生信人的20个R语言习题
题目原文:http://www.bio-info-trainee.com/3409.html
参考答案:https://www.jianshu.com/p/dd4e285665e1 https://www.jianshu.com/p/dd4e285665e1
参考答案:https://www.jianshu.com/p/c62cbb9e1a2e
1.安装一些R包:
数据包: ALL, CLL, pasilla, airway
软件包:limma,DESeq2,clusterProfiler
工具包:reshape2
绘图包:ggplot2
不同领域的R包使用频率不一样,在生物信息学领域,尤其需要掌握bioconductor系列包。
# R包的安装一般分为两种
# 1.对于bioconductor的安装。可在下面的网站中查询包是否属于bioconductor系列
# https://www.bioconductor.org/packages/release/BiocViews.html#___Software
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install(c('ALL','CLL','pasilla','clusterProfiler'))
BiocManager::install(c('airway','DESeq2','edgeR','limma'))
# 2.对于普通包的安装
install.packages("reshape2", "ggplot2")
第2题
了解ExpressionSet对象,比如CLL包里面就有data(sCLLex) ,找到它包含的元素,提取其表达矩阵(使用exprs函数),查看其大小
A参考:http://www.bio-info-trainee.com/bioconductor_China/software/limma.html
B参考:https://github.com/bioconductor-china/basic/blob/master/ExpressionSet.md

文章连接
ExpressionSet 类旨在将多个不同的信息源组合到一个方便的结构中。
ExpressionSet 可以方便地操作(例如,子集化、复制),并且是许多 Bioconductor 函数的输入或输出。
ExpressionSet类包含:
assayData:微阵列表达数据
phenodata:实验样本的描述
featuredata:实验所用芯片或技术的特点
annotation:注释信息
experimentData:描述实验的一种灵活结构
if (!require("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("CLL")
suppressPackageStartupMessages(library(CLL))
data("sCLLex")
sCLLex
# 获得表达矩阵
exprSet <- exprs(sCLLex)
class(exprSet)
dim(exprSet)
#查看样本编号
sampleNames(sCLLex)
#查看所有表型变量
varMetadata(sCLLex)
#查看基因芯片编码
featureNames(sCLLex)[1:100]
# 取sCLLex中phenoData中的data
pdata <- pData(sCLLex)
group_list <- as.character(pdata[,2])
table(group_list)
suppressPackageStartupMessages(library(CLL))
data(sCLLex)
exprSet=exprs(sCLLex)
##sCLLex是依赖于CLL这个package的一个对象
samples=sampleNames(sCLLex)
pdata=pData(sCLLex)
group_list=as.character(pdata[,2])
dim(exprSet)
# [1] 12625 22
exprSet[1:5,1:5]
# CLL11.CEL CLL12.CEL CLL13.CEL CLL14.CEL CLL15.CEL
# 1000_at 5.743132 6.219412 5.523328 5.340477 5.229904
# 1001_at 2.285143 2.291229 2.287986 2.295313 2.662170
# 1002_f_at 3.309294 3.318466 3.354423 3.327130 3.365113
# 1003_s_at 1.085264 1.117288 1.084010 1.103217 1.074243
# 1004_at 7.544884 7.671801 7.474025 7.152482 6.902932
3.了解 str,head,help函数,作用于 第二步提取到的表达矩阵
str(exprSet)
# str: Compactly display the internal structure of an R object, a diagnostic function and an alternative to summary (and to some extent, dput).
head(exprSet)
# 看一下exprSet的结构
str(exprSet)
# 显示前六行(默认)
head(exprSet)
# 如何想看几行就看几行呢 10为例
head(exprSet,n=10)
# 万物皆可"help"&"?"
help()
# 展示内部结构
str(exprSet)
# 默认展示前6行
head(exprSet)
# 提供帮助文档
help("sCLLex")
4. 安装并了解hgu95av2.db包,看看ls(“package:hgu95av2.db”)后显示的那些变量。
# 使用bioconductor系列包的安装方法
BiocManager::install("hgu95av2.db")
suppressPackageStartupMessages(library(hgu95av2.db))
ls("package:hgu95av2.db")
# BiocManager::install('hgu95av2.db')
library(hgu95av2.db)
# 如前
ls("package:hgu95av2.db")
hgu95av2.db是一个注释包,它为hgu95av2平台的芯片提供注释,这个包中有很多注释文件,
BiocManager::install("hgu95av2.db")
library(hgu95av2.db)
ls("package:hgu95av2.db")
#[1] "hgu95av2" "hgu95av2.db" "hgu95av2_dbconn" "hgu95av2_dbfile" "hgu95av2_dbInfo" "hgu95av2_dbschema"
[7] "hgu95av2ACCNUM" "hgu95av2ALIAS2PROBE" "hgu95av2CHR" "hgu95av2CHRLENGTHS" "hgu95av2CHRLOC" "hgu95av2CHRLOCEND"
[13] "hgu95av2ENSEMBL" "hgu95av2ENSEMBL2PROBE" "hgu95av2ENTREZID" "hgu95av2ENZYME" "hgu95av2ENZYME2PROBE" "hgu95av2GENENAME"
[19] "hgu95av2GO" "hgu95av2GO2ALLPROBES" "hgu95av2GO2PROBE" "hgu95av2MAP" "hgu95av2MAPCOUNTS" "hgu95av2OMIM"
[25] "hgu95av2ORGANISM" "hgu95av2ORGPKG" "hgu95av2PATH" "hgu95av2PATH2PROBE" "hgu95av2PFAM" "hgu95av2PMID"
[31] "hgu95av2PMID2PROBE" "hgu95av2PROSITE" "hgu95av2REFSEQ" "hgu95av2SYMBOL" "hgu95av2UNIGENE" "hgu95av2UNIPROT"
安装了hgu95av2.db之后用ls可以查看这个包里面有36个映射数据,都是把芯片探针ID号转为其它36种主流ID号的映射而已。
library(hgu95av2.db)
> ls("package:hgu95av2.db")
[1] "hgu95av2" "hgu95av2ACCNUM" "hgu95av2ALIAS2PROBE"
[4] "hgu95av2CHR" "hgu95av2CHRLENGTHS" "hgu95av2CHRLOC"
[7] "hgu95av2CHRLOCEND" "hgu95av2.db" "hgu95av2_dbconn"
[10] "hgu95av2_dbfile" "hgu95av2_dbInfo" "hgu95av2_dbschema"
[13] "hgu95av2ENSEMBL" "hgu95av2ENSEMBL2PROBE" "hgu95av2ENTREZID"
[16] "hgu95av2ENZYME" "hgu95av2ENZYME2PROBE" "hgu95av2GENENAME"
[19] "hgu95av2GO" "hgu95av2GO2ALLPROBES" "hgu95av2GO2PROBE"
[22] "hgu95av2MAP" "hgu95av2MAPCOUNTS" "hgu95av2OMIM"
[25] "hgu95av2ORGANISM" "hgu95av2ORGPKG" "hgu95av2PATH"
[28] "hgu95av2PATH2PROBE" "hgu95av2PFAM" "hgu95av2PMID"
[31] "hgu95av2PMID2PROBE" "hgu95av2PROSITE" "hgu95av2REFSEQ"
[34] "hgu95av2SYMBOL" "hgu95av2UNIGENE" "hgu95av2UNIPROT"
但是用这个包自带的函数capture.output(hgu95av2())可以看到这些映射并没有囊括我们标准的hg19版本的2.3万个基因,也就说这个芯片设计的探针只有1.1万个左右。但它根据已有的org.Hs.eg.db来构建了它自己芯片独有的数据包,这样就显得更加正式规范化了,这启发我们研发人员在做一些市场产品的同时也可以把自己的研究成果通主流数据库数据形式结合起来,更易让他人接受。
> capture.output(hgu95av2())
[1] "Quality control information for hgu95av2:"
[2] ""
[3] ""
[4] "This package has the following mappings:"
[5] ""
[6] "hgu95av2ACCNUM has 12625 mapped keys (of 12625 keys)"
[7] "hgu95av2ALIAS2PROBE has 33755 mapped keys (of 103735 keys)"
[8] "hgu95av2CHR has 11540 mapped keys (of 12625 keys)"
[9] "hgu95av2CHRLENGTHS has 93 mapped keys (of 93 keys)"
[10] "hgu95av2CHRLOC has 11474 mapped keys (of 12625 keys)"
[11] "hgu95av2CHRLOCEND has 11474 mapped keys (of 12625 keys)"
[12] "hgu95av2ENSEMBL has 11460 mapped keys (of 12625 keys)"
[13] "hgu95av2ENSEMBL2PROBE has 9814 mapped keys (of 28553 keys)"
[14] "hgu95av2ENTREZID has 11543 mapped keys (of 12625 keys)"
[15] "hgu95av2ENZYME has 2125 mapped keys (of 12625 keys)"
[16] "hgu95av2ENZYME2PROBE has 786 mapped keys (of 975 keys)"
[17] "hgu95av2GENENAME has 11543 mapped keys (of 12625 keys)"
[18] "hgu95av2GO has 11245 mapped keys (of 12625 keys)"
[19] "hgu95av2GO2ALLPROBES has 17214 mapped keys (of 18826 keys)"
[20] "hgu95av2GO2PROBE has 12920 mapped keys (of 14714 keys)"
[21] "hgu95av2MAP has 11519 mapped keys (of 12625 keys)"
[22] "hgu95av2OMIM has 10541 mapped keys (of 12625 keys)"
[23] "hgu95av2PATH has 5374 mapped keys (of 12625 keys)"
[24] "hgu95av2PATH2PROBE has 228 mapped keys (of 229 keys)"
[25] "hgu95av2PMID has 11529 mapped keys (of 12625 keys)"
[26] "hgu95av2PMID2PROBE has 372382 mapped keys (of 432400 keys)"
[27] "hgu95av2REFSEQ has 11506 mapped keys (of 12625 keys)"
[28] "hgu95av2SYMBOL has 11543 mapped keys (of 12625 keys)"
[29] "hgu95av2UNIGENE has 11533 mapped keys (of 12625 keys)"
[30] "hgu95av2UNIPROT has 11315 mapped keys (of 12625 keys)"
[31] ""
[32] ""
[33] "Additional Information about this package:"
[34] ""
[35] "DB schema: HUMANCHIP_DB"
[36] "DB schema version: 2.1"
[37] "Organism: Homo sapiens"
[38] "Date for NCBI data: 2014-Sep19"
[39] "Date for GO data: 20140913"
[40] "Date for KEGG data: 2011-Mar15"
[41] "Date for Golden Path data: 2010-Mar22"
[42] "Date for Ensembl data: 2014-Aug6"
这个hgu95av2.db所加载的36个包都是一种特殊的对象,但是可以把它当做list来操作,是一种类似于hash的对应表格,其中keys是独特的,但是value可以有多个。
既然是类似于list,那我就简单讲几个小技巧来操作这些数据对象。所有的操作都要用as.list()函数来把数据展现出来
> as.list(hgu95av2ENZYME[1])
$`1000_at`
[1] "2.7.11.24"
可以看到这样就提取出来了hgu95av2ENZYME的第一个元素,key是`1000_at`,它所映射的value是 "2.7.11.24"这个酶。
同理对list取元素的三个操作在这里都可以用
> as.list(hgu95av2ENZYME['1000_at'])
$`1000_at`
[1] "2.7.11.24"
> as.list(hgu95av2ENZYME$'1000_at')
[[1]]
[1] "2.7.11.24"
然而这只是list的操作,我们还有一个函数专门对这个对象来取元素,那就是get函数,取多个元素用mget,类似于as.list(hgu95av2ENZYME[1:10])
用函数mget(probes_id,hgu95av2ENZYME)就可以根据自己的probes_id这个向量来选取数据了,当然也要用as.list()来展示出来。
值得一提的是这里有个非常重要的函数是revmap,可以把我们的key和value调换位置。
因为我们的数据对象里面的对应关系不是一对一,而是一对多,例如一个基因往往有多个go通路信息,例如这个就有十几个
as.list(hgu95av2GO$'1000_at')
$`GO:0000165`
$`GO:0000165`$GOID
[1] "GO:0000165"
$`GO:0000165`$Evidence
[1] "TAS"
$`GO:0000165`$Ontology
[1] "BP"
$`GO:0000186`
$`GO:0000186`$GOID
[1] "GO:0000186"
$`GO:0000186`$Evidence
[1] "TAS"
$`GO:0000186`$Ontology
[1] "BP"
一层层的数据结构非常清晰,但是数据太多,所以它给了一个toTable函数来格式化,就是把一对多的list压缩成表格。
> toTable(hgu95av2GO[1])
probe_id go_id Evidence Ontology
1 1000_at GO:0000165 TAS BP
2 1000_at GO:0000186 TAS BP
3 1000_at GO:0000187 TAS BP
4 1000_at GO:0002224 TAS BP
5 1000_at GO:0002755 TAS BP
6 1000_at GO:0002756 TAS BP
7 1000_at GO:0006360 TAS BP
------------------------------------------------------------
81 1000_at GO:0004707 NAS MF
82 1000_at GO:0001784 IEA MF
83 1000_at GO:0005524 IEA MF
这样就非常方便的查看啦。
当然对这个数据对象还有很多实用的操作。length(),Llength(),Rlength(),keys(),Lkeys(),Rkeys()等等,还有count.mappedkeys(),mappedLkeys(),还有个比较特殊的isNA来判断是否有些keys探针没有对应任何信息。
而且以上这些函数不仅可以用来获取数据对象的信息,还可以修改这个数据对象。
Lkeys(hgu95av2CHR) 可以查看这个对象有12625个探针。
而> Rkeys(hgu95av2CHR)
[1] “19” “12” “8” “14” “3” “2” “17” “16” “9” “X” “6” “1” “7” “10” “11”
[16] “22” “5” “18” “15” “Y” “20” “21” “4” “13” “MT” “Un”
可以看到这些探针分布在不同的染色体上面,如果我这时候给
x=hgu95av2CHR
Rkeys(x) = c(“1”,“2”)
toTable(x)可以看到这时候x只剩下1946个探针了,就是1,2号染色体上面的基因了。
然后可以一个个看这些函数的用法,其实就是SQL的增删改查的基本操作而已。
> length(x)
[1] 12625
> Llength(x)
[1] 12625
> Rlength(x)
[1] 2
> head(keys(x))
[1] "1000_at" "1001_at" "1002_f_at" "1003_s_at" "1004_at" "1005_at"
> head(Lkeys(x))
[1] "1000_at" "1001_at" "1002_f_at" "1003_s_at" "1004_at" "1005_at"
> head(Rkeys(x))
[1] "1" "2"
> count
count.fields count.mappedLkeys countOverlaps counts<- count.links count.mappedRkeys countQueryHits countSubjectHits count.mappedkeys countMatches counts > count.mappedkeys(x)
[1] 1946
> count.mappedLkeys(x)
[1] 1946
> count.mappedRkeys(x)
[1] 2
5. 理解 head(toTable(hgu95av2SYMBOL)) 的用法,找到 TP53 基因对应的探针ID
# 提供标识符和基因缩写之间的映射(probe_id和symbol的对应关系)
?hgu95av2SYMBOL
# toTable()是S4的一个泛型函数,可以替代as.data.frame()
?toTable
# Lkeys;探针总数是12625,能匹配上的是11683个;
# Rkeys:基因名的总数是62044,实际上只有8776种
# 原因:一般多个探针对应一个基因,取最大表达值探针来作为基因的表达量
summary(hgu95av2SYMBOL)
ids <- toTable(hgu95av2SYMBOL)
# head(ids)
# 正则表达式:https://www.runoob.com/regexp/regexp-syntax.html
ids[grep("^TP53$", ids$symbol),]
# 也可以直接打开ids,在搜索框中搜索TP53(同R语言小作业-中级-第3题)
ids <- toTable(hgu95av2SYMBOL)
head(ids)
# 找到 TP53 基因对应的探针ID,也可直接去数据框搜
ID <- ids[ids$symbol%in%"TP53",][,1]
# 保存下数据,方便下次继续,避免从头开始。
save(ids,exprSet,pdata,file = 'input.Rdata')
?hgu95av2SYMBOL
?toTable
summary(hgu95av2SYMBOL)
#SYMBOL map for chip hgu95av2 (object of class "ProbeAnnDbBimap")
|
| Lkeyname: probe_id (Ltablename: probes)
| Lkeys: "1000_at", "1001_at", ... (total=12625/mapped=11460)
|
| Rkeyname: symbol (Rtablename: gene_info)
| Rkeys: "A1BG", "A2M", ... (total=61050/mapped=8585)
|
| direction: L --> R
ids <- toTable(hgu95av2SYMBOL)
View(ids)
library(dplyr)
# 方法1:
filter(ids, symbol=="TP53") #用dplyr包的筛选功能,找到 TP53 基因对应的探针ID
# probe_id symbol
#1 1939_at TP53
#2 1974_s_at TP53
#3 31618_at TP53
#方法2:
ids[grep("^TP53$", ids$symbol),]
# probe_id symbol
# 966 1939_at TP53
# 997 1974_s_at TP53
# 1420 31618_at TP53
#方法1,2虽然结果相同,但是定义的对象是不同的
hug95av2SYMBOL是一个R对象,它提供的是芯片生产厂家与基因缩写之间的映射信息。这个映射的信息主要依据Entrez Gene数据库。现在我们通过mappedkeys()这个函数,得到映射到基因上的探针信息。
6.理解探针与基因的对应关系,总共多少个基因,基因最多对应多少个探针,是哪些基因,是不是因为这些基因很长,所以在其上面设计多个探针呢?
# dim一下,发现11460行,2列
dim(ids)
# unique可见,总共8585个基因
length(unique(ids$symbol))
# 给多个基因排序,显示最靠后的6个,同样可以n=10
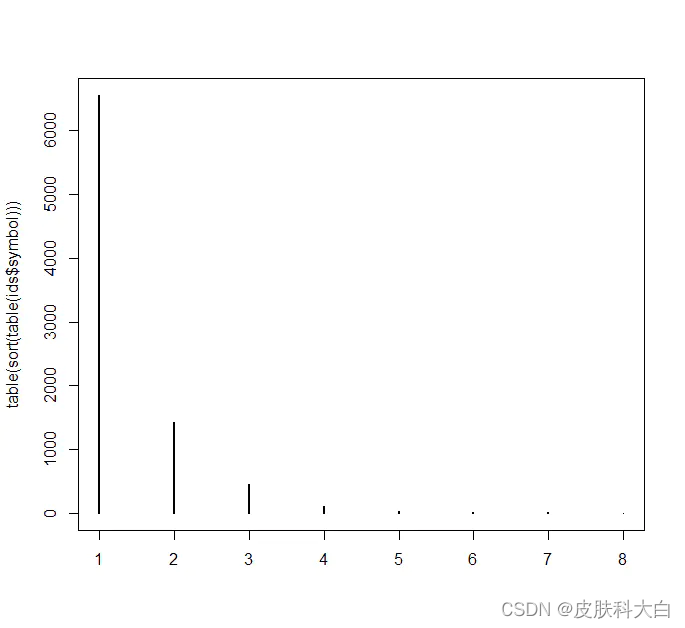
tail(sort(table(ids$symbol)))
# 查看各出现频数的分布,其中6555个基因只出现了一次
table(sort(table(ids$symbol)))
# 可视化
plot(table(sort(table(ids$symbol))))
# 探针与基因是多对一的关系
# 对symbol去重然后查看长度,总共有8776个基因
length(unique(ids$symbol))
# 统计symbol中每个基因出现的次数,然后排序取其尾部
# 所得结果即可看出对应探针数目最多的基因
tail(sort(table(ids$symbol)))
# 统计对应不同探针数目的基因
table(sort(table(ids$symbol)))
# 因为基因长度远大于探针长度,所以一般一个基因对应多个探针
length(unique(ids$symbol))
# [1] 8585
tail(sort(table(ids$symbol)))
#YME1L1 GAPDH INPP4A MYB PTGER3 STAT1
# 7 8 8 8 8 8
table(sort(table(ids$symbol)))
# 1 2 3 4 5 6 7 8
# 6555 1428 451 102 22 16 6 5
7.第二步提取到的表达矩阵是12625个探针在22个样本的表达量矩阵,找到那些不在 hgu95av2.db 包收录的对应着SYMBOL的探针。 提示:有1165个探针是没有对应基因名字的。
%in% 逻辑判断
用法 a %in% table
a值是否包含于table中,为真输出TURE,否者输出FALSE
# 查看多少%in%,多少!%in%,即分布。可知,11460个TRUE,1165个FALSE
table(rownames(exprSet) %in% ids$probe_id)
dim(exprSet)
# 统计exprSet中的探针在ids中的存在情况
# FALSE表示不存在,反之亦然
# 在这里为942,而不是1165,怀疑是因为包更新了...
table(rownames(exprSet) %in% ids$probe_id)
# 将exprSet中与ids中不对应的探针提取出来
# %in%是一个二元操作符,返回其左操作数长度的逻辑向量,指示其中的元素是否匹配
new_exprSet <- exprSet[!(rownames(exprSet) %in% ids$probe_id),]
dim(new_exprSet)
8.过滤表达矩阵,删除那1165个没有对应基因名字的探针。
方法1:%in% 逻辑判断
exprSet <- exprSet[rownames(exprSet) %in% ids$probe_id, ]
dim(exprSet)
[1] 11460 22
View(exprSet)
# These probes are in the package.
方法2 mappedkeys() 映射关系
length(hgu95av2SYMBOL)
[1] 12625
probe_map <- hgu95av2SYMBOL
length(probe_map)
[1] 12625
#全部的探针数目
# [1] 12625
probe_info <- mappedkeys(probe_map)
length(probe_info)
[1] 11460
#探针与基因产生映射的数目
gene_info <- as.list(probe_map[probe_info])
# 转化为数据表
length(gene_info)
[1] 11460
gene_symbol <- toTable(probe_map[probe_info])
# 从hgu95av2SYMBOL文件中,取出有映射关系的探针,并生成数据框给gene_symbol
head(gene_symbol)
probe_id symbol
1 1000_at MAPK3
2 1001_at TIE1
3 1002_f_at CYP2C19
4 1003_s_at CXCR5
5 1004_at CXCR5
6 1005_at DUSP1
mappedkeys用法示例,帮助理解。
library(hgu95av2.db)
x <- hgu95av2GO
x
length(x)
count.mappedkeys(x)
x[1:3]
links(x[1:3])
## Keep only the mapped keys
keys(x) <- mappedkeys(x)
length(x)
count.mappedkeys(x)
x # now it is a submap
## The above subsetting can also be achieved with
x <- hgu95av2GO[mappedkeys(hgu95av2GO)]
## mappedkeys() and count.mappedkeys() also work with an environment
## or a list
z <- list(k1=NA, k2=letters[1:4], k3="x")
mappedkeys(z)
count.mappedkeys(z)
## retrieve the set of primary keys for the ChipDb object named 'hgu95av2.db'
keys <- keys(hgu95av2.db)
head(keys)
# 将上一题的取反(!)删除即可
exprSet <- exprSet[(rownames(exprSet) %in% ids$probe_id), ]
dim(exprSet)
9.整合表达矩阵,多个探针对应一个基因的情况下,只保留在所有样本里面平均表达量最大的那个探针。
提示,理解 tapply,by,aggregate,split 函数 , 首先对每个基因找到最大表达量的探针。
然后根据得到探针去过滤原始表达矩阵
by(data, INDICES, FUN, …, simplify = TRUE)函数用于将data中的数据,按照INDICES里面的内容拆分成若干个小的data frame,并且在每一小块data frame上应用FUN函数。
match返回其第一个参数在第二个参数中的(第一个)匹配位置的向量
ids=ids[match(rownames(exprSet),ids$probe_id),]
head(ids)
exprSet[1:5,1:5]
