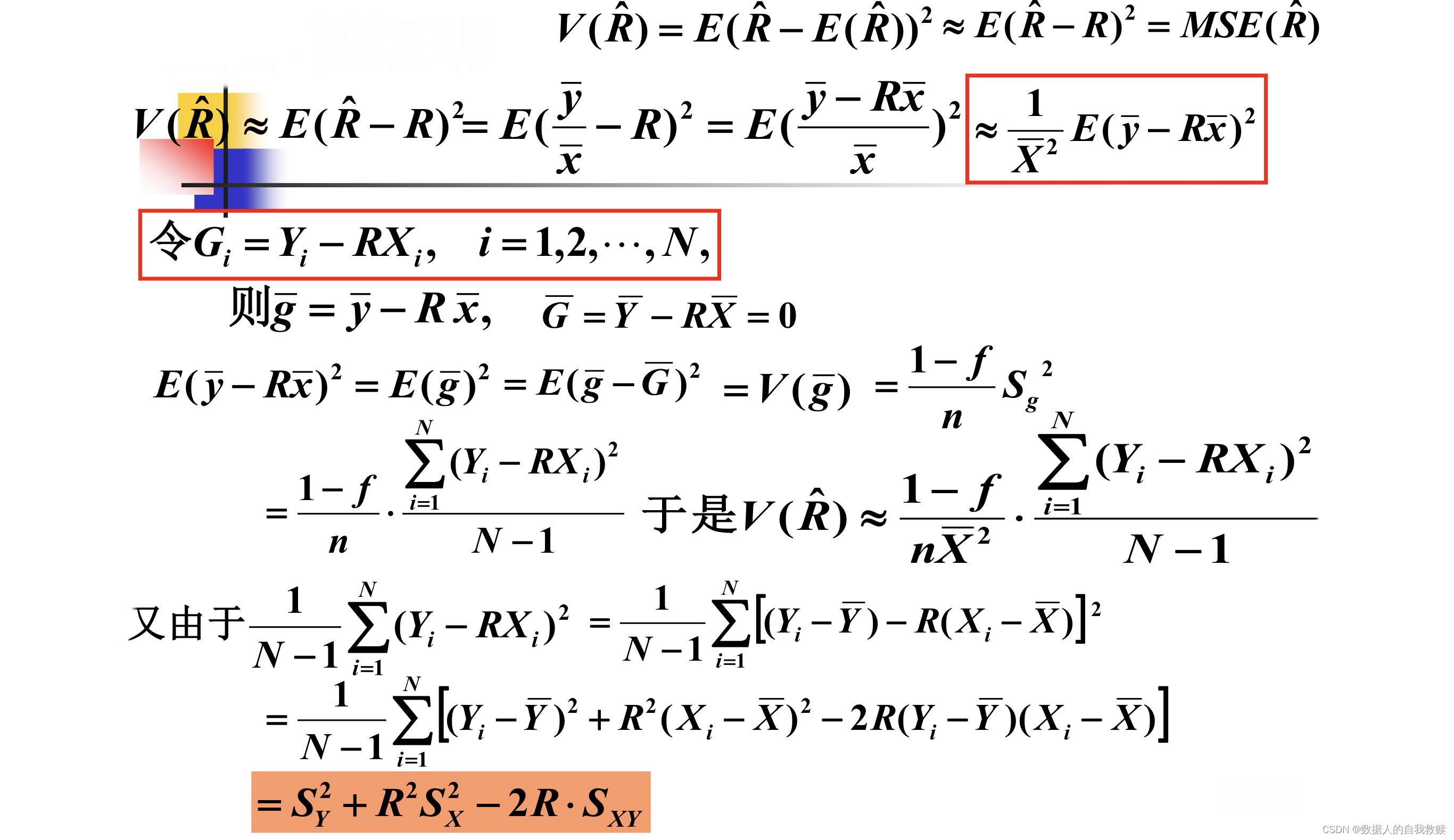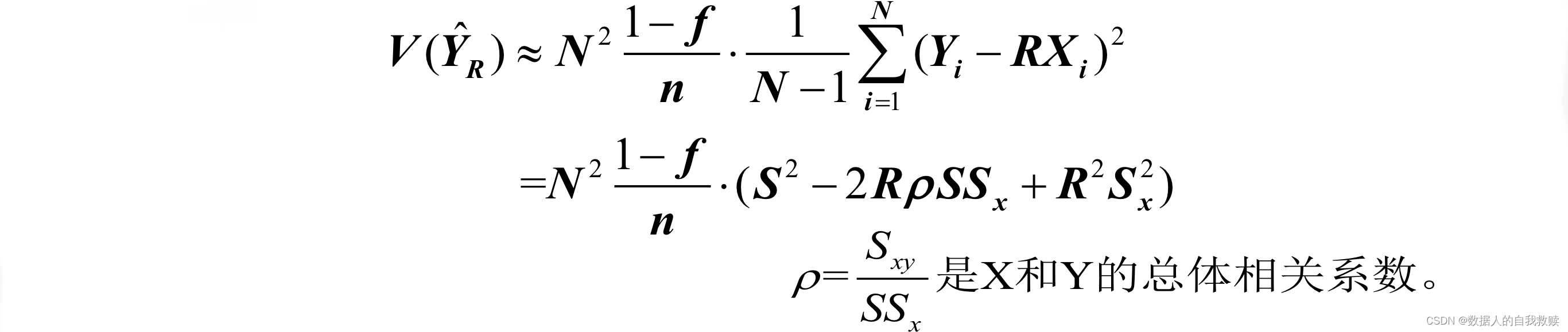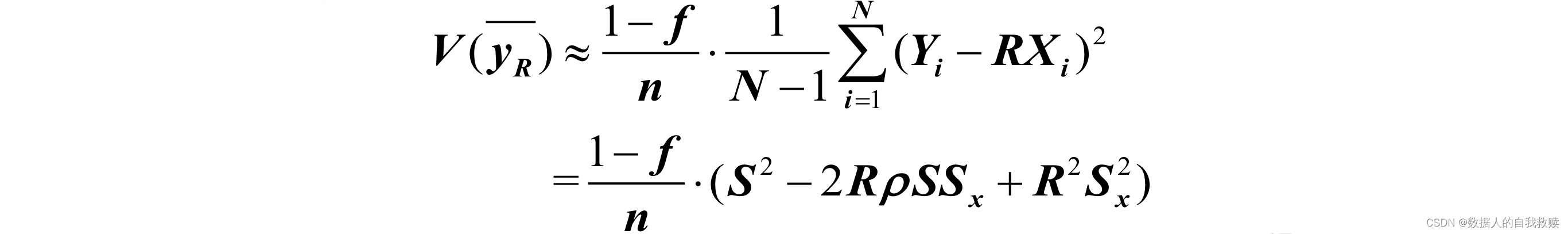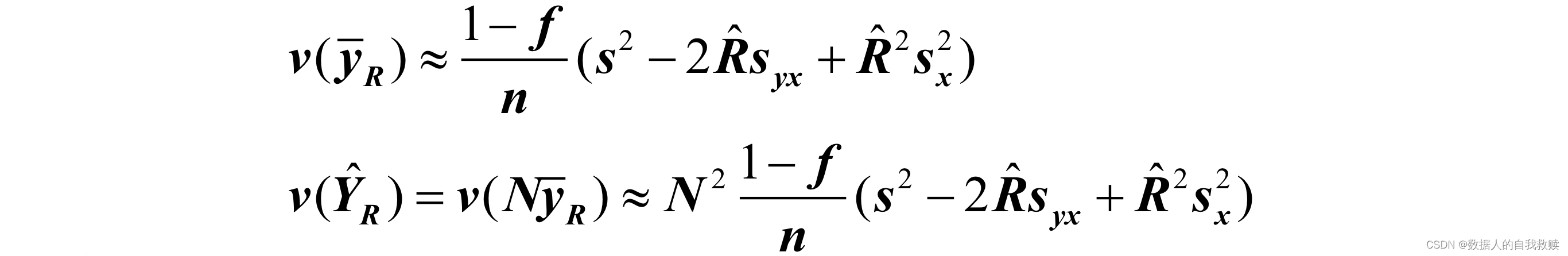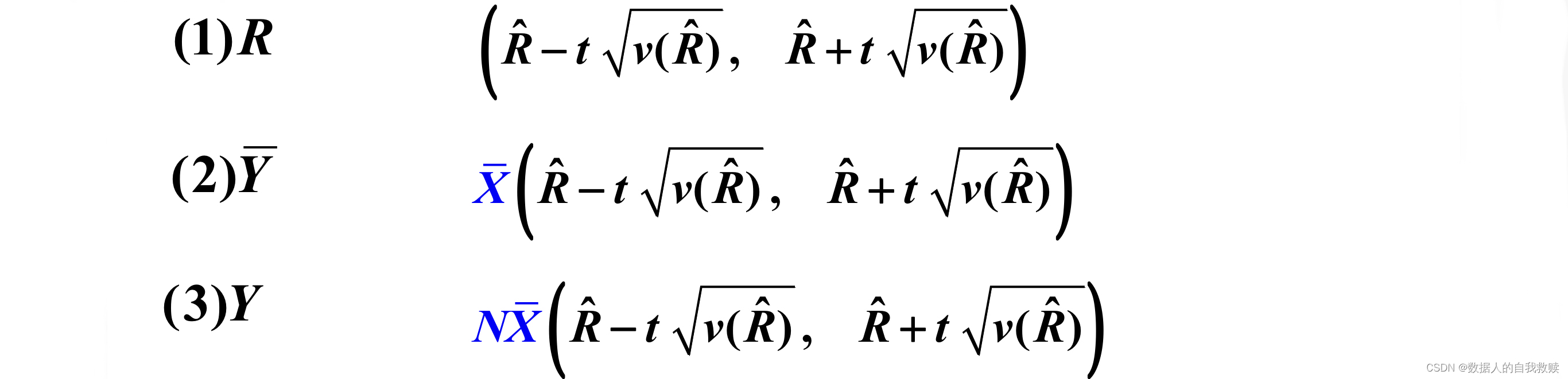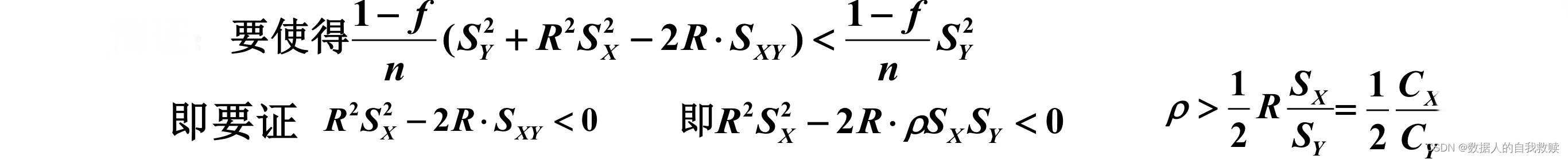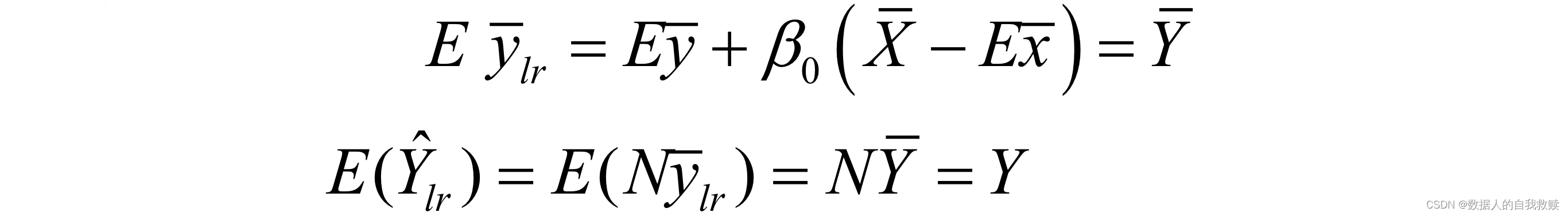