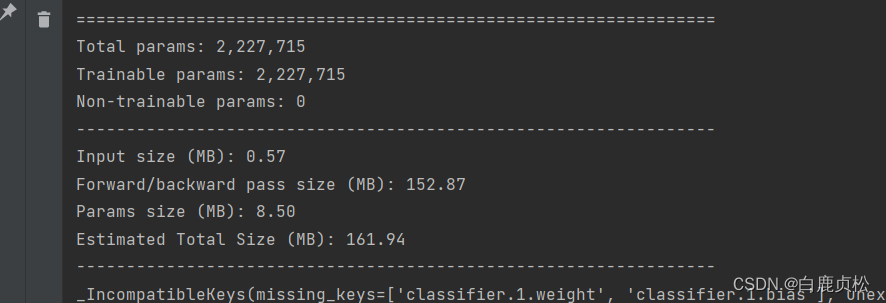
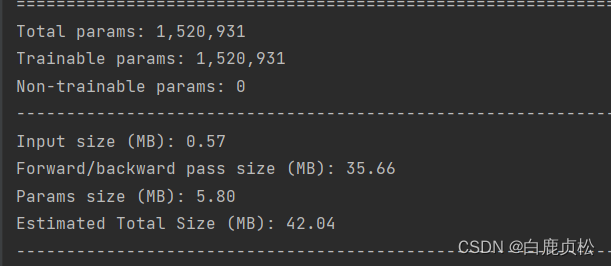
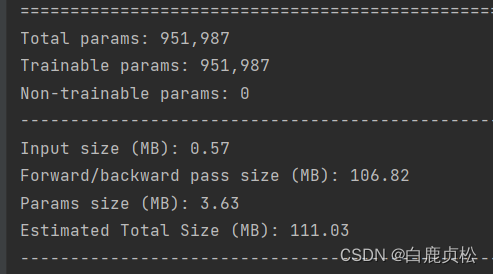
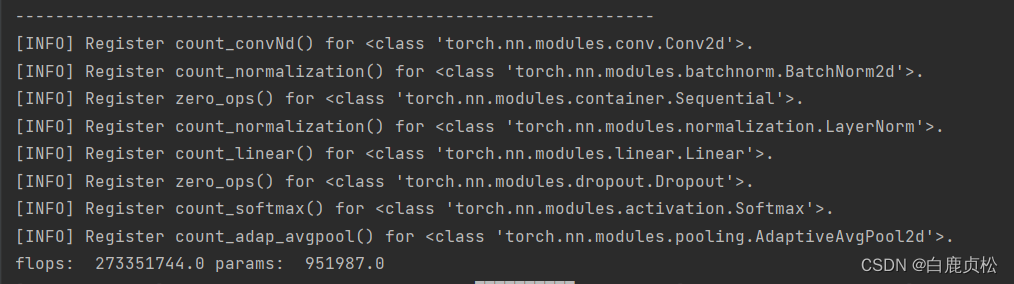
参数大小
MobileViT xxs参数:
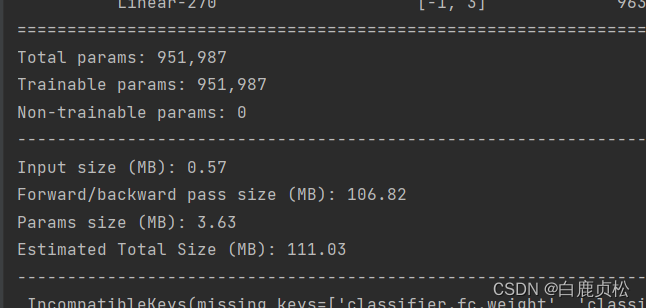
MobileViT xs参数
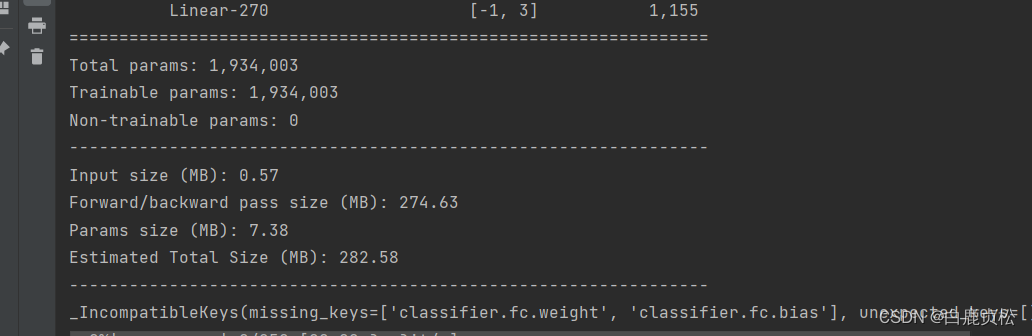
MobileViT s参数
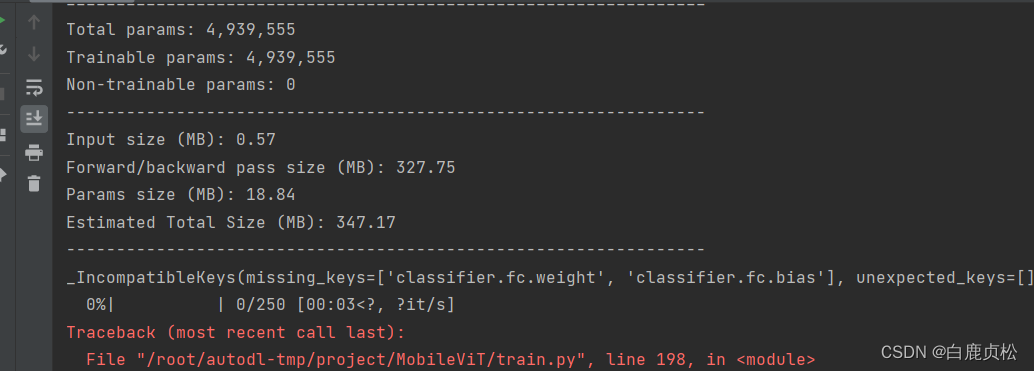
MobileViT+SE模块
无SE模块时
有预训练文件
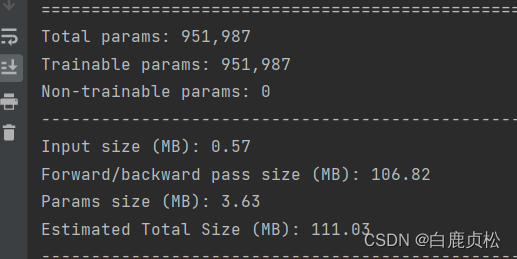
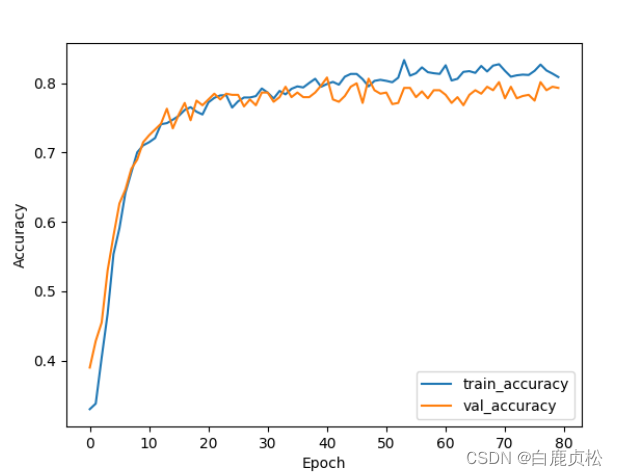
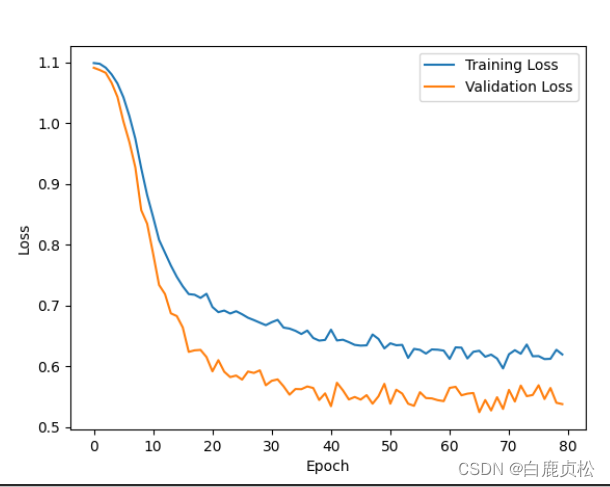
