原文:Alex C-G
译文:Piper Hu
(本文阅读时长约为5分钟)

神经搜索 是数据处理上非常新颖的一个话题,也是Jina AI目前着重关注的方向,可是到底神经搜索是什么?它能解决什么问题?与现在开发者们使用的搜索系统搭建又有什么不一样?今天,就让我们一起走进神奇的神经搜索世界,及神经搜索的最佳探索方式——Jina。
什么是神经搜索?
简而言之,神经搜索是一种全新的信息检索方式。神经搜索通过预训练的神经网络来达到传统的训练机器需要被设置各种各样的数据理解规则进行数据理解的效果。这也就意味着,开发者不再需要花费更多的时间在编写各式各样的数据理解规则上,也就解决了搭建复杂数据处理系统中一个非常令人头疼的问题,并且神经系统本身自己也可以在不断使用的过程中自我训练。
什么是Jina?
Jina 是我们搭建的最好的最快的神经搜索搭建框架。
Jina 架构是云原生的,所以在它诞生的第一天起就可以搭建在基于容器的服务上,并且Jina 可以解决任何数据类型的搜索问题,比如基于语义理解的长短文本搜索,图片、声音、视频等多媒体数据类型的搜索,代码搜索等等。总之,利用Jina搭建的搜索系统,应该可以搜索一切!
关于搜索
搜索是一个在日益剧增的巨大产业。就在几年前,搜索还只是在文本框中输入几行文字。而现在可搜索的数据类型已包括文本、语音、音乐、照片、视频、产品等等。在世纪之交之前,谷歌的搜索量每天只有350万次。如今(根据搜索词2020谷歌每天搜索量的最高结果),这个数字可能已经飙升至50亿,是原来的1000多倍。更何况这还不包括每天数百万人通过手机、电脑和虚拟助手搜索的数十亿维基百科文章、亚马逊产品和Spotify播放列表!
下图中谷歌查询的飞速增长即可体现——而这只是截止到2012年!
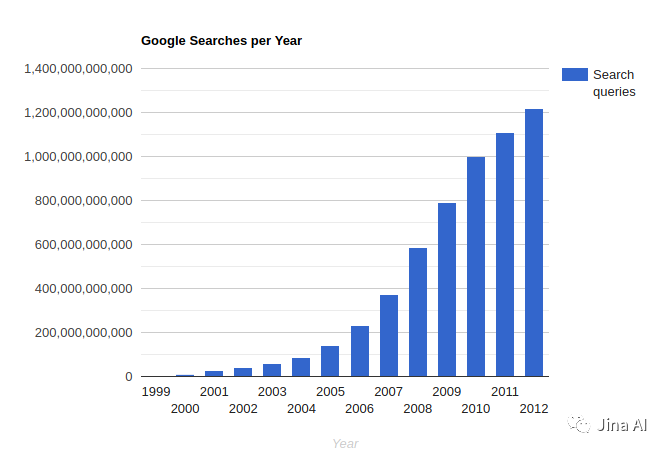
总之,搜索是一个非常巨大的产业,我们将在这篇文章里讨论到搜索方法的长期霸主——符号搜索,以及勇敢的新锐玩家——神经搜索。

符号搜索:基于规则的搜索
我们常用的百度或者谷歌就是一个巨大的通用搜索引擎,但其他公司不能根据自己的需求对其进行调整,并将其插入他们的系统。基于此,像Elastic和Apache Solr这样的框架应运而生。这些符号搜索框架系统允许开发人员编写规则来创建公司所需的可对产品、人物、消息或任何东西进行搜索的处理流程。
