文章目录
- 关键词
- 一、做什么
- 二、怎么做
- 1、获取数据&&处理数据
- 2、数据库设计&&存储数据
- 3、开发后端接口
- 4、前端页面编写
- 三、效果展示
- 四、总结
关键词
- Python
- Django
- Python网络爬虫
- echarts可视化
- 阅读者(Python基础、Django基础、H5基础)
一、做什么
国家数据十年数据
教育、文化、体育、财政…
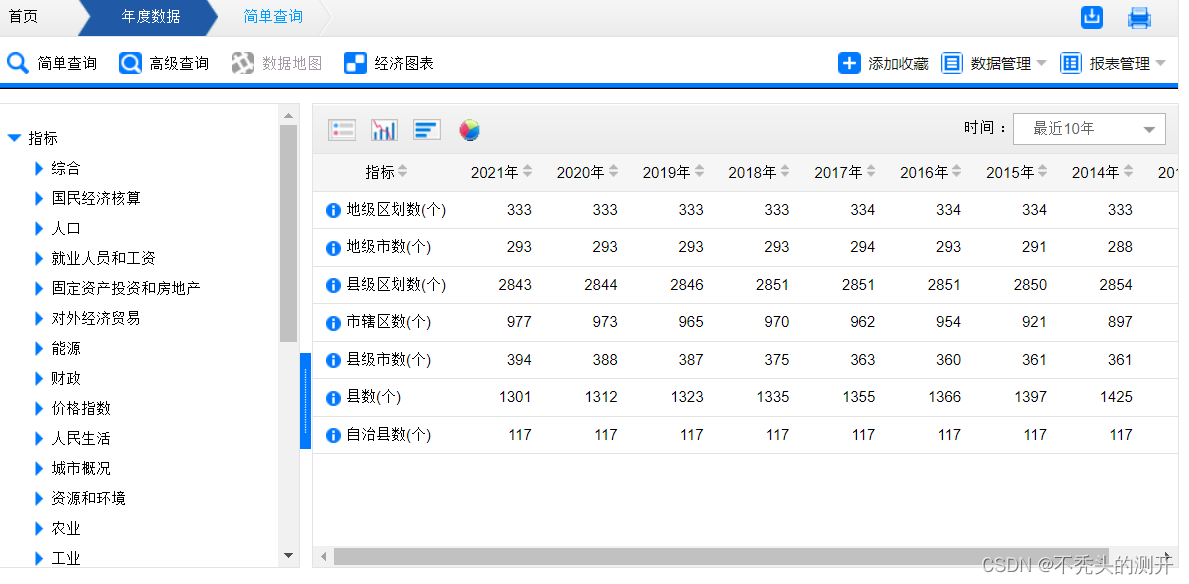
二、怎么做
1、获取数据&&处理数据
分析网页数据 | 接口
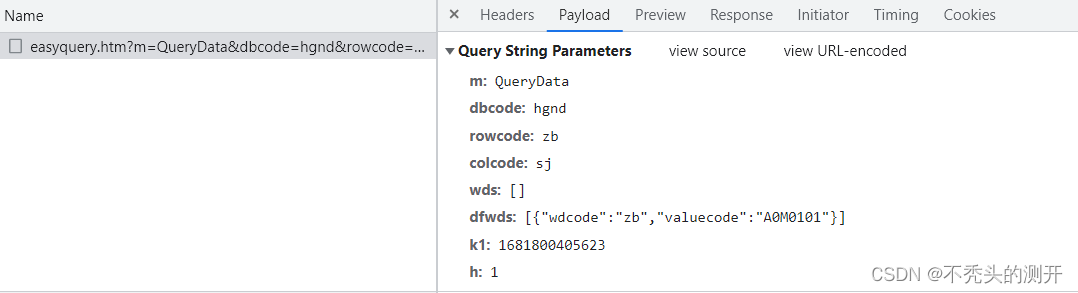
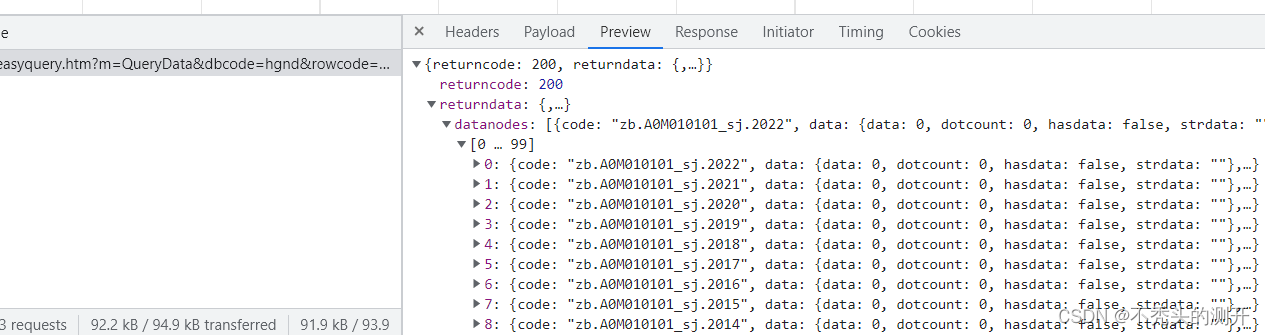
通过构造请求即可获取数据
import requests
url = "https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=zb&colcode=sj&wds=%5B%5D&dfwds=%5B%7B%22wdcode%22%3A%22zb%22%2C%22valuecode%22%3A%22A0M0101%22%7D%5D&k1=1681802150380&h=1"
payload={}
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'en,zh-CN;q=0.9,zh;q=0.8',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Cookie': '_trs_uv=lb3ivyja_6_9rxg; wzws_sessionid=gWQ5YzU0NIAyNDA5OjhhMzg6YzBhOjU3Yjg6NDA3Ojk4OTc6ZmJkZTpkODE1oGQ+OquCZmM1ZWUx; u=6; JSESSIONID=nhaTNEtX-UbYOP07UUOERWA20RlZhKPfyIJOXPgdpF5X26gOalzB!1171792879',
'Pragma': 'no-cache',
'Referer': 'https://data.stats.gov.cn/easyquery.htm?cn=C01',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua': '"Chromium";v="112", "Google Chrome";v="112", "Not:A-Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"'
}
response = requests.request("GET", url, headers=headers, data=payload)
print(response.text)
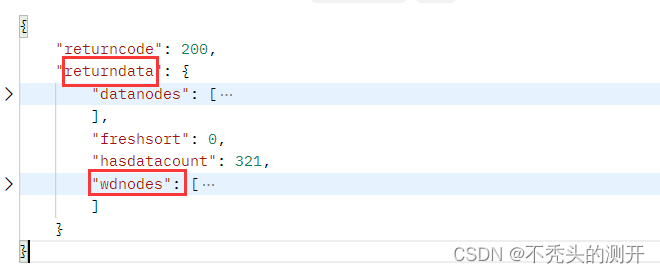
处理response
我们要获取的数据有
datanodes[i].data.data 年度数据
wdnodes[i].nodes.cname 数据名称
wdnodes[i].nodes.unit 单位
__author__ = "Nick"
__created_date__ = "2023/04/18"
import requests
import json
import pymysql
import time
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
import random
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Cookie': '_trs_uv=lb3ivyja_6_9rxg; wzws_sessionid=gTc5MmRlNaBjiV2ZgmZjNWVlMYAyNDA5OjhhMzg6YzBhOmNlNDE6NDA3Ojk4OTc6ZmJkZTpkODE1; u=2; JSESSIONID=JdPTM5JOti-gtAt3y4OxewoNkDOizREzxPdkiYzr1HkaEoOXtsDc!2123879546',
'Pragma': 'no-cache',
'Referer': 'https://data.stats.gov.cn/easyquery.htm?cn=C01',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
class Get_national_data():
def __init__(self,url,fld,sld_name):
"""
@param url 请求url
@param fld 一级目录缩写
@param sld 二级目录category_name_two缩写
"""
self.url = url
self.fid = fld
self.sld_name = sld_name
def get_request(self):
"""
发起请求
"""
payload = {}
time.sleep(3)
r = requests.request("GET", url=self.url, headers=headers, data=payload, verify=False)
r.encoding = "utf-8"
res = json.loads(r.text.encode("utf-8"))
self.res = res
def count_cname(self):
"""
统计二级目录下指标数量
@return 二级目录下指标个数
"""
unit = self.res["returndata"]["wdnodes"][0]["nodes"][0]["unit"]
self.unit = unit
names_list = self.res["returndata"]["wdnodes"][0]["nodes"]
index_name = []
for name in names_list:
_name = name["name"]
index_name.append(_name)
return len(index_name)
def get_original_data_name(self):
"""
获取二级目录下的指标名称
通过 yield 函数每次获取一个名称
"""
names_list = self.res["returndata"]["wdnodes"][0]["nodes"]
index_name = []
for name in names_list:
_name = name["name"]
index_name.append(_name)
if len(index_name) == 1:
yield index_name
index_name = []
def get_original_data(self):
"""
获取二级目录下具体的数据
通过yield 每次获取取10个值
"""
data_list = self.res["returndata"]["datanodes"]
process_data = []
for data in data_list:
info = data["data"]["data"]
process_data.append(info)
if len(process_data) == 10:
yield process_data
process_data = []
def get_data_10(self, data, data_name):
"""
获取一组值
@param data get_original_data实例化获取
@param data_name get_original_data_name 实例化获取
@return 返回一组数据,元祖类型
"""
cname = data_name.__next__()[0]
self.cname = cname
self.select_cname_id()
last_data = data.__next__()
last_data.insert(0,cname)
last_data.extend([self.unit, self.fid , self.sid_id])
return tuple(last_data)
def connect_db(self):
"""
连接数据库
@return 数据库实例化
"""
connect = pymysql.connect(
host="localhost",
port=3306,
user='root',
password='rootroot',
database='tenchina'
)
return connect
def select_cname_id(self):
connect = self.connect_db()
cursor = connect.cursor()
try:
sql_id = f"""
select id from tb_category_two where category_name_two = {self.sld_name}
"""
cursor.execute(sql_id)
result = cursor.fetchone()
connect.commit()
connect.close()
self.sid_id = result[0]
except Exception as e:
print(e)
if __name__ == '__main__':
pass
2、数据库设计&&存储数据
Django中通过model.py定义数据字段即可完成表的设计
from django.db import models
"""
建立三张表
1、tb_category_one 一级目录表
2、tb_category_two 二级目录表
3、数据表
"""
class category_one(models.Model):
category_name = models.CharField(max_length=10)
class Meta:
db_table = "tb_category_one"
class category_two(models.Model):
category_name_two = models.CharField(max_length=40)
specific = models.ForeignKey(to=category_one,related_name="specific", on_delete=models.CASCADE)
class Meta:
db_table = "tb_category_two"
class detail(models.Model):
name = models.CharField(max_length=30)
year_2021 = models.DecimalField(max_digits=12,decimal_places=4,null=True)
year_2020 = models.DecimalField(max_digits=12,decimal_places=4,null=True)
year_2019 = models.DecimalField(max_digits=12,decimal_places=4,null=True)
year_2018 = models.DecimalField(max_digits=12,decimal_places=4,null=True)
year_2017 = models.DecimalField(max_digits=12,decimal_places=4,null=True)
year_2016 = models.DecimalField(max_digits=12,decimal_places=4,null=True)
year_2015 = models.DecimalField(max_digits=12,decimal_places=4,null=True)
year_2014 = models.DecimalField(max_digits=12,decimal_places=4,null=True)
year_2013 = models.DecimalField(max_digits=12,decimal_places=4,null=True)
year_2012 = models.DecimalField(max_digits=12,decimal_places=4,null=True)
unit = models.CharField(max_length=10)
category_1 = models.ForeignKey(to=category_one,related_name="category_list_1",on_delete=models.CASCADE)
category_2 = models.ForeignKey(to=category_two, related_name="category_list_2", on_delete=models.CASCADE)
class Meta:
db_table = "tb_detail"
数据迁移
记得setting.py配置MySQL数据库,并新建相关数据库
python manage.py makemigrations
python manage.py migrate
3、开发后端接口
1、view.py 编写视图函数
2、url.py 定义相关路由
def create_sql(table_name,category_id):
_sql = f"select DISTINCT id,name,year_2021,year_2020,year_2019,year_2018,year_2017,year_2016,year_2015,year_2014,year_2013,year_2012,unit from {table_name} where category_2_id = {category_id} LIMIT 6;"
return _sql
def education_select(request,num):
"""
@param request:
@param num: 1-各级各类学校数处理、2-各级各类学校专任教师数处理、3-各级各类学校毕业生数处理、4-研究生和留学生数处理
@return:Json数据,Echarts拿到数据回显
"""
data = ['2021', '2020', '2019', '2018', '2017', '2016', '2015', '2014', '2013', '2012']
index_list = []
series_list = []
data_2021 = []
data_2020 = []
data_2019 = []
data_2018= []
data_2017 = []
data_2016 = []
data_2015 = []
data_2014 = []
data_2013 = []
data_2012 = []
if num == "1":
sql = create_sql(table_name="tb_detail",category_id=1)
elif num == "2":
sql = create_sql(table_name="tb_detail",category_id=2)
elif num == "3":
sql = create_sql(table_name="tb_detail", category_id=5)
elif num == "4":
sql = create_sql(table_name="tb_detail", category_id=6)
ret = detail.objects.raw(sql)
for item in ret:
index_list.append(item.name)
data_2021.append(item.year_2021)
data_2020.append(item.year_2020)
data_2019.append(item.year_2019)
data_2018.append(item.year_2018)
data_2017.append(item.year_2017)
data_2016.append(item.year_2016)
data_2015.append(item.year_2015)
data_2014.append(item.year_2014)
data_2013.append(item.year_2013)
data_2012.append(item.year_2012)
for i in range(21, 11, -1):
year = f"20{i}"
series_dict = {
'name': year,
'type': 'line',
'stack': 'Total',
'data': ''
}
if year == "2021":
series_dict["data"] = data_2021
elif year == "2020":
series_dict["data"] = data_2020
elif year == "2019":
series_dict["data"] = data_2019
elif year == "2018":
series_dict["data"] = data_2018
elif year == "2017":
series_dict["data"] = data_2017
elif year == "2016":
series_dict["data"] = data_2016
elif year == "2015":
series_dict["data"] = data_2015
elif year == "2014":
series_dict["data"] = data_2014
elif year == "2013":
series_dict["data"] = data_2013
elif year == "2012":
series_dict["data"] = data_2012
else:
pass
if num == "1":
pass
elif num == "2":
focus ={"focus": 'series'}
series_dict["emphasis"] = focus
series_dict["areaStyle"] = "{}"
elif num == "3":
series_dict["type"] = "bar"
focus = {"focus": 'series'}
series_dict["emphasis"] = focus
series_dict["stack"] = 'Ad'
elif num == "4":
series_dict["type"] = 'bar'
show ={"show": "true"}
series_dict["label"] = show
series_list.append(series_dict)
result = {
"status": True,
"data":{
"legend": data,
"xAxis": index_list,
"series_list": series_list,
}
}
return JsonResponse(result)
def chart_three(request):
"""
各级各类学校招生数
@param request:
@return: Json数据,Echarts拿到数据回显
"""
source = []
data = ['year', '2021', '2020', '2019', '2018', '2017','2016', '2015', '2014', '2013','2012']
source.append(data)
sql = create_sql(table_name="tb_detail", category_id=3)
ret = detail.objects.raw(sql)
for item in ret:
data_list = []
data_list.extend([item.name,item.year_2021,item.year_2020,item.year_2019,
item.year_2018,item.year_2017,item.year_2016,item.year_2015,
item.year_2014,item.year_2013,item.year_2012])
source.append(data_list)
result = {
"status": True,
"data": source
}
return JsonResponse(result)
def chart_four(request):
"""
各级各类学校在校学生数
@param request:
@return:Json数据,Echarts拿到数据回显
"""
dataset = {}
dataset["dimensions"] = ['product', '2021', '2020', '2019', '2018', '2017','2016']
source_list = []
sql = create_sql(table_name="tb_detail", category_id=4)
ret = detail.objects.raw(sql)
for item in ret:
if item.year_2021:
source_dict = {}
source_dict["product"] = item.name
source_dict["2021"] = item.year_2021
source_dict["2020"] = item.year_2020
source_dict["2019"] = item.year_2019
source_dict["2018"] = item.year_2018
source_dict["2017"] = item.year_2017
source_dict["2016"] = item.year_2016
source_list.append(source_dict)
dataset["source"] = source_list
result = {
"status": True,
"data": dataset
}
return JsonResponse(result)
from django.urls import path,re_path
from . import views as v
urlpatterns = [
re_path(r'^educate/(\d+)$',v.education_select),
path('educate/chart3',v.chart_three),
path('educate/chart4',v.chart_four),
re_path(r'^culture/(\d+)$',v.culture_select),
path('culture/chart3',v.chart_three_culture),
path('culture/chart4',v.chart_four_culture),
re_path(r'^pe/(\d+)$',v.pe_select),
path('pe/chart3',v.chart_three_pe),
path('pe/chart4',v.chart_four_pe),
]
4、前端页面编写
省略相关js、css文件,见代码仓库
base.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<link rel="stylesheet" href="../static/css/main.css" />
<title>{{ title }}</title>
</head>
<body>
<div class="nav_menu w">
<div class="menu_item">
<div class="home">教育</div>
<div class="web_home"><a href="http://127.0.0.1:8000/index">教育首页</a></div>
</div>
<div class="menu_item">
<div class="home">文化</div>
<div class="web_home"><a href="http://127.0.0.1:8000/culture">文化首页</a></div>
</div>
<div class="menu_item">
<div class="home">体育</div>
<div class="web_home"><a href="http://127.0.0.1:8000/pe">体育首页</a></div>
</div>
<div class="menu_item">
<div class="home">财政</div>
<div class="web_home"><a href="#">财政首页</a></div>
</div>
<div class="menu_item">
<div class="home">人民生活</div>
<div class="web_home"><a href="#">人民生活</a></div>
</div>
<div class="menu_item">
<div class="home">科技</div>
<div class="web_home"><a href="#">科技首页</a></div>
</div>
<div class="menu_item">
<div class="home">卫生</div>
<div class="web_home"><a href="#">卫生首页</a></div>
</div>
<div class="menu_item">
<div class="home">社会</div>
<div class="web_home">社会首页</div>
</div>
</div>
<nav class="menu">
<ol>
<li id="content1" class="menu-item active">
<a href="javascript:void(0);">{{ category_content.0}}</a>
</li>
<li id="content2" class="menu-item">
<a href="javascript:void(0);">{{category_content.1 }}</a>
</li>
<li id="content3" class="menu-item">
<a href="javascript:void(0);">{{category_content.2 }}</a>
</li>
<li id="content4" class="menu-item">
<a href="javascript:void(0);">{{ category_content.3 }}</a>
</li>
<li id="content5" class="menu-item">
<a href="javascript:void(0);">{{category_content.4 }}</a>
</li>
<li id="content6" class="menu-item">
<a href="javascript:void(0);">{{ category_content.5 }}</a>
</li>
</ol>
</nav>
<div class="container-div">
<div class="text content1" id="container"></div>
<div class="text content2" id= "container1"></div>
<div class="text content3" id ="container2"></div>
<div class="text content4" id="container3"></div>
<div class="text content5" id = "container4"></div>
<div class="text content6" id="container5"></div>
</div>
<script src="https://www.jq22.com/jquery/jquery-1.10.2.js"></script>
{% block tojs %}
{% endblock %}
<script type="text/javascript" src="https://fastly.jsdelivr.net/npm/echarts@5.4.0/dist/echarts.min.js"></script>
</body>
</html>
educate.html
{% extends "base.html" %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
{% block tojs %}
<script src="../static/js/index.js"></script>
{% endblock %}
</body>
</html>
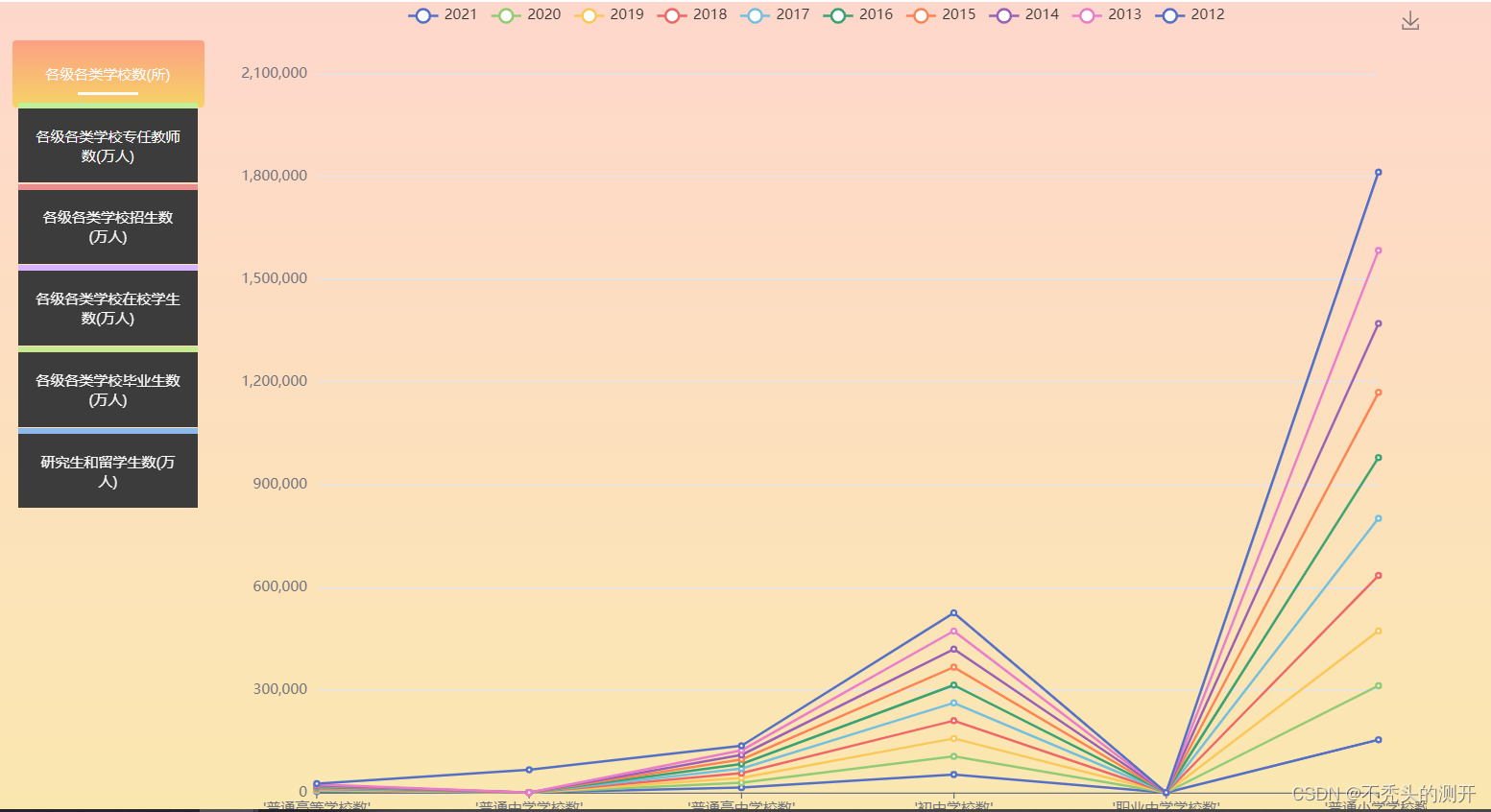
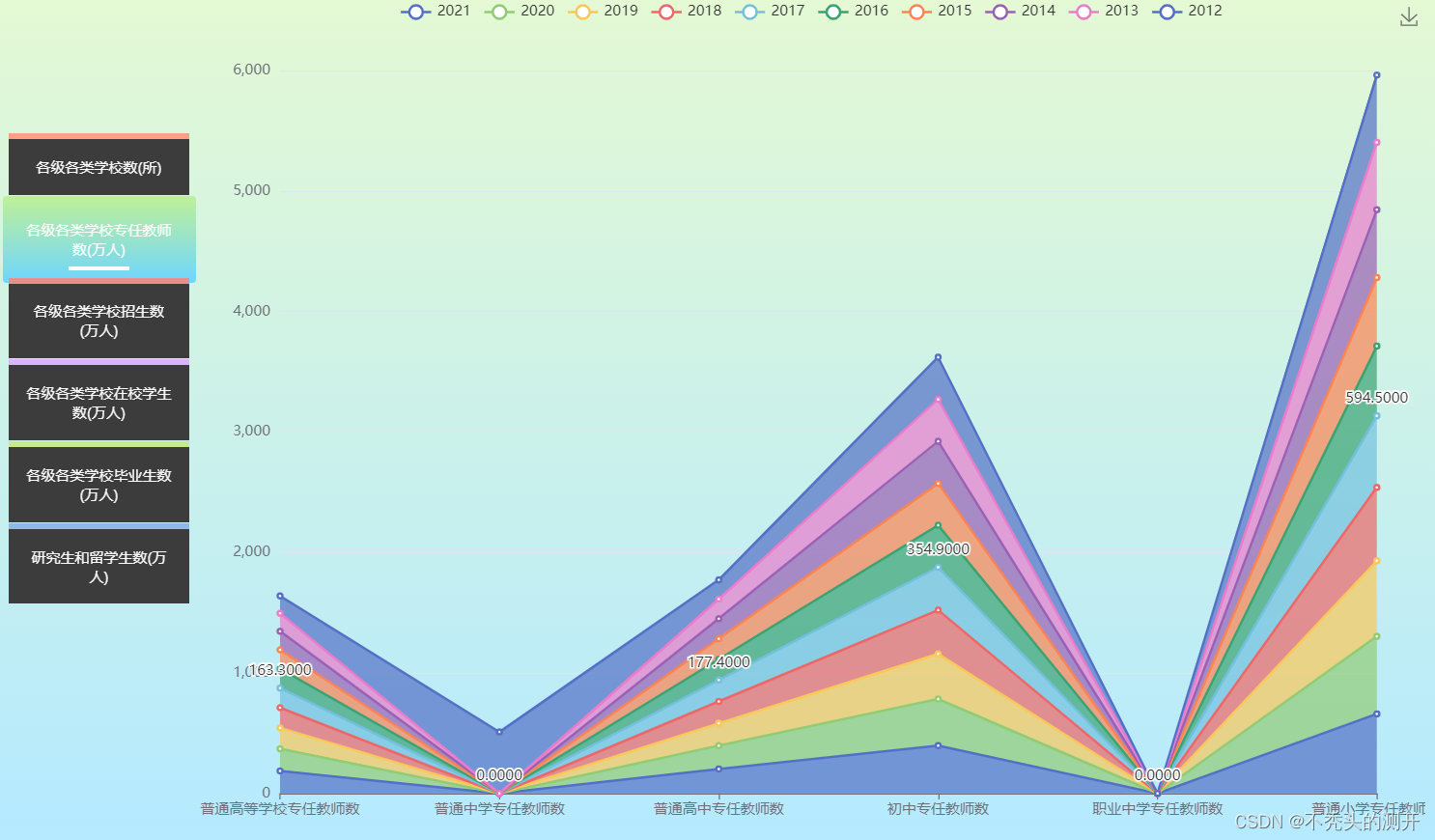
三、效果展示

四、总结
- 过于混杂(之后会进行改造)
- 数据分析过于单一(数据可视化为的是更好的展示结论)
[gitee]
https://gitee.com/nickwang666/visual-ten-china

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)