CUDA
官方教程:CUDA C++ Programming Guide (nvidia.com)
一、基础知识
首先看一下显卡、GPU、和CUDA的关系介绍:
显卡、GPU和CUDA简介_吴一奇的博客-CSDN博客
延迟:一条指令返回的时间间隔;
吞吐量:单位时间内处理的指令数量;
CPUs
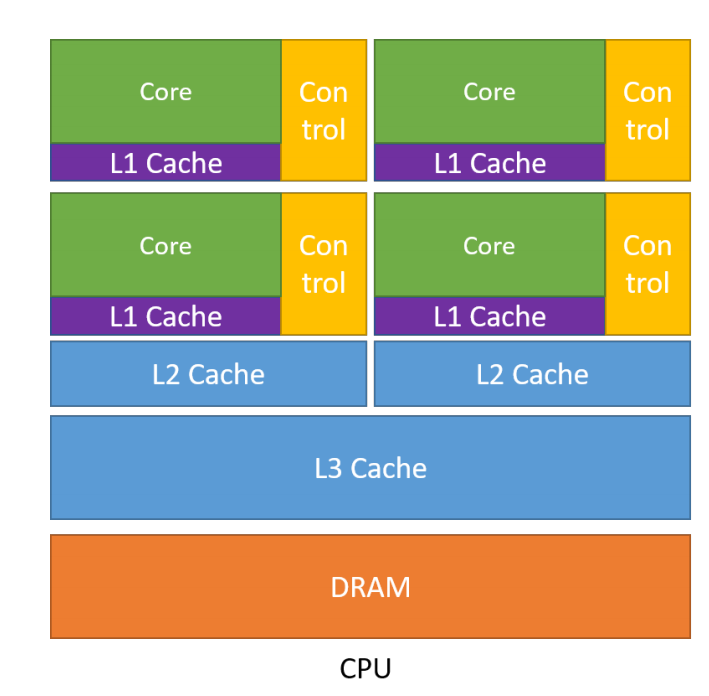
设计是按照延迟导向设计的;
主要有以下几个特点:
1、内存大:多级缓存结构提高访存速度;
2、控制复杂:分支预测机制(if-else判断)、流水线数据前送;
3、运算单元强大:整型浮点型复杂运算速度快;
GPUs
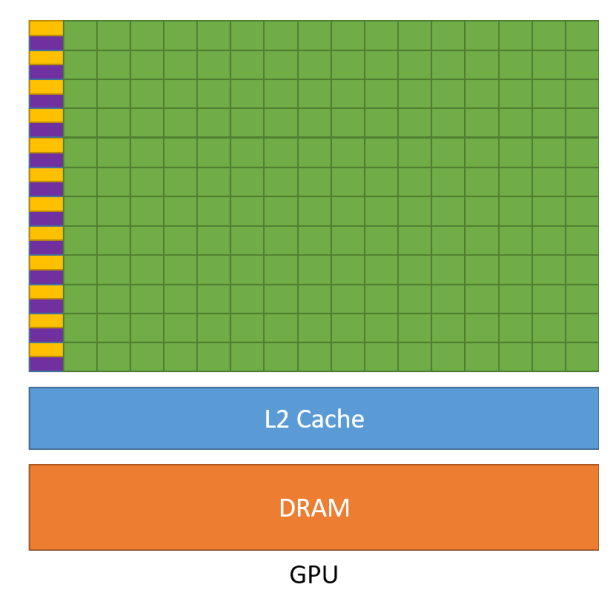
设计是按照吞吐导向设计的;
主要有以下几个特点:
1、缓存小:提高内存吞吐;
2、控制简单:没有分支预测,没有数据转发;
3、精简运算单元:需要大量线程来容忍延迟,流水线实现高吞吐量;
注意:显存其实和内存一样,也是用来暂存资料的存储空间,不过显存是帮GPU存储的,而内存是帮CPU存储的;
总结:
CPU相比于GPU,单条复杂指令延迟快10倍以上;
GPU相比于CPU,单位时间执行指令数量10倍以上;
思考:
什么样的问题适合GPU?