if(F){
# 定义最大平均表达量的...
tmp = by(exprSet,ids$symbol,
function(x) rownames(x)[which.max(rowMeans(x))] )
probes = as.character(tmp)
dim(exprSet)
#筛选表达矩阵
exprSet=exprSet[rownames(exprSet) %in% probes ,]
# 看下筛选之后行情况,8585
dim(exprSet)
# 表达矩阵探针换为基因名
rownames(exprSet)=ids[match(rownames(exprSet),ids$probe_id),2]
exprSet[1:5,1:5]
}
# 将ids中与exprSet不对应的探针删去
# match返回其第一个参数在第二个参数中的(第一个)匹配位置的向量
ids <- ids[match(rownames(exprSet),ids$probe_id),]
dim(ids)
# match(rownames(exprSet),ids$probe_id)
# head(ids)
# exprSet[1:5,1:5]
# 数据帧被行分割成由一个或多个因子的值子集的数据帧,函数FUN依次应用于每个子集
# 首先根据ids中的symbol,在exprSet中进行匹配,找到对应的行,计算平均表达量
# 挑出平均表达量最大的那一行,将其探针名保留
tmp <- by(exprSet,ids$symbol,function(x) rownames(x)[which.max(rowMeans(x))])
tmp[1:20]
# 将tmp转为字符型
probes <- as.character(tmp)
# 保留在所有样本里面平均表达量最大的那个探针
exprSet <- exprSet[rownames(exprSet) %in% probes, ]
dim(exprSet)
dim(ids)
# 详细介绍一下by那一步
# 这里取ids中按symbol排序的前两个基因为例
# ids[,2]=='AADAC'会返回逻辑值,再与exprSet进行匹配
exprSet[ids[,2]=='AADAC',]
exprSet[ids[,2]=='AAK1',]
str(exprSet[ids[,2]=='AADAC',])
str(exprSet[ids[,2]=='AAK1',])
# 匹配AADAC时,因为只有对应一个探针,所以维度跟其他多对一的不同
# 在这里报错了,但是放在by中能运行,可能自动给添加了维度,这里不明白...
rowMeans(exprSet[ids[,2]=='AADAC',])
rowMeans(exprSet[ids[,2]=='AAK1',])
which.max(rowMeans(exprSet[ids[,2]=='AADAC',]))
which.max(rowMeans(exprSet[ids[,2]=='AAK1',]))
str(which.max(rowMeans(exprSet[ids[,2]=='AAK1',])))
rownames(exprSet[ids[,2]=='AAK1',])[which.max(rowMeans(exprSet[ids[,2]=='AAK1',]))]
# 这里其实最主要依据就是ids中的基因(symbol)与探针(probe_id)的对应关系
# 如果是一对多,则对多的探针求平均表达量,然后保留最大的那个
# 依次对所有基因进行操作即可
10.把过滤后的表达矩阵更改行名为基因的symbol,因为这个时候探针和基因是一对一关系了。见上
#把ids的symbol这一列中的每一行给dat作为dat的行名
rownames(dat)=ids$symbol
#保留每个基因ID第一次出现的信息
dat[1:4,1:4]
dim(dat)
# 注意此时exprSet和ids的行数还不同,需要把ids中多余的行去除
# 法一
ids <- ids[match(rownames(exprSet),ids$probe_id),]
dim(ids)
rownames(exprSet) <- ids$symbol
exprSet[1:5, 1:5]
# 法二,这个方法可以不用改变ids
rownames(exprSet) <- ids[match(rownames(exprSet),ids$probe_id),2]
rownames(exprSet)=ids[match(rownames(exprSet),ids$probe_id),2]
exprSet[1:5,1:5]
# CLL11.CEL CLL12.CEL CLL13.CEL CLL14.CEL CLL15.CEL
# MAPK3 5.743132 6.219412 5.523328 5.340477 5.229904
# TIE1 2.285143 2.291229 2.287986 2.295313 2.662170
# CYP2C19 3.309294 3.318466 3.354423 3.327130 3.365113
# CXCR5 1.085264 1.117288 1.084010 1.103217 1.074243
# CXCR5 7.544884 7.671801 7.474025 7.152482 6.902932
library(reshape2)
