欢迎关注公众号 - 【AICV与前沿】,一起学习最新技术吧
欢迎关注公众号 - 【AICV与前沿】,一起学习最新技术吧
欢迎关注公众号 - 【AICV与前沿】,一起学习最新技术吧
1. CLIP回顾
CLIP是2021年OpenAI提出的基于图文对比学习的多模态预训练模型,具备强大的zero-shot迁移能力。
数据集:来源于互联网上搜集的4亿个image-text对,涵盖了50万个qurey,并尽量保持不同qurey的数据量均衡。
核心思想:将image-text对当做一个整体,基于对比学习的方法,模型训练时尽可能地提高image与对应text的特征相似度,尽可能的降低image与不配对text的相似度。
具体如下图(1):
训练阶段
假设训练N个image-text图像文本对,CLIP的图像编码器对N个图像进行特征提取得到N个特征向量,同理文本编码器对N个文本进行特征提取得到N个文本特征向量。那么N个图像特征和N个文本特征两两比对就会得到N*N种概率。CLIP要做的就是尽可能提高对角线匹配对的相似分数,一共有N个,降低非对角线非匹配对的概率分数,一共有N(N-1)个。论文给出的伪代码如下:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
分别计算图像的交叉熵损失和文本的交叉熵损失,最后求平均得到最终损失。
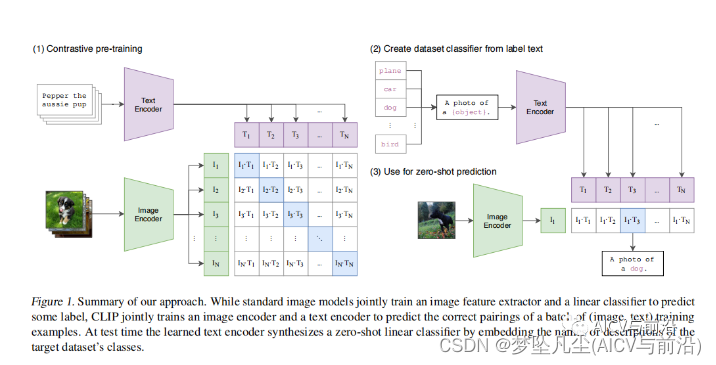
推理阶段
如图(2)和图(3),先准备好多个text prompt和一张image,然后CLIP会根据Text Encoder和Image Encoder输出的特征进行逐一匹配(可以看出分类问题转为检索问题)计算相似分数,根据相似分数从而获取到image对应的最大可能类别,反过来也可得到单个文本与多张图片中的某个进行匹配对应。
由于CLIP是基于文本与图像进行对比学习,所以对于没出现过(不在训练集里面)的图像,可以根据文本特征与图像特征匹配得到,这也是clip具备强大的zero-shot迁移能力的原因。
2. Chinese-CLIP
文章:https://arxiv.org/abs/2211.01335
代码:https://github.com/OFA-Sys/Chinese-CLIP
2.1 原理
2022年阿里达摩院开源的基于2亿中文原生图文对的多模态预训练模型。
数据集:大规模的中文图文对数据(约 2 亿规模),其中包括来自 LAION-5B 中文子集、Wukong 的中文数据、以及来自 COCO、Visual Genome 的翻译图文数据等。
为了提升训练效率和模型效果,Chinese-CLIP基于两阶段流程进行训练,具体如下:
(1)第一阶段,使用已有的图像预训练模型和文本预训练模型分别初始化 Chinese-CLIP 的双塔,并冻结图像侧参数,让语言模型关联上已有的图像预训练表示空间。这是由于CLIP的文本编码器是英文版本训练得到,所以需要对CLIP的文本表征模型进行重新训练。
(2)第二阶段,解冻图像侧参数,通过对比学习微调中文原生的图像和文本数据。
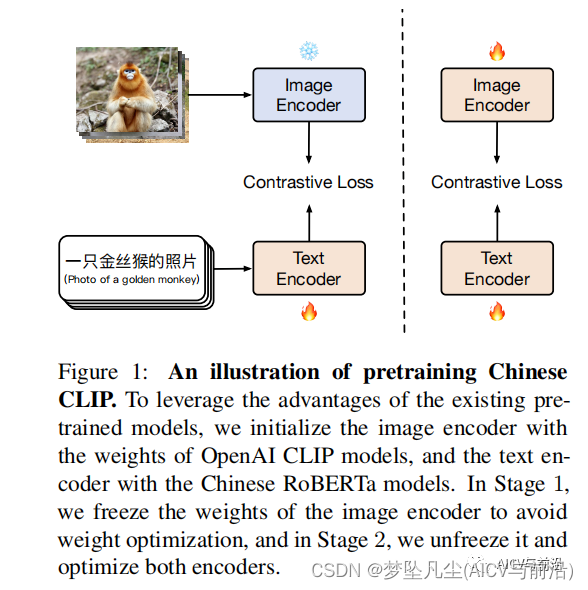
两阶段的训练流程优点如下:
(1)相比从头开始做预训练,该方法在多个下游任务上均展现显著更优的实验效果,而其显著更高的收敛效率也意味着更小的训练成本。
(2)相比全程只训练文本侧做一阶段训练,加入第二阶段微调训练能有效在图文下游任务,尤其是中文原生的图文任务上进一步提升效果。
2.2 实验结果
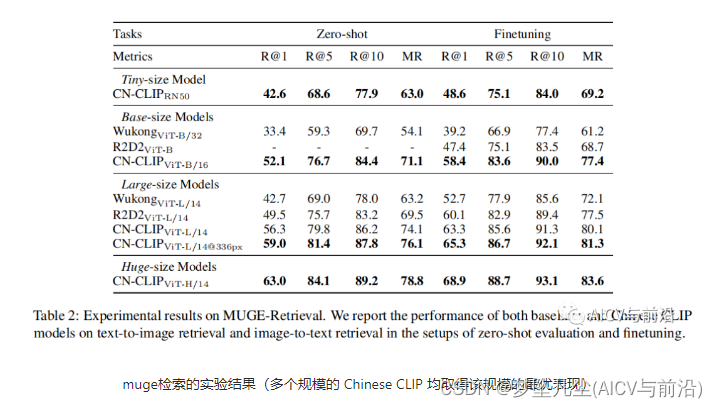
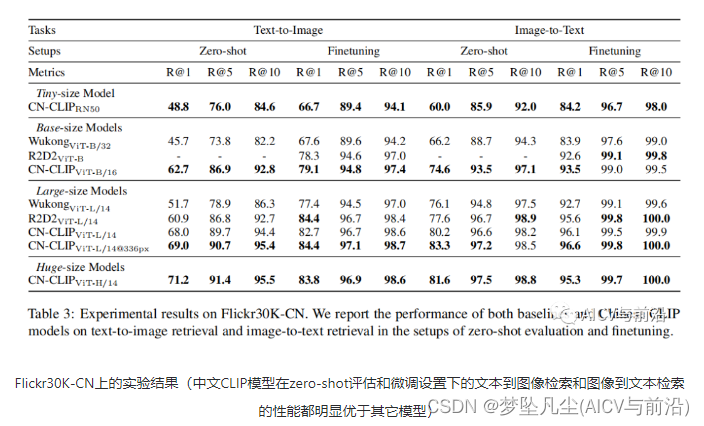
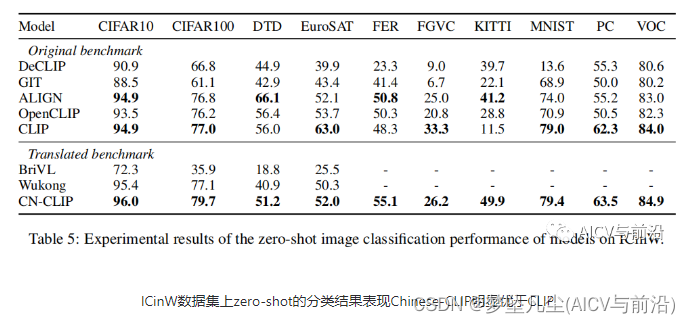
3. API快速上手
下面提供一段简单的代码示例说明如何使用中文CLIP的API。开始使用前,请先安装cn_clip
通过pip安装
pip install cn_clip
或者从源代码安装
cd Chinese-CLIP
pip install -e .
安装成功后,即可通过如下方式轻松调用API,传入指定图片(示例)和文本,提取图文特征向量并计算相似度。
import torch
from PIL import Image
import cn_clip.clip as clip
from cn_clip.clip import load_from_name, available_models
print("Available models:", available_models())
# Available models: ['ViT-B-16', 'ViT-L-14', 'ViT-L-14-336', 'ViT-H-14', 'RN50']
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = load_from_name("ViT-B-16", device=device, download_root='./')
model.eval()
image = preprocess(Image.open("examples/pokemon.jpeg")).unsqueeze(0).to(device)
text = clip.tokenize(["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
# 对特征进行归一化,请使用归一化后的图文特征用于下游任务
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
logits_per_image, logits_per_text = model.get_similarity(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # [[1.268734e-03 5.436878e-02 6.795761e-04 9.436829e-01]]
4. 图文检索应用
简单搭建一个可视化的图文检索服务,基于Chinese-Clip进行文到图以及图到图的检索,体验结果如下:
4.1 以文搜图
查询文本:一直奔跑的小狗

查询文本:夕阳、大海、沙滩
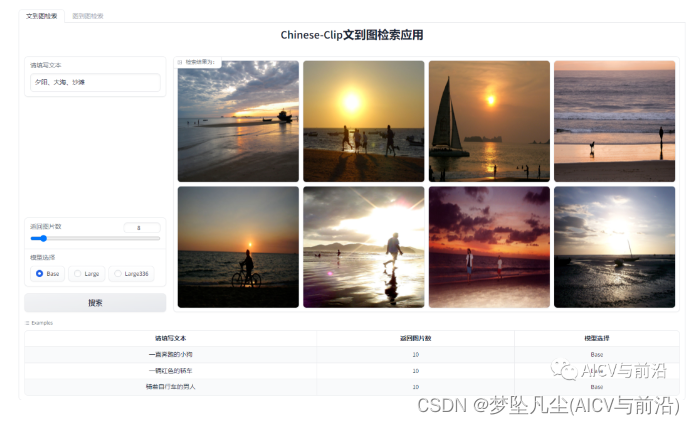
4.2 以图搜图


由于检索数据库来源于网上,并且量级较少,故检索结果可能会存在少许偏差,但也足以看出以文搜图和以图搜图都展示了Chinese-CLIP的强大能力。
参考文献
https://zhuanlan.zhihu.com/p/618490277
https://zhuanlan.zhihu.com/p/580546929
https://mp.weixin.qq.com/s/yks5sWxF6iPUlW5CSYs88A
https://github.com/OFA-Sys/Chinese-CLIP