本系列之前的篇章都是基于单线程处理。实际工程中,通过多线程对程序进行并行化往往是最简单且直接有效的优化手段。本篇以C++性能优化系列——矩阵转置(三)内存填充避免缓存抖动 中优化好的程序为Base版本,通过OpenMP技术,对程序进一步做并行化加速。同时,对OpenMP提供的并行化与开辟并行区方式进行试验,探索出OpenMP做并行化的一些规律。
c++转置并行化
代码实现
unsigned char* pSource;
pSource = (unsigned char*)malloc(sizeof(unsigned char) * NREALCOL * NROW);
for (int irow = 0; irow < NROW; ++irow)
{
memset(pSource + irow * NREALCOL, irow % 256, sizeof(unsigned char) * NREALCOL);//按照字节赋值
}
unsigned char* pTarget;
InitMem(pTarget);
clock_t begin = clock();
int nbC = NCOL / BLOCK, nbR = NROW / BLOCK;
for (int i = 0; i < REPEAT; ++i)
{
#pragma omp parallel for num_threads(8) schedule(static)
for (int ibr = 0; ibr < nbR; ++ibr)
{
for (int ibc = 0; ibc < nbC; ++ibc)
{
for (int irow = 0; irow < BLOCK; ++irow)
{
for (int icol = 0; icol < BLOCK; ++icol)
{
pTarget[(ibr * BLOCK + irow) * NROW + icol] = pSource[(ibc * BLOCK + icol) * NREALCOL + irow];
}
}
}
}
}
clock_t end = clock();
std::cout << "PaddingTranspose 1024 Time " << (end - begin) << std::endl;
std::cout << "PaddingTranspose parallel Time (ms) " << ((float)(end - begin)) / (float)REPEAT << std::endl;
代码中for循环使用静态的策略。
执行时间
PaddingTranspose parallel Time (ms) 0.114258
同时,也尝试了对for循环使用不同的调度模式。
运行时动态调度
#pragma omp parallel for num_threads(8) schedule(dynamic)
执行时间
PaddingTranspose parallel Time (ms) 0.105469
默认调度
#pragma omp parallel for num_threads(8)
执行时间
PaddingTranspose parallel Time (ms) 0.121094
三种并行化方式,对比Base版本,得到的最大加速比为 0.367188 / 0.105469 = 3.48。加速比并不理想。
测试执行耗时排序:
动态调度 < 静态调度 < 默认调度
静态调度方法,理论上每个线程的负载是一样的,原则上应该是static的方式运行速度应该最快。基于我的认知,尝试解释当前执行速度不符合预期的原因:实际程序运行情况与理论存在一定的偏差,由于矩阵尺寸太小,每个线程的负载太低,同时线程启动,同步等耗时不均匀,并行区线程启动等耗时占用比例过大,造成了目前这样的现象。
VTune分析
函数耗时统计,可以看到OpenMP线程同步占一定的比重。
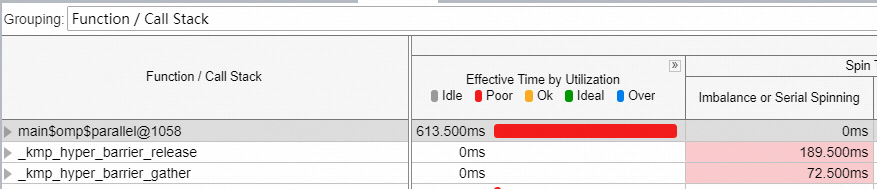
并行区线程执行情况。


并行区内8个线程在有效执行指令中,夹杂着大量同步等待时间。
造成这一点的可能原因(个人理解):
并行化过程包括创建并行区,各线程执行分配来的任务,并行区析构。每个过程的执行都要消耗一定的CPU执行时间。同时,一次并行执行的过程中,每个线程的只是对128 * 1024个Byte数据进行内存搬运,线程负载太小。因此,当前的实现方式(频繁的创建和析构并行区)造成多线程利用率低,多线程加速比不理想。
此外,尝试了在for循环最外层开辟并行区,内层循环用omp for迭代,避免并行区的频繁开辟,效果不明显,执行时间几乎没变化。
试验OpemMP并行方案
针对通过OpenMP对for循环的并行处理,可引申出两个问题:
1.OpenMP的调度方式static/dynamic对执行性能的影响
2.开辟并行区位置对执行性能的影响
为了测试上述影响,只需要对两个因素分别做更改并依次试验:并行区位置与调度方式。此外,为了排除线程负载过小带来的干扰,加大线程的负载,将二维矩阵尺寸更改为 32k * 32k。一次迭代每个线程要处理数据128M。
矩阵尺寸相关定义,其中把矩阵尺寸更新成32K,同时为了避免运行时间过长,通过调成重复次数至50次。
#define NROW 1024*32
#define NCOL 1024*32
#define NREALCOL (NCOL + 128)
#define NSLICE NROW*NCOL
#define REPEAT 50
#define BLOCK 128
内部开辟并行区,静态调度
代码实现
for (int i = 0; i < REPEAT; ++i)
{
#pragma omp parallel for num_threads(8) schedule(static)
for (int ibr = 0; ibr < nbR; ++ibr)
{
for (int ibc = 0; ibc < nbC; ++ibc)
{
for (int irow = 0; irow < BLOCK; ++irow)
{
for (int icol = 0; icol < BLOCK; ++icol)
{
pTarget[(ibr * BLOCK + irow) * NROW + icol] = pSource[(ibc * BLOCK + icol) * NREALCOL + irow];
}
}
}
}
}
执行时间
PaddingTranspose parallel Time (ms) 120.84
VTune数据
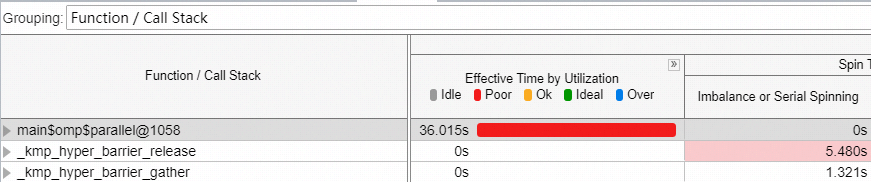

