1.现代终端设备一般都跟云端服务器相连,但只要可能,我们都希望计算可以在本地终端解决,这样做的好处是多方面的:既可以减小网络带宽的压力,又可以避免网络传输产生的时延,还可以让用户的数据更安全。现代终端设备一般用一个片上系统 (SoC)做计算,上面部署了通用的CPU和集成显卡。对于日益增多的卷积神经网络推理计算来说,在移动端的CPU(多数ARM,少数x86)上虽然优化实现相对简单(参见我们对CPU的优化),但此处它并非最佳选择,因为:1)移动端CPU算力一般弱于集成显卡(相差在2-6倍之间);2)更重要的是,已经有很多程序运行在CPU上,如果将模型推理也放在上面会导致CPU耗能过大或者CPU节流,造成耗电过快同时性能不稳定。所以在移动端进行模型计算,集成显卡是更好的选择,说起来很有道理,但用起来就不一样了。实际中我们发现移动设备上的集成显卡利用率很低,大家并不怎么用它来跑卷积神经网络推理。原因其实很简单:难用。在AWS,我们面对很多移动端机器,里面用到集成显卡多数来自Intel, ARM和Nvidia,编程模型一般是OpenCL和CUDA。虽然对于某些特定模型和算子,硬件厂商提供了高性能库(Intel的OpenVINO, ARM的ACL, Nvidia的CuDNN),但它们覆盖度有限,用起来不灵活,造成即使对单一硬件做多模型的优化,工程代价也很大,遑论我们面对的硬件类种类繁多。总之,要用传统方法在集成显卡上实现一个通用高效的模型推理并不容易。
2.深度学习两大问题,图像分类目标检测(算法专家称是回归),图像分类用来判断物体是什么,目标检测(回归)用来画框。
在图像分类问题中,ResNet,VGG,GoogLeNet,AlexNet等网络呀识别出给定图片中的物体的类别,分类是非常有意义的基础研究问题,但是实际中难以直接发挥作用,因为实际中的图片往往有非常复杂的场景,可能包含几十甚至上百种物体,而图像分类算法处理的图片中只有一个物体,因此实际应用中,不但要检测出一个物体出来,还要框出来,定位,更进一步要把图片中所有的物体都检测出来并框出来,这就是目标检测的使命。
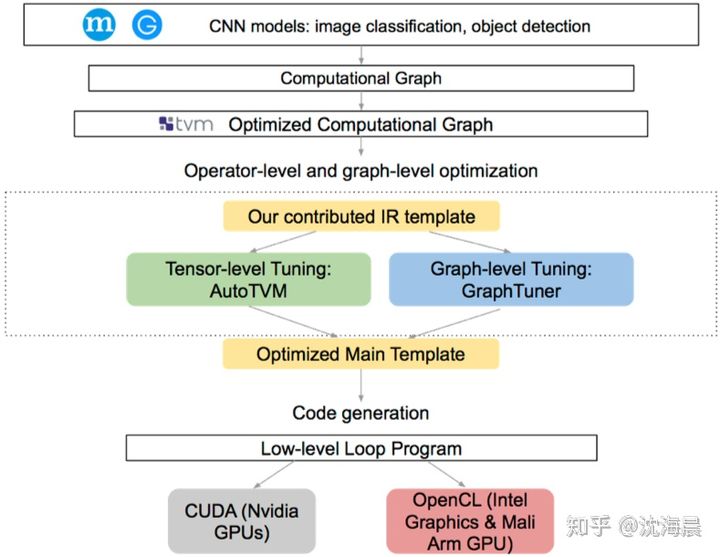
3.AI编译器架构图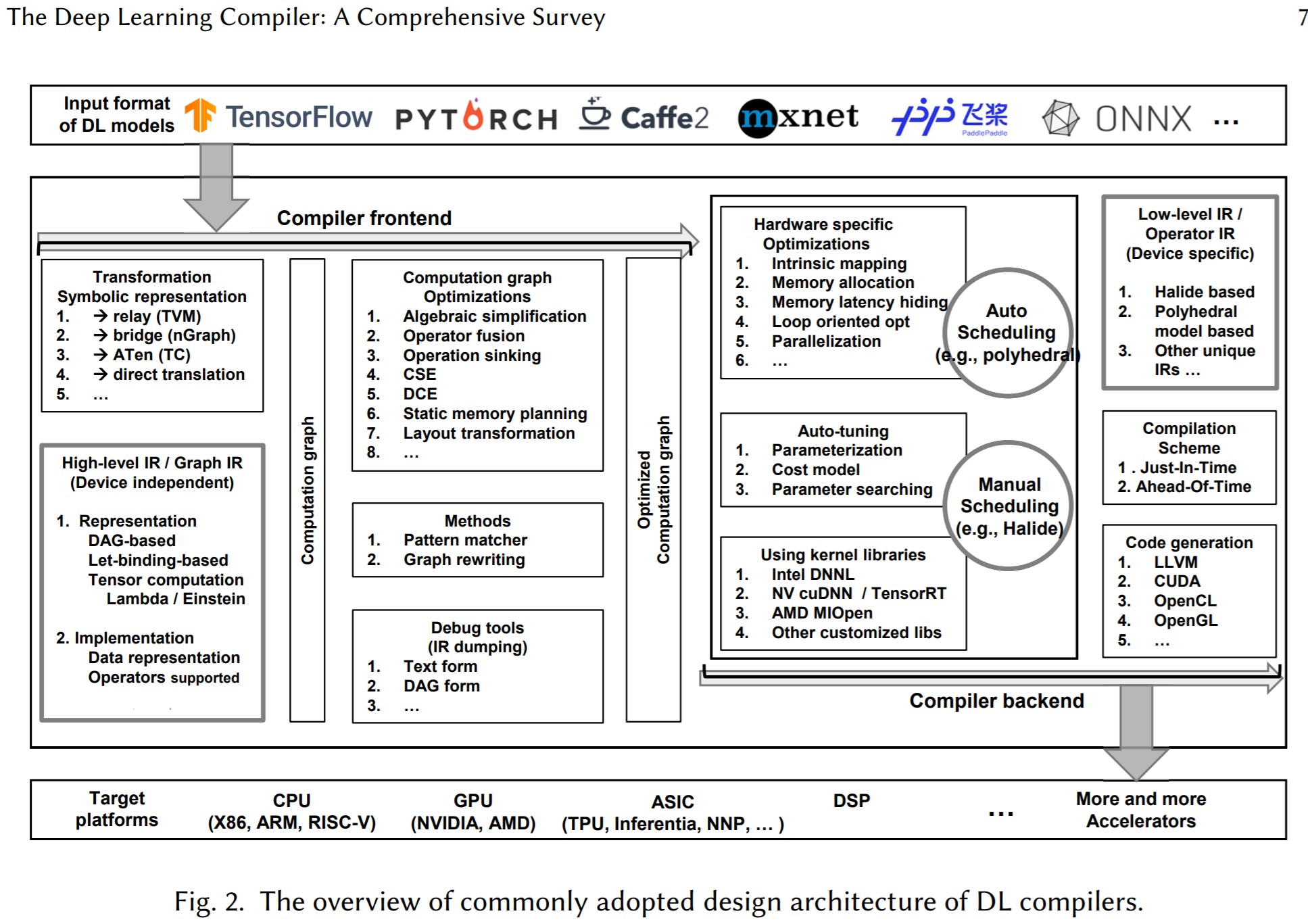
4:


