(本文只是对transformer一些前置知识和整体结构的部分讲解,详细transformer架构讲解内容请看笔者这篇文章,绝对全面 ) 史上最详细Transformer讲解附有完整代码
1.3 Transformer一些前置知识
1.3.1 自注意力机制 Self-Attention (very important)
要想把Transformer学明白,必须要先把自注意力机制给搞明白喽(比较重要,所以花费了大量笔墨讲解)
自注意力机制是什么呢?
从感官的角度理解注意力机制 分为 非自主性 和 自主性提示 两周 :
非自主性提示:
想象一下,假如我们面前有五个物品: 一份报纸、一篇研究论文、一杯咖啡、一本笔记本和一本书, 就像 图10.1.1。 所有纸制品都是黑白印刷的,但咖啡杯是红色的。 换句话说,这个咖啡杯在这种视觉环境中是突出和显眼的, 不由自主地引起人们的注意。 所以我们会把视力最敏锐的地方放到咖啡上, 如 图10.1.1所示。这是一种非自主性提示,非自主性提示是基于环境中物体的突出性和易见性。

图10.1.1 由于突出性的非自主性提示(红杯子),注意力不自主地指向了咖啡杯
自主性提示:
喝完咖啡后,我们会变得兴奋并想读书, 所以转过头,重新聚焦眼睛,然后看看书, 就像 图10.1.2中描述那样。 与 图10.1.1中由于突出性导致的选择不同, 此时选择书是受到了认知和意识的控制, 因此注意力在基于自主性提示去辅助选择时将更为谨慎。 受试者的主观意愿推动,选择的力量也就更强大。

图10.1.2 依赖于任务的意志提示(想读一本书),注意力被自主引导到书上
键值 Key Value
自主性的(Query)与非自主性(Key)的注意力提示解释了人类的注意力的方式(Value), 下面来看看如何通过这两种注意力提示, 用神经网络来设计注意力机制的框架,
首先,考虑一个相对简单的状况, 即只使用非自主性提示。 要想将选择偏向于感官输入, 则可以简单地使用参数化的全连接层, 甚至是非参数化的最大汇聚层或平均汇聚层。
因此,“是否包含自主性提示”将注意力机制与全连接层或汇聚层区别开来。 在注意力机制的背景下,自主性提示被称为查询(query)。 给定任何查询,注意力机制通过注意力汇聚(attention pooling) 将选择引导至感官输入(sensory inputs,例如中间特征表示)。 在注意力机制中,这些感官输入被称为值(value)。 更通俗的解释,每个值都与一个键(key)配对, 这可以想象为感官输入的非自主提示。 如 图10.1.3所示,可以通过设计注意力汇聚的方式, 便于给定的查询(自主性提示)与键(非自主性提示)进行匹配, 这将引导得出最jia匹配的值(感官输入)。

