前言
虽然名字带有回归,但实际上是一个常用的二分类算法,并且在预测的时候能够提供预测类别的概率。
一、逻辑回归能够解决什么?
逻辑回归可以很好的解决连续的线性函数无法很好的分类的问题,如图所示,左侧为线性回归,右侧为逻辑回归。
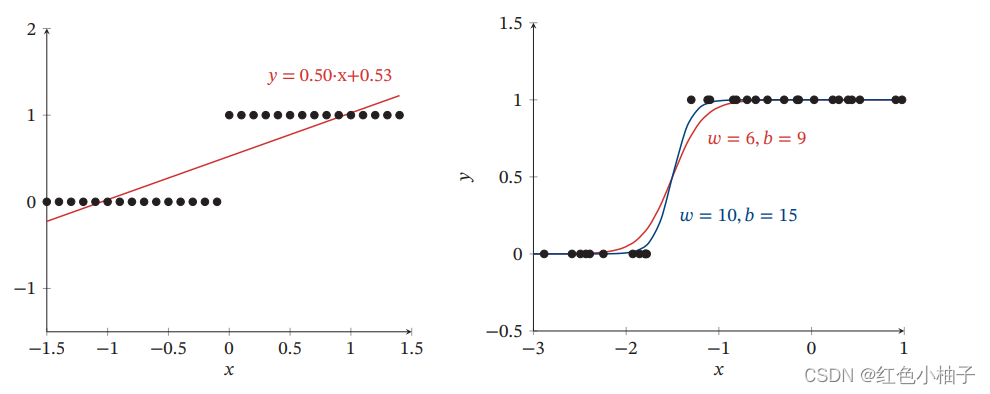
二、公式

p的含义为输入x为类别1的概率,其中因为是二分类,那么0和1的概率和为100%。f(x;w)为连续的线性函数,其中g(x)是激活函数,将f()函数的值映射到(0,1)区间,这样图像看起来是个非线性的,本质上是个线性函数。
三、激活函数
g(x) = 1/(1+exp(-x))
四、如何求得w
通常都是通过求得损失函数1的最小值,来确定的。这个就要利用到求偏导的知识。逻辑回归的损失函数通常是交叉熵函数,公式如下所示:
 显然R(w)>0,所以求得最优参数w,使得R(w)在训练数据上达到最小。当然他的泛化能力2可能并不够好。比如存在训练数据测试模型情况良好,但是测试集的情况较差,这种情况叫做过度拟合3,一般可以引入正则化和增加数据量解决问题,甚至更换模型。求导公式如下:
显然R(w)>0,所以求得最优参数w,使得R(w)在训练数据上达到最小。当然他的泛化能力2可能并不够好。比如存在训练数据测试模型情况良好,但是测试集的情况较差,这种情况叫做过度拟合3,一般可以引入正则化和增加数据量解决问题,甚至更换模型。求导公式如下:
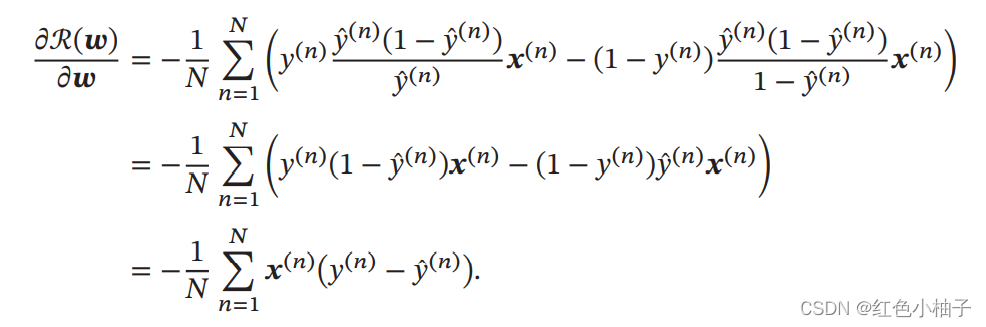 然后采用梯度下降法求得最优w:
然后采用梯度下降法求得最优w:
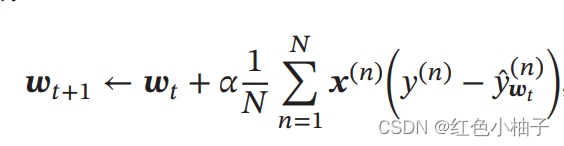 当R的偏导数接近0时,参数w的更新就可以停止了,或者模型在训练集上的表现足够 了。
当R的偏导数接近0时,参数w的更新就可以停止了,或者模型在训练集上的表现足够 了。
六、逻辑回归代码实现
1.需要的类库
import numpy as np
2.根据当前权重求得训练集的预测值
def perdict(w,x): #根据权重和逻辑函数求解最新的预测值,x为单个数据
if len(w) != len(x):
print("w和x的维度不一致")
return None
z=0
for index in range(len(w)):
z = z + w[index]*x[index]
y = (1+np.e**-(z))**-1
return y
3.根据梯度下降的原则更新权重,其中默认学习率为1
def upadteWeight(oldW, data, predict, label): #按照梯度下降的原则更新权重
offset = np.array([np.array(data[i]) * (label[i] - j) for i,j in enumerate(predict)])
offset = np.array([np.sum(offset[...,index]) for index in range(len(w))])/len(data)
newW = oldW + offset
return newW
4.主函数代码
if __name__ == '__main__':
data = [[1,0,1],[2,0,1],[3,0,1],[8,9,1],[9,9,1],[10,9,1]]
label = [0, 0, 0, 1, 1, 1]
w = [0,0,0]
while True:
predicts = [perdict(w,index) for index in data]
w=upadteWeight(w, data, predicts, label)
if sum(predicts[:3])<0.5 and sum(predicts[3:])>2: #设置更新退出条件,前三个的预测值足够第(代表类别为0),后三个预测足够高(类别为1)
break;
print("w:", w)
print("predict:", predicts)
print(perdict(w,[10,8,1]))
5.输出值
w: [-0.56732993 2.25000171 -1.13759567]
predict: [0.17761696203138966, 0.12020865794870537, 0.07956042920866521, 0.9999998167243579, 0.9999997102930378, 0.9999995420552467]
0.9999861763887856
五、sklearn demo
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer # 乳腺癌数据集
from sklearn.model_selection import train_test_split
if __name__ == '__main__':
data=load_breast_cancer() #加载数据集
X =data['data'] #数据
Y = data['target'] #标签
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.3,random_state=1) #划分测试集和训练集
l1 = LogisticRegression(penalty="l1",C=0.5,solver="liblinear") #配置逻辑回归,penalty为正则化,solver为求解w的方法
l1.fit(X_train,Y_train)
score = l1.score(X_test,Y_test)
print(score)
输出:0.94
总结
加油!!!!!!
-
损失函数通常是度量算法的预测准确性,通过模型预测值和真实值比较。
-
泛化能力指的是,模型通用性的能力,简单的说是预测新的数据的能力。
-
通常是由训练数据过少,和模型复杂能力太强引起。