
论文:
VarifocalNet: An IoU-aware Dense Object Detector
代码:https://github.com/hyz-xmaster/VarifocalNet
出处:CVPR2021
贡献:
- 作者提出了 IACS (IoU-Aware Classification Score) 的评价标准,来对框进行排序,并证明了有效排序对检测效果的影响
- 作者提出了 Varifocal Loss 来回归 IACS,并设计了 “星型” bbox 特征表示,来计算 ICAS 同时调整 bbox
- 作者基于 FCOS+ATSS,设计了目标检测器 VarifocalNet(也叫 VFNet)
- VFNet 在 COCO test 上使用 Res2Net-101-DCN 得到了 55.1 AP
一、背景
现有的目标检测器中,无论单阶段还是双阶段检测器,大多都是先生成大量的候选框,然后使用NMS来进行滤除,NMS 一般是使用分类得分来排序的。
由于分类得分高的框,并不一定是框的最准的框,得分较低但框的很准确的框很可能会被滤掉。因此,[11]使用额外的 IoU score,[9] 使用centerness 得分作为衡量框位置准确率的标准,将其得分和分类得分相乘来作为 NMS 排序的标准。用以降低分类得分和位置准确性的作用差别。
二、动机
上述两个方法虽然可能会有一些优势,但是相乘的方法并不是最优的,可能会导致更差的排序,且性能提升有限,并且单独的分支来预测位置得分会引起计算量上升。
可以不使用额外分支来预测位置得分,而是将其和分类得分分支融合起来?
作者提出了一个 localization-aware 或 IoU-aware 的 classification score (IACS),来同时表示该 bbox 的类别和框的质量。
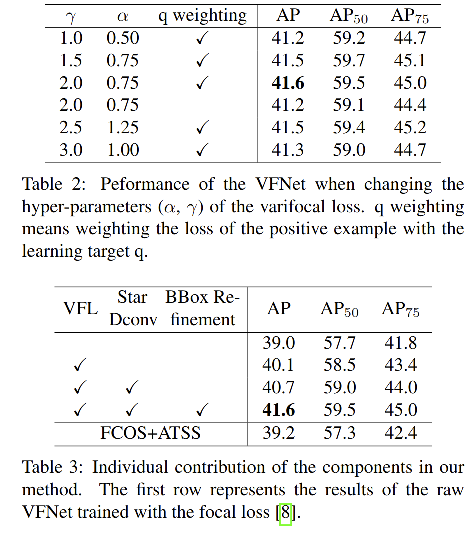
作者在FOCS+ATSS 上进行了一系列实验,将类别、位置、centerness得分分别替换为真值,寻找哪个得分对最终结果影响最大。
FCOS 是有三个分支,分别对每个位置进行分类、回归、预测 centerness(和分类得分相乘来进行框排序)。下图 2 展示了一个输出例子。
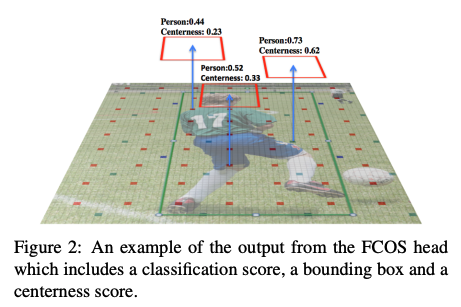
下表中,在 NMS 之前使用了真值来代替分类得分、位置偏差、centerness score。
- 分类得分使用什么来替代:在 gt 位置使用 1.0,或使用预测框和 gt 框的 IoU 得分(gt_IoU)
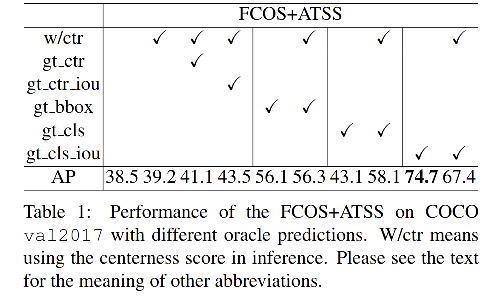
- 使用 FCOS+ATSS:39.2
- 使用真实 centerness 代替预测的 centerness 推理:41.1
- 使用 gt_IoU 代替预测的centerness 推理:43.5
- 上面几个对比结果证明,使用 centerness 或 IoU score 难以带来很大提升