exprSet_L=melt(exprSet)
colnames(exprSet_L)=c('probe','sample','value')
exprSet_L$group=rep(group_list,each=nrow(exprSet))
head(exprSet_L)
# probe sample value group
#1 MAPK3 CLL11.CEL 5.743132 progres.
#2 TIE1 CLL11.CEL 2.285143 progres.
#3 CYP2C19 CLL11.CEL 3.309294 progres.
#4 CXCR5 CLL11.CEL 1.085264 progres.
#5 CXCR5 CLL11.CEL 7.544884 progres.
#6 DUSP1 CLL11.CEL 5.083793 progres.
View(head(exprSet))
11. 对第10步得到的表达矩阵进行探索,先画第一个样本的所有基因的表达量的boxplot,hist,density , 然后画所有样本的 这些图
参考:http://bio-info-trainee.com/tmp/basic_visualization_for_expression_matrix.html
理解ggplot2的绘图语法,数据和图形元素的映射关系
# 管道回来
exprSet=dat
#
exprSet['GAPDH',]
boxplot(exprSet[,1])
boxplot(exprSet['GAPDH',])
exprSet['ACTB',]
# 用reshape2包画
library(reshape2)
# 整理分组矩阵
exprSet_L=melt(exprSet)
colnames(exprSet_L)=c('probe','sample','value')
# 获得分组信息
group_list=as.character(pdata[,2])
exprSet_L$group=rep(group_list,each=nrow(exprSet))
head(exprSet_L)
### ggplot2画图
library(ggplot2)
p=ggplot(exprSet_L,
aes(x=sample,y=value,fill=group))+geom_boxplot()
print(p)
p=ggplot(exprSet_L,aes(x=sample,y=value,fill=group))+geom_violin()
print(p)
p=ggplot(exprSet_L,aes(value,fill=group))+geom_histogram(bins = 200)+facet_wrap(~sample, nrow = 4)
print(p)
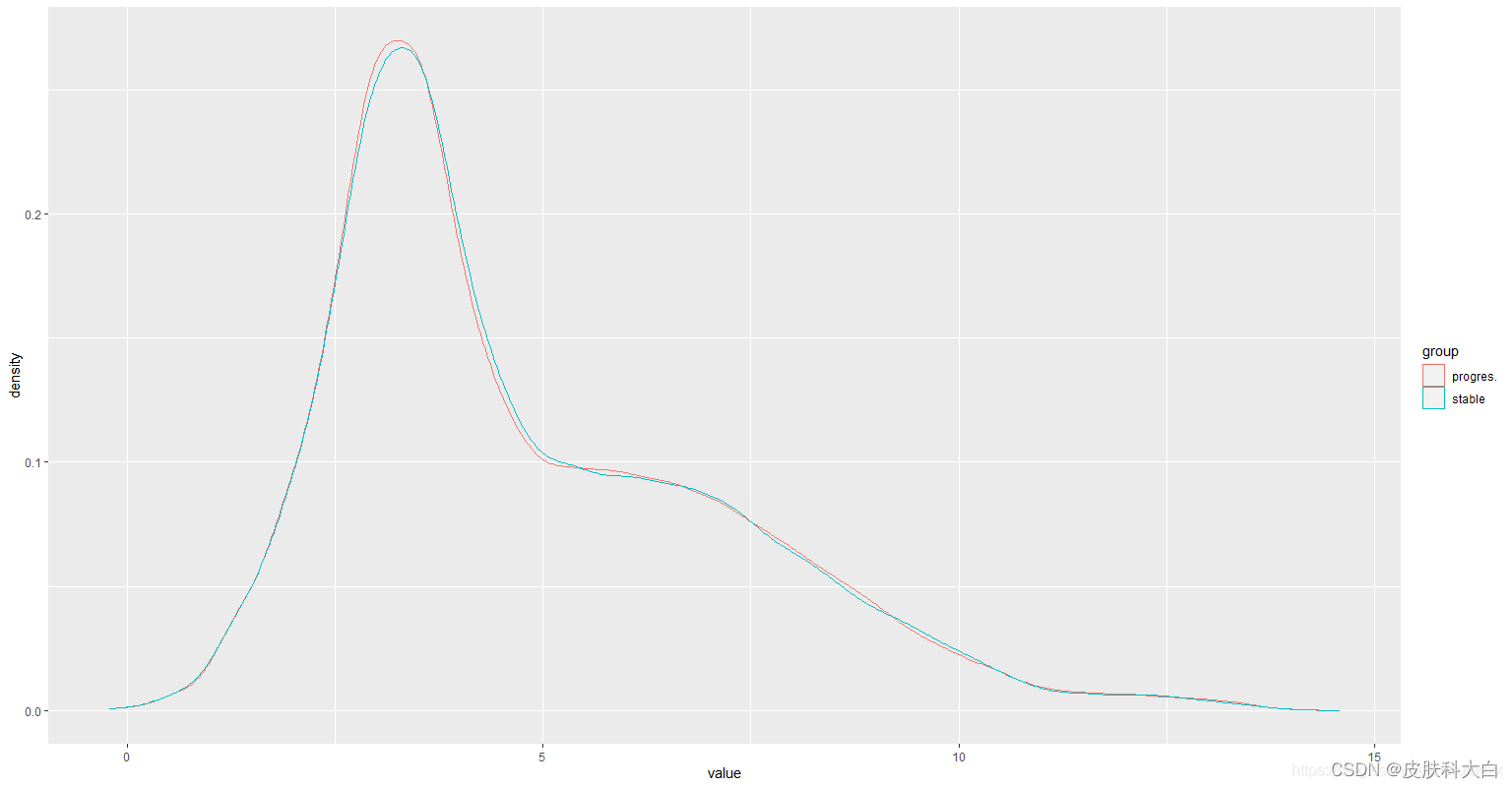
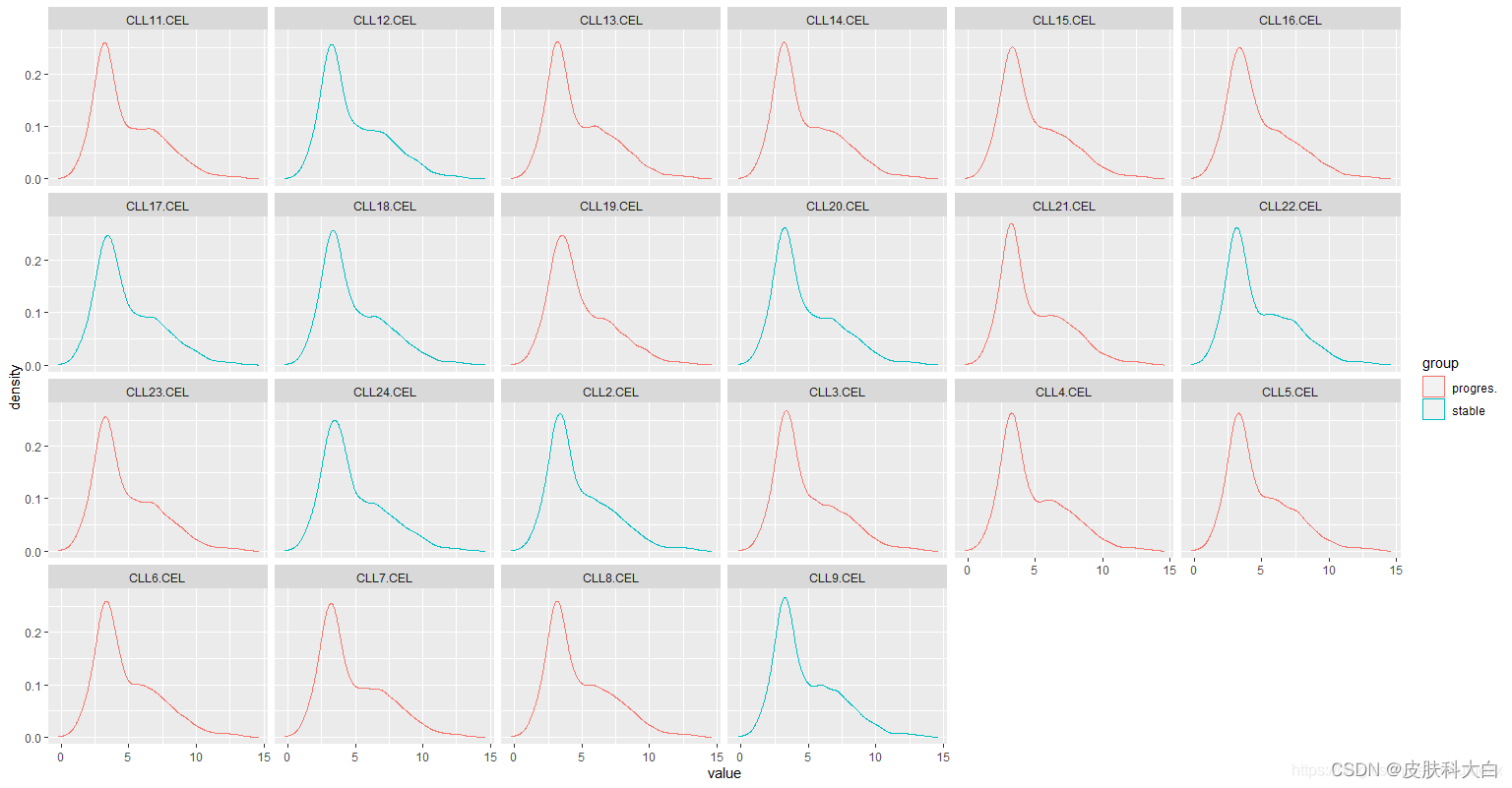
p=ggplot(exprSet_L,aes(value,col=group))+geom_density()+facet_wrap(~sample, nrow = 4)
print(p)
p=ggplot(exprSet_L,aes(value,col=group))+geom_density()
print(p)
p=ggplot(exprSet_L,aes(x=sample,y=value,fill=group))+geom_boxplot()
p=p+stat_summary(fun.y="mean",geom="point",shape=23,size=3,fill="red")
p=p+theme_set(theme_set(theme_bw(base_size=20)))
p=p+theme(text=element_text(face='bold'),axis.text.x=element_text(angle=30,hjust=1),axis.title=element_blank())
print(p)
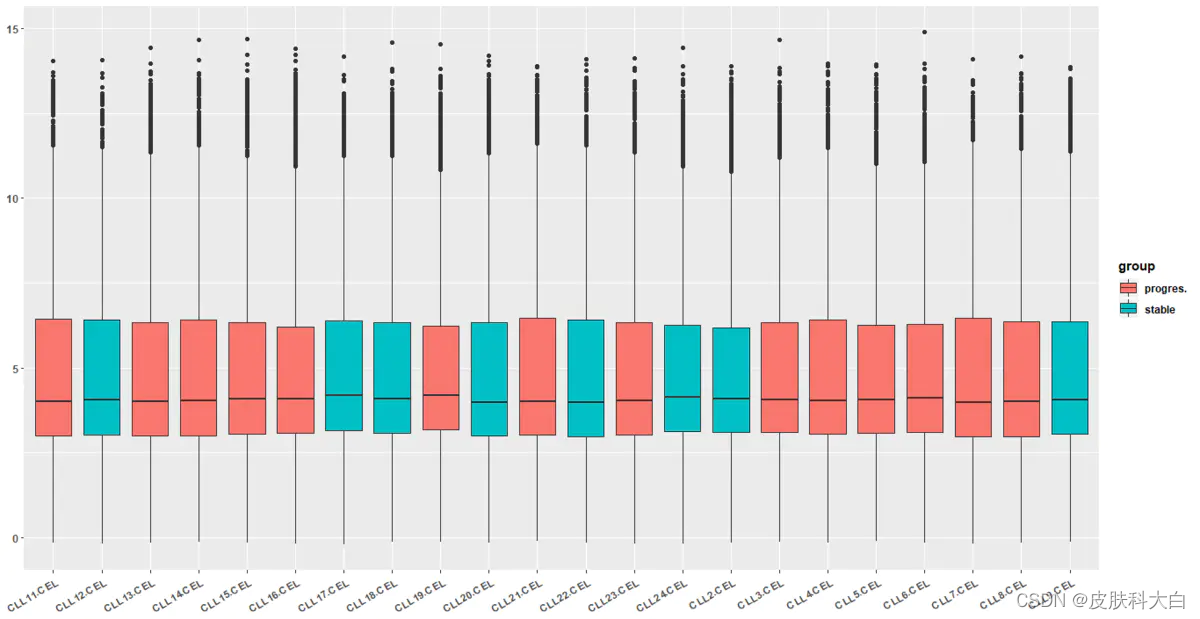
# 整理数据
library(reshape2)
m_exprSet <- melt(exprSet)
head(m_exprSet)
colnames(m_exprSet) <- c("symbol", "sample", "value")
head(m_exprSet)
m_exprSet$group <- rep(group_list, each = nrow(exprSet))
head(m_exprSet)
library(ggplot2)
# 单独画一个sample的图
ggplot(m_exprSet[m_exprSet[,2]=="CLL11.CEL", ], aes(x = sample, y = value, fill = group)) + geom_boxplot()
# 直接把所有sample都放在一起画
ggplot(m_exprSet, aes(x = sample, y = value, fill = group)) + geom_boxplot()
ggplot(m_exprSet, aes(x = sample, y = value, fill = group)) + geom_violin()
