参考博客:
处理点云数据(一):点云与生成鸟瞰图 - 灰信网(软件开发博客聚合)
点云数据
点云数据一般表示为N行,至少三列的numpy数组。每行对应一个单独的点,所以使用至少3个值的空间位置点(X, Y, Z)来表示。
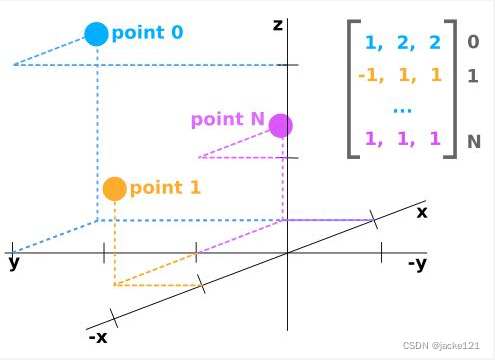
如果点云数据来自于激光雷达传感器,那么它可能有每个点的附加值,在KITTI数据中就有一个“反射率”,这是衡量激光光束在那个位置被反射回来了多少。所以在KITTI数据中,其点云数据就是N*4的矩阵。
如果点云数据来自于激光雷达传感器,那么它可能有每个点的附加值,在KITTI数据中就有一个“反射率”,这是衡量激光光束在那个位置被反射回来了多少。所以在KITTI数据中,其点云数据就是N*4的矩阵。
图像与点云坐标
图像的坐标轴和点云的坐标轴是不同的,下图显示了蓝色的图像轴和橙色的点云轴。
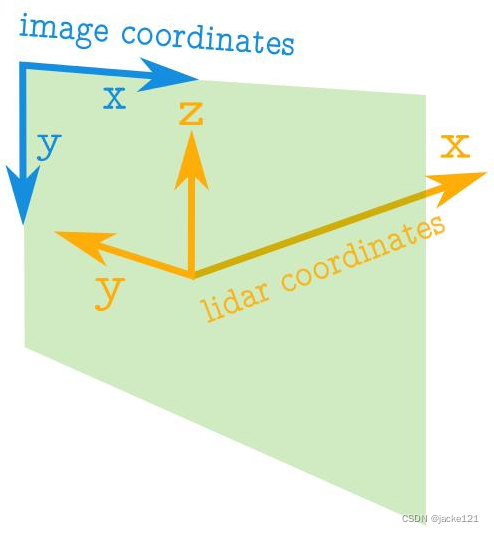
关于图像坐标轴:
1、图像中的坐标值总是正的。
2、原点位于左上角。
3、坐标是整数值。
关于点云坐标轴:
1、点云的坐标值可以是正数也可以是负数。
2、坐标是实数。
3、正X轴代表前方。
4、正Y轴代表左边。
5、正Z轴代表上方。
鸟瞰图的相关轴
为了创建鸟瞰图图像,点云数据中的相关轴将是 x 和 y 轴。
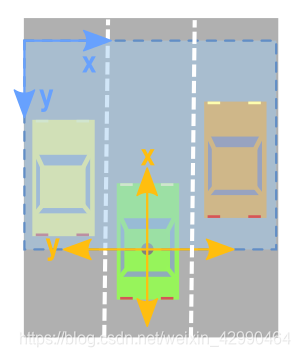
但是,从上图可以看出,我们必须小心并考虑以下事项:
x 和 y 轴的意思相反。
x 轴和 y 轴指向相反的方向。
您必须移动这些值,以便 (0,0) 是图像中的最小可能值。
限制矩形查看
只关注点云的特定区域通常很有用。因此,我们希望创建一个过滤器,只保留我们感兴趣的区域内的点。
由于我们正在查看顶部的数据并且我们有兴趣将其转换为图像,因此我将使用与图像轴更加一致的方向。下面,我指定了我想要关注的相对于原点的值范围。原点左侧的任何内容都将被视为负数,而右侧的任何内容都将被视为正数。点云的 x 轴将被解释为向前方向(这将是我们鸟瞰图像的向上方向)。
下面的代码将感兴趣的矩形设置为在原点两侧跨度 10m,在其前面跨度 20m。
side_range = ( -10 , 10 ) # 从最左边到最右边
fwd_range = ( 0 , 20 ) # 从最后到最前面
1
2
接下来,我们创建一个过滤器,只保留实际位于我们指定的矩形内的点。
# 提取每个轴的点
x_points = points[:, 0]
y_points = points[:, 1]
z_points = points[:, 2]
# 过滤器 - 仅返回所需立方体内点的索引
# 三个过滤器:前后、左右和高度范围
# 注意左侧是激光雷达坐标中的正 y 轴
f_filt = np.logical_and((x_points > fwd_range[0]), (x_points < fwd_range[1]))
s_filt = np.logical_and((y_points > -side_range[1]), (y_points < -side_range[0]))
filter = np.logical_and(f_filt, s_filt)
indices = np.argwhere(filter).flatten()
# 保持者
x_points = x_points[indices]
y_points = y_points[indices]
z_points = z_points[indices]
将点位置映射到像素位置
目前,我们有一堆具有实数值的点。为了映射那些将这些值映射到整数位置值。我们可以天真地将所有 x 和 y 值类型转换为整数,但我们最终可能会失去很多分辨率。例如,如果这些点的测量单位是米,那么每个像素将代表点云中一个 1x1 米的矩形,我们将丢失任何小于这个的细节。如果您有像山景这样的点云,这可能没问题。但如果你想捕捉更精细的细节,识别人类、汽车,甚至更小的东西,那么这种方法就不行了。
但是,可以稍微修改上述方法,以便我们获得所需的分辨率级别。在类型转换为整数之前,我们可以先缩放数据。例如,如果测量单位是米,而我们想要 5 厘米的分辨率,我们可以执行以下操作:
res = 0.05
# CONVERT TO PIXEL POSITION VALUES - Based on resolution
x_img = (-y_points / res).astype(np.int32) # x axis is -y in LIDAR
y_img = (-x_points / res).astype(np.int32) # y axis is -x in LIDAR
你会注意到 x 和 y 轴交换了,方向颠倒了,这样我们现在可以开始处理图像坐标了。
转移到新的原点
x 和 y 数据还没有完全准备好映射到图像。我们可能仍然有负的 x 和 y 值。所以我们需要移动数据使 (0,0) 成为最小值。
# SHIFT PIXELS TO HAVE MINIMUM BE (0,0)
# floor and ceil used to prevent anything being rounded to below 0 after shift
x_img -= int(np.floor(side_range[0] / res))
y_img += int(np.ceil(fwd_range[1] / res))
我们可以探索数据以向自己证明这些值现在都是正的,例如:
>>> x_img.min()
7
>>> x_img.max()
199
>>> y_img.min()
1
>>> y_img.max()
199
像素值
所以我们使用点数据来指定图像中的 x 和 y 位置。我们现在需要做的是指定我们想要填充这些像素位置的值。一种可能性是用高度数据填充它。
