前言: innodb是事务安全的mysql存储引擎,设计上采用了类似于Oracle数据库的架构.
1.innodb存储引擎概述
innodb是第一个完整支持ACID事务的mysql存储引擎,特点是行锁设计,支持mvcc,支持外检,提供一致性非锁定读,同事被设计用来最有效地利用及上使用内存和cpu
2.innodb体系架构
innodb有多个内存块,可以认为这些内存块组成了一个大的内存池,负责
维护所有进程/线程需要访问的多个内部数据结构
缓存磁盘上数据,方便快速读取
重做日志redo log 缓冲
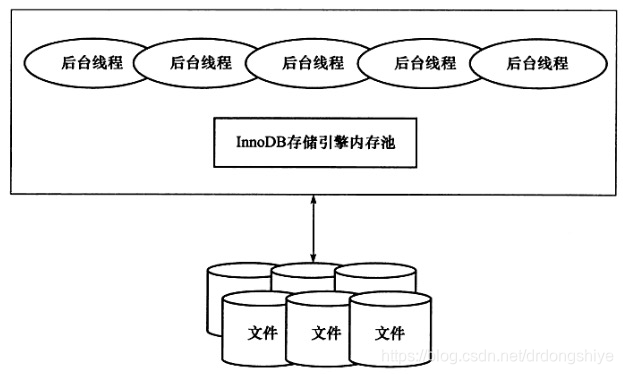
后台线程的作用是负责刷新内存池中的数据,保证缓冲池中的内存缓存的是最新的数据;此外将已修改的数据文件刷新到磁盘文件,同时保证在数据发生异常的情况下innodb能回复到正常运行的状态
2.1后台线程
innodb是多线程模型
Master Thread:核心的后台线程,负责将缓冲区数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新,合并插入缓冲,undo页的回收
IO Thread:使用了大量AIO处理写io请求,而Io thread主要负责这些io请求的回调处理,目前5.7版本linux环境 有10个线程 4个read 4个write 1个insert buffer 1个log
Purge Thread:事务被提交后,其使用的undo log可能不需要了,英雌purgeThread需要回收已经使用并分配的undo页,从innodb1.1之后开始从master thread交给了purge thread 为了减轻master thread 压力
Page Cleaner Thread:在innodb1.2.x版本引入为了处理咱也刷新操作,同时减轻master thread 压力
2.2内存
1.缓冲池
innodb基于磁盘存储,并将记录按照页的方式进行管理,因此可将其认为基于磁盘的数据库系统;在数据库系统中,由于cpu和磁盘速度相差巨大,所以基于磁盘的系统通常使用缓冲池来提高数据库整体性能;
缓冲池简单来说是一块内存区域,通过内存速度弥补磁盘对性能影响.在数据库进行读取页操作时,首先从磁盘读到的页放在缓冲池,这个过程叫将页"FIX"在缓冲池中.下次再读相同的页时,先判断缓冲池中是否存在
对于修改,先修改缓冲池的页,然后再以一定频率刷新到磁盘上,需要注意的是,页从缓冲池刷新回磁盘的操作并不是在每次页发生更新时触发,而是通过一种checkpoint的机制刷新回磁盘
缓冲池可通过 innodb_buffer_pool_size可设置,缓冲池中缓存的数据页类型有:索引页,数据页,undo也,插入缓冲insert buffer,自适应哈希索引,innodb存储的锁信息,数据字典信息

可通过观察缓冲池状态
select * from information_schema.INNODB_buffer_pool_stats
从innodb1.0.x版本开始,允许有多个缓冲池实例,每个页根据哈希值分配到不同缓冲池实例中,优点:减少数据库内部的资源竞争,增加数据库的并发处理能力, 可通过innodb_buffer_pool_instances进行设置
2.LRU list 和 Flush list 和Free list
通常来说,数据库中的缓冲池是通过LRU(Latest Recent Used),最少使用算法进行管理的.使用最频繁的页在LRU列表最前端,最少使用的页在LRU列表尾端,当缓冲池不能存放新读取的数据时,先释放LRU列表中尾端的页
在innodb中,缓冲池默认的页大小是16kb,同样使用LRU算法对缓冲池进行管理.但是innodb做了一些改动,增加了midpoint位置,新都区的页不直接放入到LRU列表的首部,而是放入lru列表的midpoint位置,该位置默认在LRU列表的5/8处. midpoint位置可以由innodb_old_blocks_pct控制
show VARIABLES like "innodb_old_blocks_pct";
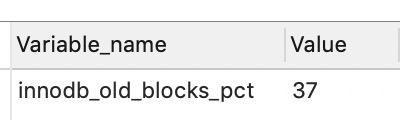
37表示新读取的页插入到LRU列表尾端的37%位置(差不多3/8),midpoint将lru列表拆成两部分,old列表,new列表
这么处理有什么好处?
