一. ChatGPT
1. ChatGPT的自我介绍

2. ChatGPT的前世
2.1GPT-3是啥?
- General Pre-Training(GPT),即通用预训练语言模型,是一种利用Transformer作为特征抽取器,基于语言模型进行训练的预训练语言模型。所以,理解GPT主要熟悉两个方面即可,即语言模型和其由Transformer组成的结构。
- 将无监督学习有监督模型的预训练目标,因此叫做生成式预训练(Generative Pre-training,GPT)
| 模型 |
发布时间 |
参数量 |
预训练数据量 |
训练逻辑 |
数据集 |
为了解决的问题 |
最终性能 |
| GPT |
2018 年 6 月 |
1.17 亿 |
约 5GB |
无监督学习,是先通过在无标签的数据上学习一个生成式的语言模型,然后再根据特定热任务进行有监督的微调 |
BooksCorpus的数据集,这个数据集包含 7,000 本没有发布的书籍。作者选这个数据集的原因有二:1. 数据集拥有更长的上下文依赖关系,使得模型能学得更长期的依赖关系;2. 这些书籍因为没有发布,所以很难在下游数据集上见到,更能验证模型的泛化能力。 |
1.监督学习需要大量的标注数据,高质量的标注数据往往很难获得,所以使用无监督的无标签的数据进行第一步的学习 2.根据一个任务训练的模型很难泛化到其它任务中,具有任务输入变换能力 |