计算密集:数值计算的比例要远大于内存操作,因此内存访问的延迟可以被计算掩盖;
数据并行:大任务可以拆解成执行相同指令的小任务,因此对复杂流程的需求控制较低;
CUDA
CUDA:由英伟达公司2007年开始推出,初衷是为GPU增加一个易用的编程接口,让开发者无需学习复杂的着色语言或者图形处理原语;
OpenCL:是2008年发布的异构平台并行编程的开放标准,也是一个编程框架;
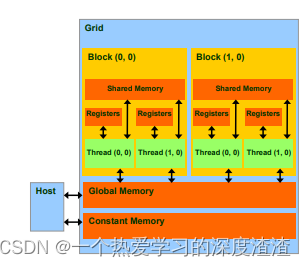
下面是CUDA编程的具体结构图:
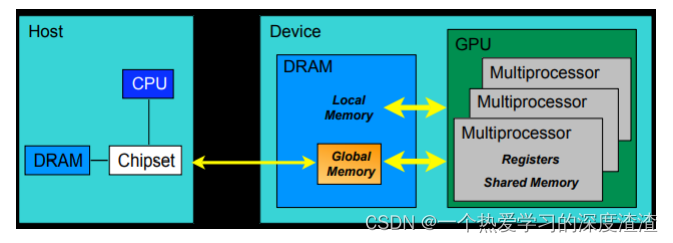
其中Device代表GPU,Host代表CPU,Kernel代表GPU上运行的函数;
术语:内存模型的层次:
- 每个线程处理器(SP)都有自己的registers(寄存器)
- 每个SP都有自己的local memory(局部内存),寄存器和局部内存只能被线程自己访问;
- 每个多核处理器(SM)内都有自己的shared memory(共享内存),可以被线程块内所有线程访问;
- 一个GPU的所有SM共有一块global memory(全局内存),不同线程块的线程都可使用;
术语:软件:
在CUDA中,具体对应结构如下
线程处理器(SP)对应线程;
多核处理器(SM)对应线程块;
设备端(device)对应线程块组合体;
一个kernel一次只能在一个GPU上执行;
线程块的概念:
将线程数组分成多个块,块内的线程通过共享内存、原子操作和屏障同步进行协作,不同块中的线程不能协作;
网格(grid)并行线程块组合的概念:
CUDA中的核函数由线程网格执行,每个线程都有一个索引,用于计算内存地址和做出控制决策;
对于每个线程需要处理的数据,是通过对线程块和线程定义具体的id,根据索引来决定要处理的数据;
线程束(warp)概念:
SM采用的SIMT(单指令多线程)架构,warp(线程束)是最基本的执行单元,一个warp包含32个并行thread,这些thread以不同数据资源执行相同的指令,warp本质是线程在GPU上运行的最小单元;
当一个kernel被执行时,grid中的线程块被分配到SM上,一个线程块的thread只能在一个SM上调度,SM一般可以调度多个线程块,大量thread可能被分到不同的SM上,每个thread拥有它自己的程序计数器和状态寄存器,并且用该线程自己的数据执行指令,这就是所谓的SIMT;
由于warp的大小为32,所以block所含的thread的大小一般要设置为32的倍数;

案例:向量相加
说明:向量相加满足GPU运行的条件,计算简单且支持并行,内存访问也少;
在CPU中实现两个向量的相加:
void vecAdd(float* A, float* B, float* C, int n)
{
for (i = 0, i < n, i++)
C[i] = A[i] + B[i];
}
需要利用循环,依次对两个向量中的数据进行相加,再将结果保存在新的向量中;
在GPU中实现两个向量的相加:
主要分为以下几个步骤:
-
为数据分配内存空间
cudaError_t cudaMalloc (void **devPtr, size_t size):两个参数为地址、申请内存大小;
作用:在设备全局内存中分配对象;
cudaError_t cudaMalloc (void **devPtr, size_t size):参数为需要释放的指针对象地址
作用:从设备全局内存中释放对象;
-
定义核函数(计算函数)
-
数据传输
这里涉及到一个数据拷贝,函数为cudaError_t cudaMemcpy (void *dst, const void *src, size_t count, cudaMemcpyKind kind)
cudaMemcpyKind 支持的四种选项:cudaMemcpyHostToDevice、cudaMemcpyDeviceToHost、cudaMemcpyDeviceToDevice
作用:内存数据在主机端和设备端的传输;
核函数的定义和调用:
- 在GPU上执行的函数;
- 一般通过标识符__ global __修饰;
- 函数调用通过<<<参数1,参数2>>>,参数用于说明核函数中的线程数量,以及线程的组织;
- 以网格(grid)的形式组织,每个线程格由若干个线程块(block)组成,而每个线程块又由若干个线程(thread)组成;
- 调用时必须声明内核函数的执行参数;
- 在编程时,必须先为kernel函数中用到的数组或变量分配好足够的空间,再调用kernel函数,否则在GPU计算时会发生错误;
CUDA编程的标识符号:
__ global __ : 核函数的返回一定要用void,也是最常见的;

CUDA编程流程:
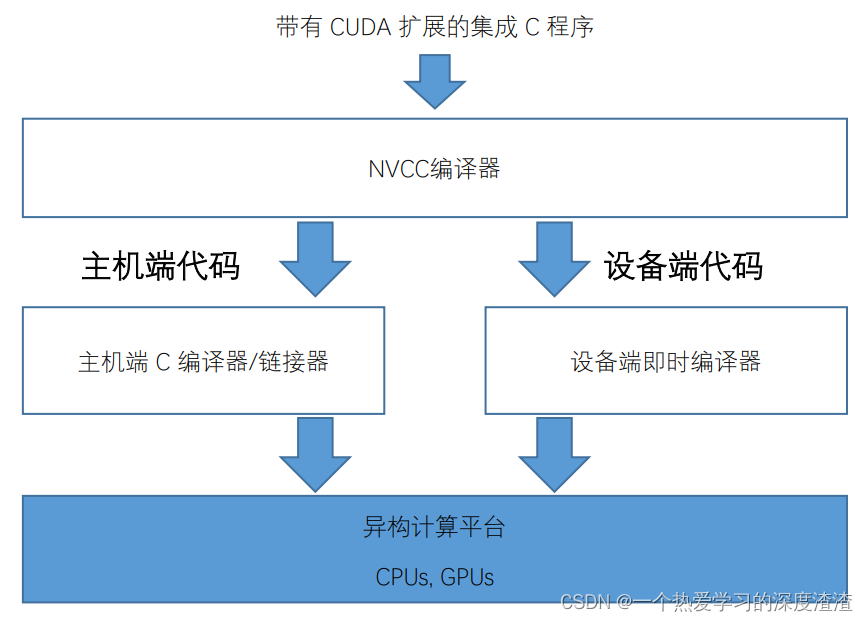
主要有几种编译的方式,比如逐文件编译,整个cuda文件编译成动态库,以及cmake编译(最常用)!
