1.requests库的介绍
requests 是 Python 语言编写,基于 urllib3 ,采用 Apache2 Licensed 开源协议的HTTP库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。是 Python 实现的简单易用的 HTTP 库。
Requests 中文文档:http://docs.pythonrequests.org/zh_CN/latest/index.html
解决package下载速度慢的问题,用国内的镜像网站:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple package
2.requests库的基本用法
2.1request访问请求
https://python123.io/ws/demo.html是一个给初级爬虫学习者练习的网站,网址的内容如下:
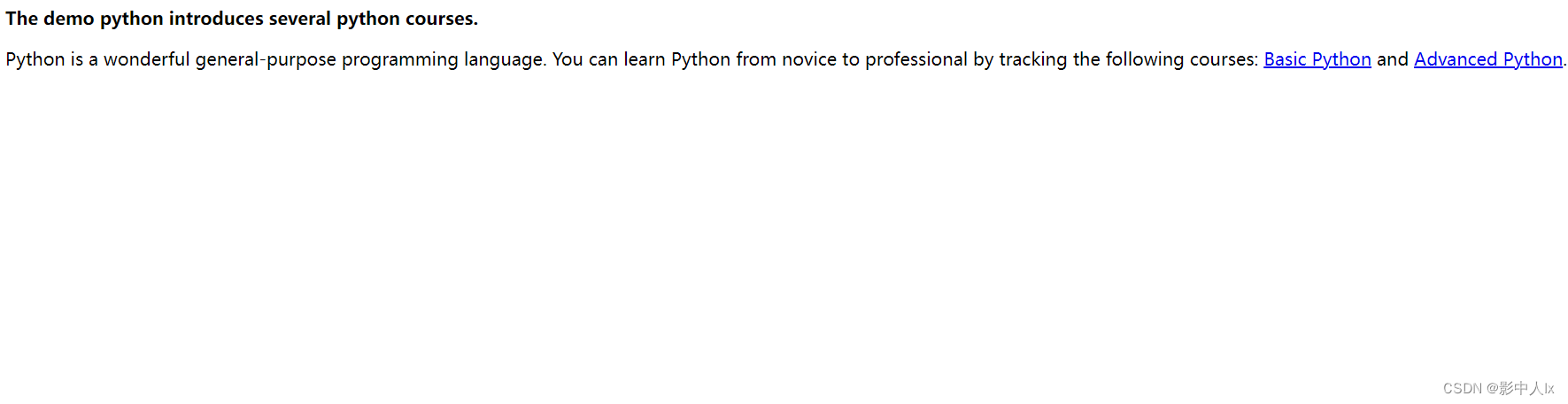
import requests
url='https://www.baidu.com'
url1='https://python123.io/ws/demo.html'
response=requests.get(url1) #返回了一个响应对象,包含了网页获取的所有信息
print(type(response.content),type(response.text)) # bytes, str
print(response.content.decode('utf-8')) # 解码为字符串

如何知道返回是否成功?-----状态码
response.status_code # 可以获取这次请求的状态码,200代表着访问成功,否则访问失败
response.raise_for_status()
'''
.raise_for_status()
如果状态码不是200,返回一个false,访问成功,就什么都不返回。
'''
输出结果:
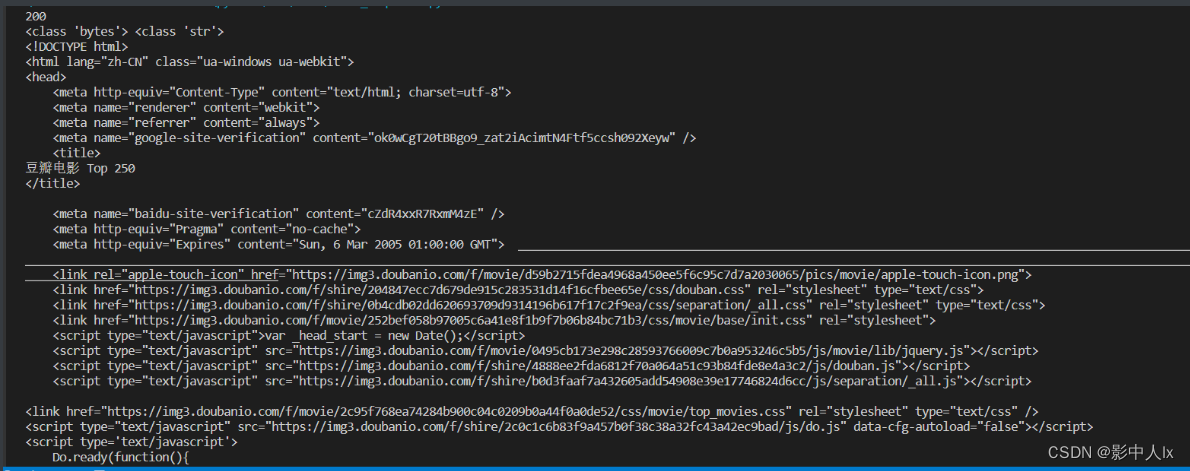
200
None 代表这次访问结果
2.1.2对豆瓣等网址发送请求的问题
url='https://movie.douban.com/top250'
r=requests.get(url)
print(r.status_code)
418 #当前的状态码是418
有些网址的robots.txt文件存在限制指令(限制搜索引擎的抓取),在进行网页抓取的时候请求会被拦截。
2.2robots协议
robots协议也叫robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。
作用:网站告知网络爬虫哪些页面可以爬取,哪些不能爬取
形式:在网站根目录下的robots.txt文件
# 注释
* 代表所有
./代表根目录
User-agent: * # 代表的是那些爬虫
Disallow: / # 代表不允许爬虫访问的目录