GPT-1在未经微调的任务上虽然也有一定效果,但是其泛化能力远远低于经过微调的有监督任务,说明了GPT-1只是一个简单的领域专家,而非通用的语言学家。 |
| GPT-2 |
2019 年 2 月 |
15 亿 |
40GB |
多任务学习,旨在训练一个泛化能力更强的词向量模型,它并没有对GPT-1的网络进行过多的结构的创新与设计,只是使用了更多的网络参数和更大的数据集 |
取自于Reddit上高赞的文章,命名为WebText。数据集共有约800万篇文章,累计体积约40G。 |
GPT-2的学习目标是使用无监督的预训练模型做有监督的任务。作者认为,当一个语言模型的容量足够大时,它就足以覆盖所有的有监督任务,也就是说所有的有监督学习都是无监督语言模型的一个子集 |
GPT-2表明随着模型容量和数据量的增大,其潜能还有进一步开发的空间,因此也诞生了GPT-3 |
| GPT-3 |
2020 年 5 月 |
1,750 亿 |
45TB |
海量参数,海量数据 in-context learning(情境学习) |
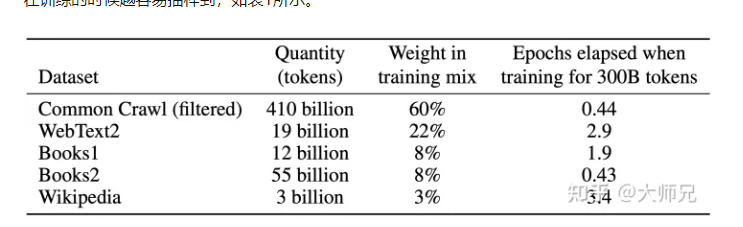
|
除了几个常见的NLP任务,GPT-3还在很多非常困难的任务上也有惊艳的表现,例如撰写人类难以判别的文章,甚至编写SQL查询语句,React或者JavaScript代码等。而这些强大能力的能力则依赖于GPT-3疯狂的 1,750 亿的参数量, 45 TB的训练数据以及高达 1,200 万美元的训练费用。 |
2.2让人惊叹的参数量
