Madhusudana P C, Birkbeck N, Wang Y, et al. Image quality assessment using contrastive learning[J]. IEEE Transactions on Image Processing, 2022.
(本篇博客中出现的图片大部分来源于原论文)
[toc]
[]
Abstract
想用自监督来做质量评估任务
- CNN : 用成对的图像来对比学习,完成辅助任务——预测失真类型和失真等级
- 提出方法: CONTRastive Image QUality Evaluator (CONTRIQUE)
I. INTRODUCTION
- 介绍图像质量评估是做什么的;介绍NR IQA是做什么的,所面临的挑战(受多因素的影响、受图像内容的影响);NR IQA研究的必要性,应用场景。
-
NR IQA 技术发展的历程:合成失真的数据集的生成及其缺点,真实失真数据集的生成及其特点。针对这些数据集,NR IQA模型所要针对解决的点。
-
建立NR-IQA模型主要依赖于参数化和学习方法。介绍了几种类型的NR-IQA 模型,包括 基于NSS的模型:通过统计获取特征用于质量预测;其优点是对于合成失真较为有效,但对于未知失真的图像质量预测效果表现受限; 基于CNN的模型:数据驱动的IQA 模型。
-
基于CNN的模型最大的限制:缺少带标签的大数据集,而建造数据集是一个很耗资源的活动。但是已经存在的数据集又太小,不能很好的训练CNN网络模型。因此大部分CNN网络针对以上问题的解决方案是:迁移学习(pretrained & fine-tuned), 缺点:针对不同的数据集,要做不同的超参数的微调。此外,过度微调容易产生过拟合,使得模型泛化性能下降。
-
我们打算使用没有标签的数据集来做 IQA,灵感来自于用于图像分类问题的无监督/自监督学习方法。
创新点:
-
失真类型、失真等级的预测作为辅助任务(CNN的训练在同时包含合成失真和真实失真的无标签的数据集上做,使用对比目标函数)
-
为了学习较强的表征信息,在训练中,多尺度的、质量保持的转换(quality preserving transformations )被应用在无标签的数据集上。
-
测试时,CNN网络的权重被冻结,从CNN输出的特征被映射到简单的全连接层做质量回归,得到质量分数。在多个数据集上取得较好的结果(没有额外的CNN网络的微调)。