淘宝网站的robots协议
比如我们查看淘宝网站的robots协议:https://www.taobao.com/robots.txt

Baiduspider和baiduspider【百度爬虫】,禁止百度爬虫访问’/'后面所有的内容。
豆瓣的robots协议
https://www.douban.com/robots.txt
User-agent: *
Disallow: /subject_search
Disallow: /amazon_search
Disallow: /search
Disallow: /group/search
Disallow: /event/search
Disallow: /celebrities/search
Disallow: /location/drama/search
Disallow: /forum/
Disallow: /new_subject
Disallow: /service/iframe
Disallow: /j/
Disallow: /link2/
Disallow: /recommend/
Disallow: /doubanapp/card
Disallow: /update/topic/
Disallow: /share/
Allow: /ads.txt
Sitemap: https://www.douban.com/sitemap_index.xml
Sitemap: https://www.douban.com/sitemap_updated_index.xml
# Crawl-delay: 5
User-agent: Wandoujia Spider
Disallow: /
User-agent: Mediapartners-Google
Disallow: /subject_search
Disallow: /amazon_search
Disallow: /search
Disallow: /group/search
Disallow: /event/search
Disallow: /celebrities/search
Disallow: /location/drama/search
Disallow: /j/
2.3查看和修改爬虫的头部信息
头部信息相当于手里拿的身份证信息。
url='https://movie.douban.com/top250'
r=requests.get(url)
r.request.headers
'''
{'User-Agent': 'python-requests/2.26.0', 'Accept-Encoding': 'gzip, deflate, br', 'Accept': '*/*', 'Connection': 'keep-alive'}
'''
修改头部信息----模仿用户行为
将头部信息的User-Agent修改为浏览器的User-Agent
通过网页信息查看浏览器的的访问信息。