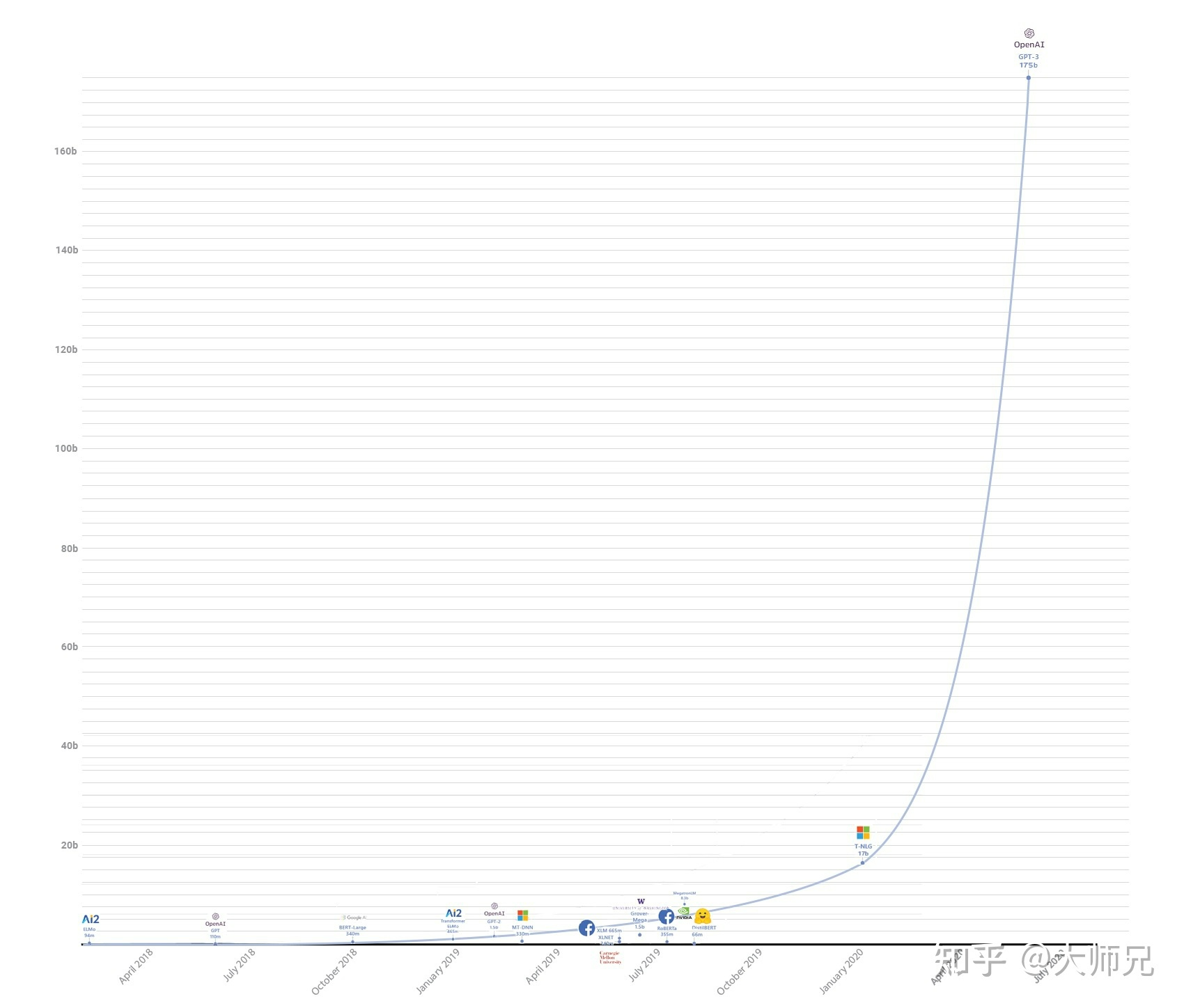
2.3衍生的大模型们

3.总结GPT家族
GPT系列从1到3,通通采用的是transformer架构,可以说模型结构并没有创新性的设计。GPT-3的本质还是通过海量的参数学习海量的数据,然后依赖transformer强大的拟合能力使得模型能够收敛。
在微软的资金支持下,这更像是一场炫富:1750亿的参数,31个分工明确的作者,超强算力的计算机( 285,000 个CPU, 10,000 个GPU),1200万的训练费用,45TB的训练数据。当然现在利用GPT-3的API构建的各个应用程序也是很多, 各种好玩的demo gpt-3-apps API(2021年3月)
GPT-3可以完成一些令人感到惊喜的任务,但是GPT-3也不是万能的,对于一些明显不在这个分布或者和这个分布有冲突的任务来说,GPT-3还是无能为力的。例如通过目前的测试来看,GPT-3还有很多缺点的:
- 对于一些命题没有意义的问题,GPT-3不会判断命题有效与否,而是拟合一个没有意义的答案出来;
- 由于40TB海量数据的存在,很难保证GPT-3生成的文章不包含一些非常敏感的内容,例如种族歧视,性别歧视,宗教偏见等;
- 受限于transformer的建模能力,GPT-3并不能保证生成的一篇长文章或者一本书籍的连贯性,存在下文不停重复上文的问题。
所以,针对这些问题,就会继续发展后续的模型。
4.ChatGPT的今生