代码实现:
CPU中向量相加的实现:
void vecAdd(float* A, float* B, float* C, int n) {
for (int i = 0; i < n; i++) {
C[i] = A[i] + B[i];
}
}
GPU中向量相加的实现:
void vecAddKernel(float* A_d, float* B_d, float* C_d, int n)
{
int i = threadIdx.x + blockDim.x * blockIdx.x;
if (i < n) C_d[i] = A_d[i] + B_d[i];
}
// 下面是调用,上面是定义核函数
vecAddKernel <<< blockPerGrid, threadPerBlock >>> (da, db, dc, n);
在实际环境下编译后运行两个代码看看耗时:

可以看出,在飞浆的环境下,十万维度的向量,GPU会比CPU快上9倍左右;
案例:矩阵相乘
矩阵相乘作为深度学习任务中最常见的计算,也是GPU优化的重点;
正常的矩阵乘法是行和列之间的相乘得到一个元素,也就是一个线程负责计算一个元素;
这里存在最主要的问题就是,数据的读取过于频繁,将会浪费大量时间在读取数据上;
优化思路:
将多次访问的数据放到共享内存中,减少重复读取的次数,充分利用共享内存的延迟低的优势;
CUDA中的内存读取速度:
- 各自线程寄存器(1周期)
- 线程块共享内存(5周期)
- Grid全局内存(500周期)
- Grid常量内存(5周期)
CUDA中的共享内存:
概念:一种特殊类型的内存,内容在源码中被显式声明和使用;
(位于处理器中,以更高速度访问,被内存访问指令访问,别名暂存存储器)
特点:
- 读取速度等同于缓存,在很多显卡上,缓存和内存使用的是同一块硬件,并且可以配置大小;
- 共享内存属于线程块,可以被一个线程块内所有线程访问;
- 共享内存有两种申请空间方式,静态申请和动态申请;
- 共享内存大小只有十几K,过度使用共享内存会降低程序的并行性;
使用方法:
- 使用__ shared __ 关键字;
- 注意数据存在交叉,应该将边界上的数据拷贝进来;
这里有个线程同步的函数——__syncthreads():
概念:是cuda的内建函数,用于块内线程通信;
申请共享内存的两种方式:
1、静态方式:
__shared__ int s[64];
共享内存大小明确;
2、动态方式:
__shared__ int s[64];
共享内存大小不明确;
平铺矩阵乘法:
原理:将内核的执行分解为多个阶段,使每个阶段的数据访问集中在一个(Md和Nd)的子集上;
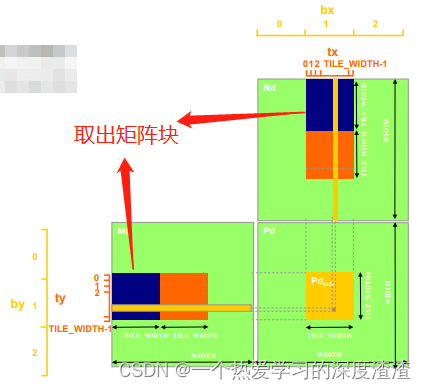
当然,需要使用内置函数__syncthreads()来确保平铺矩阵中的所有元素都被加载使用;
理论上加速的比例:原始矩阵乘法需要从全局内存中取2mnk次,平铺矩阵乘法只需要取2mnk/block_size次,加速了block_size倍,考虑到同步函数和共享内存的读写,实际上加速效率比这个低;
代码实现:
CPU下矩阵相乘的代码:
void multiplicateMatrixOnHost(float *array_A, float *array_B, float *array_C, int M_p, int K_p, int N_p)
{
for (int i = 0; i < M_p; i++)
{
for (int j = 0; j < N_p; j++)
{
float sum = 0;
for (int k = 0; k < K_p; k++)
{
sum += array_A[i*K_p + k] * array_B[k*N_p + j];
}
array_C[i*N_p + j] = sum;
}
}
}
GPU下矩阵相乘代码:
// 下面是在GPU上不适用共享内存的实现
__global__ void multiplicateMatrixOnDevice(float *array_A, float *array_B, float *array_C, int M_p, int K_p, int N_p)
{
int ix = threadIdx.x + blockDim.x*blockIdx.x;//row number
int iy = threadIdx.y + blockDim.y*blockIdx.y;//col number
if (ix < N_p && iy < M_p)
{
float sum = 0;
for (int k = 0; k < K_p; k++)
{
sum += array_A[iy*K_p + k] * array_B[k*N_p + ix];
}
array_C[iy*N_p + ix] = sum;
}
}
// 下面是在GPU上使用共享内存的实现
__global__ void matrixMultiplyShared(float *A, float *B, float *C,
int numARows, int numAColumns, int numBRows, int numBColumns, int numCRows, int numCColumns)
{