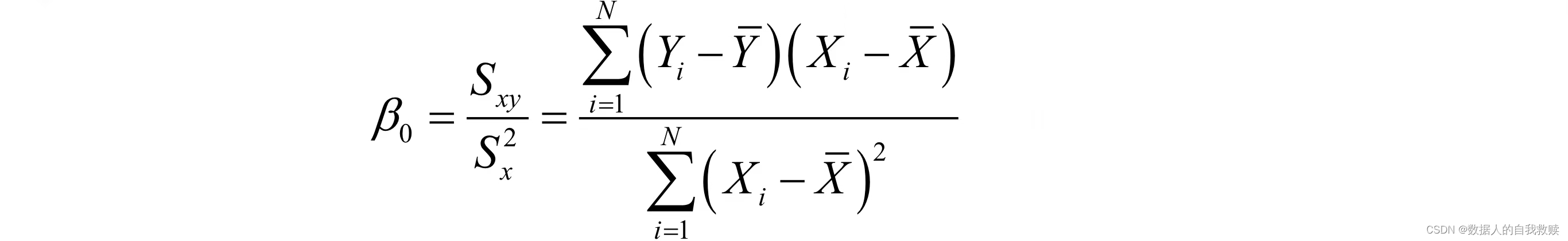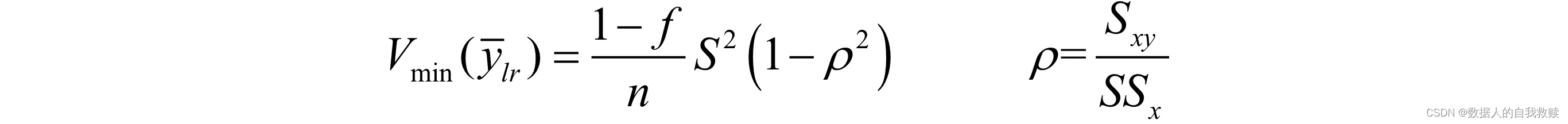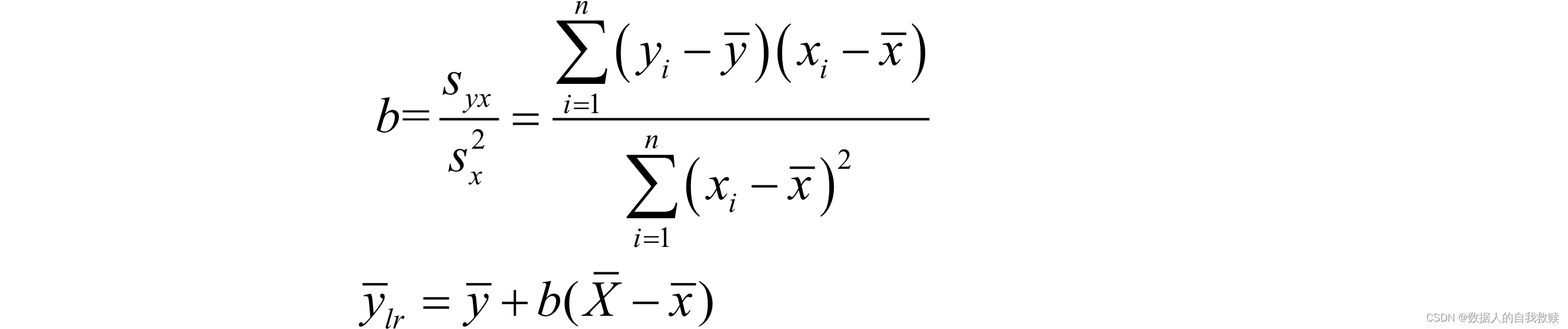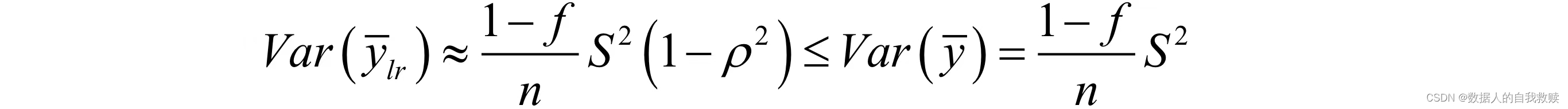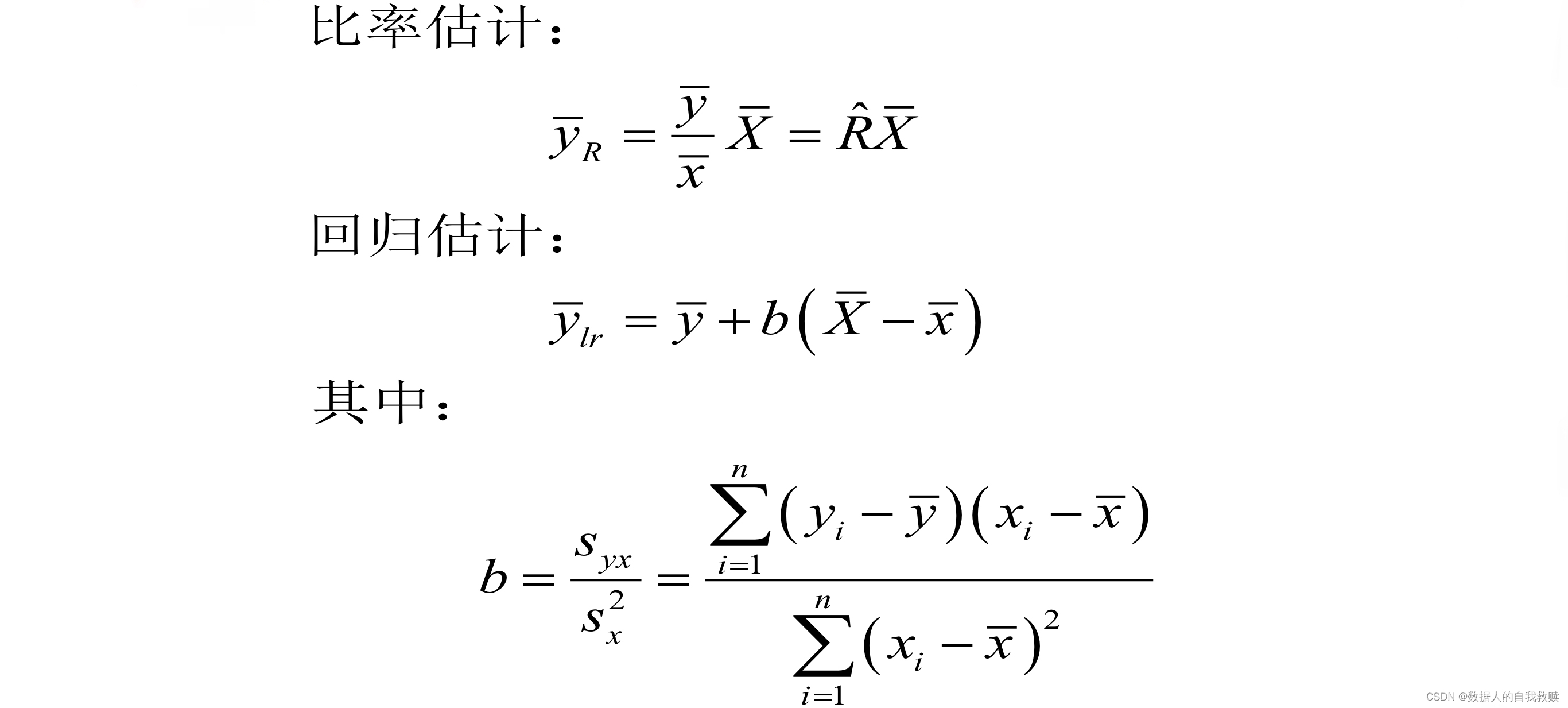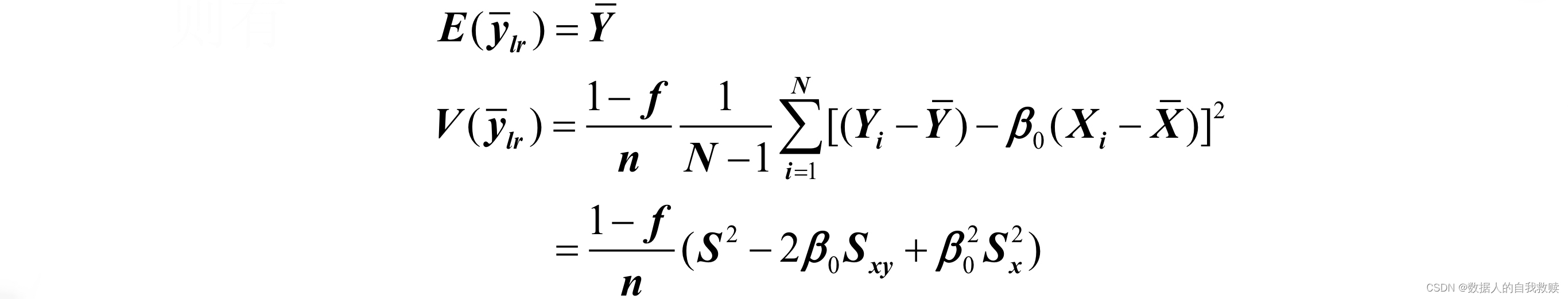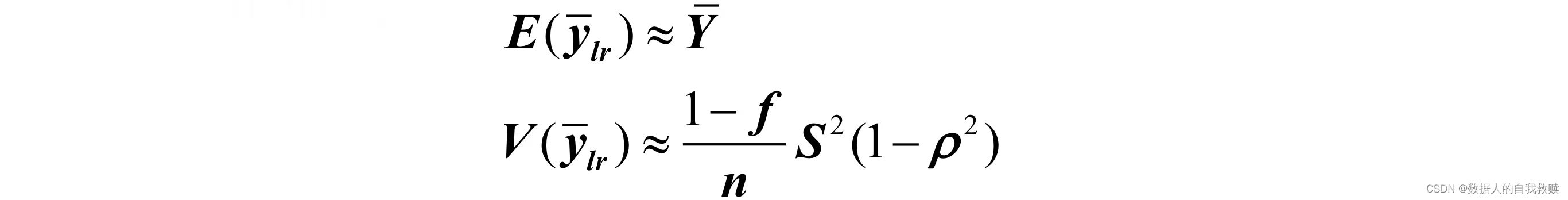