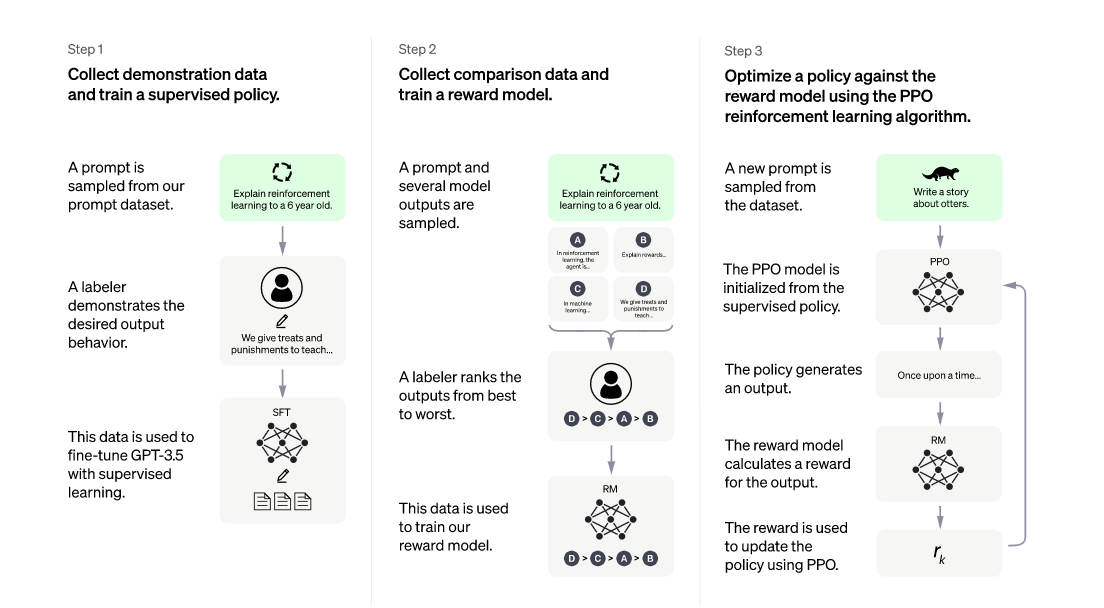
我们使用来自人类反馈的强化学习(RLHF)来训练这个模型,使用的方法与InstructGPT相同但数据收集设置略有不同。
可以看一下InstructGPT与GPT-3的差异



引入“人工标注数据+强化学习”(RLHF,Reinforcement Learning from Human Feedback ,这里的人工反馈其实就是人工标注数据(高质量的数据集)来不断Fine-tune预训练语言模型,主要目的是让LLM模型学会理解人类的命令指令的含义(比如给我写一段小作文生成类问题、知识回答类问题、头脑风暴类问题等不同类型的命令),以及让LLM学会判断对于给定的prompt输入指令(用户的问题),什么样的答案是优质的(富含信息、内容丰富、对用户有帮助、无害、不包含歧视信息等多种标准)。
- 第一步:监督微调训练了一个初始模型:人类人工智能训练员提供对话,他们在对话中扮演双方-用户和人工智能助手。我们允许培训人员获取模型书面建议,以帮助他们构思他们的回答。为了让GPT 3.5初步具备理解指令中蕴含的意图,首先会从测试用户提交的prompt(就是指令或问题)中随机抽取一批,靠专业的标注人员,给出指定prompt的高质量答案,然后用这些人工标注好的<prompt,answer>数据来Fine-tune GPT 3.5模型。