ggplot(m_exprSet, aes(x = value, fill = group)) + geom_histogram(bins = 200)
ggplot(m_exprSet, aes(x = value, fill = group)) + geom_histogram(bins = 200) + facet_wrap(vars(sample), nrow = 4)
ggplot(m_exprSet, aes(x = value, col = group)) + geom_density()
ggplot(m_exprSet, aes(x = value, col = group)) + geom_density() + facet_wrap(~sample, nrow = 4)
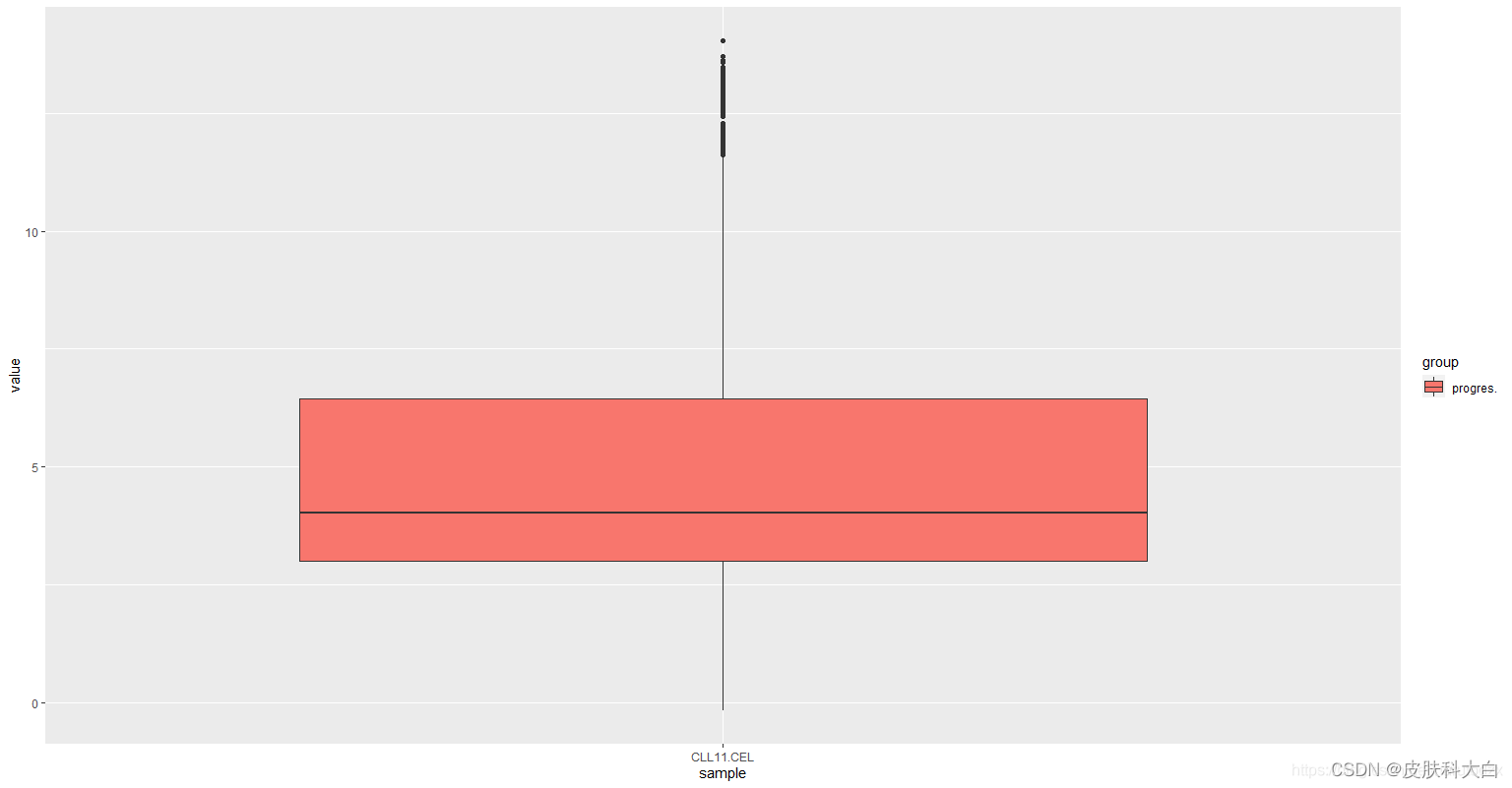
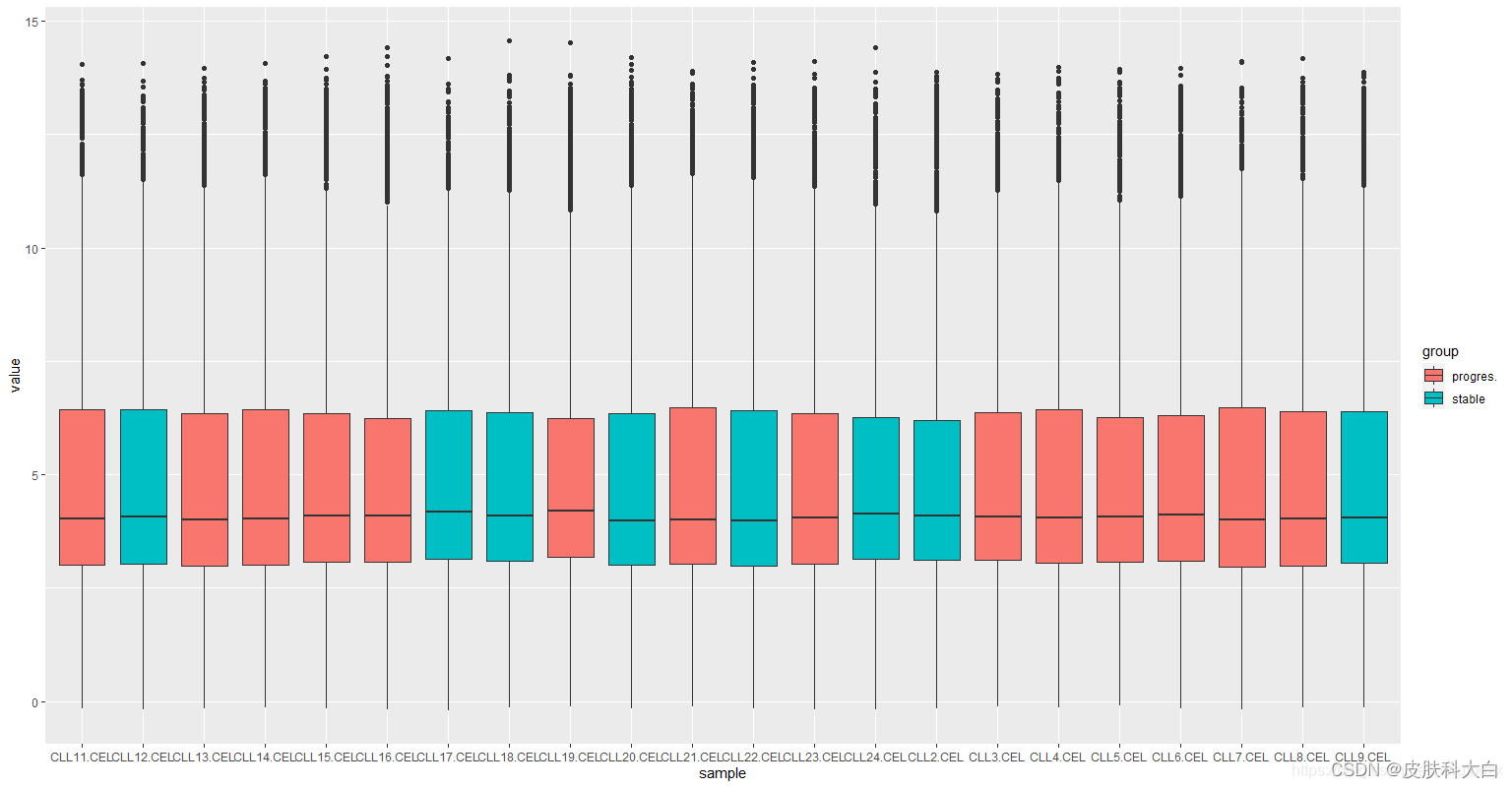
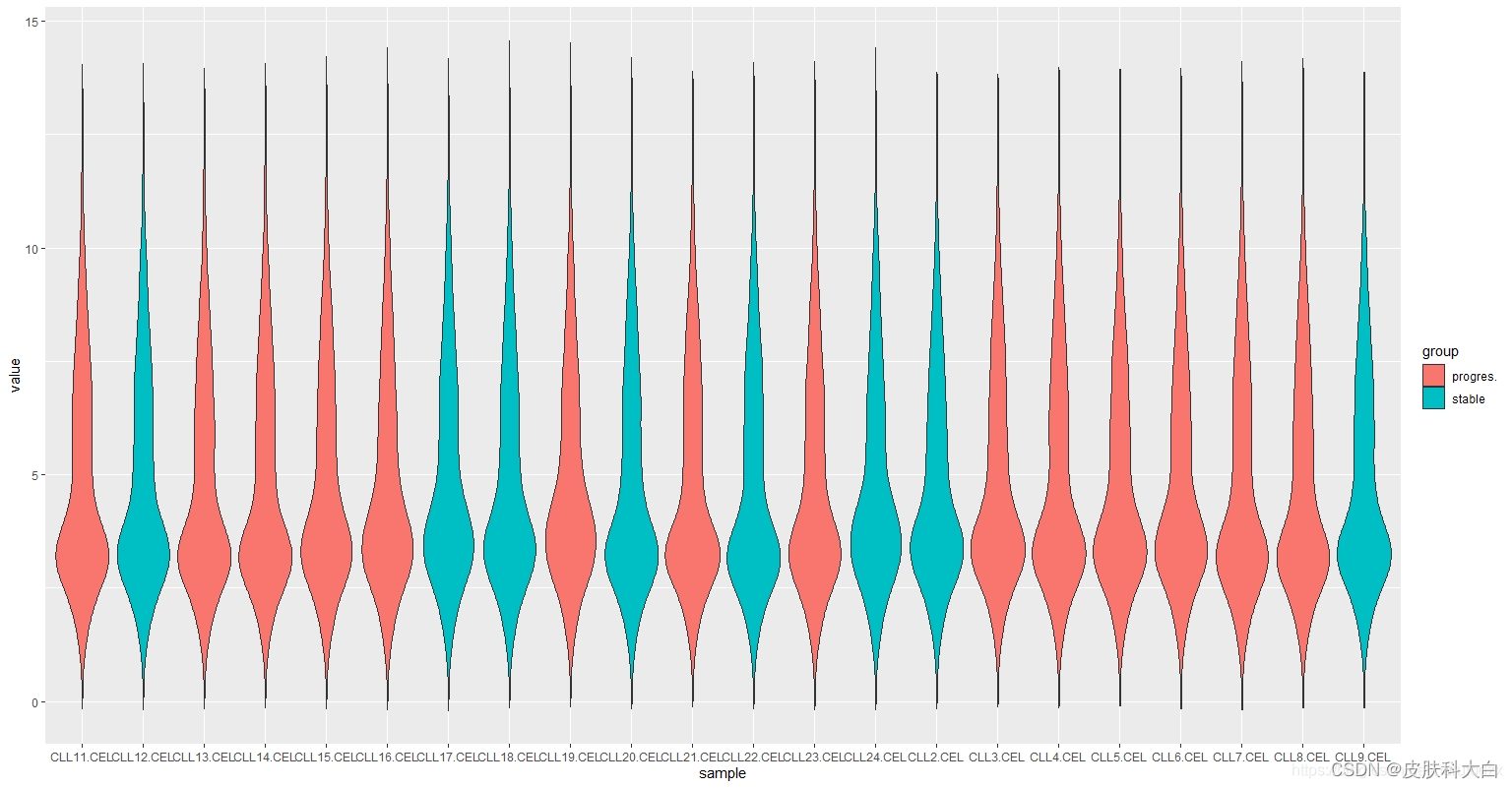
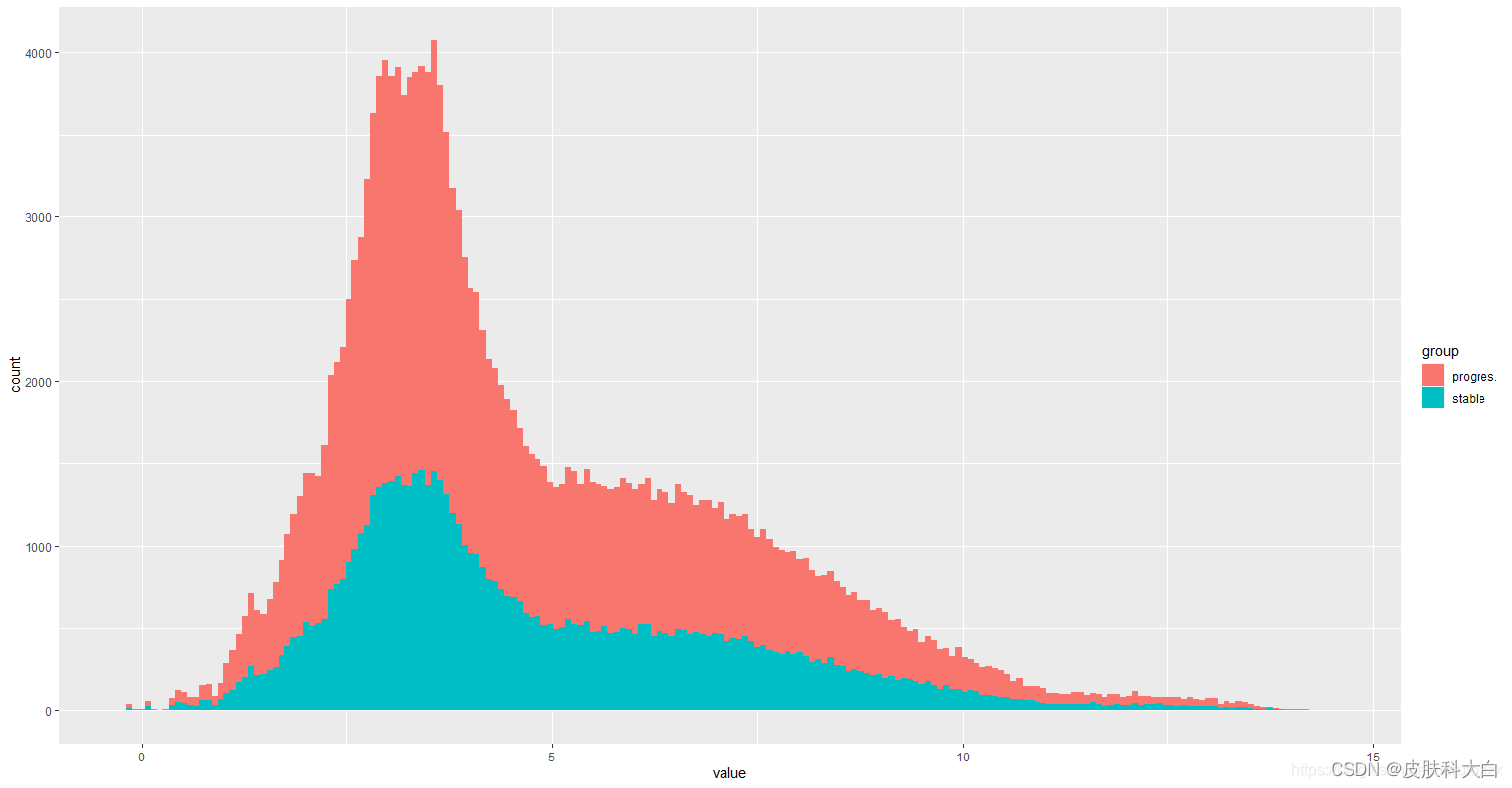
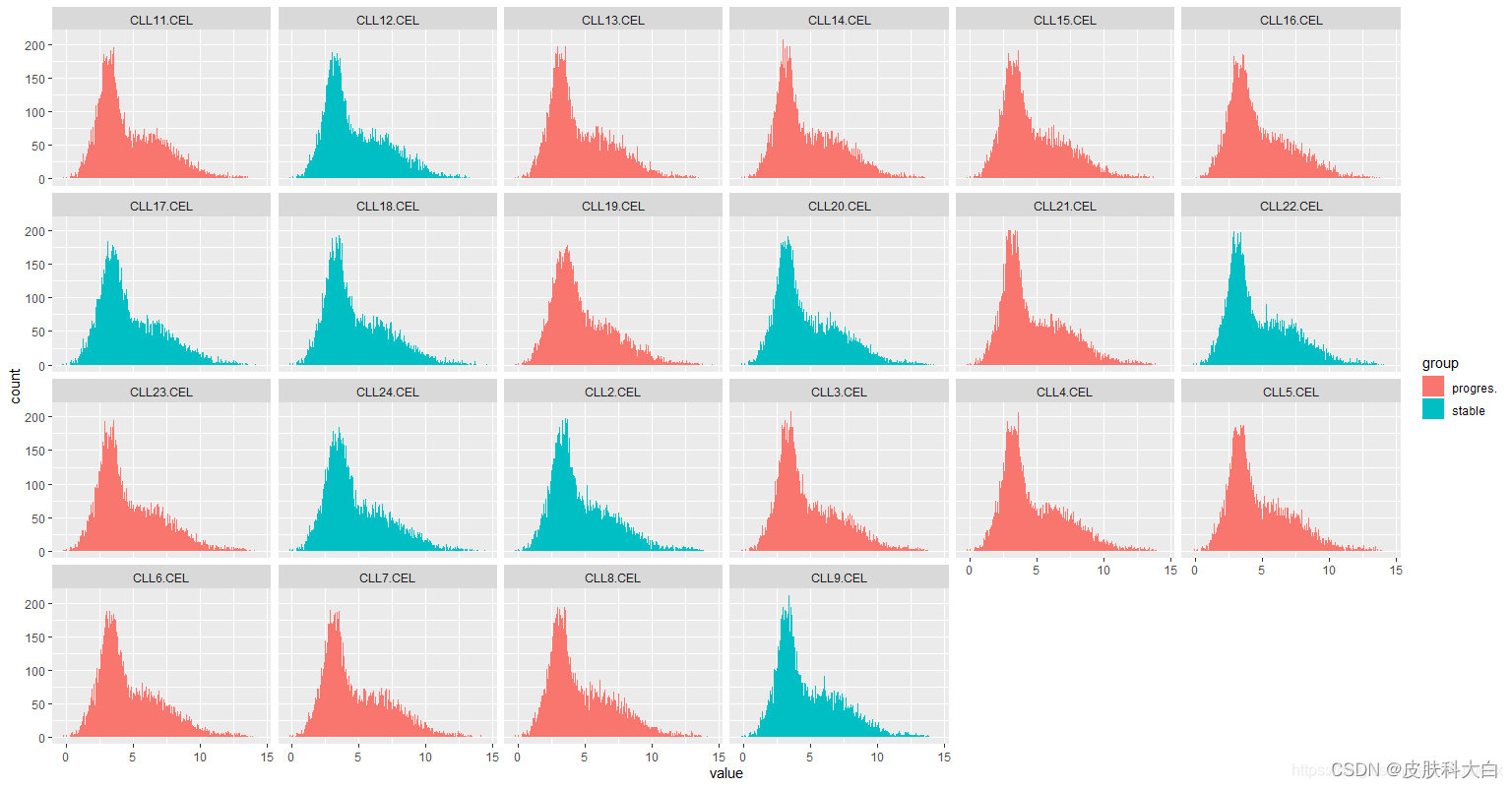
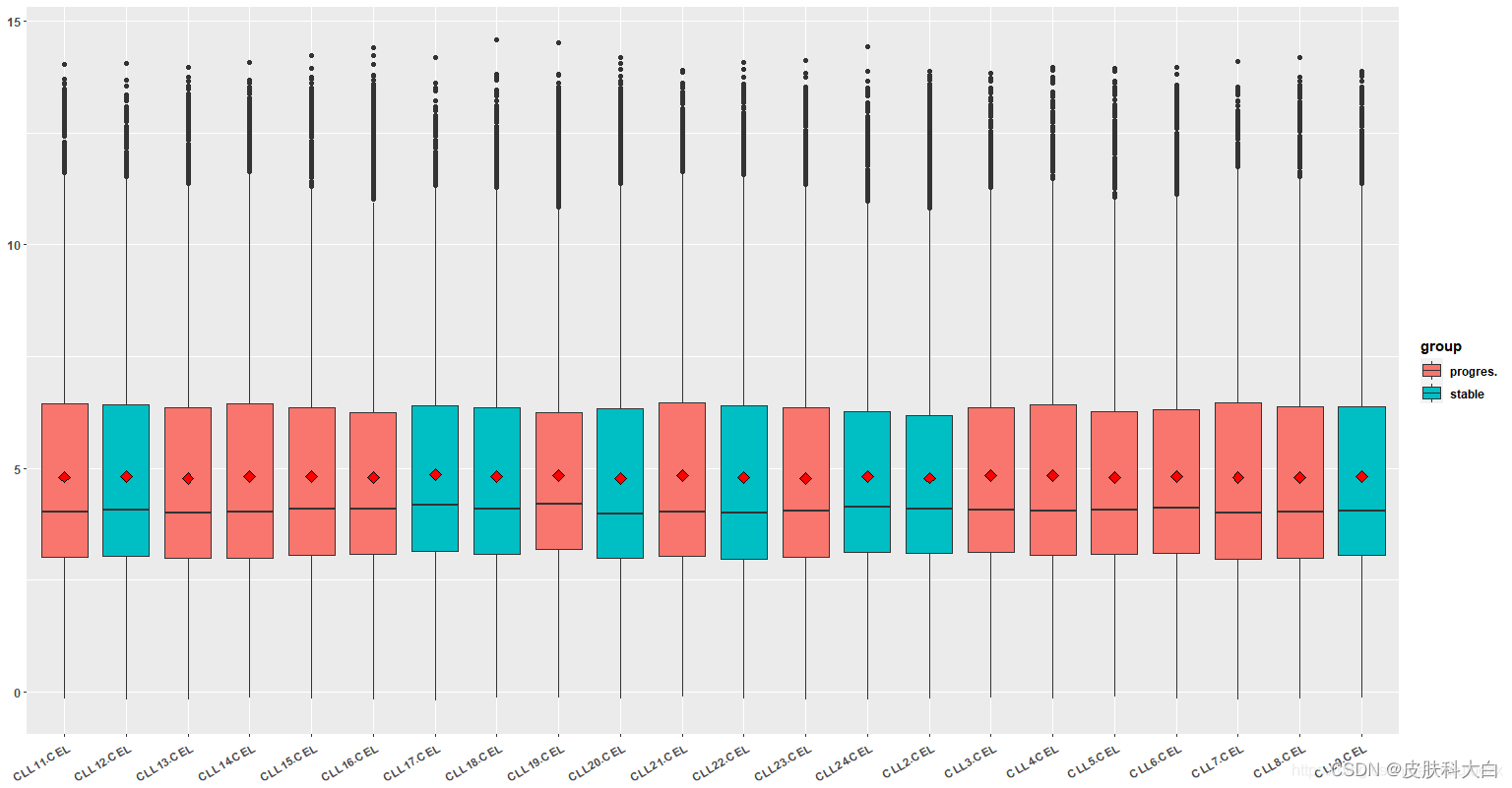
# 箱线图美化
p <- ggplot(m_exprSet, aes(x = sample, y = value, fill = group)) + geom_boxplot()
# 计算value的平均值,并以点的形式加入图中
# fun.y被抛弃了,现在流行快乐(手动狗头)
p <- p + stat_summary(fun="mean", geom="point", shape=23, size=3, fill="red")
# 加个经典的暗光ggplot2主题,虽然我没看出来有啥变化
p <- p + theme_set(theme_set(theme_bw(base_size=20)))
# 把字体设置为粗体,修改一下横坐标的显示,把标题置空
p <- p + theme(text=element_text(face='bold'), axis.text.x=element_text(angle=30,hjust=1), axis.title=element_blank())
print(p)
12.理解统计学指标mean,median,max,min,sd,var,mad并计算出每个基因在所有样本的这些统计学指标,最后按照mad值排序,取top 50 mad值的基因,得到列表。
g_mean <- tail(sort(apply(exprSet,1,mean)),50)
g_median <- tail(sort(apply(exprSet,1,median)),50)
g_max <- tail(sort(apply(exprSet,1,max)),50)
g_min <- tail(sort(apply(exprSet,1,min)),50)
g_sd <- tail(sort(apply(exprSet,1,sd)),50)
g_var <- tail(sort(apply(exprSet,1,var)),50)
g_mad <- tail(sort(apply(exprSet,1,mad)),50)
g_mad
names(g_mad)
[1] "DUSP5" "IGFBP4" "H1FX" "ENPP2" "FLNA" "CLEC2B" "TSPYL2" "ZNF266" "S100A9" "NR4A2" "TGFBI" "ARF6" "APBB2" "VCAN" "RBM38"
[16] "CAPG" "PLXNC1" "RGS2" "RNASE6" "VAMP5" "CYBB" "GNLY" "CCL3" "OAS1" "ENPP2" "TRIB2" "ZNF804A" "H1FX" "IGH" "JUND"
[31] "SLC25A1" "PCDH9" "VIPR1" "COBLL1" "GUSBP11" "S100A8" "HBB" "FOS" "LHFPL2" "FCN1" "ZAP70" "IGLC1" "LGALS1" "HBB" "FOS"
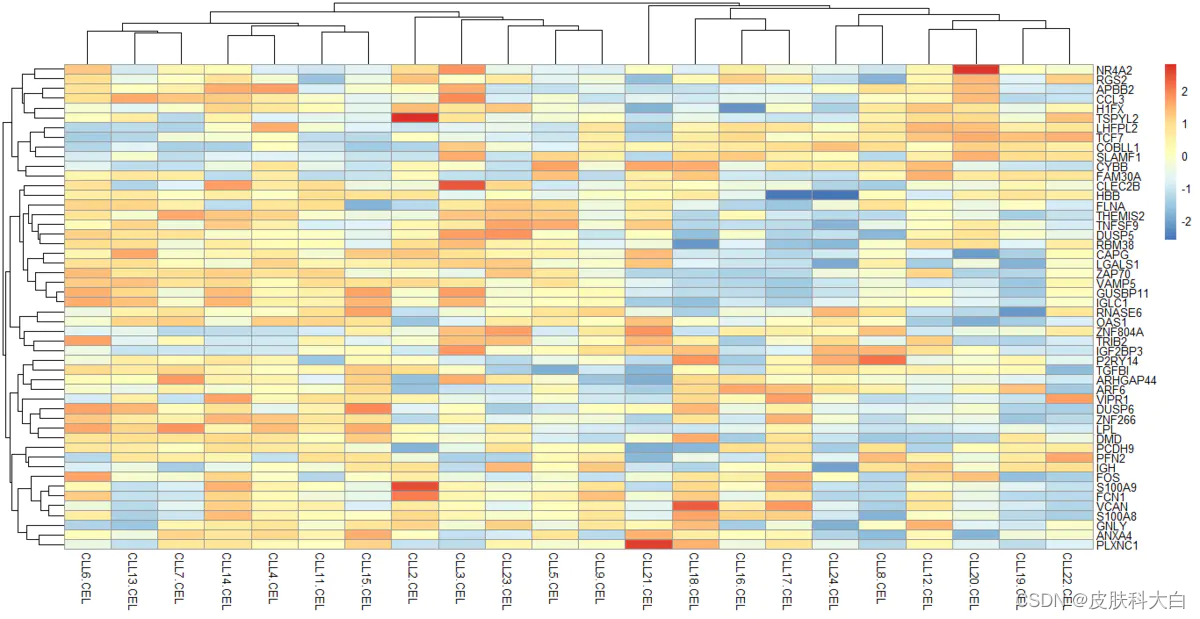
[46] "SLAMF1" "TCF7" "DMD" "IGF2BP3" "FAM30A"

13.根据第12步骤得到top 50 mad值的基因列表来取表达矩阵的子集,并且热图可视化子表达矩阵。试试看其它5种热图的包的不同效果
# 热一下试试
library(pheatmap)
choose_gene=names(tail(sort(apply(exprSet,1,mad)),50))
choose_matrix=exprSet[choose_gene,]
choose_matrix=t(scale(t(choose_matrix)))
pheatmap(choose_matrix)
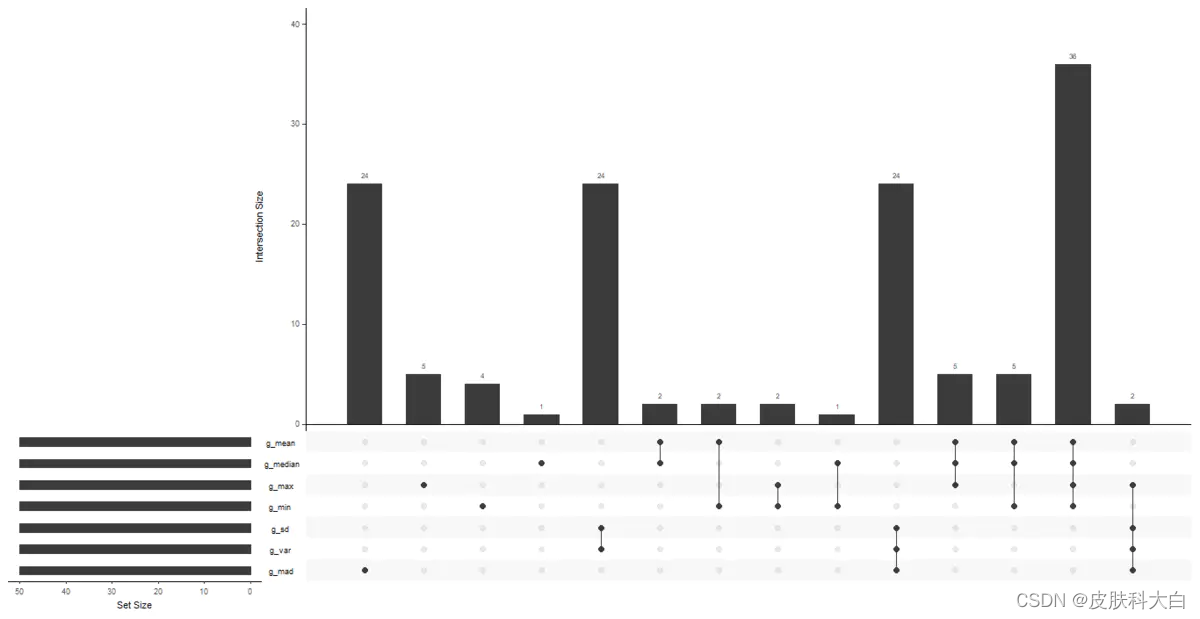
14.取不同统计学指标mean,median,max,mean,sd,var,mad的各top50基因列表,使用UpSetR包来看他们之间的overlap情况。