__shared__ float sharedM[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float sharedN[BLOCK_SIZE][BLOCK_SIZE];
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int row = by * BLOCK_SIZE + ty;
int col = bx * BLOCK_SIZE + tx;
float Csub = 0.0;
for (int i = 0; i < (int)(ceil((float)numAColumns / BLOCK_SIZE)); i++)
{
if (i*BLOCK_SIZE + tx < numAColumns && row < numARows)
sharedM[ty][tx] = A[row*numAColumns + i * BLOCK_SIZE + tx];
else
sharedM[ty][tx] = 0.0;
if (i*BLOCK_SIZE + ty < numBRows && col < numBColumns)
sharedN[ty][tx] = B[(i*BLOCK_SIZE + ty)*numBColumns + col];
else
sharedN[ty][tx] = 0.0;
__syncthreads(); // 线程同步
for (int j = 0; j < BLOCK_SIZE; j++)
Csub += sharedM[ty][j] * sharedN[j][tx];
__syncthreads(); // 线程同步
}
if (row < numCRows && col < numCColumns)
C[row*numCColumns + col] = Csub;
}
// 在cuda的内置库中,可以直接通过cublasSgemm()这个函数实现矩阵在共享内存中的相乘
下面是运行时间:
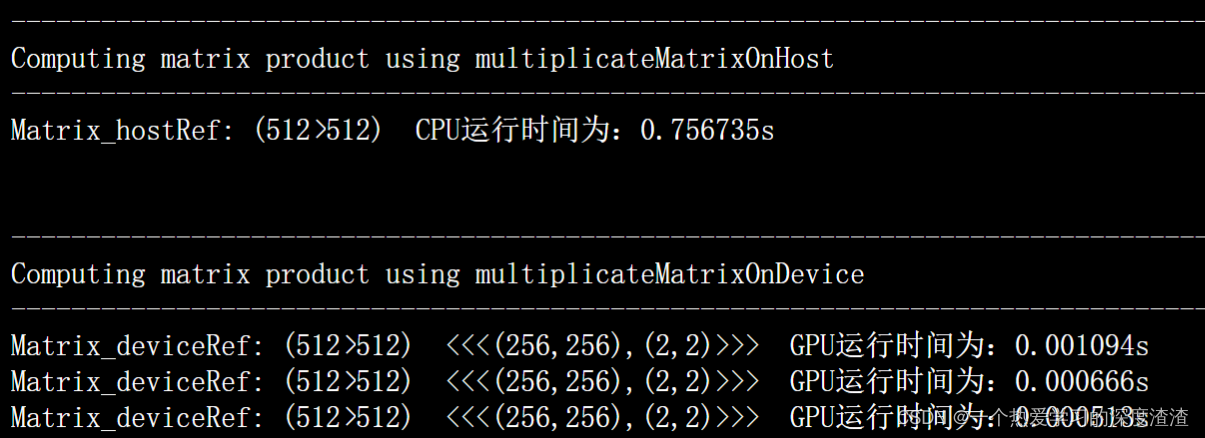
结论:
可以看出来GPU确实有实现一定效率的提升,但提升的并不多,这是因为这里的时间计算将数据的拷贝也包含了进去,如果在大的矩阵相乘的情况下,那么数据拷贝的时间可以忽略不计,而计算的效率可以看出GPU是比CPU快上很多的;
二、进阶学习
CUDA Stream
概念:CUDA Stream是GPU上task的执行队列,所有CUDA操作(kernel,内存拷贝等)都是在stream上执行的;
种类:
1、隐式流:又称为默认流、NULL流;
所有的CUDA操作默认运行在隐式流里,隐式流里的GOU和CPU端计算是同步的,也就是串行的;

2、显示流:显示申请的流;
显示流里的GPU task和CPU端计算是异步的,不同显示流内的GPU task执行也是异步的、并行的;

简单代码案例:
// 创建两个流
cudaStream_t stream[2]; // 定义流对象
for (int i = 0; i < 2; ++i){
cudaStreamCreate(&stream[i]);
}
float* hostPtr;
cudaMallocHost(&hostPtr, 2 * size);
...
// 两个流,每个流有三个命令
for (int i = 0; i < 2; ++i){
// 从主机内存复制数据到设备内存
cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size, size, cudaMemcpyHostToDevice, stream[i]);
// 执行kernel处理
MyKernrl <<grid, block, 0, stream[i]>>(outputDevPtr + i * size, inputDevPtr + i * size, size);
// 从设备内存复制数据到主机内存
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size, size, cudaMemcpyD eviceToHost, stream[i]);
}
// 同步流
for (int i = 0; i < 2; i++){
cudaStreamSyncchronize(stream[i]);
...
}
// 销毁流
for (int i = 0; i < 2; ++i){
cudaStreamDestory(stream[i]);
}
优点:
- CPU计算和kernel计算并行;
- CPU计算和数据传输并行;
- 数据传输和kernel计算并行;
- kernel计算并行;
注意点:
显示流里的GPU task和GPU端的task的执行是异步的,使用stream一定要注意同步;
以下接口作用是同步流:
cudaStreamSyncchronize():同步一个流;
cudaDeviceSynchronize():同步设备上所有流;
cudaStreamQuery():查询一个流任务是否完成;
下面看一个案例:数据传输和GPU计算通过流实现并行
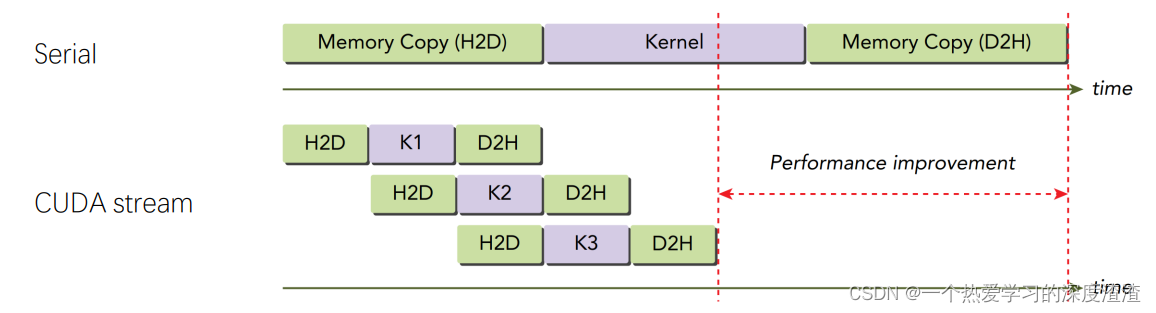
注意:从下面的任务执行顺序可以看出,数据传输并不是重叠到一起的,这是因为CPU和GPU数据的传输是经过PCle总线的,PCle的操作是顺序的;
提问:
1、CUDA Stream为什么有效?