- 第二步:在这个阶段里,首先由冷启动后的监督策略模型为每个prompt产生K个结果,人工根据结果质量由高到低排序,以此作为训练数据,通过pair-wise learning to rank模式来训练回报模型。对于学好的RM模型来说,输入<prompt,answer>,输出结果的质量得分,得分越高说明产生的回答质量越高。
- 第三步:使用这些奖励模型,使用近似值策略优化(Proximal Policy Optimization (PPO)对模型进行微调。对这个过程进行了多次迭代。
5. ChatGPT的使用案例
尽管官方对于ChatGPT的能力描述很简单,但是从实际大家使用的期刊来看,这个系统可以做的事情远超大家想象。这里我们会列举目前收集的ChatGPT的使用案例,供大家参考。
6. ChatGPT 可能存在的问题
- ChatGPT有时会写出看似合理实则错误甚至荒谬的答案 因为:
-
- 在强化学习训练期间,目前没有任何真相来源;
- 训练模型更加谨慎会导致它拒绝本来可以正确回答的问题;
- 监督训练可能误导模型,因为理想的答案取决于模型知道什么,而不是人类训练者知道什么。
- ChatGPT对输入的局部修改或多次尝试同一问题很敏感
-
- 例如,修改问题中的某个词语,ChatGPT可能会给出完全不同的回答。或者同一问题一开始无法回答,换一种措辞再问一遍又能正确回答。
- ChatGPT的回答通常过于冗长,过度使用某些短语
-
- 例如ChatGPT会重申它是OpenAI训练的语言模型。这些问题源于训练数据的偏差(训练师更喜欢看起来更全面的较长答案)和众所周知的优化问题。