图10.1.3 注意力机制通过注意力汇聚将查询(自主性提示)和键(非自主性提示)结合在一起,实现对值的选择倾向
Tips: 用通俗的语言解释一下 上述名词
-
键Key: 一系列物品(桌子上有各种各样的物品,水果,剪刀,手机,笔) @非自主性提示
-
值Value: 这一系列物品对人下意识的吸引力(比如在上述物品中,由于手机对我们吸引较大,因此它的下意识地吸引力值较大)
-
查询Query: 你想要的物品(我现在要写东西,那么我需要笔) @自主性提示
-
注意力汇聚: 一个网络层,该层的输出结果是一个所有元素的和等于1的权重向量,该层的作用是把想要的物品(比如是写字用的笔)所对应的权重值变高以选中目标物品。这样使用该 权重向量与 值 相乘之’后,即使目的物品“下意识的吸引力(即‘值’)”不够高,但是由于它对应的权重高,其他物品对应的权重小,最终选择到目标物品的可能性也会变大。
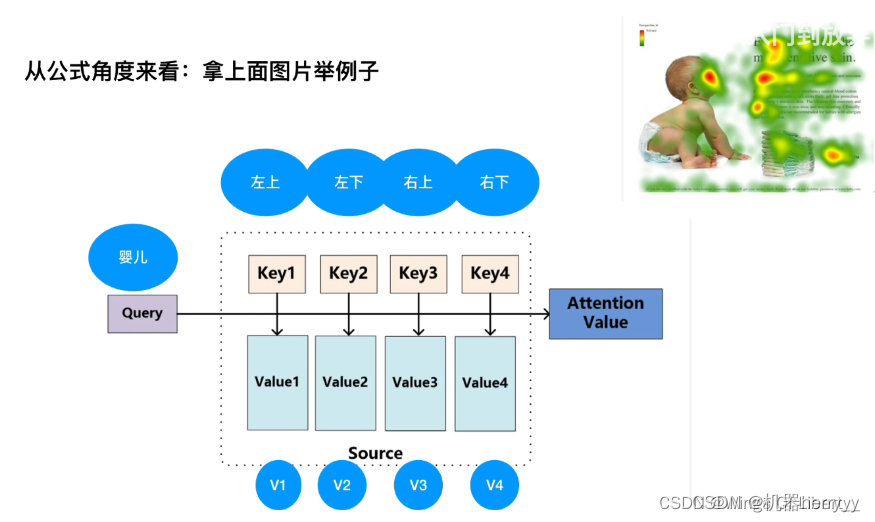
用婴儿做Query(Q),图像的四个部分做为Key(K)。首先用Query分别点乘4个Key(点乘是计算两个向量相似度的一种方式,相似度越高,点乘得到的结果越大。判断两个向量相似度的方式有点乘、构建一个新的MLP、计算cos相似度等)得到一个四维向量。
比如是[7,1,1,1] ,然后经过一次softmax层得到[0.7,0.1,0.1,0.1],作为注意力权重(注意力权重指的是各个key(即各个物品)与query(即目的物品)的相似程度,即人的目的性关注度)。注意力权重里的这4个数字,越大的数字,说明Query对相应的Key的下意识的关注度越高。
然后再用注意力权重[0.7,0.1,0.1,0.1]和4个V(Valuei)相乘(即[v10.7,v20.1,v30.1,v40.1]),再相加(即加权和),得到最终的Attention value= v10.7+v20.1+v30.1+v40.1(一个数值为最终结果)。
但是要注意,上述例子是为了易于讲解,实际在transformer结构里,Query、Key、Value不可能仅用一个数字代表,通常是使用多维向量表示。
1.3.2 位置编码 Positional Encoding
对于传统的RNN模型来说,采用的是同一套参数,这样就隐含了输入的先后顺序信息。Transformer缺少了单词输入的顺序信息,所以需要位置编码来标记各个字之间的时序关系或者位置关系。要不然由于transformer的encoder部分是双向的,整个词的向量是全部一起输入的,与RNN和LSTM不同,因此需要一个嵌入一个特殊的向量Positional Encoding以区分一个单词中前后单词出现的顺序。Transformer给出的编码公式 如图一所示:

图一:Transformer位置编码公式
最重要的是,positional embedding 是给位置进行编码,不是给单词编码,也就是说不同单词在相同位置的编码可能是相同的
通俗的来讲就是给一句话加上一个顺序标签,知道哪些字or单词是在前面所出现的,哪些是在后面所出现的。也是为了区分一句话中出现的相同字母,不然所有相同字母在任何位置的词向量编码都一样了。(位置编码的详细讲解也可参考链接Transformer 中的 Positional Encoding)
1.3.3 Transformer模型的主要架构部分
(用计算机网络的话说)seq2seq(即序列to序列,多用于机器翻译,语音处理等)是端到端的一种应用层概念,具体的网络层架构实现可以用到Encoder-Decoder,传统的 Encoder-Decoder会使用RNN、LSTM、GRU来进行构建,而Transformer则是放弃了使用常见的RNN结构,使用了一种全新的方式Self-Attention。
首先,让我们先将 Transformer 模型视为一个黑盒,如图 1.2 所示。在机器翻译任务中,将一种语言的一个句子作为输入,然后将其翻译成另一种语言的一个句子作为输出,这种操作与就是Seq2Seq模型。

图 1.2 Transformer 模型(黑盒模式)
Transformer 黑盒子的本质其实是一个 Encoder-Decoder 架构。因此中间部分的 Transformer 可以分为两个部分:编码组件和解码组件。如图 1.3 所示:

图 1.3 Transformer 模型(Encoder-Decoder 架构模式)
其中,编码组件由 多层编码器(Encoder)组成(在Attention is all you need 论文中作者使用了 6 层编码器,在实际使用过程中也可以尝试其他层数)。解码组件也是由相同层数的解码器(Decoder)组成(在论文也使用了 6 层)。如图 1.4 所示,,但是在实际选择中,层数可以根据自己的需要和设备算力的大小而改变,比如在后文,本人实现的中文版完形填空用了三层的Encoder(参数大约为25M左右)
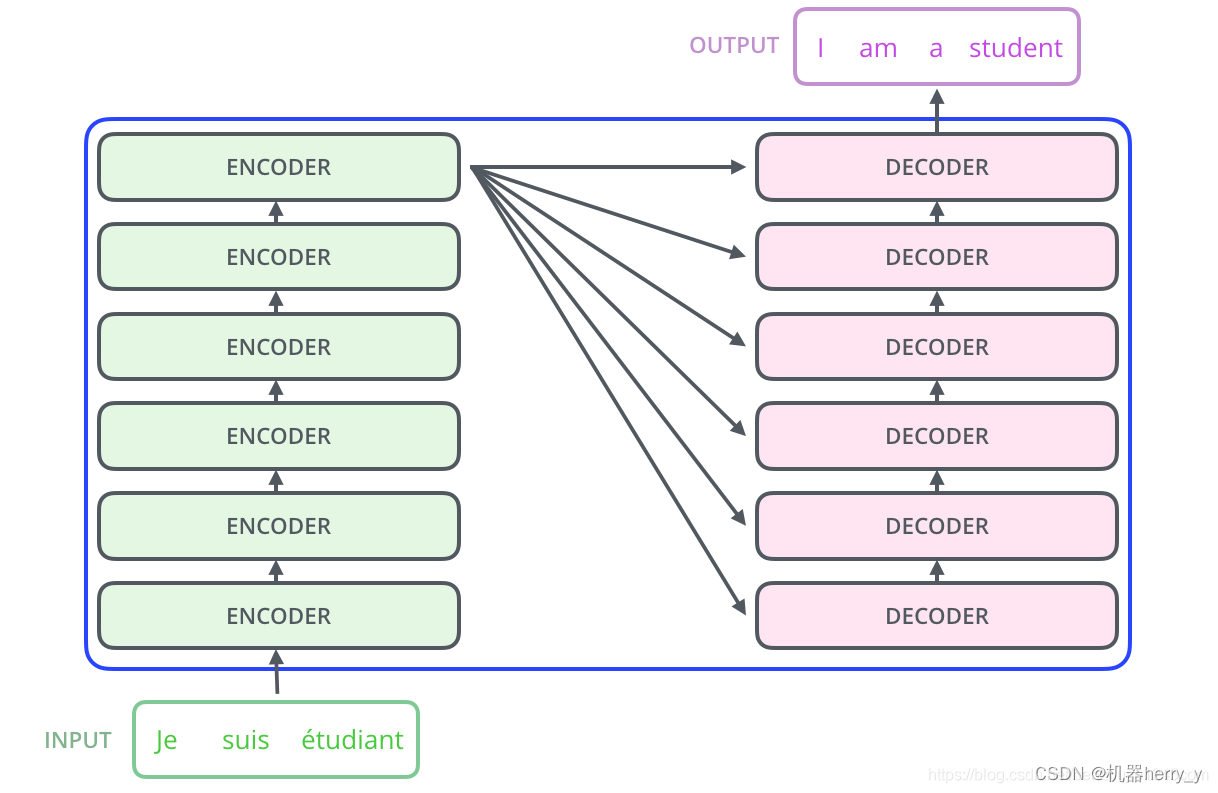
图 1.4
每个编码器由两个子层组成:Self-Attention 层(自注意力层)和 Position-wise Feed Forward Network(前馈网络,缩写为 FFN)如图 1.5 所示。每个编码器的结构都是相同的,但是它们使用不同的权重参数。

图 1.5
编码器的输入会先流入 Self-Attention 层。它可以让编码器在对特定词进行编码时使用输入句子中的其他词的信息(可以理解为:当我们翻译一个词时,不仅只关注当前的词,而且还会关注其他词的信息)。后面我们将会详细介绍 Self-Attention 的内部结构。然后,Self-Attention 层的输出会流向前馈网络。