下载的voc数据集 images ,annotations.
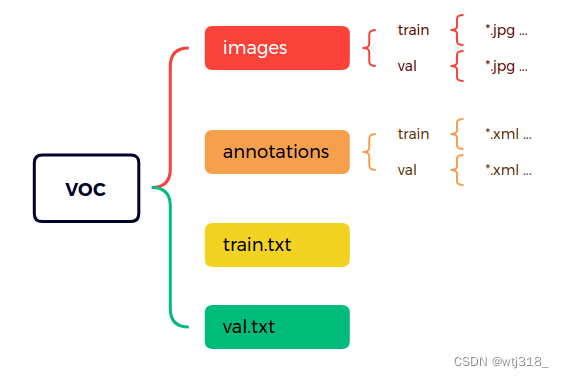
经下代码 按比例划分成,只需要修改中文批注部分路
import os
import sys
import random
import shutil
if __name__ == '__main__':
train_percent = 0.8 # 训练集比例
val_percent = 0.2 # 验证集比例
Root = '../datasets/voc-end/' # 数据集文件夹路径
imgs_path = Root + 'images/' # 图片路径
xml_path = Root + '/annotations/' # 标注路径
data_c = ['jpg', 'xml'] # 数据种类 如.jpeg需修改成jpeg
imgs_list = []
xml_list = []
imgs_list = os.listdir(imgs_path)
xml_list = os.listdir(xml_path)
if len(imgs_list) != len(xml_list):
sys.exit("图片数据集和标注不一致,请重新确认数据集!!!!")
num = len(imgs_list)
print(num)
ftrain = open(Root+'train.txt', 'w') # 训练集图片名称列表
fval = open(Root+'val.txt', 'w') # 验证集图片名称列表
img_train_dir = imgs_path + "train/"
img_val_dir = imgs_path + "val/"
xml_train_dir = xml_path + "train/"
xml_val_dir = xml_path + "val/"
if not os.path.exists(img_train_dir):
os.makedirs(img_train_dir)
if not os.path.exists(img_val_dir):
os.makedirs(img_val_dir)
if not os.path.exists(xml_train_dir):
os.makedirs(xml_train_dir)
if not os.path.exists(xml_val_dir):
os.makedirs(xml_val_dir)
train_num = int(num*train_percent)
train_sample = random.sample(imgs_list, train_num)
# print(train_sample)
# ------------------------------
# train img&xml move
# ------------------------------
for name in train_sample:
shutil.move(imgs_path+name, img_train_dir+name)
print(name)
a, b = name.split('.')
t_text = a + '\n'
ftrain.write(t_text)
shutil.move(xml_path+a+'.xml', xml_train_dir+a+'.xml')
v_list = []
for i in os.listdir(imgs_path):
c = i[-3::]
if c in data_c:
v_list.append(i)
# ------------------------------
# val img&xml move
# ------------------------------
for v_name in v_list:
shutil.move(imgs_path+v_name, img_val_dir+v_name)
print(v_name)
a, b = v_name.split('.')
v_text = a + '\n'
fval.write(v_text)
shutil.move(xml_path+a+'.xml', xml_val_dir+a+'.xml')
# ------------------------------
# train & val list text
# ------------------------------
ftrain.close()
fval.close()