过拟合:所表现的就是模型训练误差很小,但测试误差很大,对于产生这种现象以下说法正确?
提示:
基础知识:
【1】深度学习机器学习笔试面试知识——正则化
题目
在机器学习中,如果一味的去提高训练数据的预测能力,所选模型的复杂度往往会很高,这种现象称为过拟合。所表现的就是模型训练时候的误差很小,但在测试的时候误差很大,对于产生这种现象以下说法正确的是:()
样本数量太少
样本数量过多
模型太复杂
模型太简单

二、解题
样本数量太少,或者模型过分复杂,
都会使得训练出来的模型“完全记住”给出的训练样本之间的关系
(相当于只是背下来了试卷,但是等到高考的时候遇到新的题还是不会做)
而缺乏泛化能力 使得模型过拟合
关于过拟合,如何降低过拟合的方法:看下文
【1】深度学习机器学习笔试面试知识——正则化
过拟合与欠拟合
讲正则化前,需要先讲过拟合与欠拟合。
神经网络在完成学习后,对应就是一个函数,网络学习的过程,就是这个函数拟合数据分布的过程:
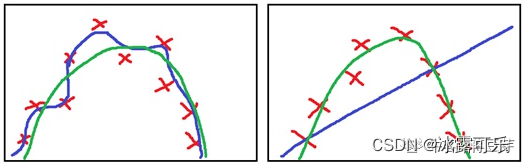
如图中,红色×就是实际数据的分布,
绿色就是拟合刚刚好的函数。——我们期待神经网络能学出这么一个模型来。
而左边的蓝色就是过拟合,拟合得太好了,针对以后的新数据可能泛化性能就差;
而右边的蓝色就是欠拟合,还差得远,没有很好的拟合现有的数据分布。
如何判断过拟合?过拟合与欠拟合的评判标准
过拟合与欠拟合的评判标准【很容易】
(1)过拟合:训练集效果很好,测试集效果较差(训练OK,测试不行)
(2)欠拟合:训练集效果差,测试集效果也差。(训练测试都很差,等于没干)
什么是正则化?为什么要正则化?
目标是减少特征的数量,减少过拟合。贪多爵不烂!!!
目标是减少特征的数量,减少过拟合。贪多爵不烂!!!
目标是减少特征的数量,减少过拟合。贪多爵不烂!!!
总结
提示:重要经验:
1)样本数量太少,或者模型过分复杂,都会导致过拟合
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。