- PCle总线传输速度慢,是瓶颈,会导致数据传输的时候GPU处于空闲状态,多流可以实现数据传输与kernel计算的并行;
- 一个kernel往往用不了整个GPU的算力,多流可以让多个kernel同时计算;
- 不是流越多越好,类似于CPU的多核一样,也是有数量限制的;
这里还有一个优化的策略,就是将小任务合并成大任务;
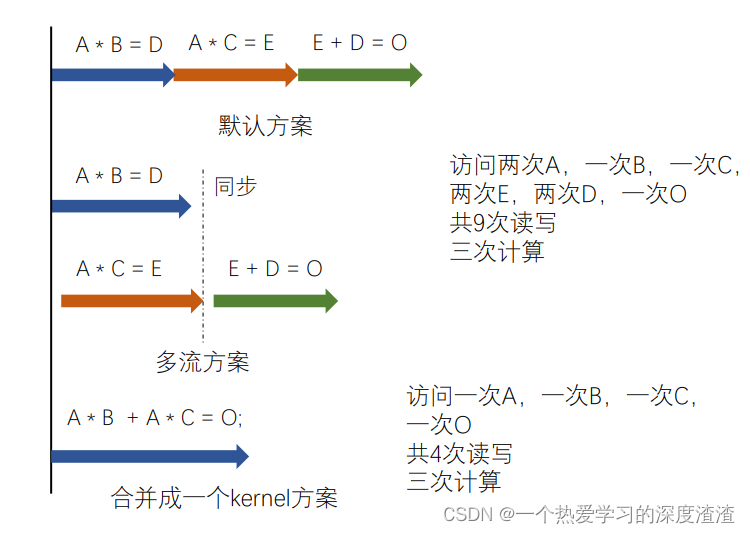
还需要注意一点,当同时存在默认流和显示流时,编译需要加上一个参数;
nvcc --default-stream per-thread ./stream_test.cu -o stream_per-thread
CUDA Event
CUDA Event是在stream中插入一个事件,类似于打一个标记位,用来记录stream是否执行到当前位置,Event有两个状态,已被执行和未被执行;
最常用的用法是来测时间:
// 使用event计算时间
float time_elapsed = 0;
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0); // 记录当前时间
mul<<<blocks, threads, 0, 0>>>(dev_a, NUM);
cudaEventRecord(stop, 0); // 记录当前时间
cudaEventSynchronize(start);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&time_elapsed, start, stop); // 计算时间差
cudaEventDestroy(start);
cudaEventDestroy(stop);
printf("执行时间: %f(ms)\n", time_elapsed);
CUDA同步操作(分为四类):
- device synchronize:影响很大,必须等待全部kernel执行完才能执行CPU端任务;
- stream synchronize:影响单个流和CPU,需要等待这个流执行完才能继续CPU;
- event synchronize:影响CPU,更细粒度的同步;
- synchronizing across streams using an event:高级控制;
NVVP
概念:NVIDIA Visual Profiler(NVVP)是NVIDIA推出的跨平台的CUDA程序性能分析工具;
主要有以下特点:
- 随着CUDA安装,不需要额外安装;
- 有图形界面,可以快速找到程序中的性能瓶颈;
- 以时间线的形式展示CPU和GPU的操作;
- 可以查看数据传输和kernel的各种软件参数(速度)和硬件参数(L1 cache命中率);
在Window端打开可视化功能还需要参考以下文章安装:
(66条消息) Package | Windows10 CUDA10.2 JDK8 环境下安装NVidia Visual Profiler(nvvp)安装Bug笔记_1LOVESJohnny的博客-CSDN博客
Cublas
概念:是一个BLAS的实现,允许用户使用NVIDIA的GPU计算资源,使用cuBLAS的时候,应用应该分配矩阵或向量所需的GPU内存空间,并加载数据,调用所需的cuBLAS函数,然后从GPU的内存空间上传计算结果至主机,cuBLAS也提供了一些帮助函数来写或者读取数据从GPU中;
学习网站:cuBLAS (nvidia.com)
说明:这一部分主要是在GPU上的线性的一些函数用法,主要用于处理向量标量、向量矩阵、矩阵矩阵的一些函数,由于短期内还用不到,这里不进行深入学习;
Cudnn
概念:NVIDIA cuDNN是用于深度神经网络的GPU加速库,它强调性能、易用性和低内存开销,并且可以继承倒更高级的机器学习框架中;
学习网站:NVIDIA cuDNN Documentation
实现步骤:
// 1、创建cuDNN句柄
cudnnStatus_t cudnnCreate(cudnnHandle_t *handle)
// 2、以Host方式调用在Device上运行的函数
比如卷积函数: cudnnConvolutionForward等
//3、释放cuDNN句柄
cudnnStatus_t cudnnDestroy(cudnnHandle_t handle)
// 4、将CUDA流设置&返回成cudnn句柄