可以看到,代码执行时,并行区析构前的同步占了一定的比重,影响了程序执行的性能。
代码内部开辟并行区,动态调度
代码实现
for (int i = 0; i < REPEAT; ++i)
{
//#pragma omp for schedule(dynamic)
#pragma omp parallel for num_threads(8) schedule(dynamic)
for (int ibr = 0; ibr < nbR; ++ibr)
{
for (int ibc = 0; ibc < nbC; ++ibc)
{
for (int irow = 0; irow < BLOCK; ++irow)
{
for (int icol = 0; icol < BLOCK; ++icol)
{
pTarget[(ibr * BLOCK + irow) * NROW + icol] = pSource[(ibc * BLOCK + icol) * NREALCOL + irow];
}
}
}
}
}
执行时间
PaddingTranspose parallel Time (ms) 127.04
VTune数据


可以看到,动态调度CPU利用效率更高,并行区内部线程同步时间比重降低了,占用的CPU资源基本上都用在执行程序。从有效时间比重这个参数来说,程序时变好了。但是执行速度变慢了,猜测可能的原因:VTune将并行区创建和析构统计为有效的执行时间,同时动态调度策略会对运行时的一些情况作出判断,额外的动作会增加线程负载。因此虽然比重降低了,但是总时间增加。
外部开辟并行区,内部静态调度
代码实现
#pragma omp parallel num_threads(8)
for (int i = 0; i < REPEAT; ++i)
{
#pragma omp for schedule(static)
//#pragma omp parallel for num_threads(8) schedule(dynamic)
for (int ibr = 0; ibr < nbR; ++ibr)
{
for (int ibc = 0; ibc < nbC; ++ibc)
{
for (int irow = 0; irow < BLOCK; ++irow)
{
for (int icol = 0; icol < BLOCK; ++icol)
{
pTarget[(ibr * BLOCK + irow) * NROW + icol] = pSource[(ibc * BLOCK + icol) * NREALCOL + irow];
}
}
}
}
}
执行时间
PaddingTranspose parallel Time (ms) 115.38
VTune数据
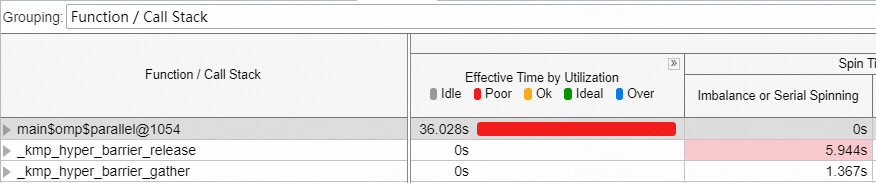

虽然夹杂的大量的同步时间,但是这种方法比内部开辟并行区执行速度快了一些。
外部开辟并行区,内部动态调度
代码实现
#pragma omp parallel num_threads(8)
for (int i = 0; i < REPEAT; ++i)
{
#pragma omp for schedule(dynamic)
//#pragma omp parallel for num_threads(8) schedule(dynamic)
for (int ibr = 0; ibr < nbR; ++ibr)
{
for (int ibc = 0; ibc < nbC; ++ibc)
{
for (int irow = 0; irow < BLOCK; ++irow)
{
for (int icol = 0; icol < BLOCK; ++icol)
{
pTarget[(ibr * BLOCK + irow) * NROW + icol] = pSource[(ibc * BLOCK + icol) * NREALCOL + irow];
}
}
}
}
}
执行时间
PaddingTranspose parallel Time (ms) 103.86
VTune数据


同步时间少,运行速度最快。
四组测试对比下来,外部开辟并行区,内部for循环动态调度 方案运行最快。
对比四个测试程序的执行情况,可以得到以下规律:
1.静态调度相比动态调度,线程同步的时间占比更大,但是总时间哪个方法快不能确定。
2.并行区开辟在最外层(即避免频繁的创建和析构并行区)速度更快,额外开销更小。
总结
本篇对矩阵转置进行并行化处理,在8核心的CPU上,实际得到的加速比为3.48,并不理想。同时,引申出的OpenMP的使用方法的探讨,文中的测试程序因为任务粒度小,因此动态调度效果好于静态调度。对于实际更加复杂的工程代码,可以通过尝试不同的调度方案来最终确定合理的调度方式。