导论
研究时间序列主要目的:进行预测,根据已有的时间序列数据预测未来的变化。
时间序列预测关键:确定已有的时间序列的变化模式,并假定这种模式会延续到未来。
时间序列预测法的基本特点
- 假设事物发展趋势会延伸到未来
- 预测所依据的数据具有不规则性
- 不考虑事物发展之间的因果关系
|
时间序列数据用于描述现象随时间发展变化的特征。
时间序列分析就其发展历史阶段和所使用的统计分析方法看:传统的时间序列分析和现代时间序列分析。
一、时间序列及其分解
时间序列(time series)是同一现象在不同时间上的相继观察值排列而成的序列。根据观察时间的不同,时间序列中的时间可以是可以是年份、季度、月份或其他任何时间形式。
时间序列:
(1)平稳序列(stationary series)
是基本上不存在趋势的序列,序列中的各观察值基本上在某个固定的水平上波动,在不同时间段波动程度不同,但不存在某种规律,随机波动
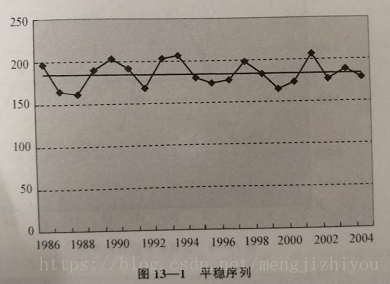
(2)非平稳序列(non-stationary series)
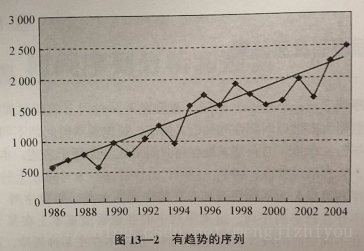
是包含趋势、季节性或周期性的序列,只含有其中一种成分,也可能是几种成分的组合。可分为:有趋势序列、有趋势和季节性序列、几种成分混合而成的复合型序列。
趋势(trend):时间序列在长时期内呈现出来的某种持续上升或持续下降的变动,也称长期趋势。时间序列中的趋势可以是线性和非线性。
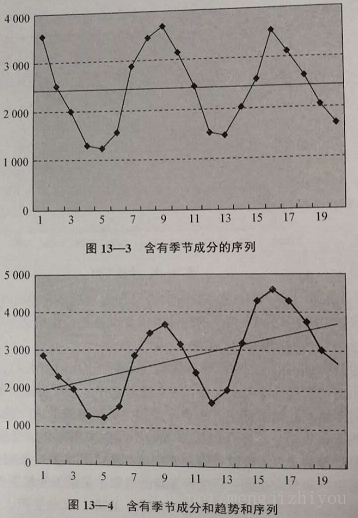
季节性(seasonality):季节变动(seasonal fluctuation),是时间序列在一年内重复出现的周期波动。销售旺季,销售淡季,旅游旺季、旅游淡季,因季节不同而发生变化。季节,不仅指一年中的四季,其实是指任何一种周期性的变化。含有季节成分的序列可能含有趋势,也可能不含有趋势。
周期性(cyclicity):循环波动(cyclical fluctuation),是时间序列中呈现出来的围绕长期趋势的一种波浪形或振荡式波动。周期性是由商业和经济活动引起的,不同于趋势变动,不是朝着单一方向的持续运动,而是涨落相间的交替波动;不同于季节变动,季节变动有比较固定的规律,且变动周期大多为一年,循环波动则无固定规律,变动周期多在一年以上,且周期长短不一。周期性通常是由经济环境的变化引起。
除此之外,还有偶然性因素对时间序列产生影响,致使时间序列呈现出某种随机波动。时间序列除去趋势、周期性和季节性后的偶然性波动,称为随机性(random),也称不规则波动(irregular variations)。
时间序列的成分可分为4种:趋势(T)、季节性或季节变动(S)、周期性或循环波动(C)、随机性或不规则波动(I)。传统时间序列分析的一项主要内容就是把这些成分从时间序列中分离出来,并将它们之间的关系用一定的数学关系式予以表达,而后分别进行分析。按4种成分对时间序列的影响方式不同,时间序列可分解为多种模型:加法模型(additive model),乘法模型(multiplicative model)。乘法模型: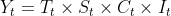
二、描述性分析
1、图形描述
2、增长率分析
是对现象在不同时间的变化状况所做的描述。由于对比的基期不同,增长率有不同的计算方法。
(1)增长率(growth rate):增长速度,是时间序列中报告期观察值与基期观察值之比减1后的结果,用%表示。由于对比的基期不同,可分为环比增长率和定基增长率。
环比增长率:是报告期观察值与前一时期观察值之比减1,说明现象逐期增长变化的程度;