如果直接将读取到的页放入LRU的首部,那么默写sql操作可能是缓冲池中的页被刷新出,从而影响缓冲池的效率.常见这类操作为索引或者数据的扫描;因为这类操作需要扫描很多页,如果需要的数据页被刷新出去,innodb需要访问磁盘;
为了解决这个问题,innodb引擎引入了innodb_old_blocks_time管理LRU列表,表示页读取到mid位置后需要等待多久才可以被加入到LRU列表的热端
LRU通过列表管理已经读取的数据,在服务器启动时,Lru列表是空的,这时页都放在Free列表,当需要从缓冲池分页时,先判断Free列表是否为空,若有删除Free列表,放入LRU列表,否则根据LRU算法,淘汰尾部
从innodb1.2版本开始,可以通过innodb_buffer_pool_stats观察缓冲池状态
select pool_id,hit_rate,pages_made_young,pages_not_made_young from information_schema.INNODB_buffer_pool_stats
可通过innodb_buffer_page_lru观察每个lru列表的每个页具体信息
select table_name,SPACE,page_number,page_type from information_schema.innodb_buffer_page_lru where space=1;

在LRU列表中的页被修改后,称该页为脏页,即缓冲池与磁盘上的页数据产生不一致.这是数据库会通过checkpoint机制将脏页刷回磁盘,而flush列表中的页即为脏页列表
3.重做日志缓冲
内存区除了缓冲池外,还有重做日志缓冲,innodb首先将重做日志信息先放入到这个缓冲区,然后按着一定的频率将其刷新到重做日志文件,
重做日志缓冲一般不大,默认8mb,因为每秒都会对重做日志刷新到磁盘上,可通过innodb_log_buffer_size控制
有以下三种情况会将重做日志缓冲刷新到磁盘上
1.master thread 每秒执行
2.每个事务提交后
3.当重做日志缓冲小于1/2时
4.额外的内存池
2.4Checkpoint技术
当执行了一条dml语句,就会造成缓冲区与磁盘数据不一致,产生脏页,就要刷入磁盘,这样开销会很大;同时为了避免数据丢失采用write ahead log策略 ,事务提交时先写入重做日志然后在修改页;
一但出现宕机可以通过重做日志回复数据, 但会有以下两个问题
1.重做日志持续增大
2.缓冲区能否承担所有数据
显然以上两个问题需要解决, 这时推出了 checkpoint检查点技术 可以解决以下几个问题
1.缩短数据库的恢复时间
2.缓冲池不够用时,将脏页刷新到磁盘
3.重做日志不可用时,刷新脏页
当数据库发生宕机时,不需要所有重做日志,因为checkpoint之前的页都已经刷新回磁盘了
2.5Master Thread工作方式
2.5.1innodb 的master thread
master thread具有最高的线程优先级别.内部由多个循环loop组成,主循环,后台循环,刷新循环,暂停循环,Master Thread 会根据数据库运行的状态在循环之间切换
2.6innodb关键特性
插入缓冲 insert buffer
两次写 double write
自适应哈希索引 adaptive hash index
异步io async io
刷新邻接页flush neighbo page
这些特性为innodb带来了更好的性能和更高的可靠性
2.6.1插入缓冲 insert buffer
1.insert buffer
innodb中聚簇索引即主键id,插入顺序和主键递增的顺序基本保持一致;但是对于非聚簇索引且索引值不唯一,在进行插入操作时,数据页的存放还是按着主键a进行顺序存储的,但是对于非聚簇索引叶子节点的插入不在是顺序的;
为了解决非聚簇索引这种情况,开创性地设计了insert buffer,对于非聚簇索引的操作,不是每次插入索引页中,而是先判断是否在缓冲池中,若在直接插入;若不在,先放入到insert buffer对象中,然后以一定频率和情况进行insert buffer 和 辅助索引页 子节点的merge操作,这时通常能将多个插入合并到一个操作中,大大提高了非聚簇索引插入性能