cudnnStatus_t cudnnSetStream( cudnnHandle_t handle, cudaStream_t streamId)
cudnnStatus_t cudnnGetStream( cudnnHandle_t handle, cudaStream_t *streamId)
三、TensorRT学习
基础概念
首先要明确TensorRT的定位,是一个推理框架:

具有以下几个特点:
- 高性能深度学习推理优化器和加速库;
- 低延迟和高吞吐量;
- 部署到超大规模数据中心、嵌入式或汽车产品;
- 相对于其他推理框架,闭源也是其特点之一;
其实现步骤主要分为两步:转换优化引擎和执行引擎;
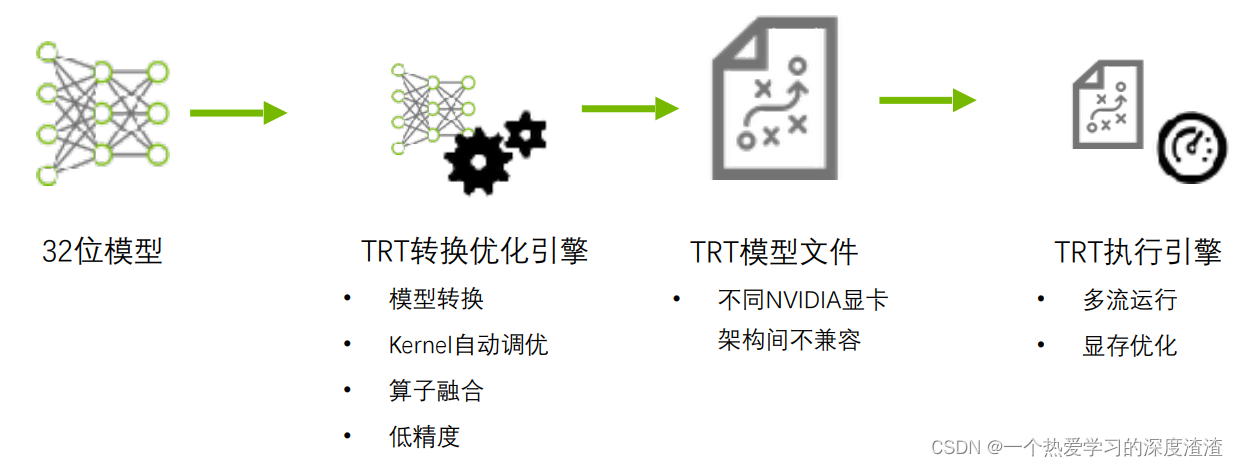
其中最常见的优化方式也就是量化(低精度)和算子融合(例如将卷积池化和激活层融合成一层)
使用流程
其使用流程分为以下几个步骤:
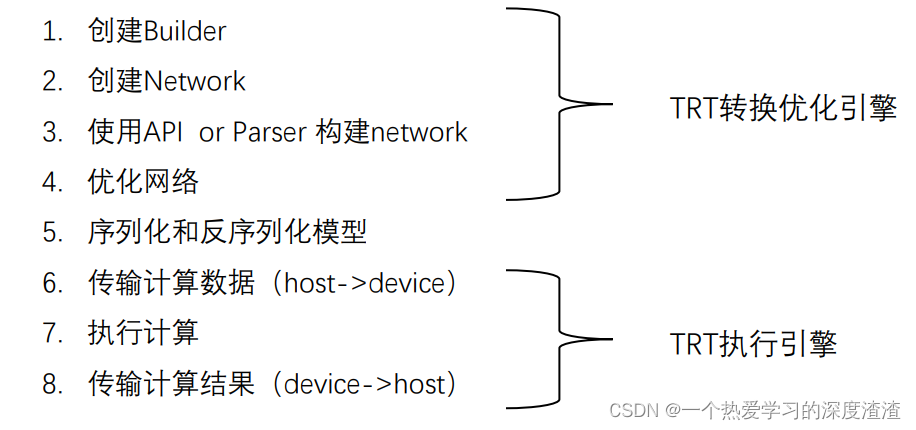
其中构建网络分为两种方式,一种是API构建,也就是网络的每一层都重新用代码构建,相对来说比较复杂;一种是用Parser来构建,也就是特定的网络有其特定的框架有对应的加载接口,只需要简单几行代码就可以构建网络结构;
模型转换
ONNX转trt:https://github.com/onnx/onnx-tensorrt/tree/6872a9473391a73b96741711d52b98c2c3e25146
Pytorch转trt:NVIDIA-AI-IOT/torch2trt: An easy to use PyTorch to TensorRT converter (github.com)
TensorFlow转trt:tensorflow/tensorflow/compiler/tf2tensorrt at 1cca70b80504474402215d2a4e55bc44621b691d · tensorflow/tensorflow (github.com)
这里介绍一个转换工具网站:https://convertmodel.com/
其中具体的一些转换的技巧还需要在实践中去探索,但最好将模型转换为onnx,再通过onnx转换为trt;
简单案例
官方源码中给出了很多案例:
https://github.com/NVIDIA/TensorRT/tree/release/6.0/samples/opensource/sampleMNIST
这是其中一个MNIST的数字识别的案例;
在AIStudio中跑了一下案例,可以得到如下结果:
四、TensorRT进阶
plugin用法
作用:
1、trt支持的算子有限,可以实现不支持的算子;
2、进行深度优化、合并算子;
工作流程:
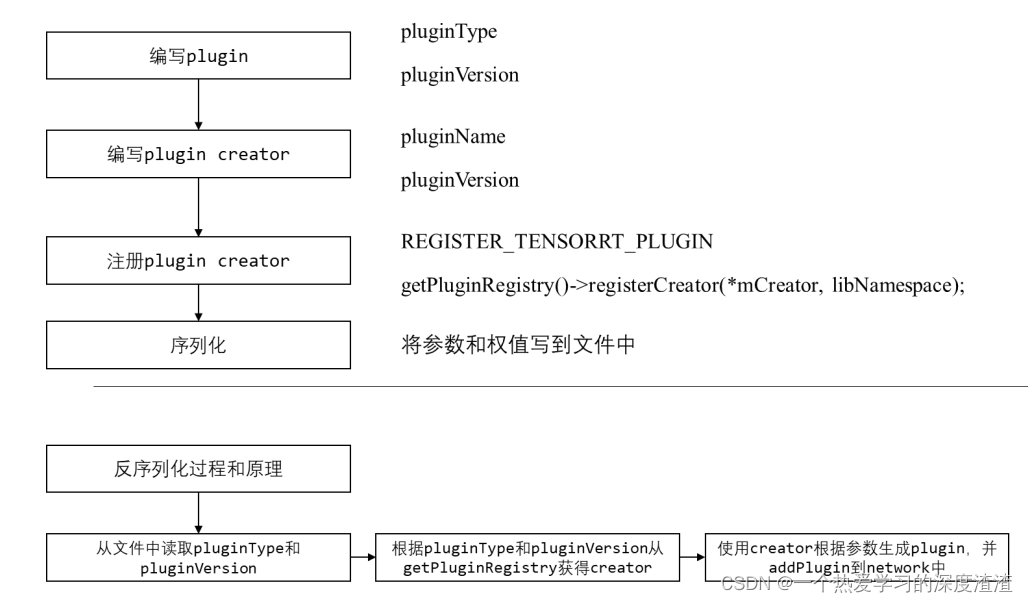
API的讲解:
首先要清楚有两种类型的定义:
- Dynamic Shape:输入维度是动态的,继承IPluginV2IOExt基础类;
- Static Shape:输入维度是静态的,继承IPluginV2DynamicExt基础类;
构造函数:
1、用于network definition阶段,PluginCreator创建该插件时调用的构造函数,需要传递权重信息以及参数。 也可用于clone阶段,或者再写一个clone构造函数;
MyCustomPlugin(int in_channel, nvinfer1::Weights const& weight, nvinfer1::Weights const& bias);
2、 用于在deserialize阶段,用于将序列化好的权重和参数传入该plugin并创建;
MyCustomPlugin(void const* serialData, size_t serialLength);
3、注意把默认构造函数删掉;
MyCustomPlugin() = delete;
析构函数:
析构函数则需要执行terminate,terminate函数就是释放这个op之前开辟的一些显存空间;
MyCustomPlugin::~MyCustomPlugin() {
terminate();
}
输出相关函数:
1、获得layer的输出个数;
int getNbOutputs() const;
2、根据输入个数和输入维度,获得第index个输出的维度;
nvinfer1::Dims getOutputDimensions(int index, const nvinfer1::Dims* inputs, int nbInputDims);