-
- 理想情况下,当用户问的问题不明确时,模型应该提出反问来明确问题。然而目前ChatGPT模型通常会猜测用户意图,给出回答
-
- 尽管OpenAI努力让模型拒绝不当问题,但它有时会难免还是会响应有害的指令或表现出偏激行为。OpenAI使用了Moderation API来警告或拦截某些类型的不安全内容,但可能目前还是会有一些误判。OpenAI希望通过收集用户反馈,以众包的形式来改进系统的工作。
7. 总结
尽管ChatGPT还存在上述局限,但在我的体验过程中,ChatGPT表现出的理解力和回复的准确度远超我的预计,让我直呼“牛逼”。如果ChatGPT正式开放出来,很有可能将是:“外事不决问谷歌,内事不决问百度,代码不会问ChatGPT”的格局。
目前ChatGPT还没联网,一旦它连上网络,可以从互联网获取更多知识和信息(有很多文章在设计他与搜索引擎相结合的模式,设想当API开放之时,很快就会有相关的产品面世...),ChatGPT的潜力将得到更大的释放,甚至达到令人恐怖的程度。我相信这一天离我们不会很远!
二. 代码智能
1. 现有产品
业界标杆CodeX (OpenAI) -> 收费产品: GitHub Copilot

AlphaCode(Google Deep Mind)
CodeGen(salesforce)
盘古coder(华为诺亚方舟实验室) 官网
各个模型的性能对比:
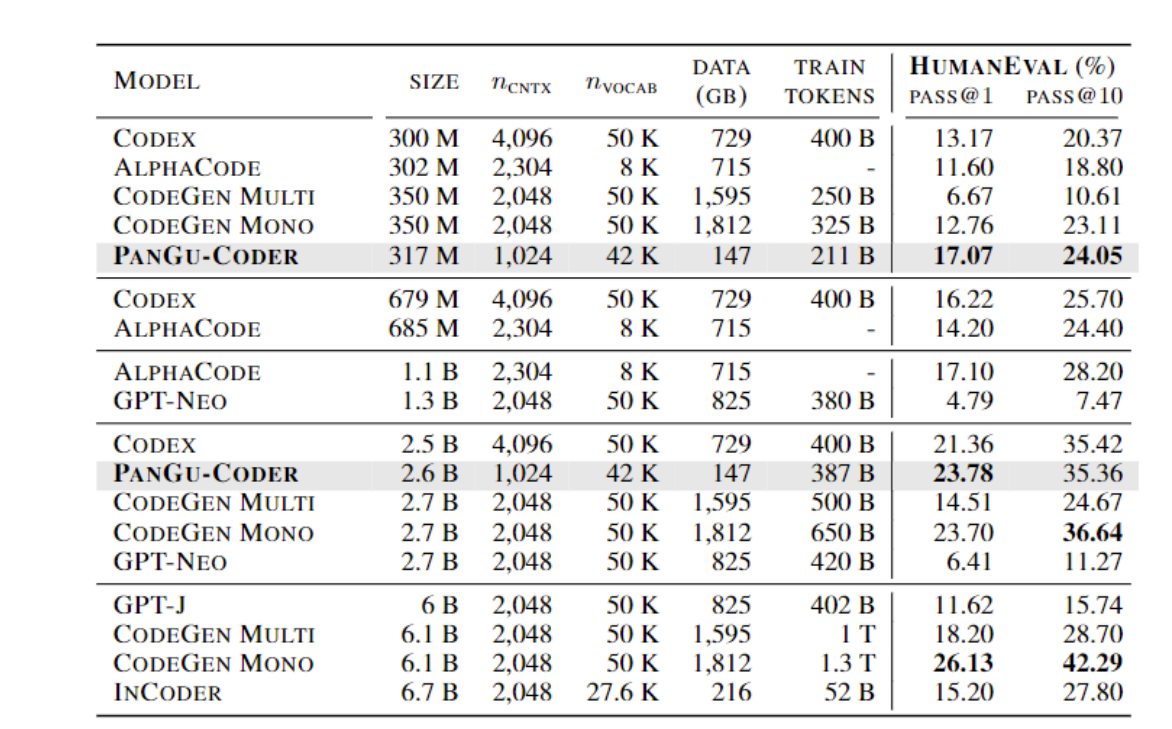
代码比自然语言的编解码有相同之处,也更容易去编码,更容易理解,因为相对来说,结构化更明确,就是很好理解的一个例子就是英文的语义理解是远比中文要简单的。
2. 基线任务 论坛

2.1 代码表示
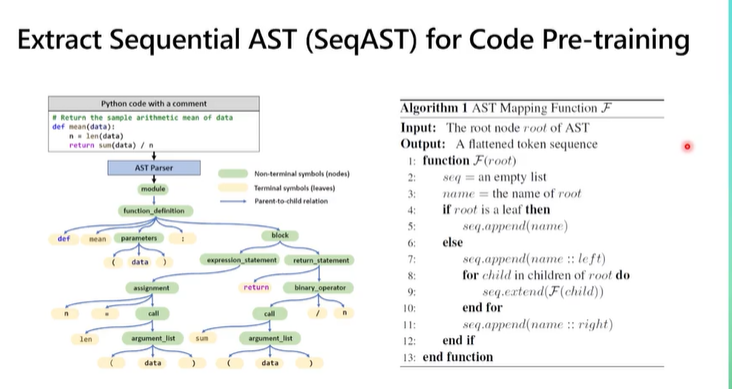
抽象语法树(abstract syntax code,AST)是源代码的抽象语法结构的树状表示,树上的每个节点都表示源代码中的一种结构。
2.2 代码检索
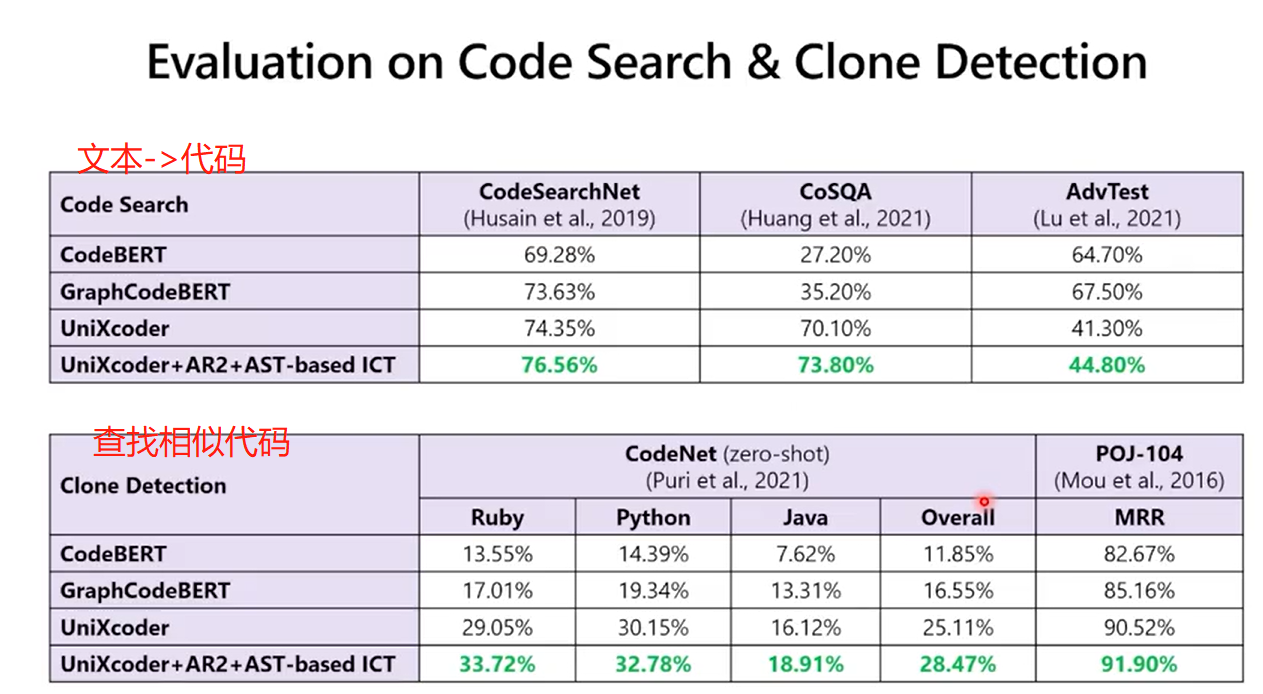
2.3 代码生成
可以把其理解为是概率统计模型,预测后代码是什么。难点:但是有时候又不能只依赖于前面几个token,可能是要看整个句子,甚至是最一开始定义的变量。
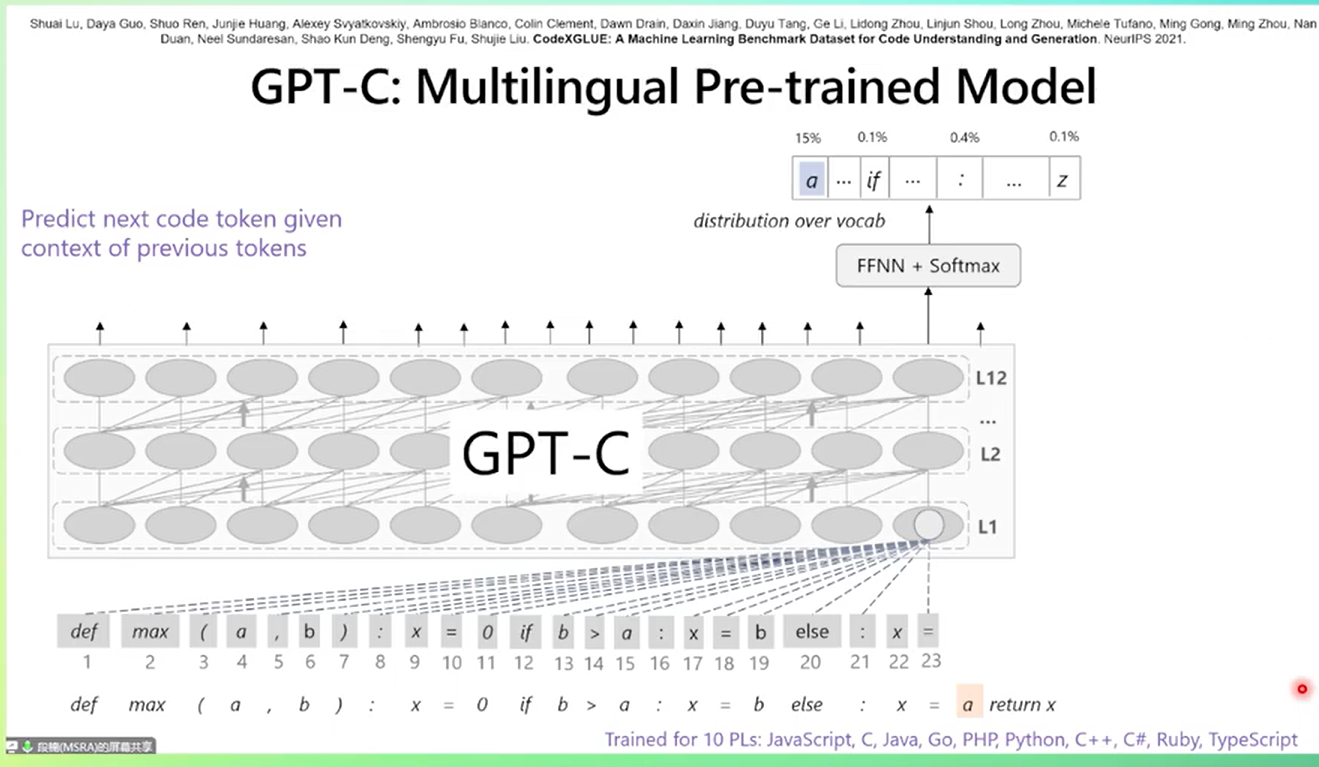
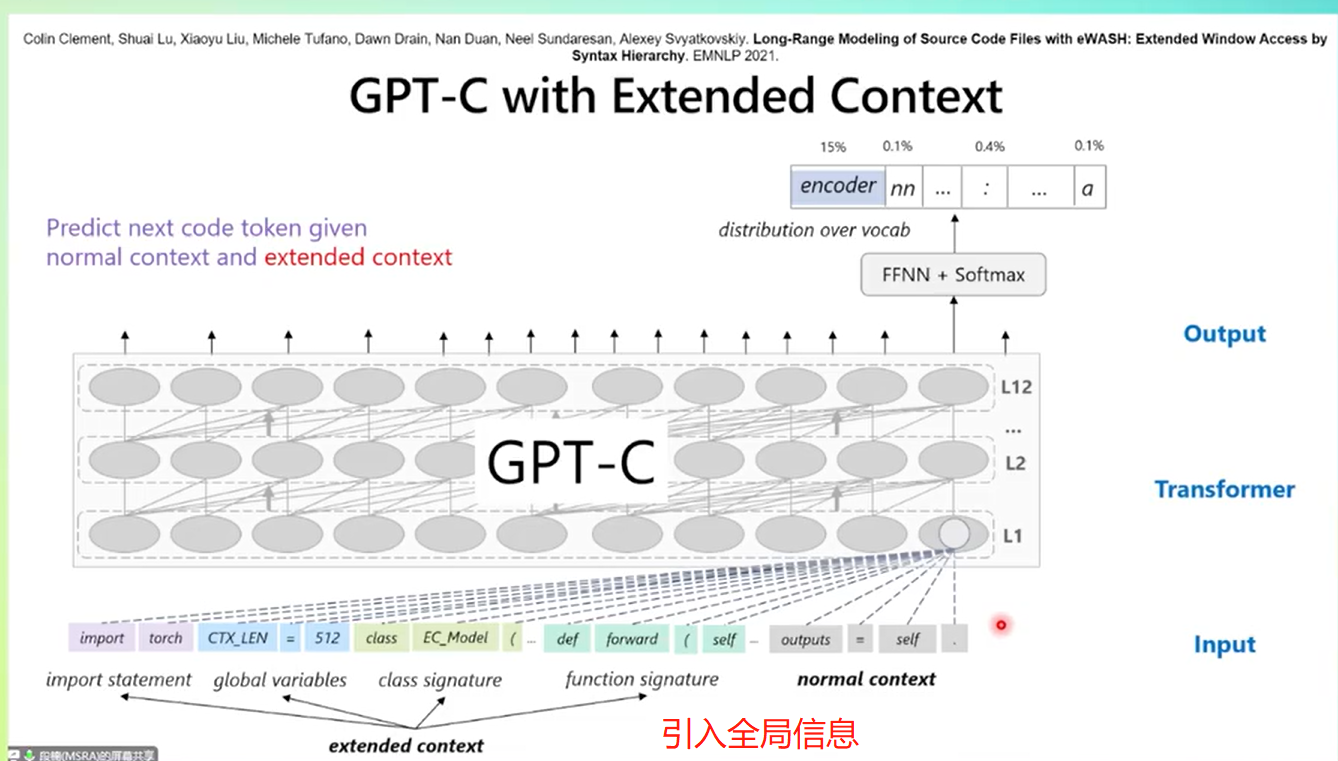
代码补全
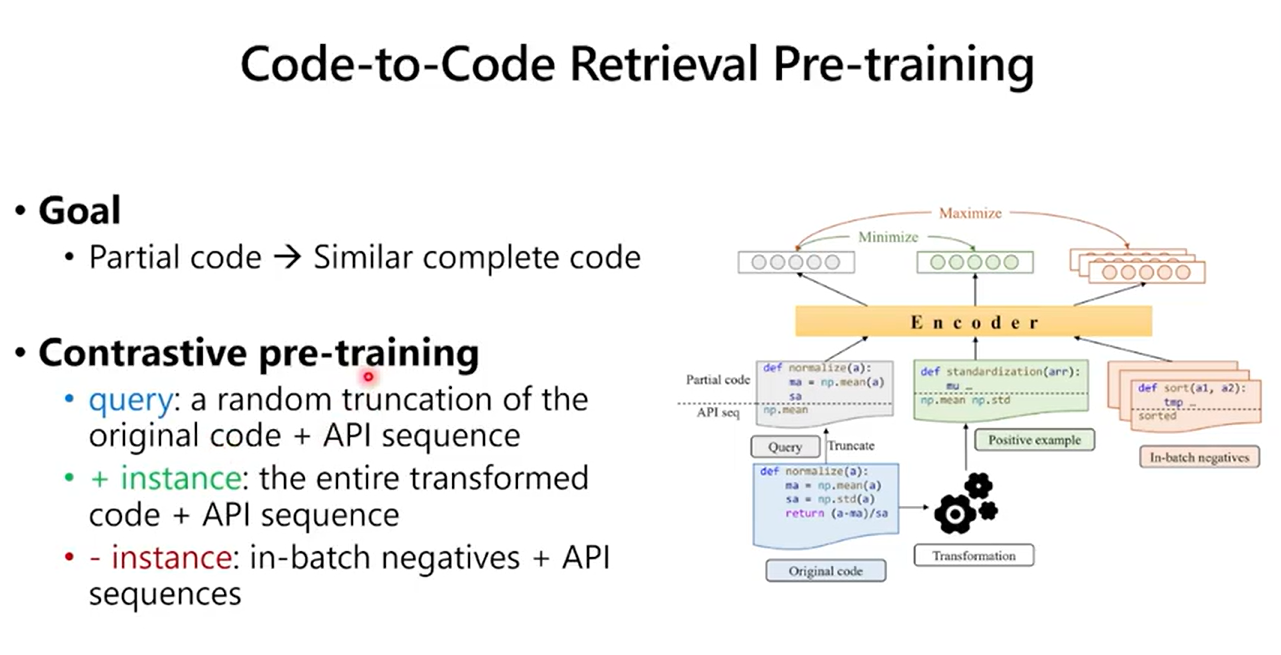
数据增强方法

2.4 代码审查
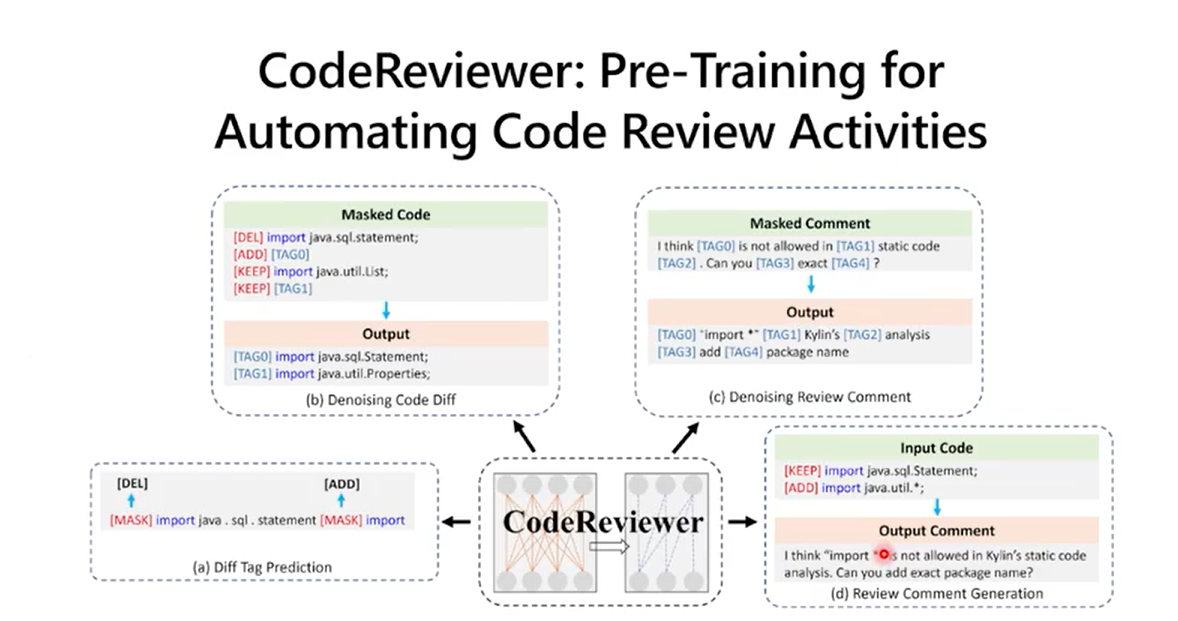
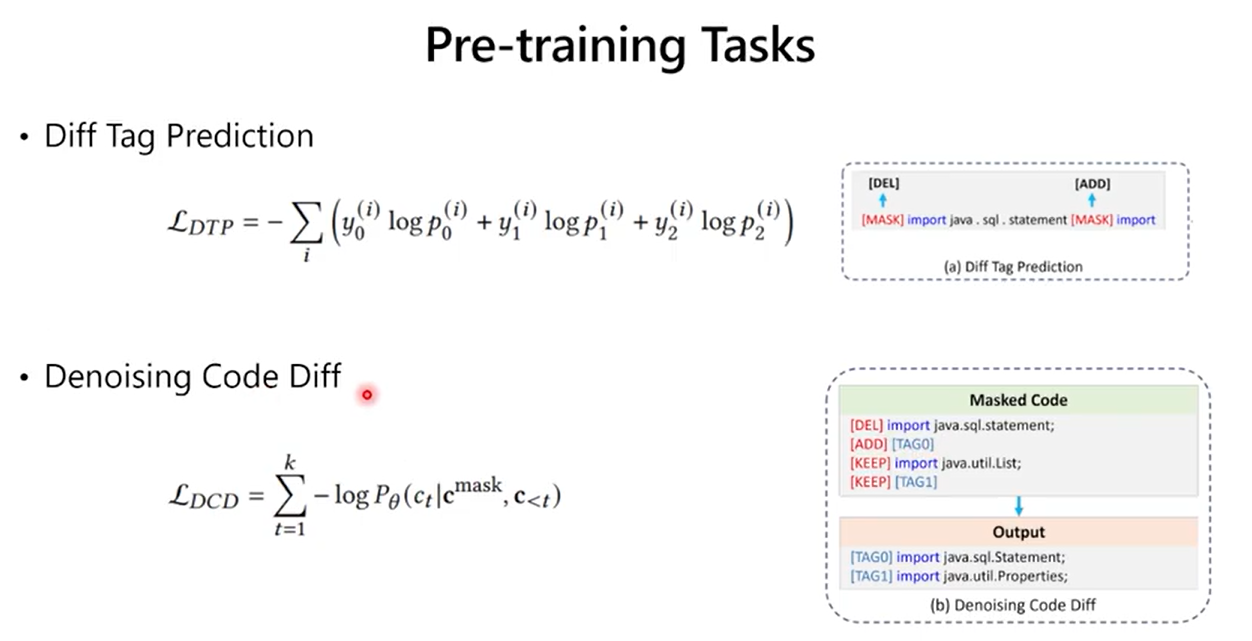
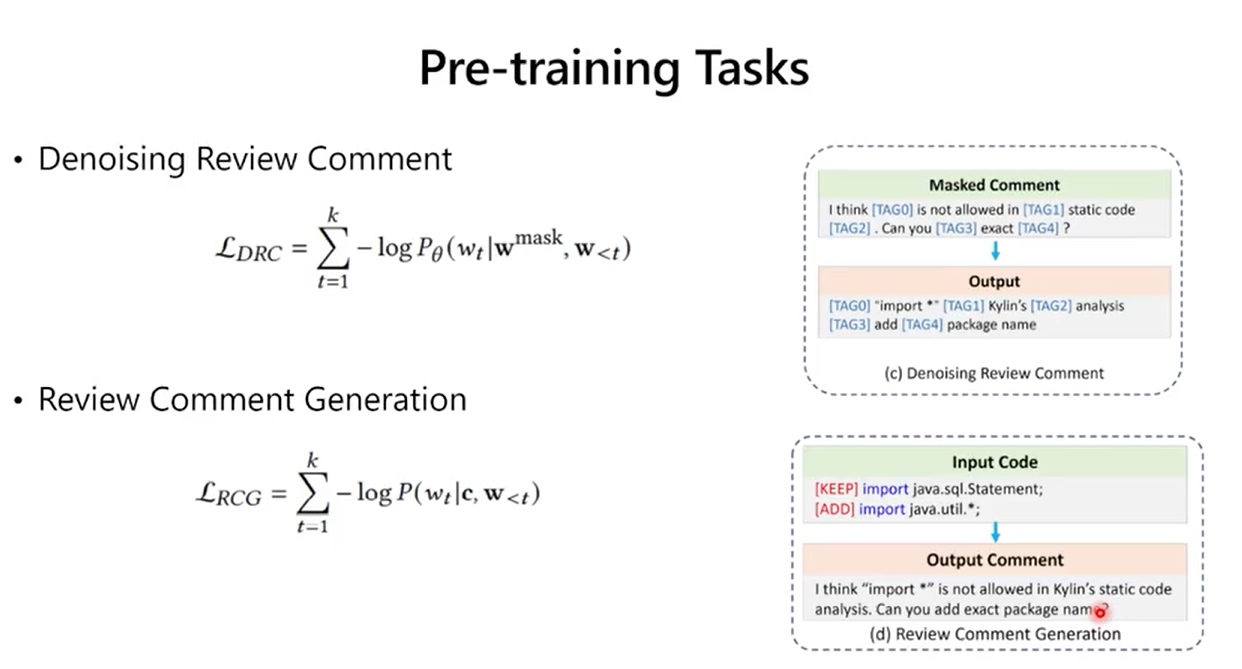