## UpSetR
# 看下说明书 https://cran.r-project.org/web/packages/UpSetR/README.html
library(UpSetR)
g_all <- unique(c(names(g_mean),names(g_median),names(g_max),names(g_min),
names(g_sd),names(g_var),names(g_mad) ))
dat=data.frame(g_all=g_all,
g_mean=ifelse(g_all %in% names(g_mean) ,1,0),
g_median=ifelse(g_all %in% names(g_median) ,1,0),
g_max=ifelse(g_all %in% names(g_max) ,1,0),
g_min=ifelse(g_all %in% names(g_min) ,1,0),
g_sd=ifelse(g_all %in% names(g_sd) ,1,0),
g_var=ifelse(g_all %in% names(g_var) ,1,0),
g_mad=ifelse(g_all %in% names(g_mad) ,1,0)
)
upset(dat,nsets = 7)
15.在第二步的基础上面提取CLL包里面的data(sCLLex) 数据对象的样本的表型数据。
pdata=pData(sCLLex)
group_list=as.character(pdata[,2])
group_list
dim(exprSet)
exprSet[1:5,1:5]
pdata=pData(sCLLex)
group_list=as.character(pdata[,2])
group_list
# [1] "progres." "stable" "progres." "progres." "progres." "progres." "stable" "stable" "progres." "stable" "progres." "stable" "progres." "stable"
# [15] "stable" "progres." "progres." "progres." "progres." "progres." "progres." "stable"
dim(exprSet)
# [1] 8585 22
exprSet[1:5,1:5]
# CLL11.CEL CLL12.CEL CLL13.CEL CLL14.CEL CLL15.CEL
MAPK3 5.743132 6.219412 5.523328 5.340477 5.229904
TIE1 2.285143 2.291229 2.287986 2.295313 2.662170
CYP2C19 3.309294 3.318466 3.354423 3.327130 3.365113
CXCR5 7.544884 7.671801 7.474025 7.152482 6.902932
DUSP1 5.083793 7.610593 7.631311 6.518594 5.059087
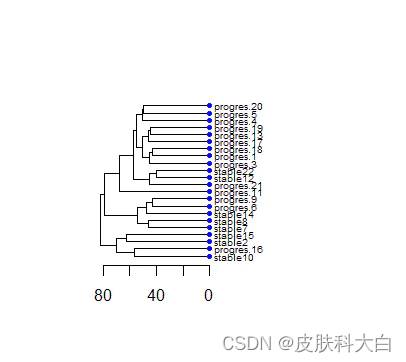
16.对所有样本的表达矩阵进行聚类并且绘图,然后添加样本的临床表型数据信息(更改样本名)
## hclust
# 更改表达矩阵列名
colnames(exprSet)=paste(group_list,1:22,sep='')
# 定义nodePar
nodePar <- list(lab.cex = 0.6, pch = c(NA, 19),
cex = 0.7, col = "blue")
# 聚类
hc=hclust(dist(t(exprSet)))
par(mar=c(5,5,5,10))
# 绘图
plot(as.dendrogram(hc), nodePar = nodePar, horiz = TRUE)
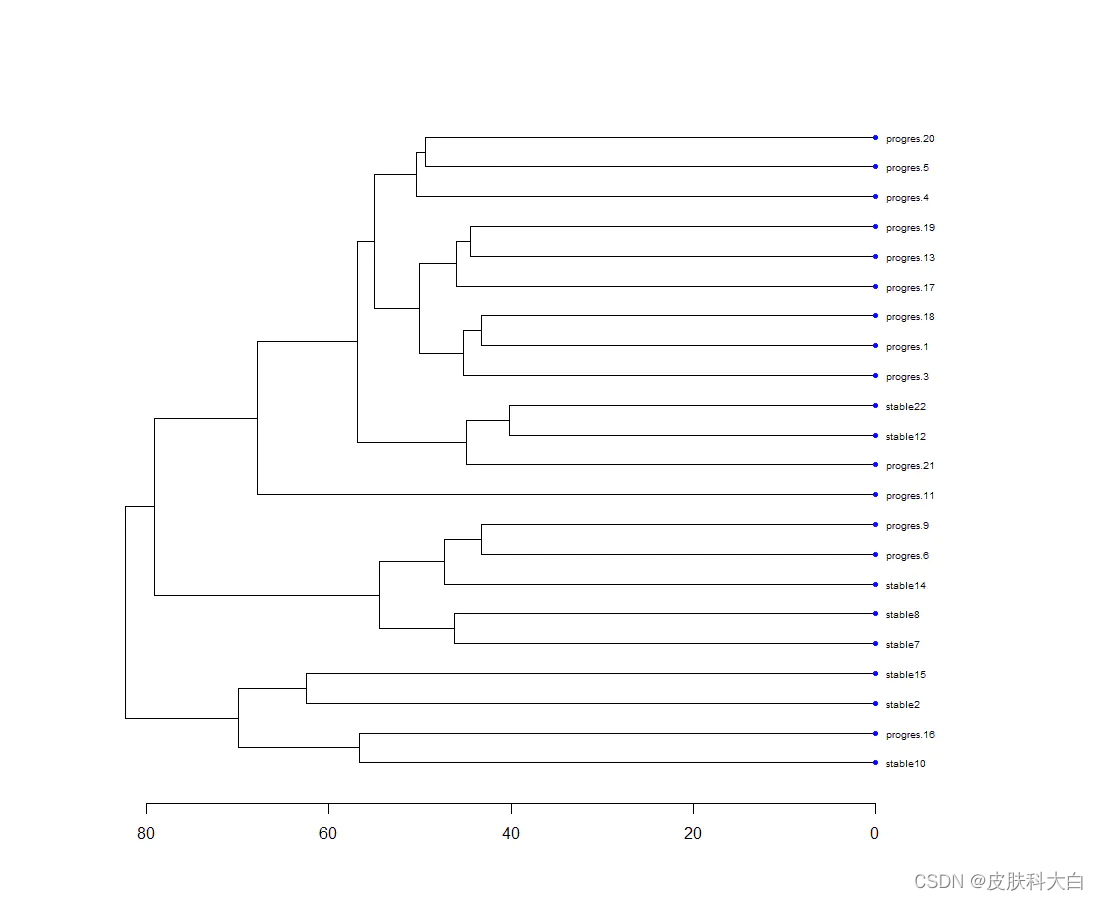
## hclust
colnames(exprSet)=paste(group_list,1:22,sep='')
# Define nodePar
nodePar <- list(lab.cex = 0.6, pch = c(NA, 19),
cex = 0.7, col = "blue")
hc=hclust(dist(t(exprSet)))
par(mar=c(5,5,5,10))
plot(as.dendrogram(hc), nodePar = nodePar, horiz = TRUE)
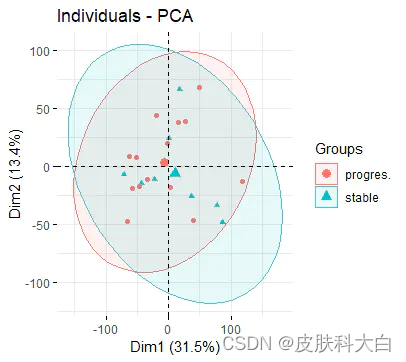
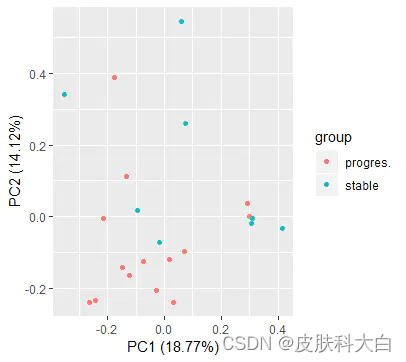
17.对所有样本的表达矩阵进行PCA分析并且绘图,同样要添加表型信息。
library(ggfortify)
# 互换行和列,dim一下
df=as.data.frame(t(exprSet))
dim(df)
# 不要view df,列太多,软件会崩掉;
df$group=group_list
autoplot(prcomp( df[,1:(ncol(df)-1)] ), data=df,colour = 'group')