让我们以购物平台Shopify为例。
Shopify需对数百个类别中的数百万种产品进行索引和搜索,工程上这不能轻易实现,开发团队也无法使用谷歌这样的通用搜索引擎来搭建服务,所以他们选择了使用Elastic框架并编写特定的规则和处理流程,根据各种标准对产品进行索引、过滤、分类和排序,并将这些数据转换为搜索系统可以理解的符号。下图是一家很受欢迎的Shopify运动鞋店——Greates的页面:
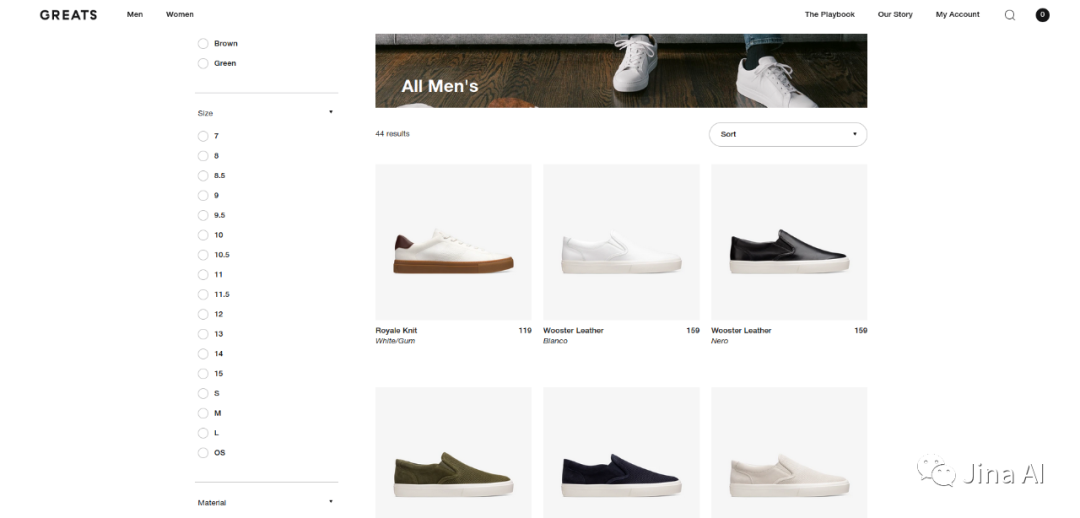
如果你想搜索一对你心仪已久的红色耐克滑板鞋,你会输入“red nike sneakers”。对于一个典型的搜索系统来说,这些只是一个个单纯的词汇,如果你运气不错,你可能碰巧会得到你想要的结果。但如果这些运动鞋被标记为trainers怎么办?或者被标记为深红色?。为解决这些情况,开发人员就需要编写相应的规则:
-
Red is a color
Scarlet is a synonym of red
Nike is a brand
Sneakers are a type of footwear
Another name for sneakers is trainers
或者用JOSN形式的Key-Value 对来表示:
{
"color": "red",
"color_synonyms": ["scarlet"],
"brand": "nike",
"type": "sneaker",
"type_synonyms": ["trainers"],
"category": "footwear"
}
这些Key-Value对中的每一个都可以看作是一个符号——这也就是符号搜索(Symbolic Search)命名的由来。当用户输入搜索查询时,系统将其分解为符号,并将这些符号与数据库中产品的符号进行匹配。

那么,问题来了,如果用户输入的是nikke 而不是nike(拼写错误),或者搜索的是shirts(复数)而不是shirt(语法上的变化)。这些繁杂的语法规则并不能总是被人们所遵循,所以为了获得有效的符号(例如,知道nikke真正要表达的是{"brand":"nike"}则有需要定义更多相应的规则,并将他们在一个复杂的处理流程中按照类似下图的方式连接。