-
我们设计的网络(CONTRIQUE )很简单,泛化性好,而且可以简单的扩展到FR IQA问题中(不用另外训练CNN网络)。
NR-IQA Models
所面临的挑战(跟自己本篇paper沾边的,也就是说,本篇paper能解决的问题)。以往工作是如何处理解决这一问题的。例如本文:提出问题—图像内容对于不同失真类型所附加的额外影响,影响到 IQA。
以往工作解决方案 :
- 提出超的网络结构来区分质量预测和内容理解
- 等级平滑损失函数
- 元学习:从不同的失真类型中获取先验知识
- 同时训练图像以及图像块
以上工作大部分都依赖于监督学习,然后做微调来获得好的效果。我们的工作主要是基于无监督,并且不需要微调。
提了一下transformer,并指出了本篇工作不适用transformer做基底的原因:模型较为复杂,需要大量的数据和算例,而且本篇工作主要在于讨论无监督学习,所以只基于CNN来做。
Self-Supervised Learning
自监督/无监督学习技术奏效,得益于从图像数据中提取到了有用的结构信息。
列举了一些自监督任务的例子
本篇提出将失真类型和失真程度的鉴别作为自监督任务,来帮助学习图像特征,以辅助质量预测任务。
III. METHOD
带通转换,如小波样分解,经常用于模拟初级视觉皮层的视觉神经元的反应,这些神经元对具有特定空间位置、频率和方向的视觉刺激进行调谐。
传统的NR-IQA模型是基于带通道转换,如DCT[12]、可导向金字塔[11]、局部均值-减法[13]、[14]等,在预测感知质量方面非常有效。
深度cnn引出的转换在捕获感知图像伪影[18],[20],[21]方面表现出了显著的效率。
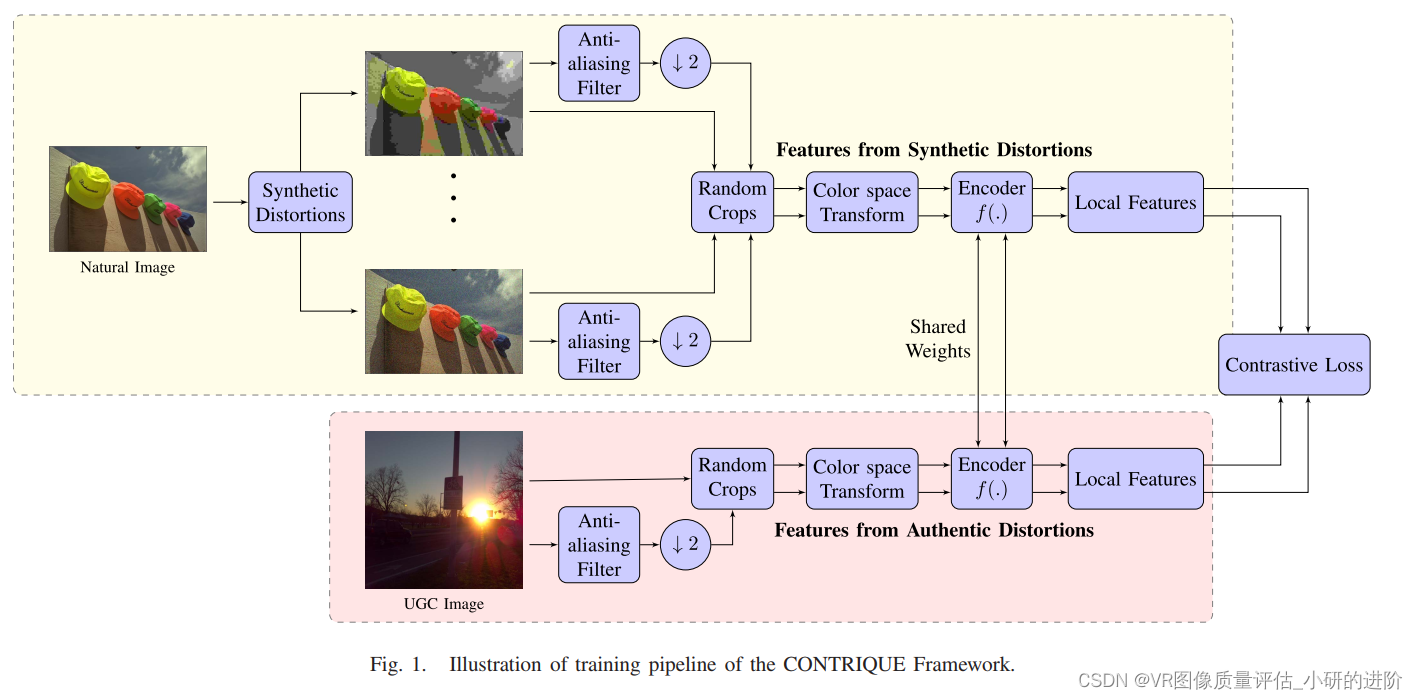
Auxiliary Task
概括什么是代理任务:代理的、密切相关的任务(真实标签较容易被知道或者获得)。然后我们的模型被训练来解决这个辅助任务,然后再将训练好的模型用在预测阶段。
以IQA为例:
- 目标——是获得能够区分不同类型失真以及失真程度的不同表征形式
- 因此,我们就将 IQA特征学习任务 转换成了 分类任务
- 每个类别是拥有相似失真类型以及相似失真程度的图像
- 使用的目标函数:交叉熵损失函数