无预训练文件
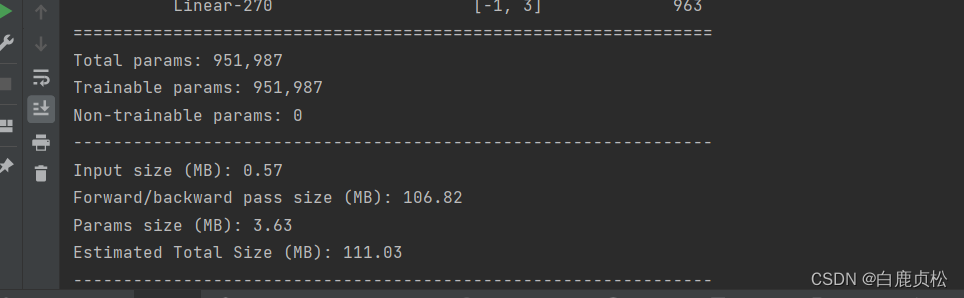
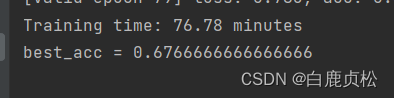
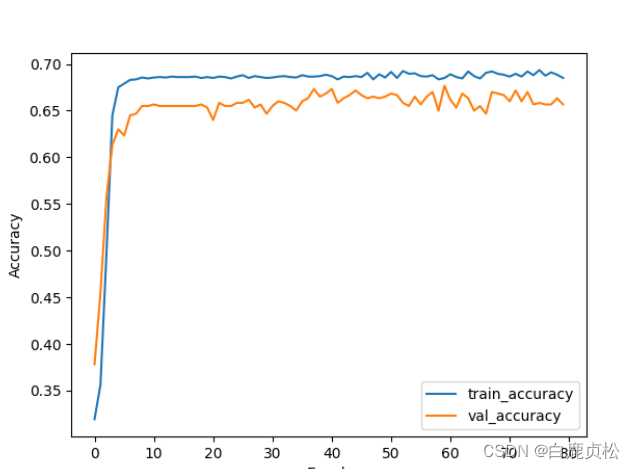

有预训练文件且加SE模块之后:
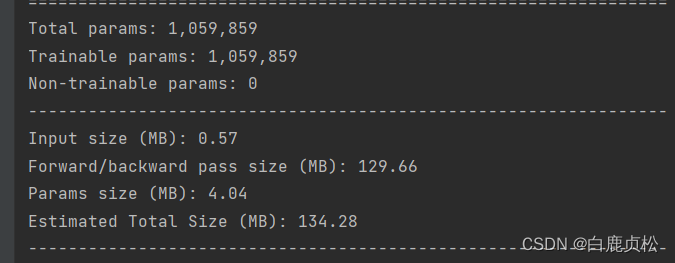
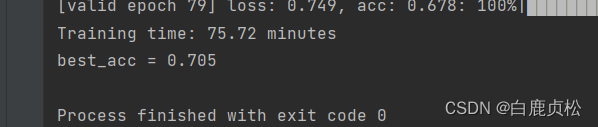
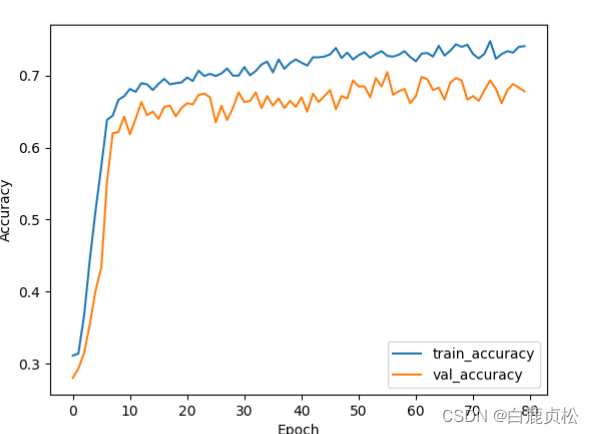
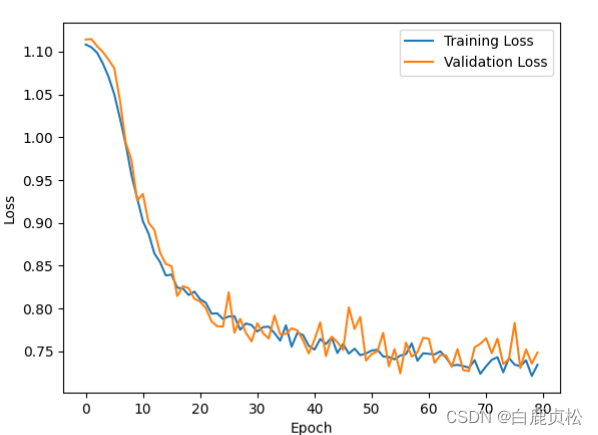
无预训练文件且加了SE模块
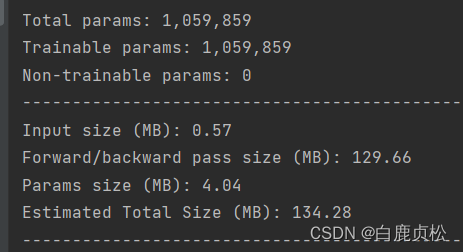
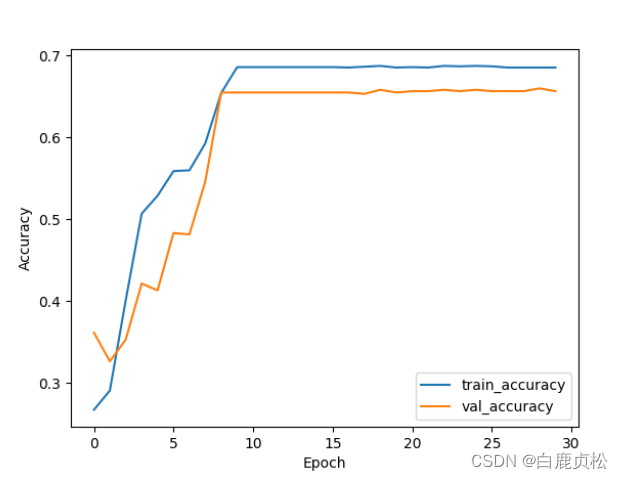
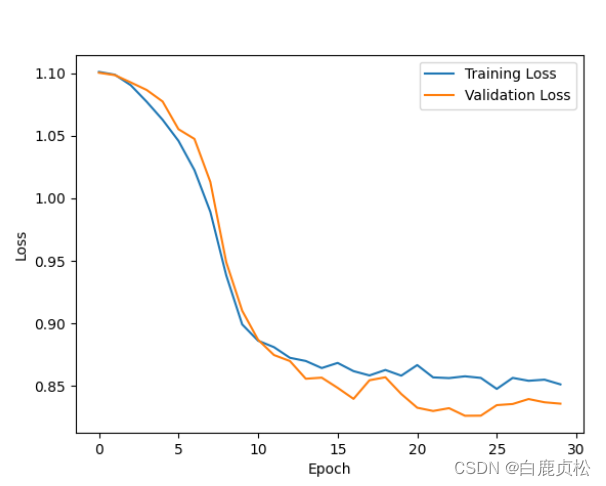
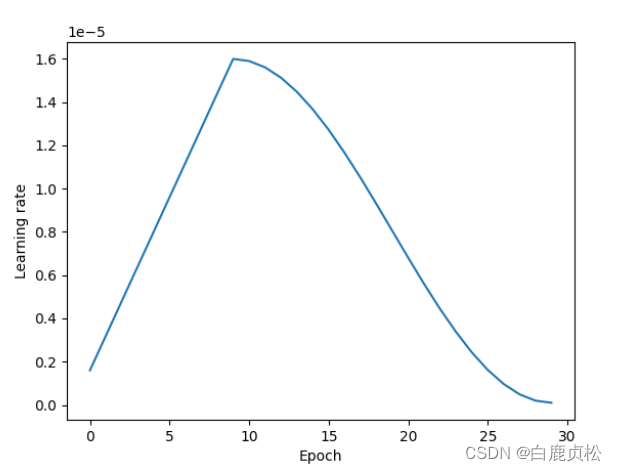
