1.Spark概述
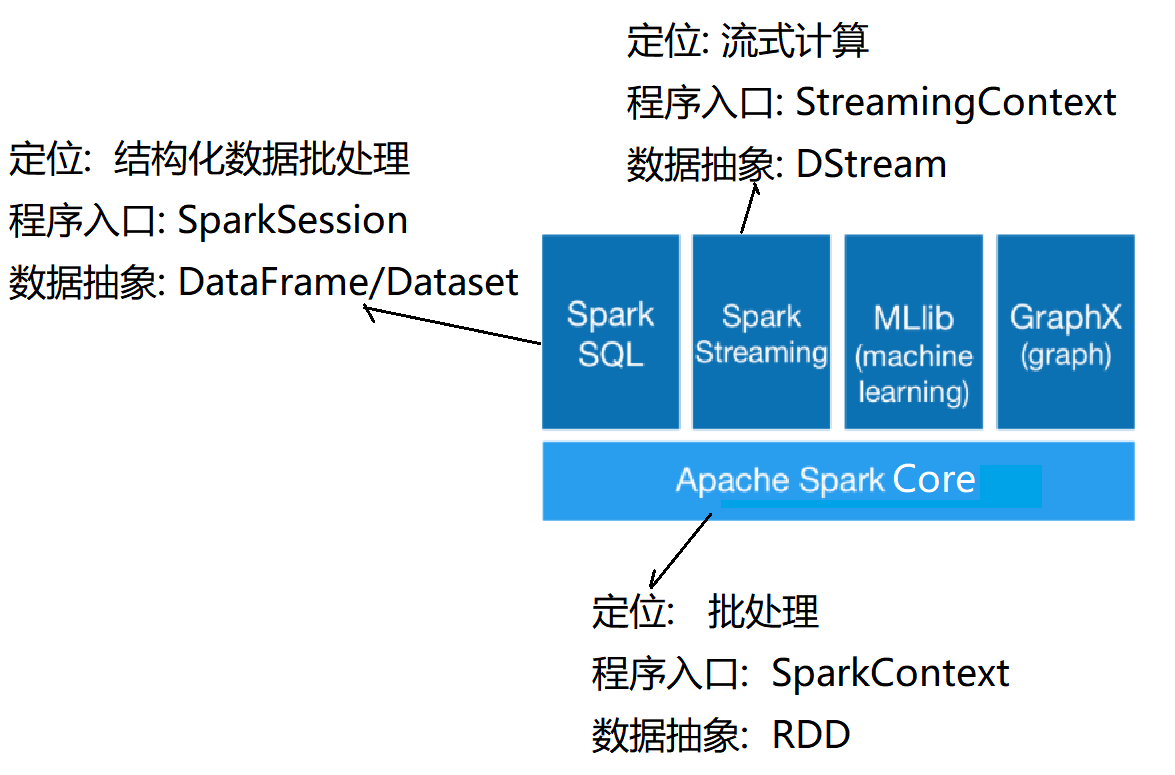
Spark是一个支持多语言的数据计算、科学计算、机器学习引擎、同时支持单节点或者集群运行模式
其强大的功能包括:批处理、结构化的SQL计算、流式计算、机器学习库、图计算等。
2.Spark集群环境的搭建
1.下载解压安装包
2.修改配置文件
2.1 spark-env.sh
# 配置hadoop集群的配置文件目录
# 目的是让Spark可以读取到HDFS数据
HADOOP_CONF_DIR=/opt/hadoop-2.7.7/etc/hadoop
# 配置Spark集群主节点的主机名和端口
SPARK_MASTER_HOST=host02
# Spark任务提交时的服务端口
SPARK_MASTER_PORT=7077
# SparkMaster WebUI 端口
SPARK_MASTER_WEBUI_PORT=8080
# 配置Java home
JAVA_HOME=/opt/jdk1.8
2.2 spark-defaults.conf
# 配置Spark相关配置
# master节点的配置
spark.master spark://host02:7077
2.3 works
host01
host02
host03
2.4 分发安装包
scp -r /opt/spark-3.1.2 host01:/opt/
scp -r /opt/spark-3.1.2 host02:/opt/
2.5 配置环境变量
echo 'export SPARK_HOME=/opt/spark-3.1.2' >> /etc/profile
echo 'export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH' >> /etc/profile
source /etc/profile
2.6 启动集群
start-spark-all.sh
2.7 访问SparkMaster管理界面
http://host02:8080/