定基增长率是报告期观察值与某一固定时期观察值之比减1,说明现象在整个观察期内总的增长变化程度。
设增长率为G: 环比增长率 :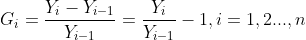
定基增长率 :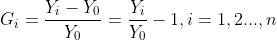
(2)平均增长率(average rate of increase):平均增长速度,是时间序列中逐期环比值(环比发展速度)的几何平均数减1的结果:![\bar{G}=\sqrt[n]{\frac{Y_1}{Y_{0}}\times \frac{Y_2}{Y_{1}}...\times \frac{Y_n-Y_{n-1}}{Y_{i-1}}}-1=\sqrt[n]{\frac{Y_n-Y_{n-1}}{Y_{0}}}-1](https://private.codecogs.com/gif.latex?%5Cbar%7BG%7D%3D%5Csqrt%5Bn%5D%7B%5Cfrac%7BY_1%7D%7BY_%7B0%7D%7D%5Ctimes%20%5Cfrac%7BY_2%7D%7BY_%7B1%7D%7D...%5Ctimes%20%5Cfrac%7BY_n-Y_%7Bn-1%7D%7D%7BY_%7Bi-1%7D%7D%7D-1%3D%5Csqrt%5Bn%5D%7B%5Cfrac%7BY_n-Y_%7Bn-1%7D%7D%7BY_%7B0%7D%7D%7D-1) n:环比值的个数
n:环比值的个数
(3)增长率分析中应注意的问题
i: 当时间序列中的观察出现0或负数时,不宜计算增长率。这种序列计算增长率,要么不符合数学公理,要么无法解释其实际意义。可用绝对数进行分析。
ii: 有些情况下,不能单纯就增长率论增长率,注意增长率与绝对水平结合起来。增长率是一个相对值,与对比的基数值的大小有关。这种情况,计算增长1%的绝对值来克服增长率分析的局限性:
增长1%的绝对值表示增长率每增长一个百分点而增加的绝对数量: 增长1%的绝对值=前期水平/100
增长1%的绝对值=前期水平/100
三、时间序列预测的程序
时间序列分析的主要目的之一是根据已有的历史数据对未来进行预测。时间序列含有不同的成分,如趋势、季节性、周期性和随机性。对于一个具体的时间序列,它可能含有一种成分,也可能同时含有几种成分,含有不同成分的时间序列所用的预测方法是不同的。预测步骤:
第一步:确定时间序列所包含的成分,确定时间序列的类型
第二步:找出适合此类时间序列的预测方法
第三步:对可能的预测方法进行评估,以确定最佳预测方案
第四步:利用最佳预测方案进行预测
1、确定时间序列成分
(1)确定趋势成分
确定趋势成分是否存在,可绘制时间序列的线图,看时间序列是否存在趋势,以及存在趋势是线性还是非线性。
利用回归分析拟合一条趋势线,对回归系数进行显著性检验。回归系数显著,可得出线性趋势显著的结论。
(2)确定季节成分
确定季节成分是否存在,至少需要两年数据,且数据需要按季度、月份、周或天来记录。可绘图,年度折叠时间序列图(folded annual time series plot),需要将每年的数据分开画在图上,横轴只有一年的长度,每年的数据分别对应纵轴。如果时间序列只存在季节成分,年度折叠时间序列图中的折线将会有交叉;如果时间序列既含有季节成分又含有趋势,则年度折叠时间序列图中的折线将不会有交叉,若趋势上升,后面年度的折线将会高于前面年度的折线,若下降,则后面年度的折线将会低于前面年度的折线。
2、选择预测方法