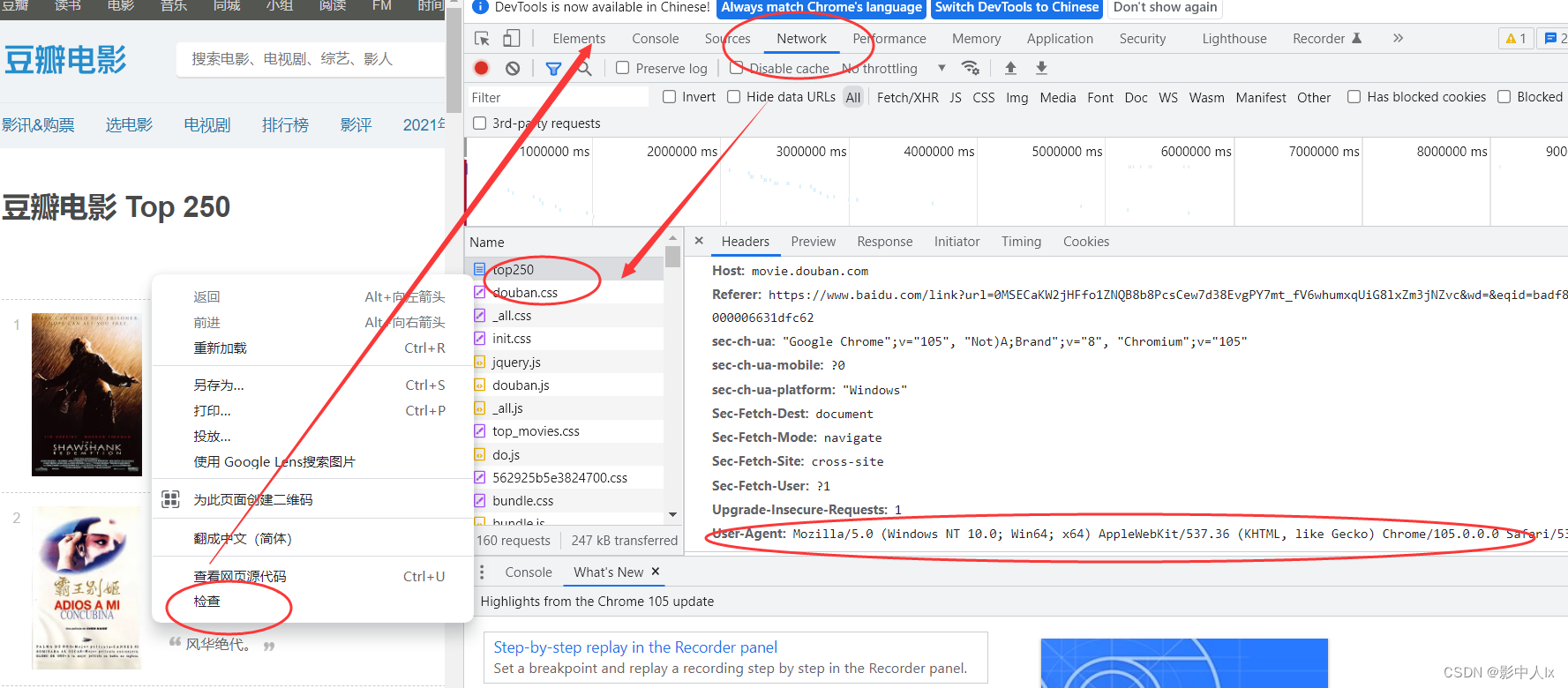
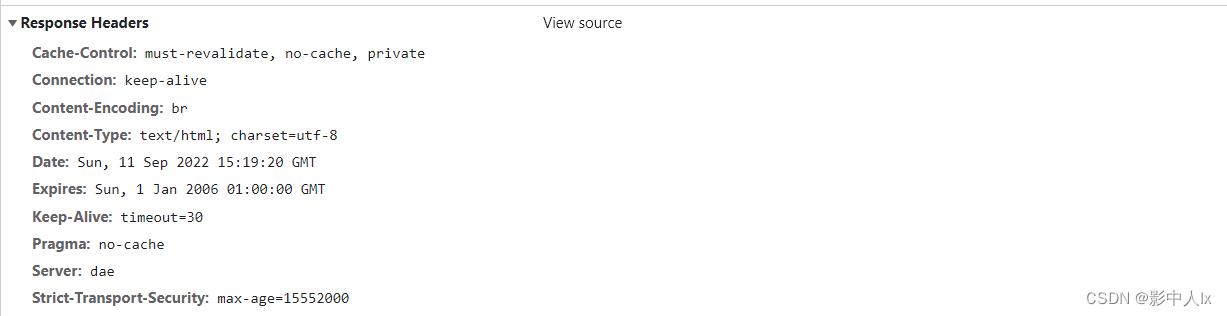
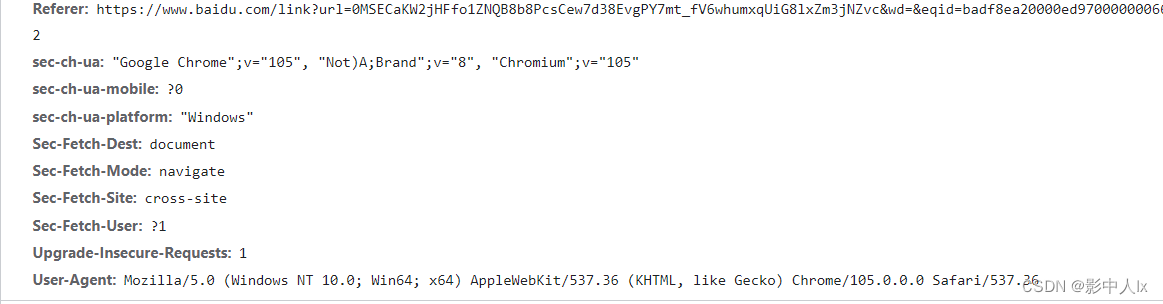
分为Request Headers和Response Headers
Response Headers
Request Headers
url='https://movie.douban.com/top250'
r=requests.get(url)
print(r.status_code)
value='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
pyuser_agent={
'User-Agent':value
}
r1=requests.get(url=url,headers=pyuser_agent)
print(r1.status_code)
输出:
418
200
2.2 response响应对象
# 目标url
url = "https://movie.douban.com/top250"
# 向目标url发送get请求
value='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
pyuser_agent={
'User-Agent':value
}
response = requests.get(url,headers=pyuser_agent) #获取网页内容
print(response.status_code)
print(type(response.content),type(response.text))
print(response.text) #打印响应内容,按照str类型解析,用于获取文字或源码
print(response.content) #打印响应内容,按照bytes类型解析,用于获取图片或音视频
print(response.content.decode('utf-8')) # 解码为字符串
2.3requests的请求类型
1.GET
get方法请求指定的页面信息,返回实体主体。该请求是向服务器请求信息,请求参数会跟在url后面,因此,对传参长度有限制的,而且不同浏览器的上限是不同的(2k, 7~8k及其他)。由于get请求直接将参数暴露在url中,因此对于一些带有重要信息的请求可能并不完全合适。
2.POST
post请求是向指定资源提交数据进行处理请求,例如提交表单或者上传文件等。数据被包含在请求体中,POST请求可能会导致新的资源的建立和/或已有资源的修改。post方法没有对传递资源的大小进行限制,往往是取决于服务器端的接受能力,而且,该方法传参安全性稍高些
3.PUT
PUT方法是从客户端向服务器传送的数据取代指定的文档的内容。PUT方法的本质是idempotent的方法,通过服务是否是idempotent来判断用PUT 还是 POST更合理,通常情况下这两种方法并没有刻意区分,根据语义使用即可
