在贝叶斯分类中,我们希望确定一个具有某些特征的样本属于某类标签的概率,通常记为 P (L | 特征 )。
贝叶斯定理告诉我们,可以直接用下面的公式计算这个概率:
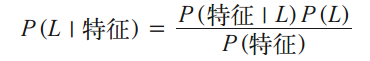
假如需要确定两种标签,定义为 L1 和 L2,一种方法就是计算这两个标签的后验概率的比值:
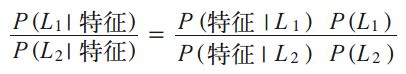
其中,P(L1)和P(L2)的值根据训练集中各个类别的数据所占比例,可以简单方便的获得。
现在需要一种模型,帮我们计算每个标签的 P ( 特征 | Li)。这种模型被称为生成模型,因为它可以训练出生成输入数据的假设随机过程(或称为概率分布)。
满足不同概率分布的数据,会使得模型的训练得到不同的结果。
“朴素贝叶斯”对每种标签的生成模型进行了简单的假设,假设数据满足某种特定的概率分布,且特征变量满足一些特定的关系(线性无关、相关)
导入库
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
(1) 高斯朴素贝叶斯
假设每个标签的数据都服从简单的高斯分布。且变量无协方差(no covariance,指线性无关)。只要找出每个标签的所有样本点均值和标准差,再定义一个高 斯分布,就可以拟合模型了。
生成随机数据:
from sklearn.datasets import make_blobs
X, y = make_blobs(100, 2, centers=2, random_state=2, cluster_std=1.5)
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap='RdBu')

实例化高斯模型,并拟合数据:
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X,y)
生成测试数据,并预测:
rng = np.random.RandomState(0)
Xnew = [-6,-14] + [14,18] * rng.rand(2000,2)
ynew = model.predict(Xnew)
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap='RdBu')
lim = plt.axis()
plt.scatter(Xnew[:,0],Xnew[:,1],c=ynew,s=20,cmap='RdBu',alpha=0.1)
plt.axis(lim)

predict_proba 方法计算样本属于某个标签的概率:
yprob = model.predict_proba(Xnew)
yprob[-8:].round(2)

多项式朴素贝叶斯
还有一种常用的假设是多项式朴素贝叶斯(multinomial naive Bayes),它假设特征是由一个简单多项式分布生成的。多项分布可以描述各种类型样本出现次数的概率,因此多项式朴素贝叶斯非常适合用于描述出现次数或者出现次数比例的特征。
这个理念和前面介绍的一样,只不过模型数据的分布不再是高斯分布,而是用多项式分布代替而已
案例: 文本分类
多项式朴素贝叶斯通常用于文本分类,其特征都是指待分类文本的单词出现次数或者频 次。
这里用 20 个网络新闻组语料库(20 Newsgroups corpus,约 20 000 篇新闻)的单词出现次数作为特征,演示如何用多项式朴素贝叶斯对这 些新闻组进行分类
下载数据并看看新闻组的名字:
from sklearn.datasets import fetch_20newsgroups
data = fetch_20newsgroups()
data.target_names

为了简化演示过程,只选择四类新闻,下载训练集和测试集:
categories = ['talk.religion.misc','soc.religion.christian','sci.space','comp.graphics']
train = fetch_20newsgroups(subset='train', categories=categories)
test = fetch_20newsgroups(subset='test', categories=categories)
print(train.data[5])

使用TF–IDF 向量化方法,将每个字符串的内容转换成数值向量,并使用多项式朴素贝叶斯分类器训练。
创建管道,训练数据,预测:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
model = make_pipeline(TfidfVectorizer(), MultinomialNB())
model.fit(train.data,train.target)
labels = model.predict(test.data)
用混淆矩阵统计测试数据的真实标签与预测标签的结果:
from sklearn.metrics import confusion_matrix
mat = confusion_matrix(test.target, labels)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,
xticklabels=train.target_names, yticklabels=train.target_names)
plt.xlabel('true label')
plt.ylabel('predicted label')

依据训练得到的模型,构建对任何字符串进行分类的分类器:
def predict_category(s, train=train, model=model):
pred = model.predict([s])
return train.target_names[pred[0]]
predict_category('sending a payload to the ISS')
#'sci.space'
predict_category('determining the screen resolution')
'comp.graphics'