确定时间序列类型后,选择适当的预测方法。利用时间数据进行预测,通常假定过去的变化趋势会延续到未来,这样就可以根据过去已有的形态或模式进行预测。时间序列的预测方法:传统方法:简单平均法、移动平均法、指数平滑法等,现代方法:Box-Jenkins 的自回归模型(ARMA)。
一般来说,任何时间序列都会有不规则成分存在,在商务和管理数据中通常不考虑周期性,只考虑趋势成分和季节成分。
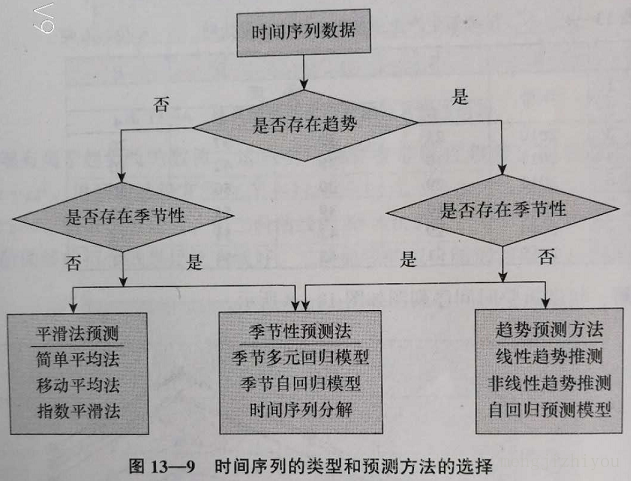
不含趋势和季节成分的时间序列,即平稳时间序列只含随机成分,只要通过平滑可消除随机波动。因此,这类预测方法也称平滑预测方法。
3、预测方法的评估
在选择某种特定的方法进行预测时,需要评价该方法的预测效果或准确性。评价方法是找出预测值与实际值的差距,即预测误差。最优的预测方法就是预测误差达到最小的方法。
预测误差计算方法:平均误差,平均绝对误差、均方误差、平均百分比误差、平均绝对百分比误差。方法的选择取决于预测者的目标、对方法的熟悉程度。
(1)平均误差(mean error):Y:观测值,F:预测值,n预测值个数
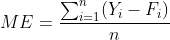
由于预测误差的数值可能有正有负,求和的结果就会相互抵消,这种情况下,平均误差可能会低估误差。
(2)平均绝对误差(mean absolute deviation)是将预测误差取绝对值后计算的平均无擦,MAD:

平均绝对误差可避免误差相互抵消的问题,因而可以准确反映实际预测误差的大小。
(3)均方误差(mean square error):通过平方消去误差的正负号后计算的平均误差,MSE:
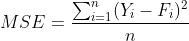
(4)平均百分比误差和平均绝对百分比误差
ME,MAD,MSE的大小受时间序列数据的水平和计量单位的影响,有时并不能真正反映预测模型的好坏,只有在比较不同模型对同一数据的预测时才有意义。平均百分比误差(mean percentage error,MPE)和平均绝对百分比误差(mean absolute percentage error,MAPE)则不同,它们消除了时间序列数据的水平和计量单位的影响,是反映误差大小的相对值。
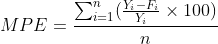
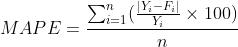
4、平稳序列的预测
平稳时间序列只含有随机成分,预测方法:简单平均法、移动平均法、指数平滑法。主要通过对时间序列进行平滑以消除随机波动,又称平滑法。平滑法可用于对时间序列进行短期预测,也可对时间序列进行平滑以描述序列的趋势(线性趋势和非线性趋势)。
(1)简单平均法:根据已有的t期观察值通过简单平均法来预测下一期的数值。设时间序列已有的t期观察值为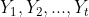 ,则t+1期的预测值
,则t+1期的预测值 为:
为:
到了t+1期后,有了t+1期的实际值,t+1期的预测误差 为:=
为:=
t+2期预测值:
简单平均法适合对较为平稳的时间序列进行预测,即当时间序列没有趋势时,用该方法比较好。但如果时间序列有趋势或季节成分,该方法的预测则不够准确。简单平均法将远期的数值和近期的数值看作对未来同等重要。从预测角度,近期的数值比远期的数值对未来有更大的作用,因此简单平均法预测的结果不够准确。
(2)移动平均法(moving average):通过对时间序列逐期递移求得平均数作为预测值的一种预测方法,有简单移动平均法(simple moving average)和加权移动平均法(weighted moving average).