上表中,效果最好的是 74.4 AP,这是使用 gt_IoU 来替代真实类别得分的情况,这实际上表明,对于大多数对象,在大量候选框中已经存在精确的局部边界框。
实现优秀检测性能的关键是准确地从池中选择出这些高质量的检测框,这些结果表明,用 gt_IoU 替代 ground-truth 类的分类分数是最有希望的选择措施。
三、方法
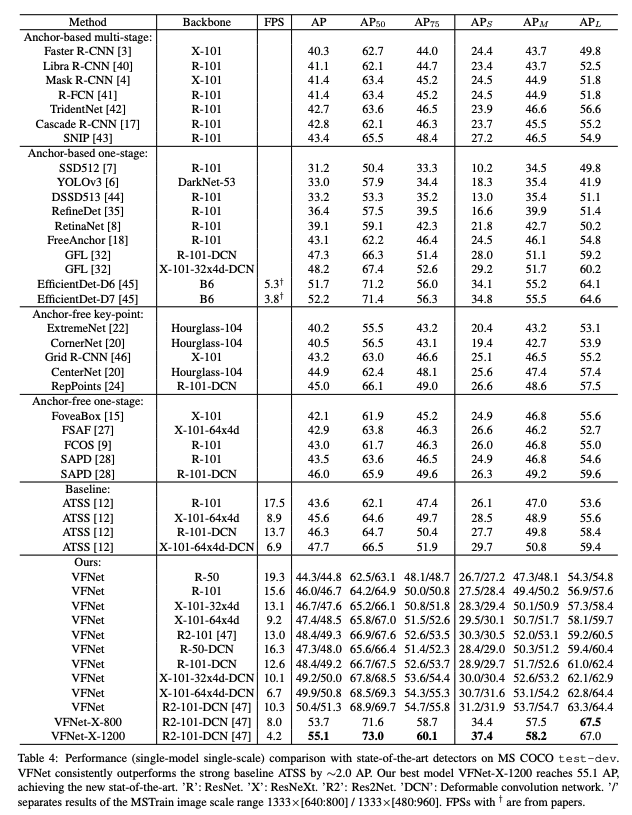
本文作者提出了基于 FCOS+ATSS 的 VarifocalNet(去掉了 centerness 分支),相比 FCOS+ATSS,该网络有三个新模块:
- varifocal loss
- star-shaped box feature representation
- bounding box refinement
3.1 IACS——IoU-Aware Classification Score
IACS:分类得分向量中的一个标量元素
- 真实类别位置的得分:预测框和真实框的 IoU
- 其他位置的得分:0
3.2 Varifocal loss
为了学习 IACS 得分,作者设计了一个 Varifocal Loss,灵感得益于 Focal Loss。
Focal Loss:
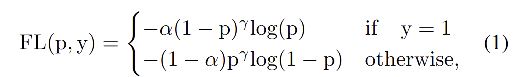
- p:预测的类别得分,
p
∈
[
0
,
1
]
p\in[0,1]
p∈[0,1]
- y:真实类别,
y
∈
±
1
y\in{\pm1}
y∈±1
- 降低前景/背景中,简单样例对 Loss 的贡献
Varifocal Loss:
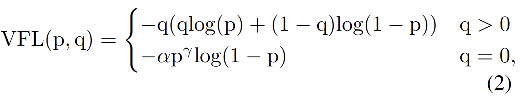
- p:预测的 IACS
- q:target score(真实类别:q 为预测和真值的 IoU,其他类别:q 为 0,如图 1)
Focal loss 对正负样本的处理是对等的(也就是使用相同的参数来加权),而 Varifocla loss 是使用不对称参数来对正负样本进行加权。
Varifocal loss 是如何不对等的处理前景和背景对 loss 的贡献的呢:VFL 只对负样本进行了的衰减,这是由于正样本太少了,希望更充分利用正样本的监督信号
- 对正样本,使用
q
q
q 进行了加权,如果正样本的 gt_IoU 很高时,则对 loss 的贡献更大一些,可以让网络聚焦于那些高质量的样本上,也就是说训练高质量的正例对AP的提升比低质量的更大一些。
- 对负样本,使用
p
γ
p^{\gamma}
pγ 进行了降权,降低了负例对 loss 的贡献,因为负样本的预测
p
p
p 肯定更小,取次幂后更小,这样就能够降低负样本对 loss 的整体贡献了

3.3 Star-Shaped Box Feature Representation
作者定义了一种 star-shaped 的 bounding-box 特征的表达方式,使用9个采样点来表达可变形卷积得到的 bounding-box,如图 1 黄色圈。
为什么用9个点来表达?