损失函数:

N : 一个batch里的图像数量
Multi-scale Learning and Cropping
利用多尺度的特征,基于CNN的IQA模型获取到了很好的结果。
我们的CONTRIQUE 模型用到两个维度:
- 原分辨率
- 一半维度分辨率(通过沿两个维度的两个因子降采样获得,为了避免混叠伪影,在下采样前使用抗混叠滤波器。在这个调整大小操作中保留了纵横比,因为修改这个比例会影响底层图像的质量。)
然后图像被随机裁剪到固定大小:M x M
本篇选取的质量保持不变的变换:水平翻转 和 颜色空间转换
我们使用了四种颜色空间方式:
Realistic Distortions
在我们的模型中,每个UGC图像都被看作一个单独的类,由多种失真组合而成的一种结合,区别于其他UGC图像,也区别于合成失真的图像。
对于给定的UGC图像:xi
只有它的等变变换之后的图像: x j 跟它属于同一类 。
此时的损失函数是:

总的损失函数:

IV. EXPERIMENTS AND RESULTS
Correlation Against Human Judgments


Cross Dataset Evaluation

Visual Comparison of Representations

Significance of Training Data

Robustness to Training Data

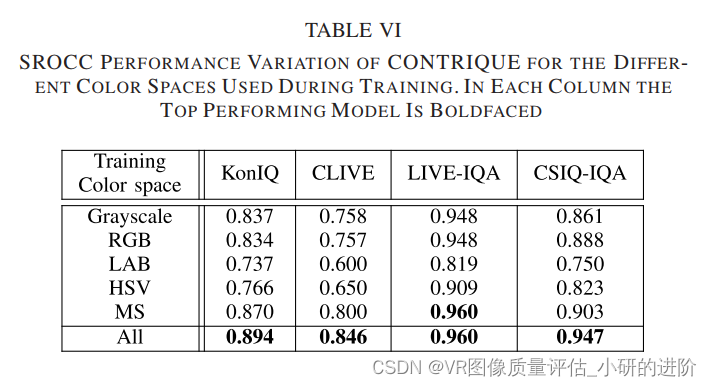
Importance of Different Color Spaces

Significance of Multi-scale Learning

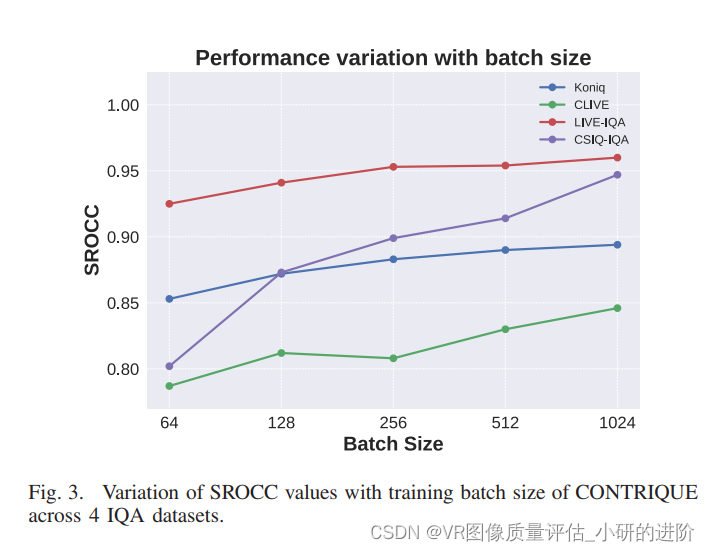
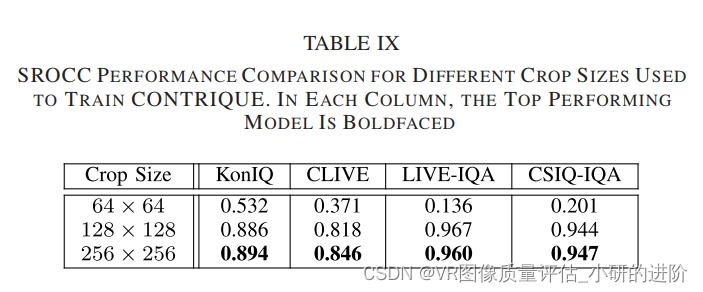
Effect of Batch Size and Crop Size
Limitations of the Model