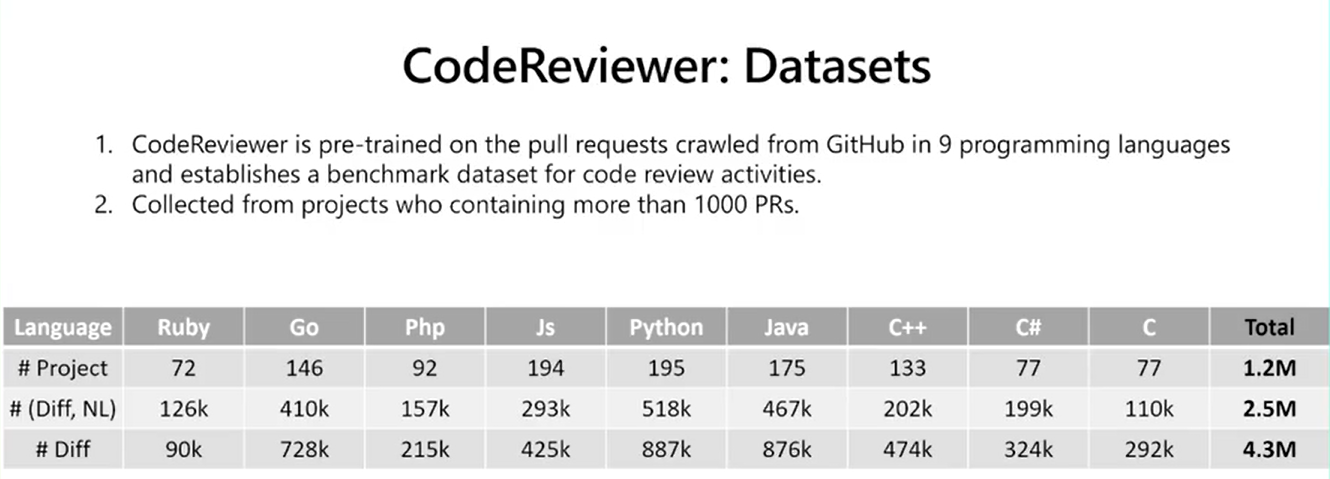
2.5 评测基线
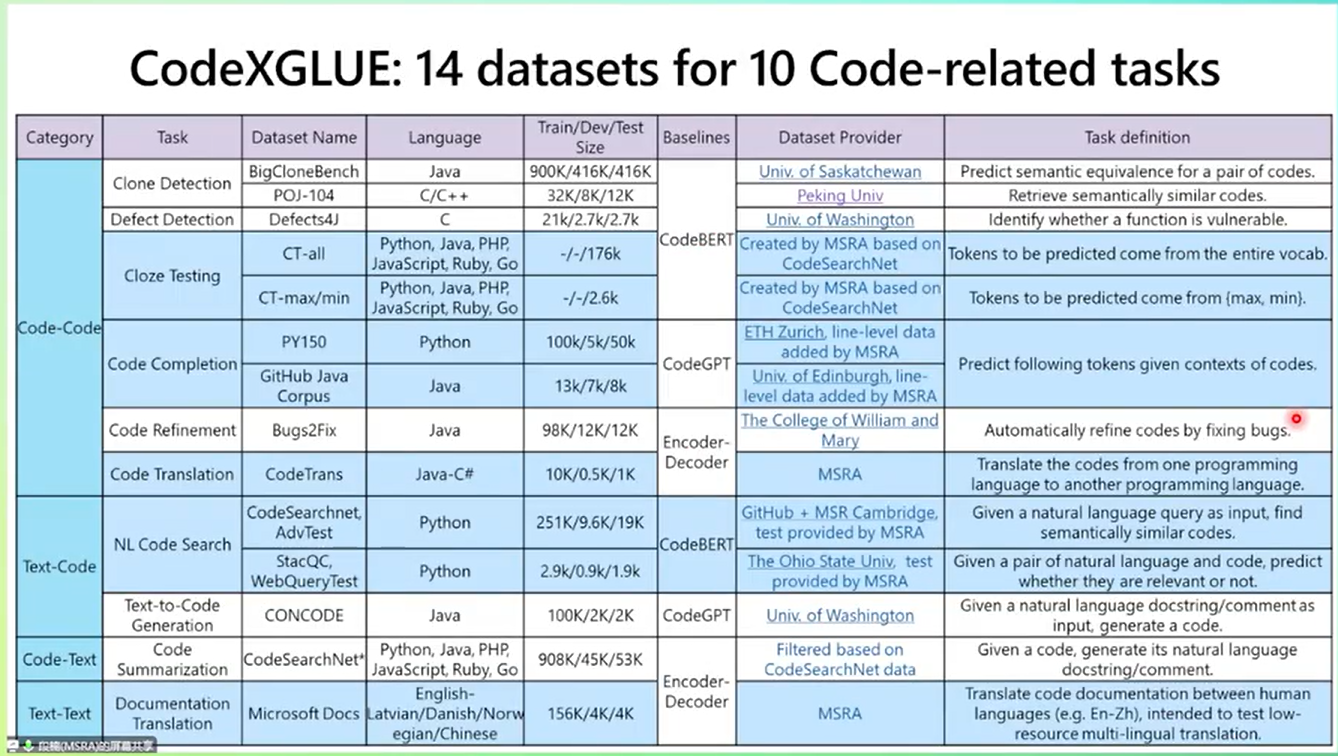
3. 总结
有一些好的声音:“一人一model,效率大大提升” 如何不被 OpenAI 取代?
也有一些不好的声音:“ChatGPT产生的答案有很高的错误率“主要问题是,虽然ChatGPT产生的答案有很高的错误率,但它们往往第一眼看起来可能是对的,而且使用人工智能导致答案非常容易生成。我们需要减少这些内容。目前在Stack Overflow上使用ChatGPT创建帖子的行为已经被禁止。如果用户在此临时规定发布后使用了ChatGPT,将会受到制裁。”Stack Overflow的运营人员表示。”
仅代表个人观点:ChatGPT绝对是一个现象级的产品,发布不到10天超100W的用户量,是比Stable Diffusion 更有竞争力的一个模型和研究趋势。让更多的人愿意用很低的成本去完成一些工作,且OPENAI他们一直知道现有模型的一些缺陷和问题,可以从一个个迭代的模型和一些功能来看,他们也会一直在尝试优化和规避之前存在的一些问题。
训练AI,就像教育孩子一样,不能因为他们在小学的年龄无法参与高校竞赛或者世界会议就把他们封闭起来,我们往往会继续让他们参与更高难度的学习,指引他们去完成看似正确的事。
reference:
张俊林 ChatGPT会不会成为下一代搜索引擎
预训练语言模型之GPT-1,GPT-2和GPT-3