MobileNetv2
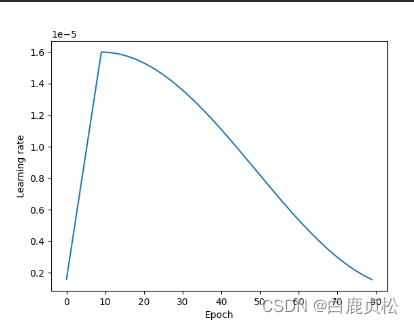
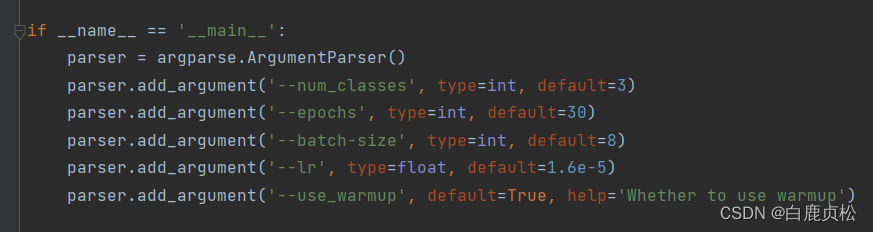
epoch=60 lr=2e-5
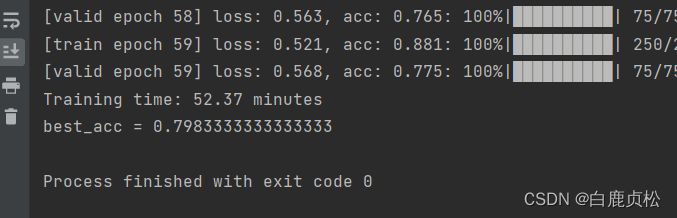
lr=1.6e-5
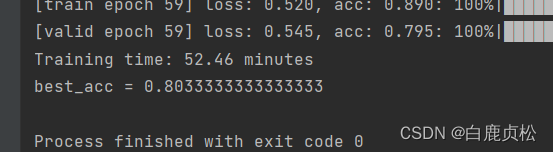
MobileNetv3
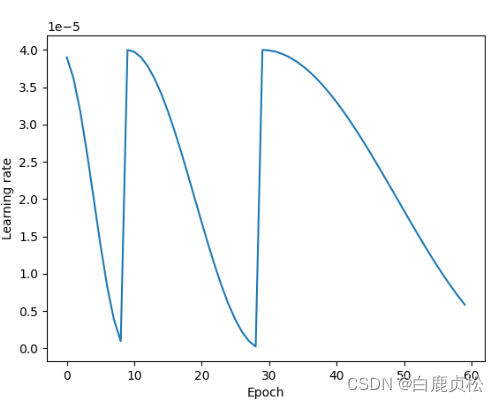
CosineAnnealingWarmRestarts
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,
T_0=10, # init_epoch to change lr
T_mult=2, # times
eta_min=0, # min of lr
last_epoch=-1, # default=-1
)
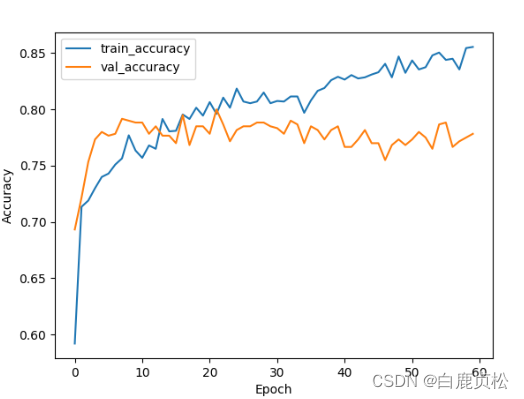