- 作者认为现在基于关键点的表达方法虽然有效,但是丢失了box中的特征和上下文信息
- 星型表达可以捕捉 bbox 的几何信息和其上下文信息,对比编码预测框和真实框的不对齐性很有效
首先,给定一个采样点(x,y),使用 3x3 卷积来回归初始 box (
l
′
,
t
′
,
r
′
,
b
′
l', t', r', b'
l′,t′,r′,b′),分别为其到左、上、右、下的距离(图1红框)。选中的9个点为黄色圈。相对位移作为可变形卷积的偏移,然后使用可变形卷积对这9个点卷积,来表示这个box。

4.4 Bounding-box refinement
作者还从 bounding box refinement 的角度来尝试提升目标定位的准确性,作者将 bbox refine 定义为残差学习问题。
- 初始的四个偏移定义为:
(
l
′
,
t
′
,
r
′
,
b
′
)
(l', t', r', b')
(l′,t′,r′,b′)
- 学习其对应的 star-shaped representation
- 根据star-shaped representation,学习四个缩放因子:
(
Δ
l
,
Δ
t
,
Δ
r
,
Δ
b
)
(\Delta l, \Delta t, \Delta r, \Delta b)
(Δl,Δt,Δr,Δb)
- refine 后的偏移:
(
l
,
t
,
r
,
b
)
=
(
Δ
l
×
l
′
,
Δ
t
×
t
′
,
Δ
r
×
r
′
,
Δ
b
×
b
′
)
(l, t, r, b) = (\Delta l\times l', \Delta t \times t', \Delta r \times r', \Delta b \times b')
(l,t,r,b)=(Δl×l′,Δt×t′,Δr×r′,Δb×b′)
4.5 VarifocalNet

框架结构和 FCOS 一致,主要差别在 heads 上
VFNet Heads 的组成:
- 定位:3 个 3x3 conv,一个子分支生成对应的距离向量,一个子分支生成 star-shaped,然后对框进行 refine
- 分类:IoU-aware classification score
4.6 Loss
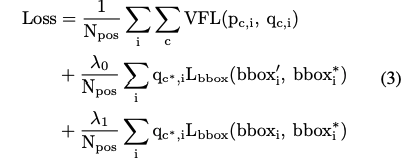
-
L
b
b
o
x
L_{bbox}
Lbbox:GIoU loss
四、效果
α
=
0.75
,
γ
=
2
\alpha=0.75, \gamma=2
α=0.75,γ=2
可视化效果:


五、代码
该文章实现基于mmdetection,本文代码的 github仓库中有安装方式,安装成功后,下载作者训练好的模型,修改coco数据路径即可成功训练和测试。
训练:
./tools/dist_train.sh configs/vfnet/vfnet_r50_fpn_1x_coco.py 8
测试:
# 测试指标
./tools/dist_test.sh configs/vfnet/vfnet_r50_fpn_1x_coco.py checkpoints/vfnet_r50_1x_41.6.pth 8 --eval bbox
# 可视化
./tools/dist_test.sh configs/vfnet/vfnet_r50_fpn_1x_coco.py checkpoints/vfnet_r50_1x_41.6.pth 8 --show-dir results/
demo:
python demo/image_demo.py demo/demo.jpg configs/vfnet/vfnet_r50_fpn_1x_coco.py checkpoints/vfnet_r50_1x_41.6.pth
5.1 修改数据集路径
在运行代码之前,一定要执行下面的语句,不然代码走的路径不对:
python setup.py develop
# 1
./configs/_base_/coco_detection.py
# 2
./configs/vfnet/vfnet_r50_fpn_1x_coco.py

5.2 VFNet
# vfnet_r50_fpn_1x_coco.py
# model settings
model = dict(
type='VFNet',
pretrained='torchvision://resnet50',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch'),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs=True,
extra_convs_on_inputs=False, # use P5
num_outs=5,
relu_before_extra_convs=True),
bbox_head=dict(
type='VFNetHead',
num_classes=80,
in_channels=256,
stacked_convs=3,
feat_channels=256,
strides=[8, 16, 32, 64, 128],
center_sampling=False,
dcn_on_last_conv=False,
use_atss=True,
use_vfl=True,
loss_cls=dict(
type='VarifocalLoss',
use_sigmoid=True,
alpha=0.75,
gamma=2.0,
iou_weighted=True,
loss_weight=1.0),
loss_bbox=dict(type='GIoULoss', loss_weight=1.5),
loss_bbox_refine=dict(type='GIoULoss', loss_weight=2.0)),
# training and testing settings
train_cfg=dict(
assigner=dict(type='ATSSAssigner', topk=9),
allowed_border=-1,
pos_weight=-1,
debug=False),
test_cfg=dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.6),
max_per_img=100))
VFNet Head:
/mmdet/models/dense_heads/vfnet_head.py
(bbox_head): VFNetHead(
(loss_cls): VarifocalLoss()
(loss_bbox): GIoULoss()
(cls_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
(2): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
)
(reg_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
(2): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
)
(relu): ReLU(inplace=True)
(vfnet_reg_conv): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
(vfnet_reg): Conv2d(256, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(scales): ModuleList(
(0): Scale()
(1): Scale()
(2): Scale()
(3): Scale()
(4): Scale()
)
(vfnet_reg_refine_dconv): DeformConv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
dilation=(1, 1),
groups=1,
deform_groups=1,
deform_groups=False)
(vfnet_reg_refine): Conv2d(256, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(scales_refine): ModuleList(
(0): Scale()
(1): Scale()
(2): Scale()
(3): Scale()
(4): Scale()
)
(vfnet_cls_dconv): DeformConv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
dilation=(1, 1),
groups=1,
deform_groups=1,
deform_groups=False)