4.DELETE
请求服务器删除指定的页面,DELETE请求一般会返回3种状态码:
- 200 (OK) - 删除成功,同时返回已经删除的资源
- 202 (Accepted) - 删除请求已经接受,但没有被立即执行(资源也许已经被转移到了待删除区域)
- 204 (No Content) - 删除请求已经被执行,但是没有返回资源(也许是请求删除不存在的资源造成的)
import requests
r = requests.get('https://httpbin.org/get') #get请求
# r = requests.post('https://httpbin.org/post') #post请求
# r = requests.put('https://httpbin.org/put') #put请求
# r = requests.delete('https://httpbin.org/delete') #delete请求
# r = requests.patch('https://httpbin.org/patch') #patch请求
print(r.text)
POST和GET的区别
- POST:向服务器传送数据
- GET向服务器获取数据
2.3.1请求携带参数
1.一般的GET请求
r = requests.get('https://httpbin.org/get')
print(r.text)
2.带参数的请求
GET请求
r = requests.get('https://httpbin.org/get?name=luoluo&age=3')
print(r.text)
data = {"name":"luoluo","age":3}
r = requests.get('https://httpbin.org/get',params=data)
print(r.text)
data = {"name":"luoluo","food":["meat","bone"]}
r = requests.get('https://httpbin.org/get',params=data)
print(r.text)
# 链接为:https://httpbin.org/get?name=luoluo&food=meat&food=bone
# 【注意】字典里值为 None 的键都不会被添加到 URL 的查询字符串里。
data = {"name":"luoluo","address":None}
r = requests.get('https://httpbin.org/get',params=data)
print(r.text)
# 链接为:https://httpbin.org/get?name=luoluo
import requests
response = requests.get("https://httpbin.org/get")