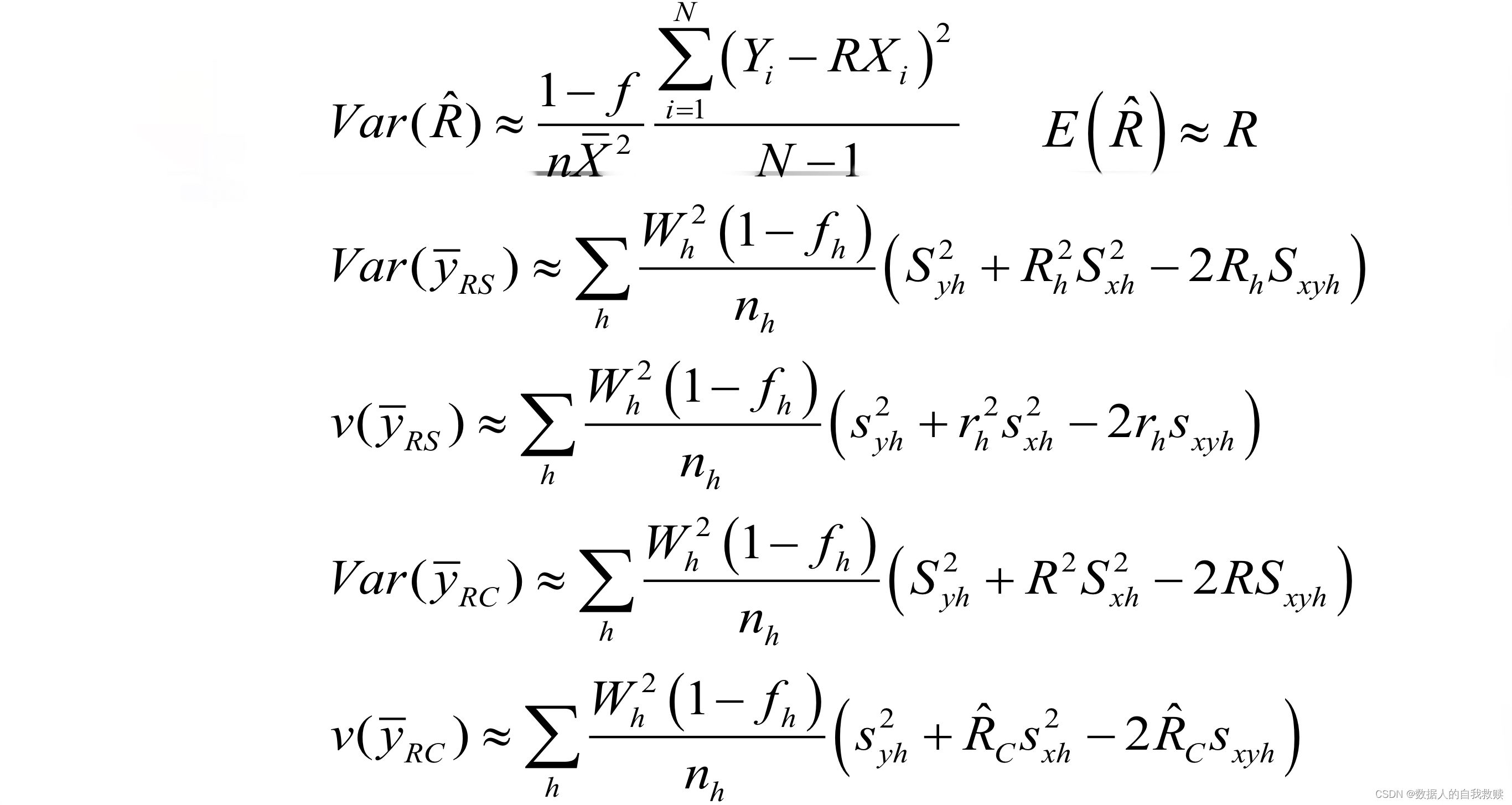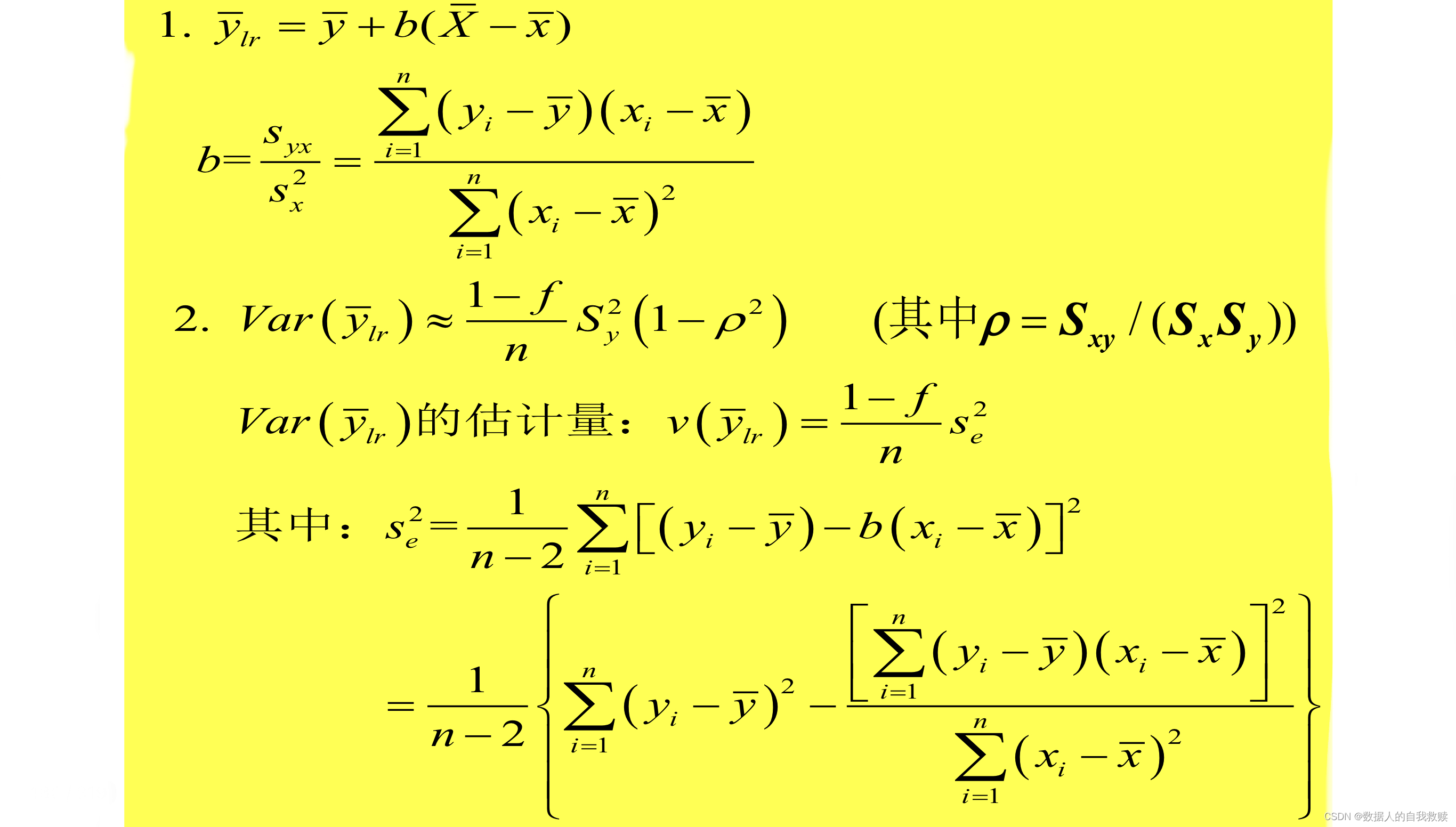目录
一、概述
1.问题的提出
2.比率估计与回归估计的作用和使用条件
3.辅助变量的特点
4.相关符号
二、比率估计量编辑 编辑
2.定义
3.比估计与简单估计的比较
4.比率估计的思想
5.比率估计量及其性质
(1)【引理】
(2)【推论】
(3)比率估计的性质
(4)【定理2.7】
(5)【推论2.10】
6.比率估计量的方差估计
7.比率估计与简单估计精度的比较
8.【例】
9.总结
三、回归估计