但要记住的两件事是:
像素值应该是整数。
像素值应介于 0-255 之间。
我们可以从数据中获取最小和最大高度值,并重新调整该范围以适应 0-255 的范围。此处将使用的另一种方法是设置我们想要关注的高度值范围,任何高于或低于该范围的值都会被剪裁为最小值和最大值。这很有用,因为它允许我们从感兴趣的区域获得最大量的细节。
在以下代码中,我们将范围设置为原点下方 2 米,原点上方半米。
height_range = (-2, 0.5) # bottom-most to upper-most
# CLIP HEIGHT VALUES - to between min and max heights
pixel_values = np.clip(a = z_points,
a_min=height_range[0],
a_max=height_range[1])
接下来,我们将这些值重新缩放到 0-255 之间,并将类型转换为整数。
def scale_to_255(a, min, max, dtype=np.uint8):
""" Scales an array of values from specified min, max range to 0-255
Optionally specify the data type of the output (default is uint8)
"""
return (((a - min) / float(max - min)) * 255).astype(dtype)
# RESCALE THE HEIGHT VALUES - to be between the range 0-255
pixel_values = scale_to_255(pixel_values, min=height_range[0], max=height_range[1])
创建图像数组
现在我们已准备好实际创建图像,我们只需初始化一个数组,其维度取决于我们在矩形中所需的值范围和我们选择的分辨率。然后我们使用转换为像素位置的 x 和 y 点值来指定数组中的索引,并将我们在上一小节中选择作为像素值的值分配给这些索引。
# INITIALIZE EMPTY ARRAY - of the dimensions we want
x_max = 1+int((side_range[1] - side_range[0])/res)
y_max = 1+int((fwd_range[1] - fwd_range[0])/res)
im = np.zeros([y_max, x_max], dtype=np.uint8)
# FILL PIXEL VALUES IN IMAGE ARRAY
im[y_img, x_img] = pixel_values
查看
目前,图像存储为一个 numpy 数组。如果我们希望将其可视化,我们可以将其转换为 PIL 图像并查看。
# CONVERT FROM NUMPY ARRAY TO A PIL IMAGE
from PIL import Image
im2 = Image.fromarray(im)
im2.show()

它实际上编码的信息量与 PIL 绘制的图像完全相同,因此机器学习算法仍然能够区分高度的差异,即使我们人类无法非常清楚地看到这些差异。
完整代码
为方便起见,我将上述所有代码放在一个函数中,该函数将鸟瞰图作为 numpy 数组返回。然后,您可以选择使用您喜欢的任何方法对其进行可视化,或者将 numpy 数组插入机器学习算法中。
import numpy as np
# ==============================================================================
# SCALE_TO_255
# ==============================================================================
def scale_to_255(a, min, max, dtype=np.uint8):
""" Scales an array of values from specified min, max range to 0-255
Optionally specify the data type of the output (default is uint8)
"""
return (((a - min) / float(max - min)) * 255).astype(dtype)
# ==============================================================================
# POINT_CLOUD_2_BIRDSEYE
# ==============================================================================
def point_cloud_2_birdseye(points,
res=0.1,
side_range=(-10., 10.), # left-most to right-most
fwd_range = (-10., 10.), # back-most to forward-most
height_range=(-2., 2.), # bottom-most to upper-most
):
""" Creates an 2D birds eye view representation of the point cloud data.
Args:
points: (numpy array)
N rows of points data