# 在请求头中带上User-Agent,模拟浏览器发送请求
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# response = requests.get("https://httpbin.org/get", headers=headers)
# 打印请求头信息
print(response.request.headers)
POST请求
提交表单,使用data属性携带字典对象
data ={'name':'luoluo','age ':'3'}
r = requests.post("http://httpbin.org/post",data=data)
print(r.text)

3.requests库的高级用法
3.1文件上传
发送post请求
upload = {'avatar': open('img.jpeg', 'rb')}
r = requests.post('https://httpbin.org/post', files=upload)
print(r.text)
3.2Cookie和Session
什么是会话?
用户打开一个浏览器, 点击多个超链接, 访问服务器多个web资源, 然后关闭浏览器, 整个过程称之为一个会话。
HTTP协议是一种"无状态"协议,客户浏览器与服务器建立连接,发出请求,得到相应,然后关闭连接,这意味着每次客户端检索网页时,客户端打开一个单独的连接到 Web 服务器,服务器会自动不保留之前客户端请求的任何记录。
所以容器不能辨认下一个请求和之前的请求是不是同一个请求,对于容器而言,每个请求都是新的。
3.2.1 保存会话数据的两种技术:
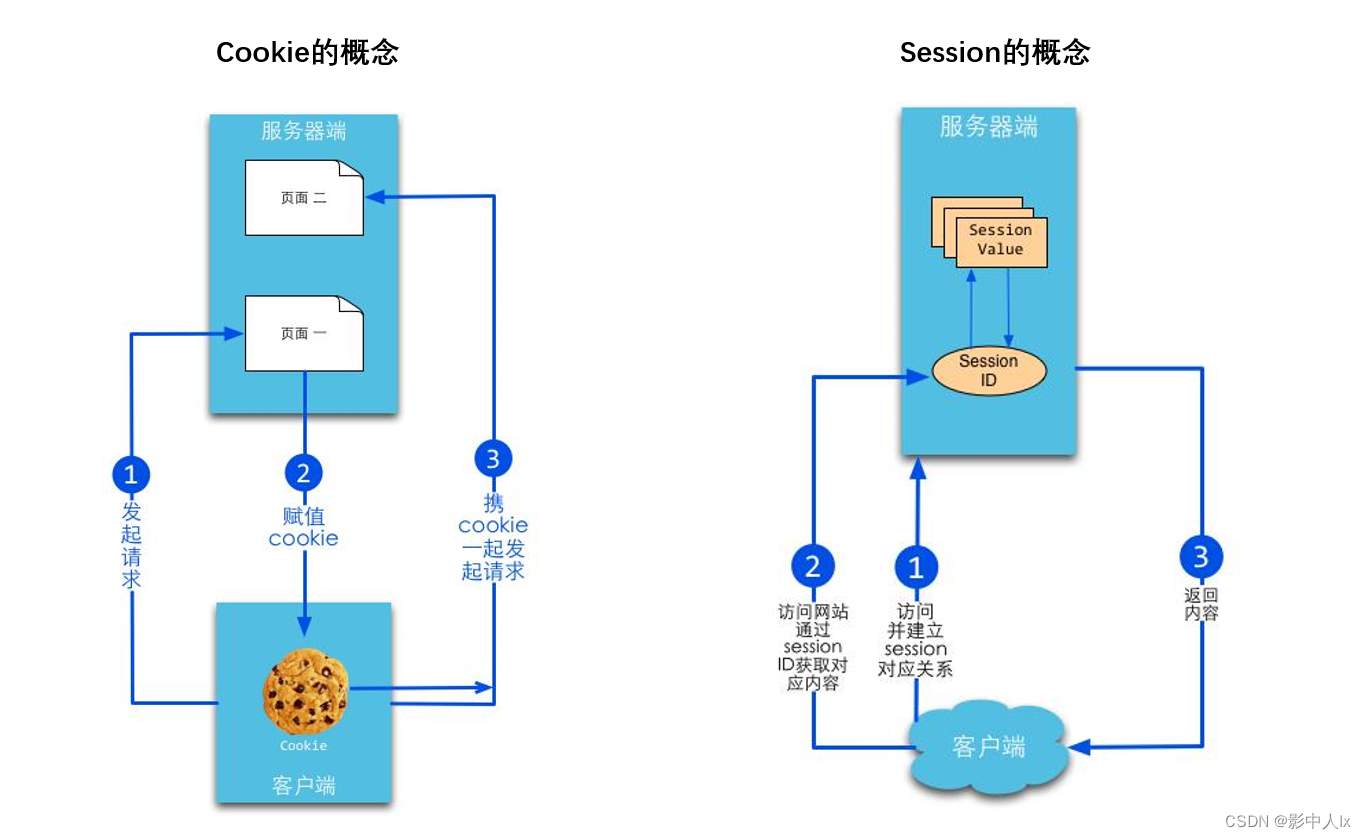
Cookie是客户端技术,程序把每个用户的数据以cookie的形式写给用户各自的**浏览器。**当用户使用浏览器再去访问服务器中的web资源时,就会带着各自的数据去。这样,web资源处理的就是用户各自的数据了。
Session是服务器端技术,利用这个技术,服务器在运行时可以为每一个用户的浏览器创建一个其独享的session对象,由于session为用户浏览器独享,所以用户在访问服务器的web资源时,可以把各自的数据【Cookie数据】放在各自的session中,当用户再去访问服务器中的其它web资源时,其它web资源再从用户各自的session中取出数据为用户服务。
Cookie和Sesson的区别
- Cookie:给用户发号牌,下次来的时候带着
- Session:根据用户特征登记,下次来的时候识别
3.3获取Cookie
#获取方法一
url='https://movie.douban.com/top250'
value='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
user_agent={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