简单移动平均将最近k期数据加以平均,作为下一期的预测值。设移动平均间隔为k(1<k<t),则t期的移动平均值为:
 是对时间序列的平滑结果,通过这些平滑值可描述出时间序列的变化形态或趋势。也可以用来预测。
是对时间序列的平滑结果,通过这些平滑值可描述出时间序列的变化形态或趋势。也可以用来预测。
t+1期的简单移动平均预测值为:
t+2期的简单移动平均预测值为:
移动平均法只使用最近k期的数据,在每次计算移动平均值时,移动的间隔都为k,也适合对较为平稳的时间序列进行预测。应用关键是确定合理的移动平均间隔k。对于同一个时间序列,采用不同的移动间隔,预测的准确性是不同的。可通过试验的方法,选择一个使均方误差达到最小的移动间隔。移动间隔小,能快速反映变化,但不能反映变化趋势;移动间隔大,能反映变化趋势,但预测值带有明显的滞后偏差。
移动平均法的基本思想:移动平均可以消除或减少时间序列数据受偶然性因素干扰而产生的随机变动影响,适合短期预测。
(3)指数平滑法(exponential smoothing)是通过对过去的观察值加权平均进行预测,使t+1期的预测值等t期的实际观察值与t期的预测值的加权的平均值。指数平滑法是从移动平均法发展而来,是一种改良的加权平均法,在不舍弃历史数据的前提下,对离预测期较近的历史数据给予较大权数,权数由近到远按指数规律递减,因此称指数平滑。指数平滑有一次指数平滑法、二次指数平滑法、三次指数平滑法等。
一次指数平滑法也称单一指数平滑法(single exponential smoothing),只有一个平滑系数,且观察值离预测时期越久远,权数变得越小。一次指数平滑是将一段时期的预测值与观察值的线性组合作为t+1时期的预测值,预测模型为:

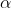 :平滑系数(
:平滑系数(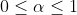 )
)
t+1期的数据是t期的实际观察值与t期的预测值的加权平均。1期的预测值=1期的观察值
2期预测值:
3期预测值:
4期预测值:
对指数平滑法的预测精度,用均方误差来=衡量:

是t期的预测值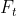 加上用调整的t期预测误差(
加上用调整的t期预测误差(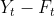 )。
)。
使用指数平滑法时, 关键问题是确定一个合适的平滑系数,不同的对预测结果产生不同的影响。
=0,预测值仅仅是重复上一期的预测结果;=1,预测值就是上一期的实际值;
越接近1,模型对时间序列变化的反应就越及时,因为它给当前的实际值赋予了比预测值更大的权数;
越接近0,给当前的预测值赋予了更大的权数,模型对时间序列变化的反应就越慢。
当时间序列有较大随机波动时,选较大,以便能很快跟上近期的变化;当时间序列比较平稳时,选较小。
实际应用中,需考虑预测误差,用均方误差衡量预测误差大小。确定时,可选择几个进行预测,然后找出预测误差最小的作为最后的值。
与移动平均法一样,一次指数平滑法可用于对时间序列进行修匀,以消除随机波动,找出序列的变化趋势。
用一次指数平滑法进行预测时,一般取值不大于0.5,若大于0.5,才能接近实际值,说明序列有某种趋势或波动过大。
阻尼系数 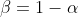 ,阻尼系数越小,近期实际值对预测结果的影响越大,反之,越小。阻尼系数是根据时间序列的变化特性来选取。
,阻尼系数越小,近期实际值对预测结果的影响越大,反之,越小。阻尼系数是根据时间序列的变化特性来选取。
5、趋势型序列的预测
时间序列的趋势可分为线性趋势和非线性趋势,若这种趋势能够延续到未来,就可利用趋势进行外推预测。有趋势序列的预测方法主要有线性趋势预测、非线性趋势预测和自回归模型预测。
(1) 线性趋势预测
线性趋势(linear trend)是指现象随着时间的推移而呈现稳定增长或下降的线性变化规律。
趋势方程:
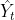 :时间序列
:时间序列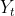 的预测值;
的预测值;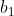 是趋势线斜率,表示时间t 变动一个单位,观察值的平均变动数量
是趋势线斜率,表示时间t 变动一个单位,观察值的平均变动数量