#或者
#画主成分分析图需要加载这两个包
library("FactoMineR")
library("factoextra")
df=as.data.frame(t(exprSet))
dat.pca <- PCA(df, graph = FALSE)#现在dat最后一列是group_list,需要重新赋值给一个dat.pca,这个矩阵是不含有分组信息的
fviz_pca_ind(dat.pca,
geom.ind = "point", # show points only (nbut not "text")
col.ind = group_list, # color by groups
# palette = c("#00AFBB", "#E7B800"),
addEllipses = TRUE, # Concentration ellipses
legend.title = "Groups"
)
18.根据表达矩阵及样本分组信息进行批量T检验,得到检验结果表格
dat = exprSet
group_list=as.factor(group_list)
group1 = which(group_list == levels(group_list)[1])
group2 = which(group_list == levels(group_list)[2])
dat1 = dat[, group1]
dat2 = dat[, group2]
dat = cbind(dat1, dat2)
pvals = apply(exprSet, 1, function(x){
t.test(as.numeric(x)~group_list)$p.value
})
p.adj = p.adjust(pvals, method = "BH")
avg_1 = rowMeans(dat1)
avg_2 = rowMeans(dat2)
log2FC = avg_2-avg_1
DEG_t.test = cbind(avg_1, avg_2, log2FC, pvals, p.adj)
DEG_t.test=DEG_t.test[order(DEG_t.test[,4]),]
DEG_t.test=as.data.frame(DEG_t.test)
# 查看t检验结果表格,包含log2FC、pvals和p.adj等,通常认为t<0.05即有统计学意义
head(DEG_t.test)
## t.test
dat = exprSet
group_list=as.factor(group_list)
group1 = which(group_list == levels(group_list)[1])
group2 = which(group_list == levels(group_list)[2])
dat1 = dat[, group1]
dat2 = dat[, group2]
dat = cbind(dat1, dat2)
pvals = apply(exprSet, 1, function(x){
t.test(as.numeric(x)~group_list)$p.value
})
p.adj = p.adjust(pvals, method = "BH")
avg_1 = rowMeans(dat1)
avg_2 = rowMeans(dat2)
log2FC = avg_2-avg_1
DEG_t.test = cbind(avg_1, avg_2, log2FC, pvals, p.adj)
DEG_t.test=DEG_t.test[order(DEG_t.test[,4]),]
DEG_t.test=as.data.frame(DEG_t.test)
head(DEG_t.test)
# avg_1 avg_2 log2FC pvals p.adj
36129_at 7.875615 8.791753 0.9161377 1.629755e-05 0.2057566
37676_at 6.622749 7.965007 1.3422581 4.058944e-05 0.2436177
33791_at 7.616197 5.786041 -1.8301554 6.965416e-05 0.2436177
39967_at 4.456446 2.152471 -2.3039752 8.993339e-05 0.2436177
34594_at 5.988866 7.058738 1.0698718 9.648226e-05 0.2436177
32198_at 4.157971 3.407405 -0.7505660 2.454557e-04 0.3516678
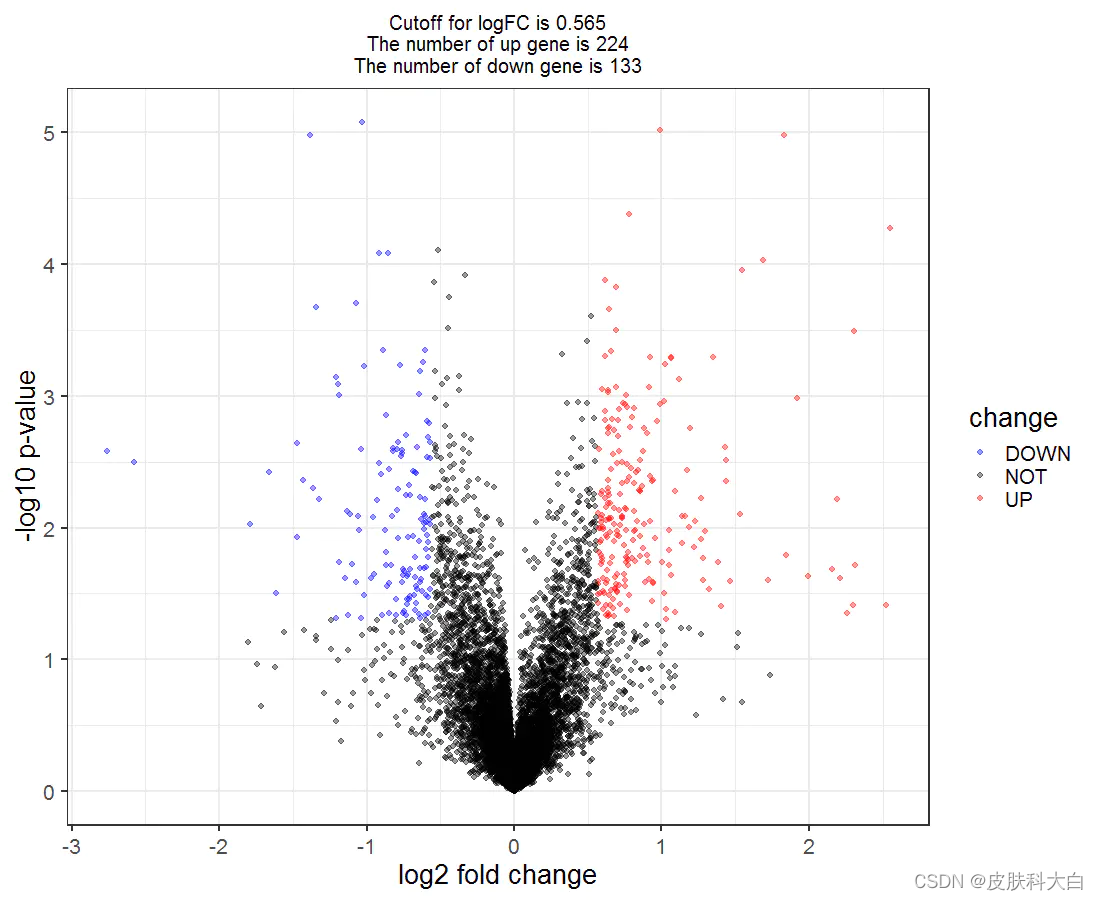
19.使用limma包对表达矩阵及样本分组信息进行差异分析,得到差异分析表格,重点看logFC和P值,画个火山图(就是logFC和-log10(P值)的散点图)。
# DEG by limma
suppressMessages(library(limma))
design <- model.matrix(~0+factor(group_list))
colnames(design)=levels(factor(group_list))