r = requests.get(url=url,headers=user_agent)
print(r.cookies)
for key, value in r.cookies.items():
print(key + '=' + value)
#获取方法二
# cookieJar对象转换为cookies字典的方法
cookies_dict = requests.utils.dict_from_cookiejar(r.cookies)
print(type(cookies_dict),cookies_dict)
<RequestsCookieJar[<Cookie bid=Ty9y_Daz_rw for .douban.com/>]>
bid=Ty9y_Daz_rw
<class 'dict'> {'bid': 'Ty9y_Daz_rw'}

3.4设置Cookie
r=requests.get('http://httpbin.org/cookies/set/number/123456789')
print(r.text)
# 获取登陆后的cookie,在下次请求时返回给服务器
cookies="H_PS_PSSID=35105_31254_34584_35490_35246_35318_26350_22157;domain=.baidu.com"
jar = requests.cookies.RequestsCookieJar()
for cookie in cookies.split(";"):
key,value = cookie.split("=",1)
jar.set(key,value)
r = requests.get('http://httpbin.org/cookies',cookies=jar)
print(r.text)
输出:
{
"cookies": {
"number": "123456789"
}
}
#两次算作不同的会话
{
"cookies": {
"H_PS_PSSID": "35105_31254_34584_35490_35246_35318_26350_22157",
"domain": ".baidu.com"
}
}
3.5Session维持
下面的代码,对于服务器来说,相当于打开了两个不同的会话,所以无法获取设置的cookie
import requests
requests.get('https://httpbin.org/cookies/set/number/123456789')
r = requests.get('https://httpbin.org/cookies')
print(r.text)
输出:
{
"cookies": {}
}
可以看到第一次的请求并没有成功设置Cookie
开启会话后,在浏览器关闭前,发出多次请求或打开多个标签页,都属于同一个
s = requests.Session()
s.get('https://httpbin.org/cookies/set/number/123456789')