3、根据输入个数和输入类型,获得第index个输出的类型;
nvinfer1::DataType getOutputDataType(int index, const nvinfer1::DataType* inputTypes, int nbInputs) const;
序列化和反序列化相关函数:
1、返回序列化时需要写多少字节到buffer中;
size_t getSerializationSize() const;
2、序列化函数,将plugin的参数权值写入到buffer中;
void serialize(void* buffer) const;
3、获得plugin的type和version,用于反序列化使用;
const char* getPluginType() const;
const char* getPluginVersion() const;
初始化、配置和销毁函数:
1、初始化函数,在这个插件准备开始run之前执行。一般申请权值显存空间并copy权值;
int initialize();
2、terminate函数就是释放initialize开辟的一些显存空间;
void terminate();
3、释放整个plugin占用的资源;
void destroy();
4、配置这个插件op,判断输入和输出类型数量是否正确;
void configurePlugin(const nvinfer1::PluginTensorDesc* in, int nbInput, const nvinfer1::PluginTensorDesc* out, int nbOutput);
5、判断pos索引的输入/输出是否支持inOut[pos].format和inOut[pos].type指定的格式/数据类型;
bool supportsFormatCombination(int pos, const nvinfer1::PluginTensorDesc* inOut, int nbInputs, int nbOutputs) const;
运行时相关函数:
1、获得plugin所需要的显存大小。最好不要在plugin enqueue中使用cudaMalloc申请显存;
size_t getWorkspaceSize(int maxBatchSize) const;
2、推理函数;
int enqueue(int batchSize, const void* const* inputs, void** outputs, void* workspace, cudaStream_t stream);
IPluginCreator相关函数:
1、获得pluginname和version,用于辨识creator;
const char* getPluginName() const;
const char* getPluginVersion() const;
2、通过PluginFieldCollection去创建plugin 将op需要的权重和参数一个一个取出来,然后调用上文提到的第一个构造函数:
const nvinfer1::PluginFieldCollection* getFieldNames();
nvinfer1::IPluginV2* createPlugin(const char* name, const nvinfer1::PluginFieldCollection*
fc);
3、反序列化,调用反序列化那个构造函数,生成plugin;
nvinfer1::IPluginV2* deserializePlugin(const char* name, const void* serialData, size_t serialLength);
建议参考官方的案例进行学习,来巩固代码的实现流程;
优化
首先可以了解下FP32、FP16类型的具体定义:
参考:ARM CPU性能优化:FP32 、FP16 和BF16区别 - 知乎 (zhihu.com)
INT8量化的含义:
将基于浮点的模型转换成低精度的int8数值进行运算,以加快推理速度;
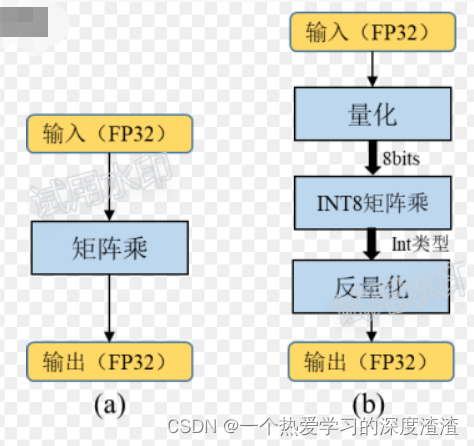
INT8和FP16加速推理的原理:
通过指令或硬件技术,在单位时钟周期内,FP16和INT8类型的运算次数大于FP32类型的运算次数;
INT8量化为什么不会大幅损失精度?