1.回归估计量及其性质
(1)回归估计的含义
(2)回归估计量的性质
2.回归估计与比率估计、简单估计精度的比较
(1)与简单估计的比较
(2)与比率估计的比较(n较大时)
3.总结:回归估计的性质
四、总结
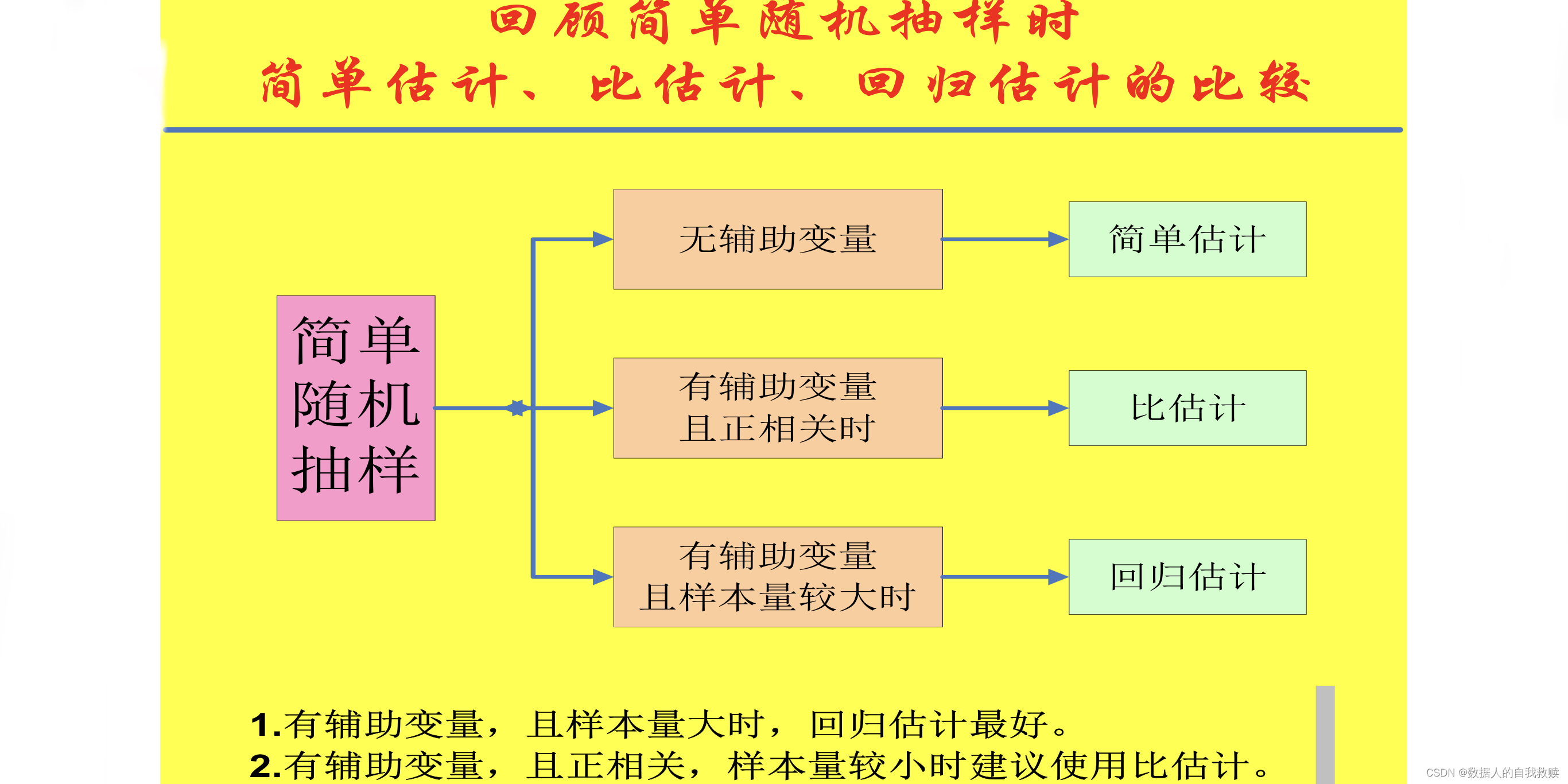
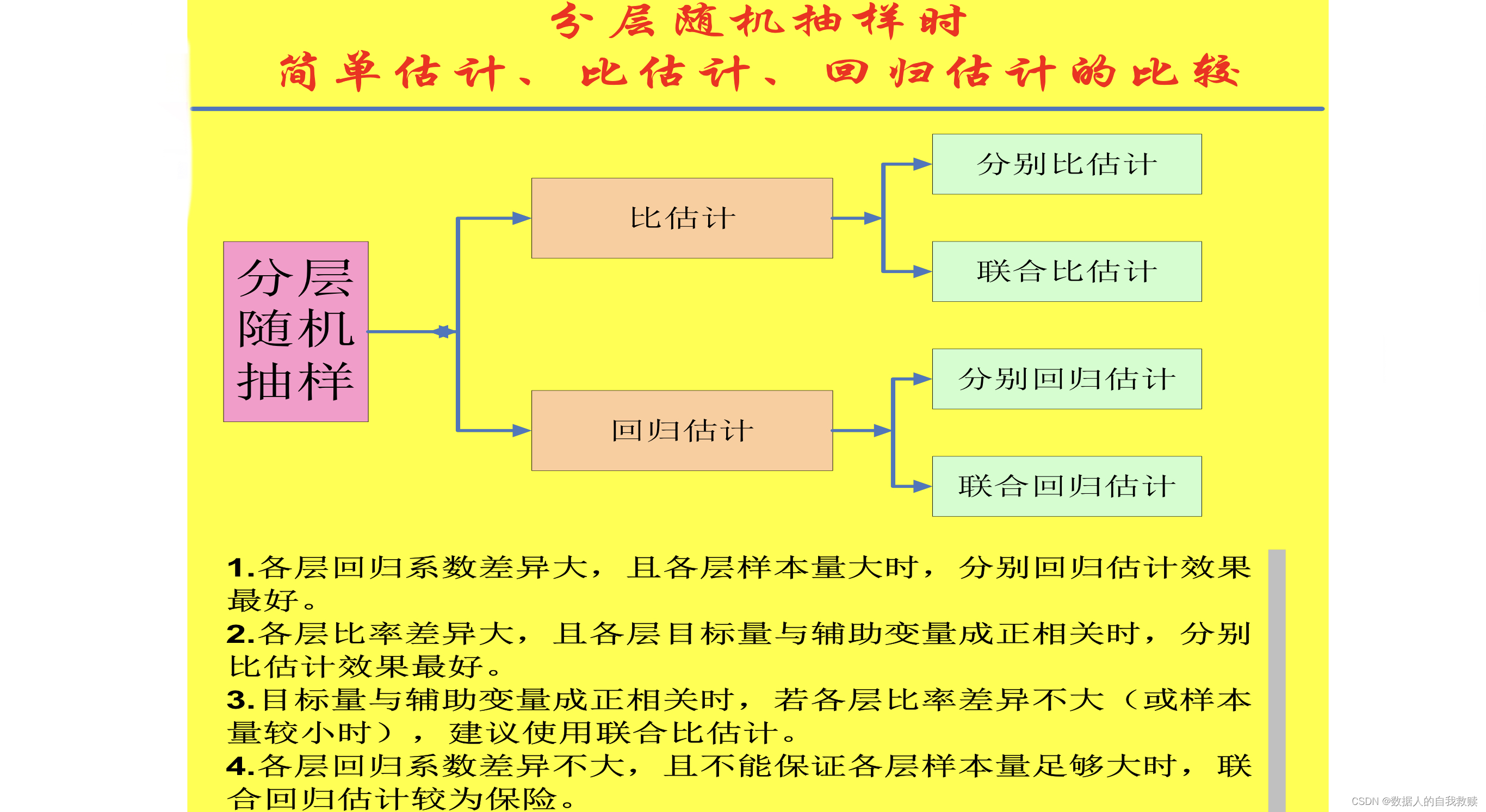
1.各种估计量的比较与选择
2.应该记住的几个基本公式
3.应该了解的几个基本公式
调查通常是多指标的:
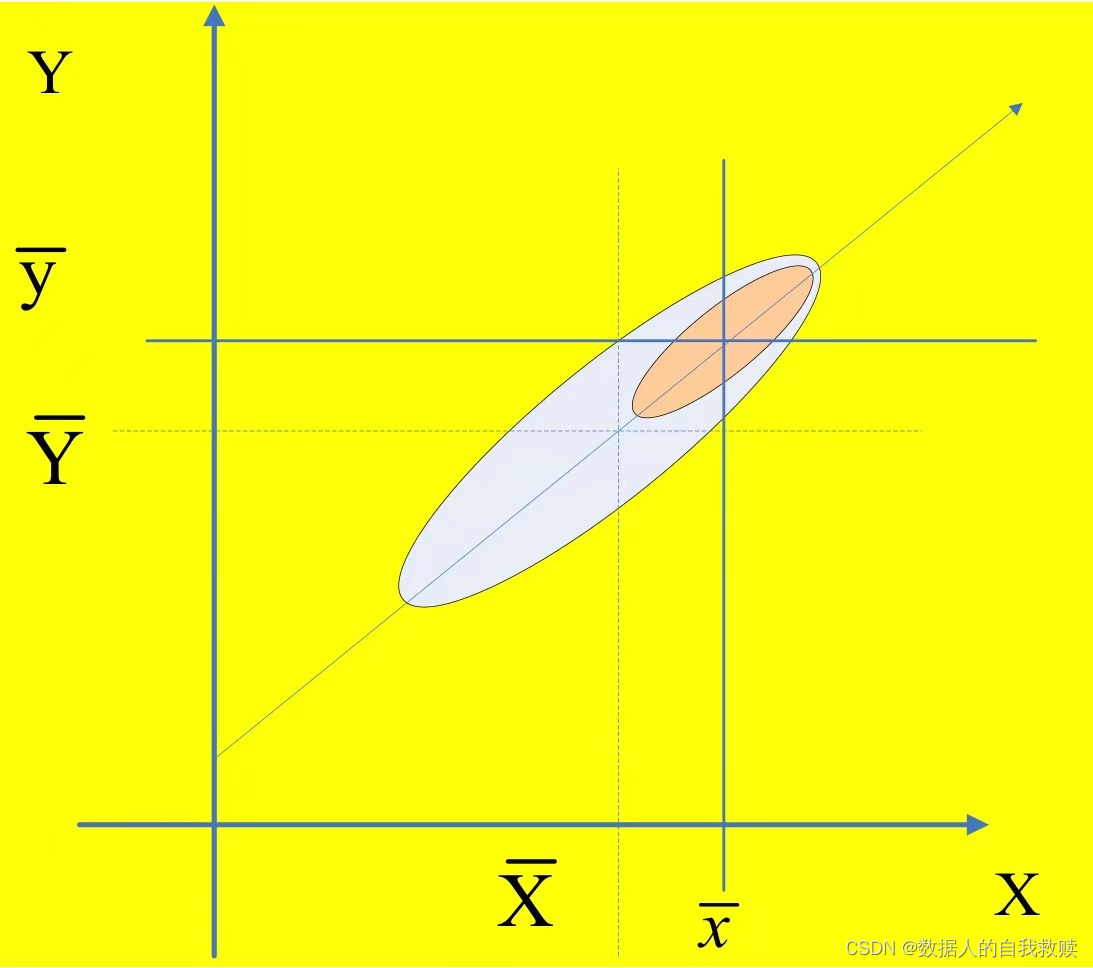