r = s.get('https://httpbin.org/cookies')
print(r.text)
输出:
{
"cookies": {
"number": "123456789"
}
}

4.代理设置
对于某些网站,在测试的时候请求几次,能正常获取内容。但是一旦开始大规模爬取,对于大规模且频繁的请求,网站可能会弹出验码,或者跳转到登录认证页面,更甚者可能会直接封禁客户端的IP,导致一定时间段内无法访问。 【比如贴吧,微博等】
什么是代理设置
proxy代理参数通过指定代理ip,让代理ip对应的正向代理服务器转发我们发送的请求。
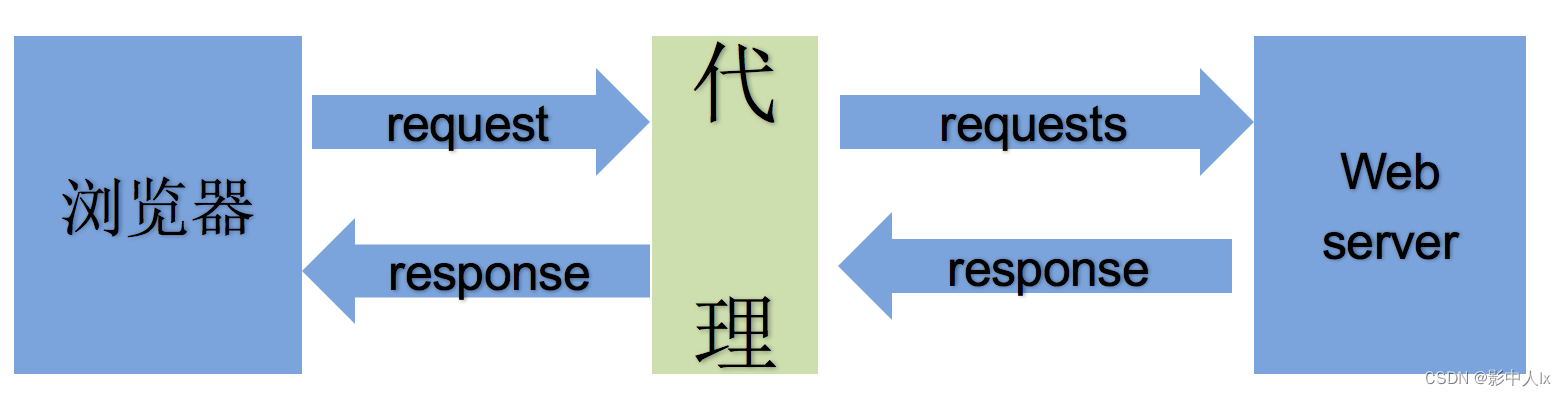
- 代理ip是一个ip,指向的是一个代理服务器
- 代理服务器能够帮我们向目标服务器转发请求
4.1代理服务器的分类
根据代理ip的匿名程度,代理IP可以分为下面三类:
**透明代理(Transparent Proxy):**透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以查到你是谁。目标服务器接收到的请求头如下:
REMOTE_ADDR = Proxy IP
HTTP_VIA = Proxy IP
HTTP_X_FORWARDED_FOR = Your IP
**匿名代理(Anonymous Proxy):**使用匿名代理,别人只能知道你用了代理,无法知道你是谁。目标服务器接收到的请求头如下:
REMOTE_ADDR = proxy IP
HTTP_VIA = proxy IP
HTTP_X_FORWARDED_FOR = proxy IP
**高匿代理(Elite proxy或High Anonymity Proxy):**高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。毫无疑问使用高匿代理效果最好。目标服务器接收到的请求头如下:
REMOTE_ADDR = Proxy IP
HTTP_VIA = not determined
HTTP_X_FORWARDED_FOR = not determined
4.2代理的请求协议
根据网站所使用的协议不同,需要使用相应协议的代理服务。从代理服务请求使用的协议可以分为:
- http代理:目标url为http协议
- https代理:目标url为https协议
- socks隧道代理(例如socks5代理)等:
- socks 代理只是简单地传递数据包,不关心是何种应用协议(FTP、HTTP和HTTPS等)。
- socks 代理比http、https代理耗时少。
- socks 代理可以转发http和https的请求
4.3代理参数的设置
为了让服务器以为不是同一个客户端在请求;为了防止频繁向一个域名发送请求被封ip,所以我们需要使用代理ip 。
response = requests.get(url, proxies=proxies)