Each point should be specified by at least 3 elements x,y,z
res: (float)
Desired resolution in metres to use. Each output pixel will
represent an square region res x res in size.
side_range: (tuple of two floats)
(-left, right) in metres
left and right limits of rectangle to look at.
fwd_range: (tuple of two floats)
(-behind, front) in metres
back and front limits of rectangle to look at.
height_range: (tuple of two floats)
(min, max) heights (in metres) relative to the origin.
All height values will be clipped to this min and max value,
such that anything below min will be truncated to min, and
the same for values above max.
Returns:
2D numpy array representing an image of the birds eye view.
"""
# EXTRACT THE POINTS FOR EACH AXIS
x_points = points[:, 0]
y_points = points[:, 1]
z_points = points[:, 2]
# FILTER - To return only indices of points within desired cube
# Three filters for: Front-to-back, side-to-side, and height ranges
# Note left side is positive y axis in LIDAR coordinates
f_filt = np.logical_and((x_points > fwd_range[0]), (x_points < fwd_range[1]))
s_filt = np.logical_and((y_points > -side_range[1]), (y_points < -side_range[0]))
filter = np.logical_and(f_filt, s_filt)
indices = np.argwhere(filter).flatten()
# KEEPERS
x_points = x_points[indices]
y_points = y_points[indices]
z_points = z_points[indices]
# CONVERT TO PIXEL POSITION VALUES - Based on resolution
x_img = (-y_points / res).astype(np.int32) # x axis is -y in LIDAR
y_img = (-x_points / res).astype(np.int32) # y axis is -x in LIDAR
# SHIFT PIXELS TO HAVE MINIMUM BE (0,0)
# floor & ceil used to prevent anything being rounded to below 0 after shift
x_img -= int(np.floor(side_range[0] / res))
y_img += int(np.ceil(fwd_range[1] / res))
# CLIP HEIGHT VALUES - to between min and max heights
pixel_values = np.clip(a=z_points,
a_min=height_range[0],
a_max=height_range[1])
# RESCALE THE HEIGHT VALUES - to be between the range 0-255
pixel_values = scale_to_255(pixel_values,
min=height_range[0],
max=height_range[1])
# INITIALIZE EMPTY ARRAY - of the dimensions we want
x_max = 1 + int((side_range[1] - side_range[0]) / res)
y_max = 1 + int((fwd_range[1] - fwd_range[0]) / res)
im = np.zeros([y_max, x_max], dtype=np.uint8)
# FILL PIXEL VALUES IN IMAGE ARRAY
im[y_img, x_img] = pixel_values
return im
参考
http://ronny.rest/tutorials/module/pointclouds_01/point_cloud_birdseye/
————————————————
版权声明:本文为CSDN博主「点PY」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_42990464/article/details/119415687