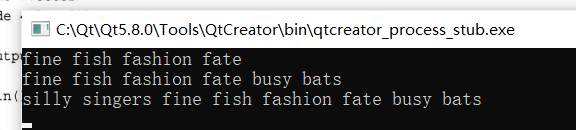
下面程序演示了这两种迭代器的用法,还使用for_each而不是ostream迭代器进行输出。
#include <iostream>
#include<iterator>
#include<string>
#include<vector>
#include<algorithm>
using namespace std;
void output(const string & s)
{
cout<<s<<" ";
}
int main()
{
string s1[4]={"fine","fish","fashion","fate"};
string s2[2]={"busy","bats"};
string s3[2]={"silly","singers"};
vector<string>words(4);
copy(s1,s1+4,words.begin());//从s1复制4个字符串到words
for_each(words.begin(),words.end(),output);
cout<<endl;
//构造匿名back_insert_iterator 对象
copy(s2,s2+2,back_insert_iterator<vector<string> >(words));//back_insert_iterator将s2中的字符串插入到words数组末尾,将words的长度增加到6个元素。
for_each(words.begin(),words.end(),output);
cout<<endl;
//构造匿名insert_iterator对象
copy(s3,s3+2,insert_iterator<vector<string> >(words,words.begin()));//insert_iterator将s3中的两个字符串插入到words的第一个元素的前面,将words的长度增加到8个元素。
for_each(words.begin(),words.end(),output);
cout<<endl;
return 0;
}
注:程序试图使用words.end()和words.begin()作为迭代器,将s2和s3复制words中,words将没有空间来存在新数据,程序可能由于内存违规而异常终止。