把p2b的工作推广到p2rb
目的:学习目标检测,熟悉目标检测,为自己写论文打基础
我的碎碎念:真的是fuck了,自己这个东西整了这么久,还是没有整出来,从5月分我就开始了把。因为考试,因为自己喜欢玩游戏,因为我tm真的浪费了好多时间,像个废物,学校还封校&我很不爽。
就这样把,去死吧fuck day!!!
p2b模型为,从点标注实现框检测。是一个很神奇的网络。
本文的逻辑是:利用点标注,生成框标注,利用框,进行强监督。这就是为什么模型会有两个部分组成,并且有前后逻辑关系。那么这个模型能不能好,主要就是取决于点到框标注,生成的怎么样。
训练好网络之后,只需要只是用第二个模块,便是一个detection网络。
第一部分:p2b网络
整体逻辑
首先,经过了backbone和neck模块后,会根据stage的不同,做出不同的训练策略
for stage in range(self.num_stages):
if stage == 0:
generate_proposals, proposals_valid_list = gen_proposals_from_cfg(gt_points, base_proposal_cfg,
img_meta=img_metas)
dynamic_weight = torch.cat(gt_labels).new_ones(len(torch.cat(gt_labels)))
neg_proposal_list, neg_weight_list = None, None
pseudo_boxes = generate_proposals
else:
generate_proposals, proposals_valid_list = fine_proposals_from_cfg(pseudo_boxes, fine_proposal_cfg,
img_meta=img_metas,
stage=stage)
neg_proposal_list, neg_weight_list = gen_negative_proposals(gt_points, fine_proposal_cfg,
generate_proposals,
img_meta=img_metas)
roi_losses, pseudo_boxes, dynamic_weight = self.roi_head.forward_train(stage, x, img_metas,
pseudo_boxes,
generate_proposals,
proposals_valid_list,
neg_proposal_list, neg_weight_list,
gt_true_bboxes, gt_labels,
dynamic_weight,
gt_bboxes_ignore, gt_masks,
**kwargs)
首先,stage==0,会根据设定好的大小和比例,在每一个gt_points为中心,生成一系列的框,更具体一点:
6种不同的尺寸4,8,16,32,64,128
7种不同的比例0.33,0.5,0.66,1,1.5,2,3
在一幅图片的7个gt_points附近,生成了(7*42,4)的数据
生成好初始的框之后,便进入了网络最重要的一部分:
self.roi_head.forward_train(*)
def _bbox_forward_train(self, x, proposal_list_base, proposals_list, proposals_valid_list, neg_proposal_list,
neg_weight_list, gt_points,
gt_labels,
cascade_weight,
img_metas, stage):
rois = bbox2roi(proposals_list)
bbox_results = self._bbox_forward(x, rois, gt_points, stage)
num_instance = bbox_results['num_instance']
gt_labels = torch.cat(gt_labels)
proposals_valid_list = torch.cat(proposals_valid_list).reshape(
*bbox_results['cls_score'].shape[:2], 1)
if neg_proposal_list is not None:
neg_rois = bbox2roi(neg_proposal_list)
neg_bbox_results = self._bbox_forward(x, neg_rois, None, stage) ######stage
neg_cls_scores = neg_bbox_results['cls_score']
neg_weights = torch.cat(neg_weight_list)
else:
neg_cls_scores = None
neg_weights = None
reg_box = bbox_results['bbox_pred']
if reg_box is not None:
boxes_pred = self.bbox_head.bbox_coder.decode(torch.cat(proposals_list).reshape(-1, 4),
reg_box.reshape(-1, 4)).reshape(reg_box.shape)
else:
boxes_pred = None
proposals_list_to_merge = proposals_list
pseudo_boxes, mean_ious, filtered_boxes, filtered_scores, dynamic_weight = self.merge_box(bbox_results,
proposals_list_to_merge,
proposals_valid_list,
gt_labels,
gt_points,
img_metas, stage)
bbox_results.update(pseudo_boxes=pseudo_boxes)
bbox_results.update(dynamic_weight=dynamic_weight.sum(dim=-1))
pseudo_boxes = torch.cat(pseudo_boxes)
if stage == self.num_stages - 1:
retrain_weights = self._bac_assigner(torch.cat(proposals_list), torch.cat(proposal_list_base))
else:
retrain_weights = None
loss_instance_mil = self.bbox_head.loss_mil(stage, bbox_results['cls_score'], bbox_results['ins_score'],
proposals_valid_list,
neg_cls_scores, neg_weights,
boxes_pred, gt_labels,
torch.cat(proposal_list_base), label_weights=cascade_weight,
retrain_weights=retrain_weights)
loss_instance_mil.update({"mean_ious": mean_ious[-1]})
loss_instance_mil.update({"s": mean_ious[0]})
loss_instance_mil.update({"m": mean_ious[1]})
loss_instance_mil.update({"l": mean_ious[2]})
loss_instance_mil.update({"h": mean_ious[3]})
bbox_results.update(loss_instance_mil=loss_instance_mil)
return bbox_results
上面这一段函数,有一些非常重要的子函数,这里非常有必要好好介绍并解释:
- bbox2roi :(294,4),(168,4) -->(462,5)这里是把两个初始坐标concatenate在一起,然后加入image_id以加以区分
- bbox_forward:这是最最重要的函数其包含很多函数和模块,下面会详细介绍
- merge_box
- loss_mil
上面的除了第一个都需要篇幅进行介绍。需要值得注意的是,这里的部分的代码都是stage0和1都需要跑的部分,这并不是代码stage0,1走的是一条路径,在每一个函数中,它们分别用了不同的处理。
经过了bbox_forward之后,会根据有无负例框,有无reg_box进行一些操作。而这些操作,在stage=0的时候都是略过的。在stage=1的时候,我们会一一介绍
然后便进入了merg_box函数–请从目录中进入
merge之后,stage0也就步入了尾声,最后计算loss
loss_mil—
pseudo_boxes, mean_ious, filtered_boxes, filtered_scores, dynamic_weight =
self.merge_box(
bbox_results,
proposals_list_to_merge,
proposals_valid_list,
gt_labels,
gt_points,
img_metas, stage
)
bbox_forward
_bbox_forward(x,rois,gt_points,stage)
这一段代码:根据roi从图片中提取特征,传入head模块提取分类得分,实例得分,回归框。
经过reshape之后传回一个字典
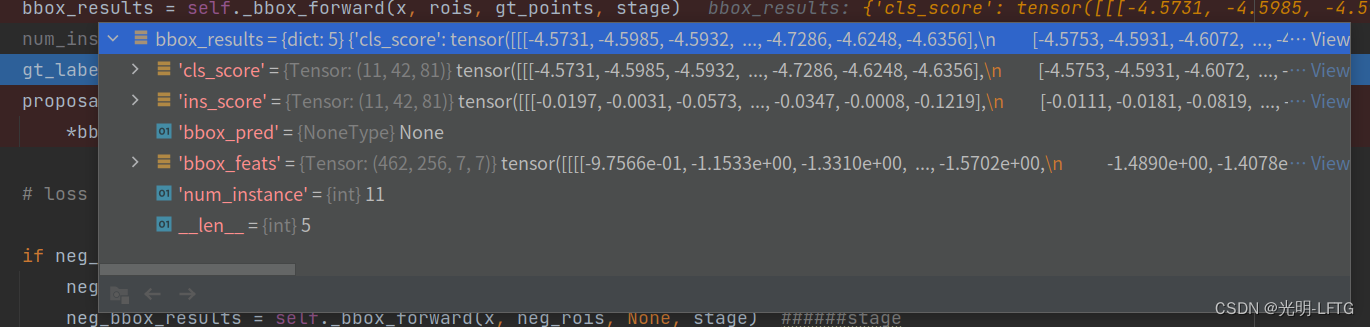
bbox_results = dict(cls_score=cls_score, ins_score=ins_score, bbox_pred=reg_box,
bbox_feats=bbox_feats, num_instance=num_gt)
merge_box
merge_box(self, bbox_results, proposals_list, proposals_valid_list, gt_labels, gt_bboxes, img_metas, stage)
还记得之前提到,在每一个gt点的附近生成了42个不同尺寸比例的框,这一步就是融合这些不同的框,使得每一个gt点只保留一个框,然后进行强监督训练。那么,如何决定最终保留的框呢?
这里采用根据分类得分预测的前7名,在通过加权平均的方式得到坐标。
这一部分的代码用到了非常巧妙的取切片的操作。
而其中分类得分的预测就在上一个函数中已经计算获得。
这部分代码的输出如下图:pseud_boxes:list2,tensor(7,4),tensor(4,4)

以上是宏观上,下面从代码层面细细分析一下。
def merge_box(self, bbox_results, proposals_list, proposals_valid_list, gt_labels, gt_bboxes, img_metas, stage):
# 7 42 81 shape of cls is same as ins_scores
cls_scores = bbox_results['cls_score']
ins_scores = bbox_results['ins_score']
num_instances = bbox_results['num_instance']
if stage < 1:
cls_scores = cls_scores.softmax(dim=-1)
else:
cls_scores = cls_scores.sigmoid()
ins_scores = ins_scores.softmax(dim=-2) * proposals_valid_list
ins_scores = F.normalize(ins_scores, dim=1, p=1)
cls_scores = cls_scores * proposals_valid_list
dynamic_weight = (cls_scores * ins_scores)
dynamic_weight = dynamic_weight[torch.arange(len(cls_scores)), :, gt_labels]
cls_scores = cls_scores[torch.arange(len(cls_scores)), :, gt_labels]
ins_scores = ins_scores[torch.arange(len(cls_scores)), :, gt_labels]
# split batch
batch_gt = [len(b) for b in gt_bboxes]
cls_scores = torch.split(cls_scores, batch_gt)
ins_scores = torch.split(ins_scores, batch_gt)
gt_labels = torch.split(gt_labels, batch_gt)
dynamic_weight_list = torch.split(dynamic_weight, batch_gt)
if not isinstance(proposals_list, list):
proposals_list = torch.split(proposals_list, batch_gt)
stage_ = [stage for _ in range(len(cls_scores))]
boxes, filtered_boxes, filtered_scores = multi_apply(self.merge_box_single, cls_scores, ins_scores,
dynamic_weight_list,
gt_bboxes,
gt_labels,
proposals_list,
img_metas, stage_)
pseudo_boxes = torch.cat(boxes).detach()
# mean_ious =torch.tensor(mean_ious).to(gt_point.device)
iou1 = bbox_overlaps(pseudo_boxes, torch.cat(gt_bboxes), is_aligned=True)
### scale mean iou
gt_xywh = bbox_xyxy_to_cxcywh(torch.cat(gt_bboxes))
scale = gt_xywh[:, 2] * gt_xywh[:, 3]
mean_iou_s = iou1[scale < 32 ** 2].sum() / (len(iou1[scale < 32 ** 2]) + 1e-5)
mean_iou_m = iou1[(scale > 32 ** 2) * (scale < 64 ** 2)].sum() / (len(
iou1[(scale > 32 ** 2) * (scale < 64 ** 2)]) + 1e-5)
mean_iou_l = iou1[(scale > 64 ** 2) * (scale < 128 ** 2)].sum() / (len(
iou1[(scale > 64 ** 2) * (scale < 128 ** 2)]) + 1e-5)
mean_iou_h = iou1[scale > 128 ** 2].sum() / (len(iou1[scale > 128 ** 2]) + 1e-5)
mean_ious_all = iou1.mean()
mean_ious = [mean_iou_s, mean_iou_m, mean_iou_l, mean_iou_h, mean_ious_all]
if self.test_mean_iou and stage == 1:
self.sum_iou += iou1.sum()
self.sum_num += len(iou1)
# time.sleep(0.01) # 这里为了查看输出变化,实际使用不需要sleep
print('\r', self.sum_iou / self.sum_num, end='', flush=True)
pseudo_boxes = torch.split(pseudo_boxes, batch_gt)
return list(pseudo_boxes), mean_ious, list(filtered_boxes), list(filtered_scores), dynamic_weight.detach()
loss_mil
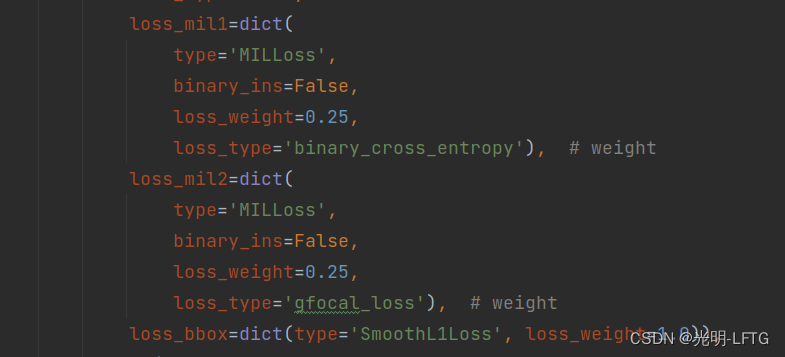
这里stage0只会用到mil1,也就是binary_cross_entropy损失,其实我不是很理解为什么名字为MIL损失,实际代码是把前面生成的42个框的结果加权求和之后,根据分类偏差计算损失。这么一分析好似和mil没有啥关系。
忘掉这些
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)