但是使用insert buffer要满足以下两个条件
1.索引是辅助索引或者说二级索引sencondary index
2.索引不是惟一的, 目的是 不需要再去判断记录的唯一性
但如果某个时刻突然宕机了 ,insert buffer的数据还未合并到实际的非聚簇索引中去, 恢复起来就麻烦了
2.change buffer
insert buffer升级版,在1.0.x之后加入,innodb引擎可以对dml操作, insert delete update 进行缓冲对应的是insert buffer delete buffer purge buffer
其中对一条记录进行update 需要两步
1.将记录标记为已删除 ->delete
2.真正删除 ->purge
3.insert buffer内部实现
insert buffer的数据结构是一颗B+树,在4.1之后版本,全局只有一个B+树负责所有表二级索引的insert buffer处理;
insert buffer是一颗B+树,由叶子节点和非叶子节点组成,非叶子节点存放的是查询的search key键值

search key共9个字节,space标识插入记录所在表空间id,在innodb中每个表都有一个space id ,space占用4字节
marker占用1字节,用于兼容旧版本insert buffer
offset表示页所在的偏移量 占用4字节
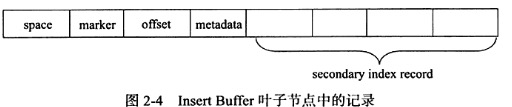
当一个辅助索引要插入到页(space,offset),如果页不在缓冲区,那么innodb会根据上述规则构建一个search key
此时构建的search key还需要构造,才能插入叶子节点 metadata占用4个字节,还需要insert buffer bigmap 协助标记索引页剩余可用空间
4.Merge insert buffer
将insert buffer中的记录合并到镇等的secondery index中 有以下几种情况
1.辅助索引页被读到缓冲池
2.insert buffer bitmap 发现索引页没有剩余空间了
3.master thread每秒/10秒 进行一个merge insert buffer的操作,不同之处在于处理的数据量
2.6.2两次写
两次写doublewrite给innodb带来了数据页的可靠性
如果数据库突然宕机了,16k的数据页,只写了4k, 如果仅通过重做日志恢复的话,是没有意义的;
doublewrite由两部分组成,一个是内存中的doublewrite buffer 大小为2m,另一部分是物理磁盘共享表空间连续的128个页,即2个分区 大小同样为2m;在对缓冲池的脏页进行刷新时,并不直接写磁盘,而是通过memcpy函数将脏页先复制到内存的doublewrite buffer,然后doublewrite buffer 分两次,每次1mb顺序写入到共享表空间磁盘上,然后马上调用fsync喊出,同步磁盘

2.6.3自适应哈希索引
innodb监控表中各索引查询情况,如果发现建立哈希索引能带来大的优化,就建立哈希索引 adaptive hash index
建立AHI一个要求是,对这个页的访问模式必须一样 ,即查询条件一样
2.6.4异步io
为了提高磁盘操作性能,数据采用了异步ioaio处理磁盘
AIO好处1是不用等待耗时操作 2是可以进行io merge,将多个io合并为1个io
2.6.5刷新邻接页
工作原理是:当刷新一个脏页时,innodb会检测该页所在区的所有页,如果是脏页,那么就一起刷新
需要注意:随着ssd速度升高 这个功能主要针对磁盘
2.7启动,关闭与恢复
在关闭时,参数innodb_fast_shutdown影响着表的存储引擎的行为该值可谓0,1,2默认为1
0:关闭数据库时,innodb需要完成所有与full purge 和 merge insert buffer 所有脏页写回磁盘
1:默认设置,不需要完成full purge 和 merge insert buffer ,但是缓冲区的脏页还是会刷新到磁盘
2.不进行任何操作,只是将日志写到日志文件中,然后下次启动进行服务操作
参考:MySQL技术内幕-innodb