【目的】
ChatGPT令人震撼的冲击下,笔者转向NLM的Transformer模型,ChatGLM作为清华开源的大语言模型,笔者尝试了其环境配置,为相关理论学习奠定基础。本文用于备忘与学习,无商业用途。
【参考】
ChatGLM的源码下载链接:
GitHub - THUDM/ChatGLM-6B: ChatGLM-6B:开源双语对话语言模型 | An Open Bilingual Dialogue Language ModelChatGLM的离线模型国外链接:
THUDM/chatglm-6b at main
ChatGLM的离线模型国内链接(注意:国内链接只包含主要的模型节点文件,需要github下载响应的配置文件):
清华大学云盘
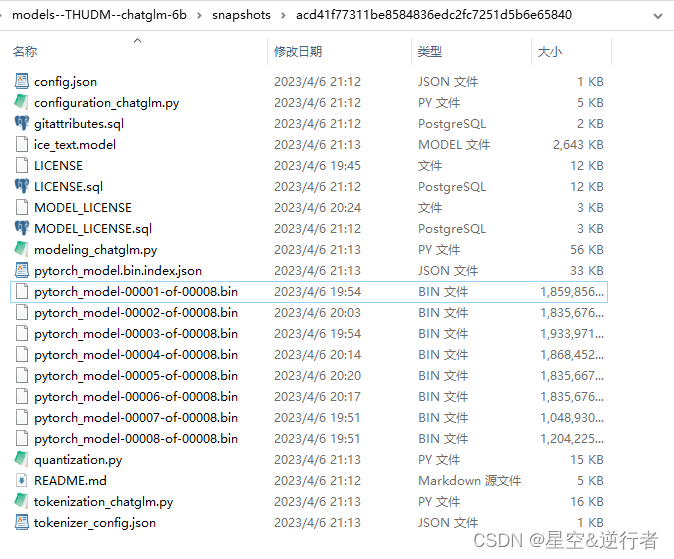
完整的模型数据结构如下图:

【步骤】
1、下载Anaconda并安装,安装流程网上搜索或参考如下博文:
anaconda安装配置教程_anaconda安装教程_振华OPPO的博客-CSDN博客
2、进入anaconda Prompt, 创建并激活环境
# 创建环境
conda create -n pytorch python=3.7
conda activate pytorch

3、进入源码文件,按要求配置环境
pip install -r requirements.txt
注意:3.7python环境下pytorch 的版本需要与你的计算显卡参数相匹配,便于配置CUDA,因此,在安装完配置环境后,需要卸载调pytorch相关安装包,后面根据CUDA要求重新安装
uninstall torch torchaudio torchvision
4、配置CUDA环境 (安装前需要确定后面要安装的pytorch 的版本)
参考链接:
踩坑总结!Windows系统安装CUDA、cuDNN_cuda安装时自动重启_Angus *的博客-CSDN博客
配置大致流程:查看本机显卡匹配的CUDA,官网下载CUDA安装包,CUDA安装,cuDNN文件下载与复制到相应文件夹
Pytorch与CUDA的版本对应参考官网:
Start Locally | PyTorch

5、配置pytorch,选择与CUDA相匹配的pytorch版本
pytorch从如下链接离线下载并安装。清华源会默认安装CPU版本的,因此GPU的pytorch推荐离线安装
Index of /anaconda/cloud/pytorch/win-64/ | 北京外国语大学开源软件镜像站 | BFSU Open Source Mirror
conda install --use-local D:\pytorch-1.13.1-py3.7_cuda11.6_cudnn8_0.tar.bz2
torchaudio 和torchvision通过清华源安装
pip install torchaudio -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install torchvision -i https://pypi.mirrors.ustc.edu.cn/simple/
6、将下载的THUDM/chatglm-6b 模型放到huggingface的默认读取文件夹内:
C:\Users\HP\.cache\huggingface\hub\models--THUDM--chatglm-6b\snapshots\acd41f77311be8584836edc2fc7251d5b6e65840
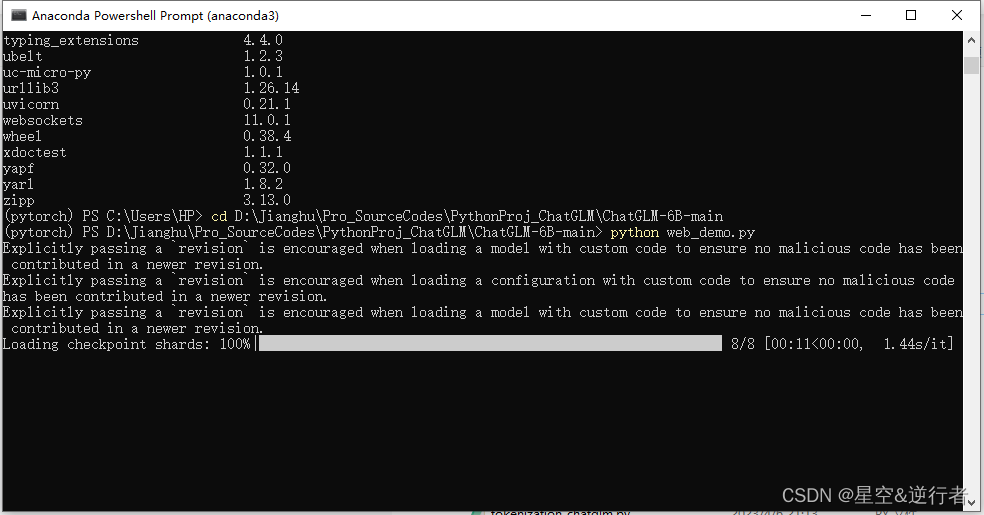
7、模型运行
8、浏览器显示结果:
