1 soft-DTW来由
DTW 算法通过动态规划求解了两个序列的相似度。这个过程1是离散的,不可微的。如果要将其应用作为神经网络的损失函数,这是不行的。因为神经网络通过对损失函数结果进行梯度下降的方法,更新参数,要求损失函数可微。
2 符号说明
论文“A differentiable loss function for time-series”(2017 ICML)中使用了 Soft minimum 来代替 DTW minimum
对于两个序列 和
和 ,我们定义代价矩阵
,我们定义代价矩阵 ,其中δ是 可微代价函数
,其中δ是 可微代价函数 (某一时刻x上的p维信息+某一时刻y上的p维信息——>一个实数值)【通常δ(·,·)可以用欧几里得距离】
(某一时刻x上的p维信息+某一时刻y上的p维信息——>一个实数值)【通常δ(·,·)可以用欧几里得距离】
3 soft-DTW原理
定义集合 ,为路径上的代价和
,为路径上的代价和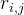 组成的集合(从(0,0)到(i,j)的最小开销路径的cost)
组成的集合(从(0,0)到(i,j)的最小开销路径的cost)
如果是DTW,那么它的动态规划式子为

如1所说,由于min是一个离散的过程,不可微,所以这导致了DTW的离散。
于是Soft-DTW使用了连续的soft-min

当γ=0的时候,就是DTW,否则他就是一个可微的式子
(在max函数的平滑(log-sum-exp trick)_UQI-LIUWJ的博客-CSDN博客 中,我们知道
![log(\sum_{i \in [1,n]}e^{x_i})=log(\sum_{i \in [1,n],i \ne j}e^{x_i}+e^{x_j}) \approx log(e^{x_j})=x_j=max \{x_1,\dots,x_n \}](https://latex.csdn.net/eq?log%28%5Csum_%7Bi%20%5Cin%20%5B1%2Cn%5D%7De%5E%7Bx_i%7D%29%3Dlog%28%5Csum_%7Bi%20%5Cin%20%5B1%2Cn%5D%2Ci%20%5Cne%20j%7De%5E%7Bx_i%7D+e%5E%7Bx_j%7D%29%20%5Capprox%20log%28e%5E%7Bx_j%7D%29%3Dx_j%3Dmax%20%5C%7Bx_1%2C%5Cdots%2Cx_n%20%5C%7D)
那么这里也是类似的

![=-log (\sum_{i \in [1,n]} e^{-a_i})](https://latex.csdn.net/eq?%3D-log%20%28%5Csum_%7Bi%20%5Cin%20%5B1%2Cn%5D%7D%20e%5E%7B-a_i%7D%29)
![=-log [\sum_{i \in [1,n]} (e^\frac{{-a_i}}{\gamma})^\gamma]](https://latex.csdn.net/eq?%3D-log%20%5B%5Csum_%7Bi%20%5Cin%20%5B1%2Cn%5D%7D%20%28e%5E%5Cfrac%7B%7B-a_i%7D%7D%7B%5Cgamma%7D%29%5E%5Cgamma%5D)
这里这篇论文做了一个近似
![\approx -log [\sum_{i \in [1,n]} (e^\frac{{-a_i}}{\gamma})]^\gamma](https://latex.csdn.net/eq?%5Capprox%20-log%20%5B%5Csum_%7Bi%20%5Cin%20%5B1%2Cn%5D%7D%20%28e%5E%5Cfrac%7B%7B-a_i%7D%7D%7B%5Cgamma%7D%29%5D%5E%5Cgamma)
也就等于 了
了
3.1 前向传播
定义 ,这是一个集合,其中的每一个元素A是一个矩阵,该矩阵表示两个时间序列x和y之间的对齐矩阵(alignment matrix)
,这是一个集合,其中的每一个元素A是一个矩阵,该矩阵表示两个时间序列x和y之间的对齐矩阵(alignment matrix)
对于一个特定的对齐矩阵 ,A中只有在(1,1)到(n,m)路径上的点(i,j),其
,A中只有在(1,1)到(n,m)路径上的点(i,j),其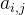 =1,其他点的都是0。
=1,其他点的都是0。
以DTW中出现过的图为例,那种情况下的A矩阵,在红色箭头上的(i,j),其=1,其余点的均为0DTW 笔记: Dynamic Time Warping 动态时间规整 (&DTW的python实现)_UQI-LIUWJ的博客-CSDN博客

换句话说, 中包含了所有(1,1)到(n,m)的路径(每个路径是一个矩阵,每个矩阵只有路径上的元素为1)
中包含了所有(1,1)到(n,m)的路径(每个路径是一个矩阵,每个矩阵只有路径上的元素为1)
于是矩阵内积<A,Δ(x,y)>表示这条路径下的代价和(非这条路径上的点乘0,这条路径上的点乘1,再求和)
于是,soft-dtw的目标函数为

3.1.1 算法伪代码
如果γ=0的时候,也就退化为了DTW,这里不同的是,我们需要关注γ>0的情况

3.2 反向传播
soft-DTW的目的是为了计算时间序列x和时间序列y之间的动态扭曲距离,y是目标序列的话,我们反向传播计算的是对时间序列x的梯度,也即
通过链式法则,我们有

这里 的分子和分母都是矩阵,所以线性代数笔记:标量、向量、矩阵求导_UQI-LIUWJ的博客-CSDN博客
的分子和分母都是矩阵,所以线性代数笔记:标量、向量、矩阵求导_UQI-LIUWJ的博客-CSDN博客


也就是在我们的问题中, 都是一个p×m维矩阵,那么整体上是一个np×nm的矩阵(记
都是一个p×m维矩阵,那么整体上是一个np×nm的矩阵(记
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)