(2) 非线性趋势预测
序列中的趋势通常可认为是由于某种固定因素作用同一方向所形成的。若这种因素随时间推移按线性变化,则可对时间序列拟合趋势直线;若呈现出某种非线性趋势(non-linear trend),则需要拟合适当的趋势曲线。
i: 指数曲线(exponential curve):用于描述以几何级数递增或递减的现象,即时间序列的观察值按指数规律变化,或者时间序列的逐期观察值按一定的增长率增长或衰减。一般的自然增长及大多数经济序列都有指数变化趋势。
趋势方程: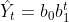
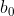 ,为待定系数
,为待定系数
若>1,则增长率随着时间t的增加而增加;若<1,则增长率随着时间t的增加而降低;若>0,<1,则预测值逐渐降低以到0为极限。
为确定,,可采用线性化手段将其化为对数直线形式,两端取对数:
根据最小二乘原理,按直线形式的常数确定方法求得 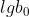 ,
,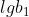 ,求出 ,后,再取其反对数,即可得到,。
,求出 ,后,再取其反对数,即可得到,。

ii: 多阶曲线:
有些现象变化形态复杂,不是按照某种固定的形态变化,而是有升有降,在变化过程中可能有几个拐点。这时就需要拟合多项式函数。当只有一个拐点时,可拟合二项曲线,即抛物线;当有两个拐点时,需要拟合三阶曲线;有k-1个拐点时,需要拟合k阶曲线。
6、复合型序列的分解预测
复合型序列是指含有趋势、季节、周期和随机成分的序列。对这类序列的预测方法是将时间序列的各个因素依次分解出来,然后进行预测。由于周期成分的分析需要有多年的数据,实际中很难得到多年的数据,因此采用的分解模型为: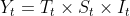
预测方法有:季节性多元回归模型、季节自回归模型和时间序列分解法预测。
分解法预测步骤:
第一步:确定并分离季节成分。计算季节指数,以确定时间序列中的季节成分。然后将季节成分从时间序列中分离出去,即用每一个时间序列观察值除以相应的季节指数,以消除季节性。
第二步:建立预测模型并进行预测。对消除了季节成分的时间序列建立适当的预测模型,并根据这一模型进行预测。
第三步:计算最后的预测值。用预测值乘以相应的季节指数,得到最终的预测值。
(1)确定并分离季节成分
季节性因素分析是通过季节指数来表示各年的季节成分,以此描述各年的季节变动模式。
i: 计算季节指数(seasonal index)
季节指数刻画了序列在一个年度内各月或各季度的典型季节特征。在乘法模型中,季节指数以其平均数等于100%为条件而构成的,反映了某一月份或季度的数值占全年平均值的大小。若现象的发展没有季节变动,则各期的季节指数应等于100%;若某一月份或季度有明显的季节变化,则各期的季节指数应大于或小于100%。因此,季节变动的程度是根据各季节指数与其平均数(100%)的偏差程度来测定的。
季节指数计算方法较多,移动平均趋势剔除法步骤:
第一步:计算移动平均值(若是季节数据,采用4项移动平均,月份数据则采用12项移动平均),并对其结果进行中心化处理,即将移动平均的结果再进行一次二项移动平均,即得出中心化移动平均值(CMA)。
第二步:计算移动平均的比值,即季节比率,即将序列的各观察值除以相应的中心化移动平均值,然后计算出各比值的季度或月份平均值。
第三步:季节指数调整。由于各季节指数的平均数应应等于1或100%,若根据第二步计算的季节比率的平均值不等于1,则需要进行调整。具体方法:将第二步计算的每个季节比率的平均值除以它们的总平均值。
ii: 分离季节成分
计算出季节指数后,可将各实际观察值分别除以相应的季节指数,将季节成分从时间序列中分离出去: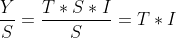
结果即为季节成分分离后的序列,反映了在没有季节因素影响下时间序列的变化形态。
iii: 建立预测模型并进行预测
7、时序案例分析
https://blog.csdn.net/mengjizhiyou/article/details/104765862
参考:贾俊平《统计学》第六版
《统计学》pdf及课后答案:链接: https://pan.baidu.com/s/1dZPW0smz2cO-67zfn1BFyQ 提取码: ktxq