由于神经网络具有以下特性:具有一定的鲁棒性;
原因:训练数据一般都是有噪声的,神经网络的训练过程往往就是从噪声中识别出有效信息,可以将降低精度计算造成的损失理解成另一种噪声;
INT8量化的分类:
动态对称量化算法(ONNX量化、torch动态量化)
动态非对称量化算法(Google Gemmlowp)
静态对称量化算法(torch静态量化、TensorRT、NCNN)
动态对称量化算法:
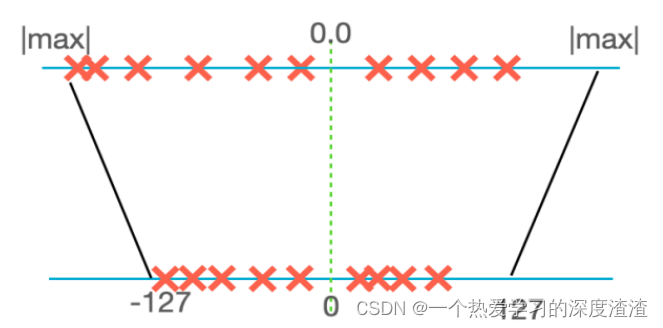
计算公式:
scale = |max| * 2/256;
real_value = scale * quantized_value;
其中real_value为真实值(float类型),quantized_value为INT8量化的结果(char类型)
优点:算法简单,量化步骤耗时短;
缺点:会造成位宽浪费,影响精度,也就是说像可能转换成8位的值,有一位的值可能是空的;
动态非对称量化算法:
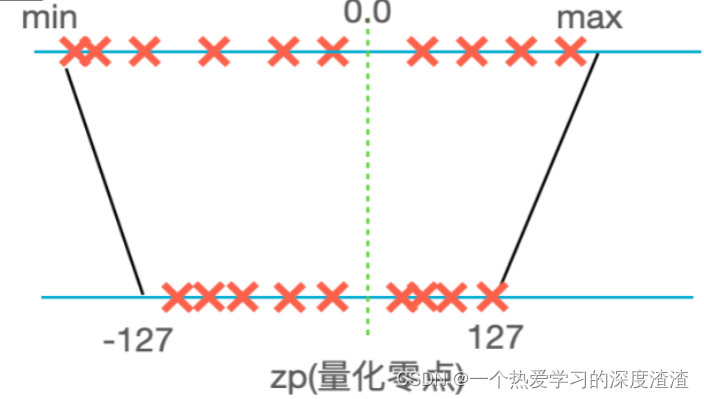
计算公式:
scale = |max - min| / 256;
real_value = scale * (quantized_value - zero_point);
其中real_value位真实值(float类型),quantized_value为INT8量化的结果(char类型),zero_point为零点值
优点:不会造成bit位宽浪费,精度有保障;
缺点:算法比较复杂,量化步骤耗时较长;
静态对称量化算法:
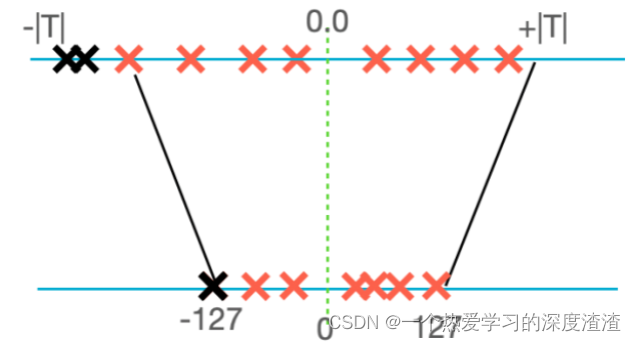
动态量化:推理时实时统计数值|max|;
静态量化:推理时使用预先统计的缩放阈值,截断部分阈值外的数据;
优点:算法最简单,量化耗时最短,精度也有一定保证;
缺点:构建量化网络比较麻烦;
主要采用KL散度来计算量化的阈值,可以参考下面文章:
(72条消息) TensorRT INT8量化原理与实现(非常详细)_Nicholson07的博客-CSDN博客
源代码案例:TensorRT/samples/opensource/sampleINT8 at release/7.2 · NVIDIA/TensorRT · GitHub
INT8量化大规模上线:
总结
1、对于深度神经网络的推理,TRT可以充分发挥GPU的算力,以及节省GPU的存储空间;
2、要多参考官方源码的sample案例,尝试替换现有模型,再深入了解API进行网络的搭建;
3、如果要使用自定义组件,至少先了解CUDA基本架构以及常用属性;
4、推荐使用FP16(定义很少变量,明显能提高速度,精度影响不大)和INT8(更大的潜力,可能导致精度下降)这两种量化模式;
5、在不同架构的GPU或者不同的软件版本的设备上,引擎不能通用,要重新生成一个;