# proxies的形式:字典,例如:
proxies = {
"http": "http://36.62.194.186:4289",
"https": "https://36.62.194.186:4289",
}
requests.get("http://www.taobao.com",proxies = proxies)
运行这个实例可能不行,因为这个代理可能是无效的,请换成自己的有效代理试一下。
5.超时设置
在爬虫中,一个请求很久没有结果,就会让整个项目的效率变得非常低,这时就需要对请求进行强制要求,让它必须在特定的时间内返回结果,否则就报错。
- 超时参数timeout的使用方法:
- response = requests.get(url, timeout=1)
- timeout=1表示:发送请求后,1秒钟内返回响应,否则就抛出异常
import requests
url = 'https://ssr4.scrape.center/' # 这个页面默认延迟5秒加载
response = requests.get(url, timeout=1) # 设置超时时间
#运行结果
requests.exceptions.ReadTimeout:HTTPSConnectionPool(host='ssr4.scrape.center',port=443): Read timed out. (read timeout=1)
实际上,请求分为两个阶段,即连接(connect)和读取(read),上面设置的 timeout 将用作连接和读取这两者的 timeout 总和
你也可以分别指定,传入一个元组,设置(连接次数,超时时间)
r = requests.get("https://ssr4.scrape.center/",timeout = (5,30))
如果想永久等待,可以直接将 timeout 设置为 None ,或者不设置直接留 ,因为默认是 None
r = requests.get("https://ssr4.scrape.center/",timeout = none)
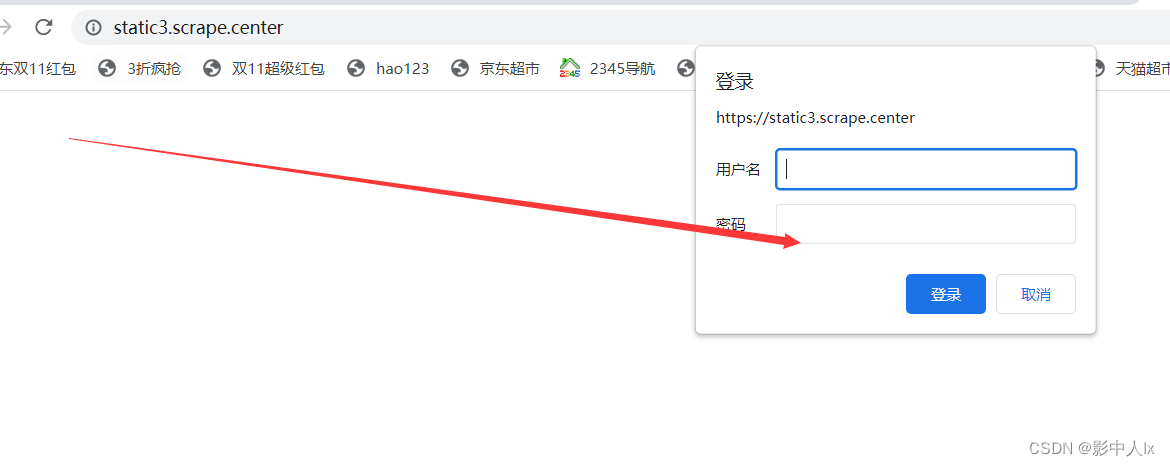
6.登录验证
登录网站:https://static3.scrape.center/ 需要进行身份验证
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('https://static3.scrape.center/', auth=HTTPBasicAuth('admin','admin'))
print(r.status_code)
# 认证失败,返回401;认真成功返回200
# 简化写法,使用元组包裹(用户名,密码)
r = requests.get('https://static3.scrape.center/', auth=('admin', 'admin'))
print(r.status_code)
输出:
200
200