rownames(design)=colnames(exprSet)
design
contrast.matrix<-makeContrasts(paste0(unique(group_list),collapse = "-"),levels = design)
contrast.matrix
##这个矩阵声明,我们要把progres.组跟stable进行差异分析比较
##step1
fit <- lmFit(exprSet,design)
##step2
fit2 <- contrasts.fit(fit, contrast.matrix) ##这一步很重要,大家可以自行看看效果
fit2 <- eBayes(fit2) ## default no trend !!!
##eBayes() with trend=TRUE
##step3
tempOutput = topTable(fit2, coef=1, n=Inf)
nrDEG = na.omit(tempOutput)
#write.csv(nrDEG2,"limma_notrend.results.csv",quote = F)
head(nrDEG)
## volcano plot
DEG=nrDEG
logFC_cutoff <- with(DEG,mean(abs( logFC)) + 2*sd(abs( logFC)) )
DEG$change = as.factor(ifelse(DEG$P.Value < 0.05 & abs(DEG$logFC) > logFC_cutoff,
ifelse(DEG$logFC > logFC_cutoff ,'UP','DOWN'),'NOT')
)
this_tile <- paste0('Cutoff for logFC is ',round(logFC_cutoff,3),
'\nThe number of up gene is ',nrow(DEG[DEG$change =='UP',]) ,
'\nThe number of down gene is ',nrow(DEG[DEG$change =='DOWN',])
)
g = ggplot(data=DEG, aes(x=logFC, y=-log10(P.Value), color=change)) +
geom_point(alpha=0.4, size=1.75) +
theme_set(theme_set(theme_bw(base_size=20)))+
xlab("log2 fold change") + ylab("-log10 p-value") +
ggtitle( this_tile ) + theme(plot.title = element_text(size=15,hjust = 0.5))+
scale_colour_manual(values = c('blue','black','red')) ## corresponding to the levels(res$change)
print(g)
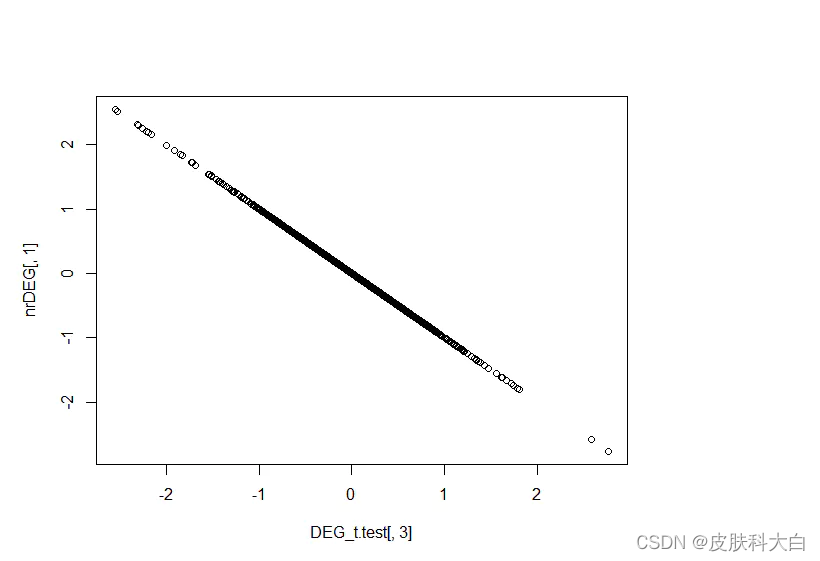
20.对T检验结果的P值和limma包差异分析的P值画散点图,看看哪些基因相差很大。
### different P values
head(nrDEG)
head(DEG_t.test)
DEG_t.test=DEG_t.test[rownames(nrDEG),]
plot(DEG_t.test[,3],nrDEG[,1])
plot(DEG_t.test[,4],nrDEG[,4])
plot(-log10(DEG_t.test[,4]),-log10(nrDEG[,4]))
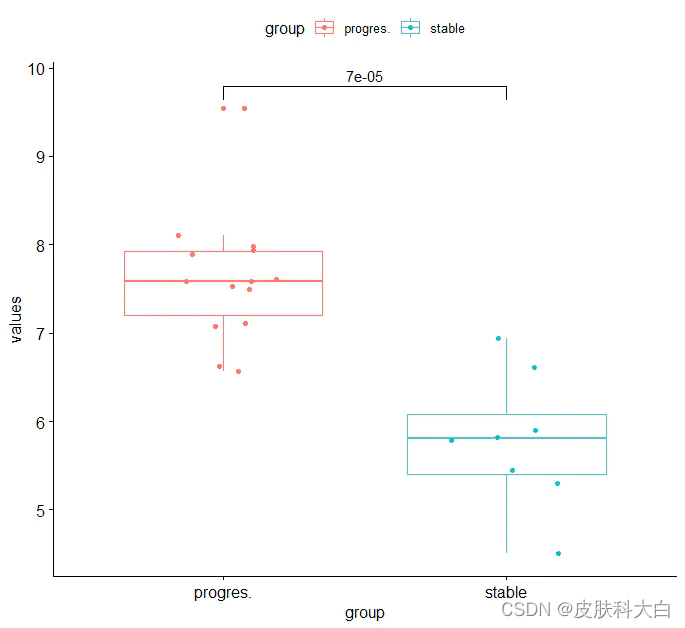
rownames(exprSet)=ids[match(rownames(exprSet),ids$probe_id),2]
exprSet[1:5,1:5]
exprSet['GAPDH',]
exprSet['ACTB',]
exprSet['DLEU1',]
library(ggplot2)
library(ggpubr)
my_comparisons <- list(
c("stable", "progres.")
)
dat=data.frame(group=group_list,
sampleID= names(exprSet['DLEU1',]),
values= as.numeric(exprSet['DLEU1',]))
ggboxplot(
dat, x = "group", y = "values",
color = "group",
add = "jitter"
)+
stat_compare_means(comparisons = my_comparisons, method = "t.test")
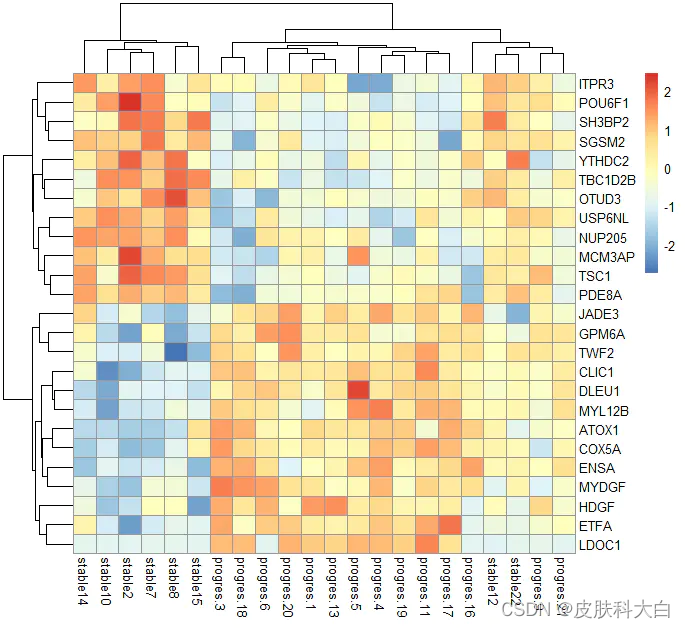
## heatmap
library(pheatmap)
choose_gene=head(rownames(nrDEG),25)
choose_matrix=exprSet[choose_gene,]
choose_matrix=t(scale(t(choose_matrix)))
pheatmap(choose_matrix)