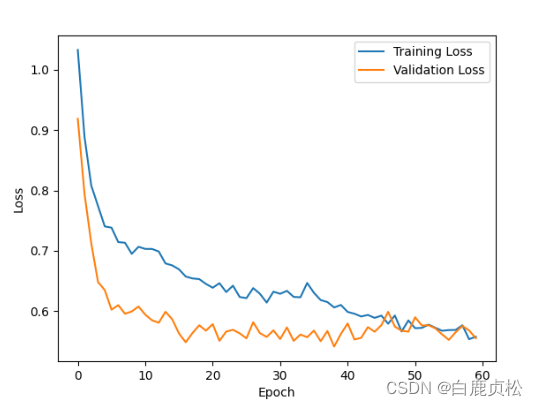
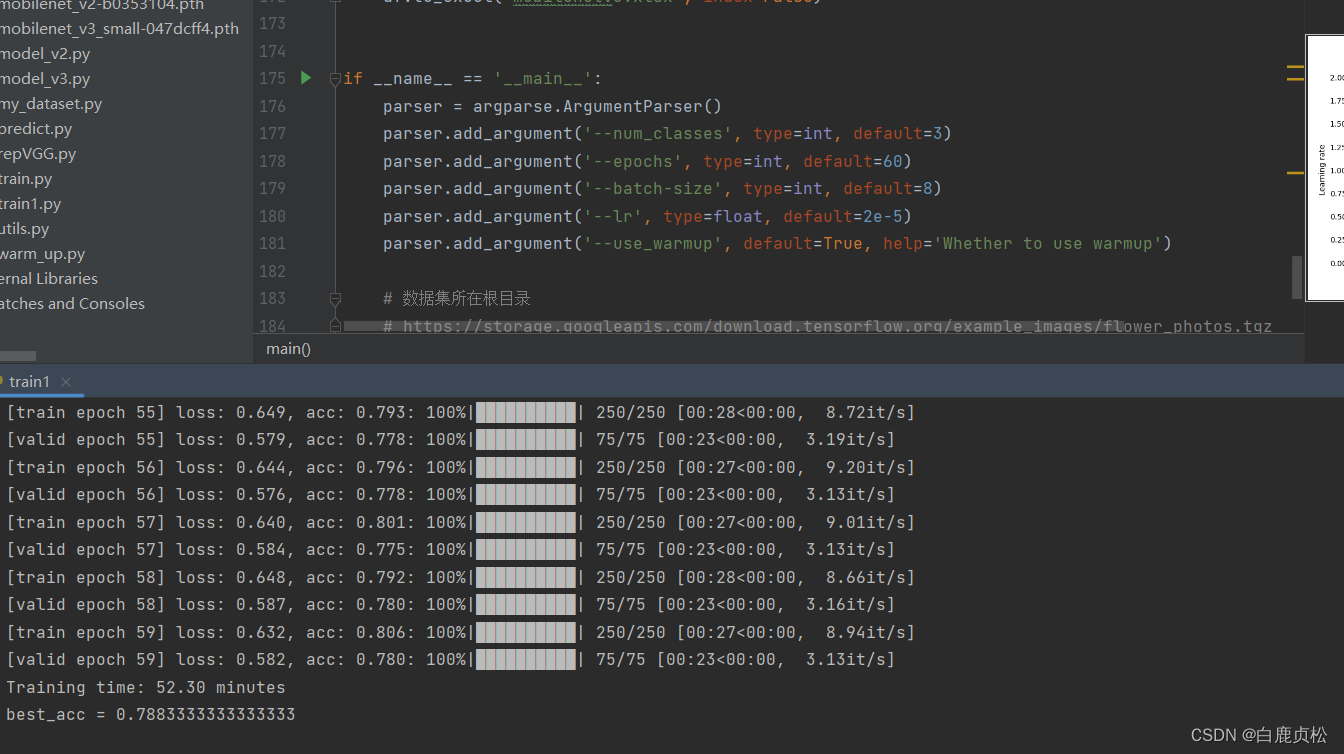
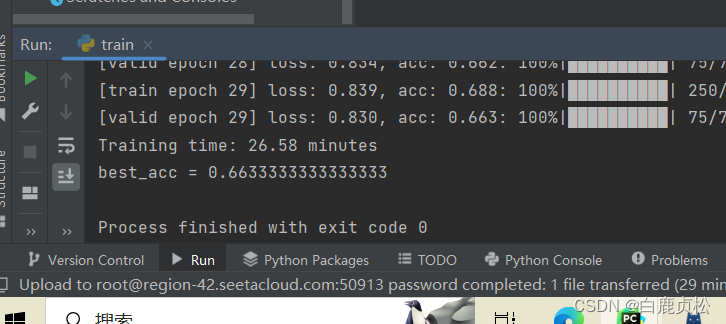
MobileViT 无预训练文件
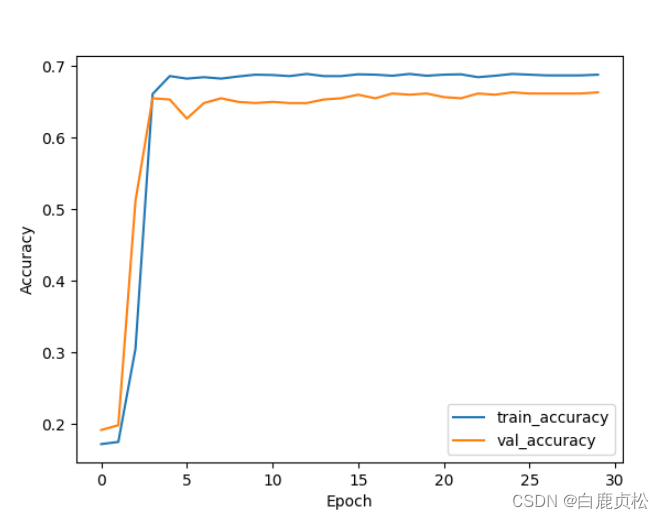
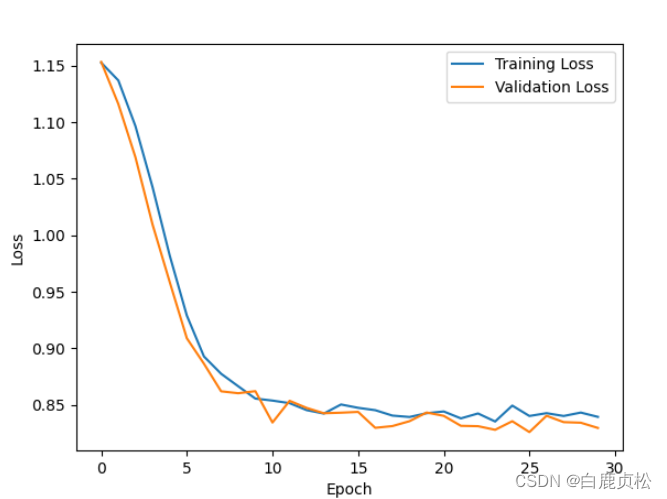
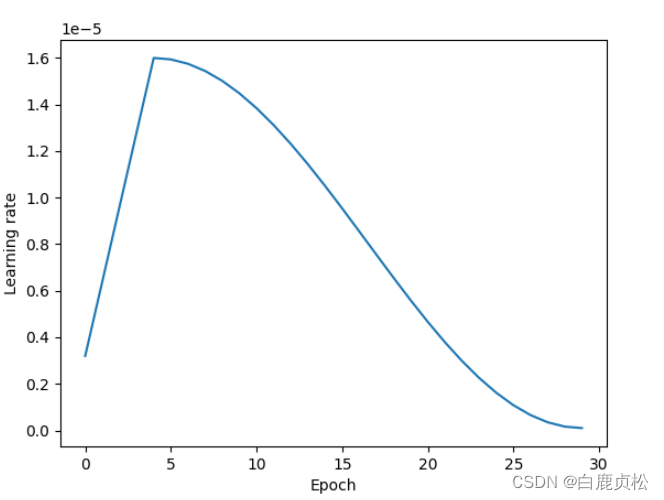
test.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from MobileViT_SE import mobile_vit_small as MobileViT_SE
from MobileViT import mobile_vit_small as MobileViT
from MobileSwin import mobile_vit_small as MobileSwin