设二维总体,样本为。
设调查指标为,辅助变量为,所用的符号。
在许多实际问题中常常涉及两个调查变量(指标)和。常常要估计总体比率。
总体比率在形式上总是表现为两个变量总值或均值之比。例如:估计家庭中用于食品的支出在总支出中比重;在校儿童对全体学龄儿童的比重等等。
比率与比例的区别:比例中总体的规模已知,仅需调查一个指标;比率中需要调查样本的两个指标。
【问题1】比率的估计
【问题2】总体均值的比率估计量的构造方法
对于简单随机抽样,若是样本两个指标的均值,则总统的这两个指标总值或均值之比值(比率)。比率估计量 。
当调查变量为,将作为辅助变量时,已知,则以及的比率估计值为
都成为比率估计量,简称比估计。由于中仅与相差常数,所以我们以研究的性质为主。
对于简单随机抽样,较大时,的期望为
对于简单随机抽样,较大时,
【注】性质4的证明
对于简单随机抽样,当n较大时,的方差为:
对于简单随机抽样,当n较大时的方差为:
思路:根据定理,直接用的样本方差,样本协方差和样本比率替代相应比率估计量方差定理中的总体方差,总体协方差和总体比率。
置信度为的置信区间为:
统计知识告诉我们:有关信息的充分利用,将会提高估计量的精度。因此,有理由认为:的精度在一般情况下要高于的精度。
设相关系数;的变异系数分别为,有如下结论:
使用回归估计的原因:比率估计使用的前提是与辅助变量之间基本呈正比例关系;若之间关系密切,但对的回归线不通过原点,则可以通过回归估计来提高估计的效率。
前提:存在与主要变量高度相关的其他辅助变量的有效信息。
已知辅助变量的总体均值;总体均值的回归估计量定义为:
其中, 是目标变量相对于辅助变量的变化率。
定义:总体均值与总体总值的回归估计定义为:
特别,时的估计称为差估计:;时的估计称为简单估计:;时的估计称为比率估计:。因此,简单估计与比率估计均为回归估计的特例。
为事先给定的常数时:,则是的无偏估计:
为事先给定的常数时:可看成是变量的样本均值,其总体均值为,由关于样本均值方差的核心公式可得:
的方差估计为:
的不同取值会影响的值,的最佳值是?可以证明,取对的总体回归系数为:
方差达到最小值:
为未知(需要由样本数据估计)的情形:一般情形下总体回归系数未知,此时一个较好的选择是用样本回归系数替代总体回归系数,构造回归估计:
需要由样本估计()的情形:
由于,所以较大时:
故回归估计优于简单估计。
定义主要变量的总体总值的回归估计量为。
辅助变量的特点:
1.对于简单随机抽样,如为常数,则有:
2.使回归估计量的估计精度最高,即最小的为:
3.对于简单随机抽样,若回归系数需要通过样本估计,当足够大时,的数学期望与方差分别为: