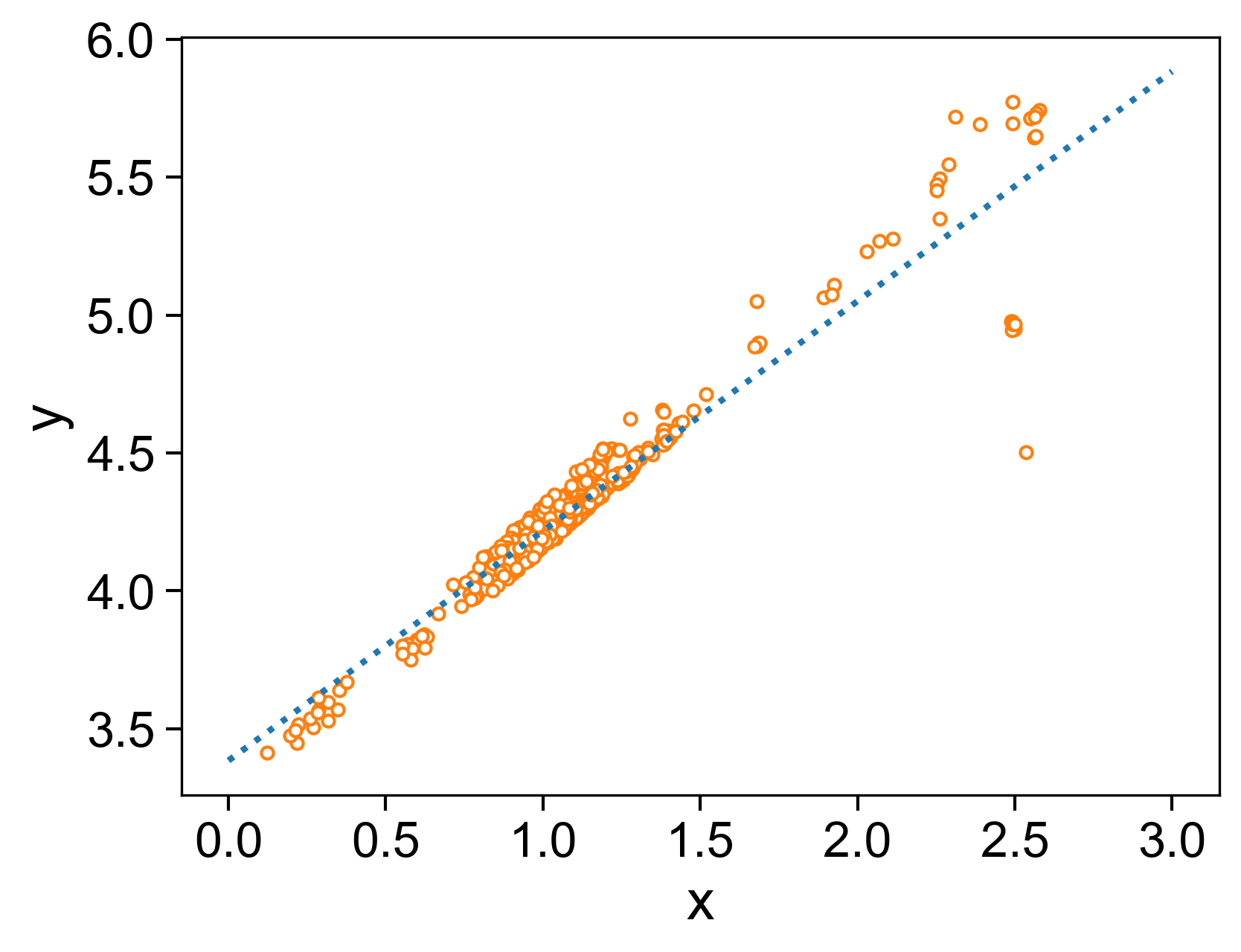
使用sklearn对数据进行线性回归,并绘制回归线
在科研工作中,有时得到一组或者几组数据,为了研究数据之间是否存在线性关系,一般会想到拟合数据,看下数据的线性关系。严格地说,是使用线性模型研究两个或多个变量之间规律的一种方法,这个过程就是线性回归。
本文以一元线性回归为例,记录处理过程。
基本思想
【线性回归步骤】
- 读入数据集
- 将数据集转为矩阵形式
- 进行回归训练
- 创建预测输入值
- 基于预测模型预测输出值
- 绘制回归曲线
代码实现
import matplotlib
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
#导入、读入数据
data=pd.read_excel(r"D:\desk\data.xlsx",header=0)
data_tolist = data.values.tolist()
x=[]
y=[]
for i in data_tolist:
x.append(i[0])
y.append(i[1])
#绘制散点图
#图形设置
plt.rcParams['figure.figsize']=(6.0,4.5)
plt.rcParams['savefig.dpi'] = 300 #图片像素
plt.rcParams['figure.dpi'] = 300 #分辨率
plt.rcParams['font.sans-serif']=['Arial']
plt.scatter(x,y,marker='o',s=15,c='white',edgecolors='tab:orange')
font1 = {'family' : 'Arial',
'weight' : 'normal',
'size' : 18,}
plt.xlabel('x',font1)
plt.ylabel('y',font1)
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
#plt.show()
#将数据整理为矩阵形式
T_x = np.array(x).reshape((len(x), 1))
T_y = np.array(y).reshape((len(y), 1))
#进行回归训练
lineModel = LinearRegression()
lineModel.fit(T_x, T_y)
#创建预测输入值
x_test=np.linspace(0,3,301)
T_x_test = np.array(x_test).reshape((len(x_test), 1))
#绘制预测曲线
plt.plot(T_x_test,lineModel.predict(T_x_test),linestyle='dotted',color='tab:blue')
ax=plt.gca()
labels = ax.get_xticklabels() + ax.get_yticklabels()
[label.set_fontname('Arial') for label in labels]
plt.tick_params(axis='both',width=1,length=5)
plt.show()
【图形输出】