import shutil
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
img_size = 224
data_transform = transforms.Compose(
[transforms.Resize(int(img_size * 1.14)),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model load model weights
model = MobileViT(num_classes=3).to(device)
model_weight_path = "./result_weight/MobileViT_S_best.pth"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.eval()
class_name='Seborrheic_keratosis'
# 设置输入和输出文件夹路径
input_folder = "D:\Deep-learning\deep-learning-for-image-processing-master\data_set\skin_data\Test"+'\\'+class_name # 输入文件夹,包含待处理的图片
output_folder = "D:\Deep-learning\deep-learning-for-image-processing-master\data_set\Test"+'\\'+class_name # 输出文件夹,用于存储符合条件的图片
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 遍历输入文件夹中的所有文件
for filename in os.listdir(input_folder):
# 检查图片是否是该类别"
img_path = os.path.join(input_folder, filename)
img = Image.open(img_path)
# plt.imshow(img)
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
id=''
npmax=0
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
if npmax<predict[i].numpy():
npmax=predict[i].numpy()
id=class_indict[str(i)]
print(id)
if id == class_name:
# 构建输入和输出文件的完整路径
input_filepath = os.path.join(input_folder, filename)
output_filepath = os.path.join(output_folder, filename)
# 将符合条件的文件复制到输出文件夹
shutil.copyfile(input_filepath, output_filepath)
print(f"Copied file: {filename}")
if __name__ == '__main__':
main()