(vfnet_cls): Conv2d(256, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(loss_bbox_refine): GIoULoss()
)
init_cfg={'type': 'Normal', 'layer': 'Conv2d', 'std': 0.01, 'override': {'type': 'Normal', 'name': 'vfnet_cls', 'std': 0.01, 'bias_prob': 0.01}}
)
VFNet model:
VFNet(
(backbone): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
)
init_cfg={'type': 'Pretrained', 'checkpoint': 'torchvision://resnet50'}
(neck): FPN(
(lateral_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
)
(1): ConvModule(
(conv): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
)
(2): ConvModule(
(conv): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
)
)
(fpn_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(2): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(3): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
(4): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
)
)
init_cfg={'type': 'Xavier', 'layer': 'Conv2d', 'distribution': 'uniform'}
(bbox_head): VFNetHead(
(loss_cls): VarifocalLoss()
(loss_bbox): GIoULoss()
(cls_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
(2): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
)
(reg_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
(2): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
)
(relu): ReLU(inplace=True)
(vfnet_reg_conv): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
(activate): ReLU(inplace=True)
)
(vfnet_reg): Conv2d(256, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(scales): ModuleList(
(0): Scale()
(1): Scale()
(2): Scale()
(3): Scale()
(4): Scale()
)
(vfnet_reg_refine_dconv): DeformConv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
dilation=(1, 1),
groups=1,
deform_groups=1,
deform_groups=False)
(vfnet_reg_refine): Conv2d(256, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(scales_refine): ModuleList(
(0): Scale()
(1): Scale()
(2): Scale()
(3): Scale()
(4): Scale()
)
(vfnet_cls_dconv): DeformConv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
dilation=(1, 1),
groups=1,
deform_groups=1,
deform_groups=False)
(vfnet_cls): Conv2d(256, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(loss_bbox_refine): GIoULoss()
)
init_cfg={'type': 'Normal', 'layer': 'Conv2d', 'std': 0.01, 'override': {'type': 'Normal', 'name': 'vfnet_cls', 'std': 0.01, 'bias_prob': 0.01}}
)
Varifocal loss:
def varifocal_loss(pred,
target,
weight=None,
alpha=0.75,
gamma=2.0,
iou_weighted=True,
reduction='mean',
avg_factor=None):
"""`Varifocal Loss <https://arxiv.org/abs/2008.13367>`_
Args:
pred (torch.Tensor): The prediction with shape (N, C), C is the
number of classes
target (torch.Tensor): The learning target of the iou-aware
classification score with shape (N, C), C is the number of classes.
weight (torch.Tensor, optional): The weight of loss for each
prediction. Defaults to None.
alpha (float, optional): A balance factor for the negative part of
Varifocal Loss, which is different from the alpha of Focal Loss.
Defaults to 0.75.
gamma (float, optional): The gamma for calculating the modulating
factor. Defaults to 2.0.
iou_weighted (bool, optional): Whether to weight the loss of the
positive example with the iou target. Defaults to True.
reduction (str, optional): The method used to reduce the loss into
a scalar. Defaults to 'mean'. Options are "none", "mean" and
"sum".
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
"""
# pred and target should be of the same size
assert pred.size() == target.size()
import pdb; pdb.set_trace();
pred_sigmoid = pred.sigmoid()
target = target.type_as(pred)
if iou_weighted:
focal_weight = target * (target > 0.0).float() + \
alpha * (pred_sigmoid - target).abs().pow(gamma) * \
(target <= 0.0).float()
else:
focal_weight = (target > 0.0).float() + \
alpha * (pred_sigmoid - target).abs().pow(gamma) * \
(target <= 0.0).float()
loss = F.binary_cross_entropy_with_logits(
pred, target, reduction='none') * focal_weight
loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
return loss