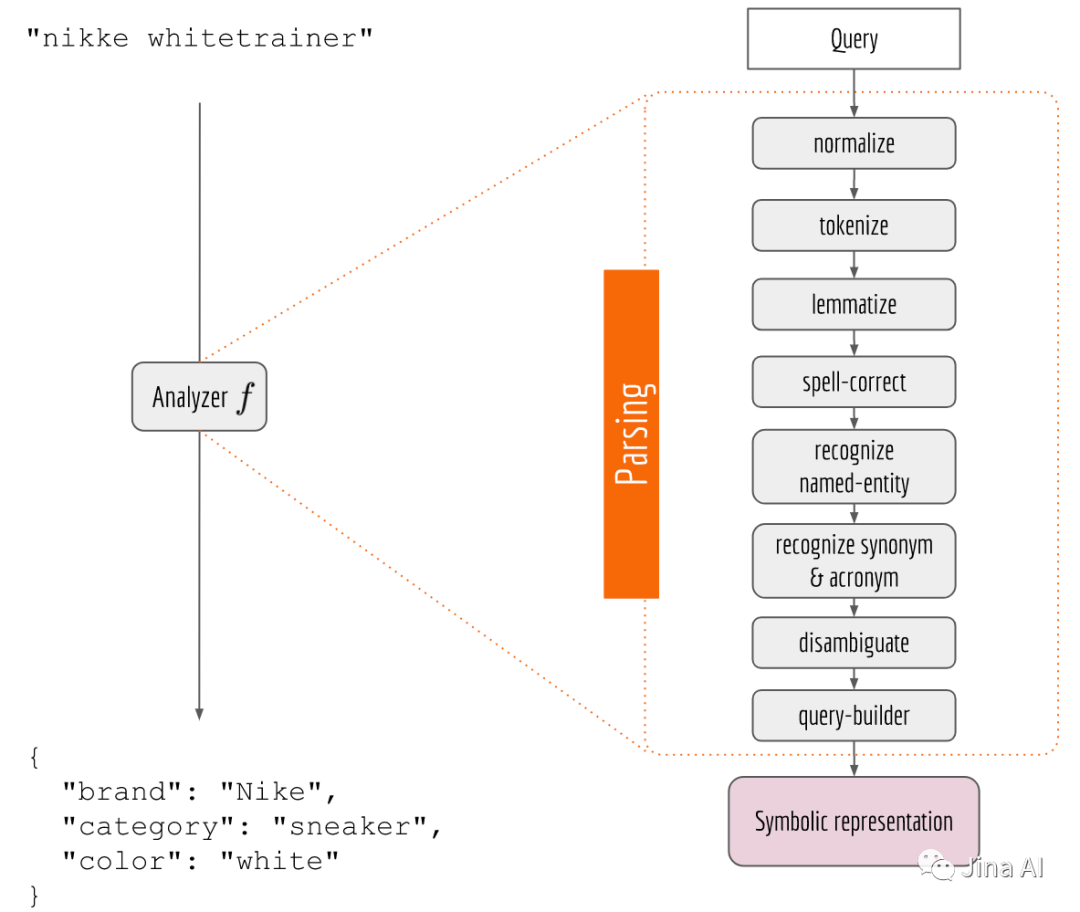
符号搜索的短板
每一个细枝末节的规则都不能少
上面的搜索查询词是“red nike sneaker man”。但如果用户是一名英国人,他就会按照英国的语言习惯输入“red nike trainer man”。此时,我们就必须向我们的系统解释,sneaker和trainer只是名字不同的同一个东西。而当有人在搜“LV handbag”时,我们又得让系统把LV理解为Louis Vuitton。
为每一种产品设置规则不仅需要花费很长的时间,而且总有一些遗漏之处,若要更换成另一种语言还需重新构建整套语法规则。这将会带来大量的工作、对细节的关注、还有专业的语言知识。
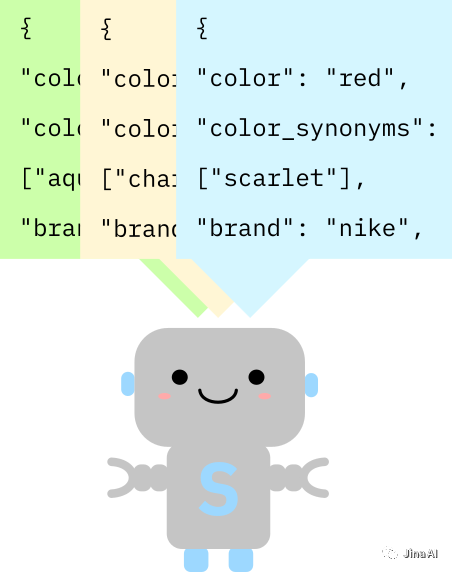
符号搜索相对来说是脆弱的
现实文本总是复杂的:正如我们上面阐述的,如果用户输入“red nike sneaker man”,一个经典的搜索系统必须识别出他们正在搜索的是:red (颜色) Nike (brand 且 拼写正确) sneaker (商品种类) for men (细分品类)。这是通过将搜索字符串和产品细节通过处理流程转换为为相应符号而完成的,而这些处理流程可能产生很多问题。

神经搜索:预训练,无需多言
相较传统搜索方式,使用现有数据训练出的神经网络进行搜索是一种更简洁、更方便的方法。只要你预先在足够多的不同场景下训练这个系统(预训练模型),它就会学习出一种找到与输入相匹配的输出的泛化能力,输入数据可以是Tumblr GIF、维基百科的句子抑或是Pokémon的图片。而你所需要做的,只是将此模型直接嵌入你的系统,就可以立即开始索引和搜索。
from jina import Document, Executor, requests, Flow
class JinaEngineers(Executor):
@requests(on='/work')
def work(self, docs, **kwargs):
for d in docs:
d.text += '✅'
def celebrate(resp):
for d in resp.data.docs:
print(f'
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)