5.深度学习的技术方案:


6.Linux平台上,可以预见,算法跑的时候内核态占用不多,多的是用户态,内核中等NPU中断会睡眠在等待队列中,那么,既然有了NPU,为何还需要用户态算法库呢,为什么软件上还要做算法,答案是,软件上做算法是为NPU做数据前处理或者后处理,这部分算法要求的算力比重于NPU相比很小,主要是做格式转换,reshape之类,归一化操作,均值,方差类操作,以及浮点的像素操作,图片分辨率很小,一般300*200够用了。
7.NPU运行的结果是以什么形式给到用户的? 比如,一张图片做物体检测,那输出应该是坐标位置,这些坐标位置是存储在NPU的寄存器中吗还是哪里?
回答是,网络有个输出buffer,结果存放在里面。
8.卷积网络是指那些至少再网络的一层中使用卷积运算来替代一般的矩阵乘法运算的神经网络。
9:

10:CUDA和OpenCL以及硬件平台之间的关系。

11:内存级

12: 什么是IC数字设计中的数据反压?
以VIPP为例,就是VIPP模块从DDR 要参数, 发送请求后,DDR回数据,VIPP必须接收,如果不接收,数据就丢了,这叫不支持反压。
所谓支持反压,意思是说,别人给我数据,我可以告诉他我没有准备好,那么等我准备好后数据再给我,数据不会丢。
CPU 访问寄存器,我是可以晚些响应的,他会等我。 但是MBUS(就是和DDR交互的)的数据,是不等slave(下家)是否准备好的,他认为你问他要数据了,你一定是准备好的
就是说不支持反压,源端发送的数据必须要接受,不接受就丢了.反压的话,就是两家可以商量
一个是强买强卖,要给是友好协商.对吧?
当入口流量大于出口流量,这时候就需要反压,或者,当后级未准备好时,如果本级进行数据传递,那么它就需要反压前级,所以此时前级需要将数据保持不动,直到握手成功才能更新数据。而反压在多级流水线中就变得稍显复杂,原因在于,比如我们采用三级流水设计,如果我们收到后级反压信号,我们理所当然想反压本级输出信号的寄存器,但是如果只反压最后一级寄存器,那么会面临一个问题,就是最后一级寄存器数据会被前两级流水冲毁,导致数据丢失,引出数据安全问题,所以我们此时需要考虑反压设计。


也可以参考这篇文章了解反压:
数字芯片设计——握手与反压 - 知乎
13: 卷积运算一个output channel(输出通道)一个bias.
14: OpenVX

15:获取数据,清晰数据,训练模型,测试模型,投入使用.
16:机器人分类:

17:问:我看书上说,卷积神经网络缺乏可解释性,我的理解是运行结果有一些撞大运的味道,只是经过训练的网络,撞大运的概率高,可以这样理解吗?
答: 是的
再问:会没有有这种情况,对于一张识别准确率达到%99的图片,可能会存在一些暗点,如果将这些暗点的像素修改,即便是人眼看不出区别,网络的结果也会发生巨大变化?
回答:是的!
所以,总体看来,感觉AI这东西有点不靠谱,消费电子还好,如果涉及到人命关天的事情,还是靠不住,虽然Resnet的识别结果已经超越人类,但人类可以容忍自己的错误,却无法容忍机器犯错。不过生活中的应用足够了,至少,孩子问你路边的花花草草叫啥名啊,也不至于答不上来。
18.对NPU的一些认识:
一颗AI芯片的算力只是基础,再加上
1.算子支持的覆盖度
2.算法移植的友好度
3.量化反量化能力
4.编译器对网络的fuse及针对自身NPU优化
5.NPU和CPU之间数据共享能力
6.CPU对网络的前后处理性能
等因素结合起来才能真的称为更好的AI芯片。
19:一张有目标的图片和一张没有目标的图片,网络运行时间是一样的吗?每一层的计算都会执行的.
嗯,是一样的,除了后处理部分,检测不到目标就不用往后做后处理(分析出框的位置之类),
网络运行时间几乎是一样的,无论有没有目标,网络运行的时间都是一样的,区别在于后处理部分(检测的结果赋值到目标空间中),但是这块几乎不怎么耗时。
20:AlexNet学习出来的特征是什么样子的?
- 第一层:都是一些填充的块状物和边界等特征
- 中间层:学习一些纹理特征
- 更高层:接近于分类器的层级,可以明显的看到物体的形状特征
- 最后一层:分类层,完全是物体的不同的姿态,根据不同的物体展现出不同姿态的特征了。
即无论对什么物体,学习过程都是:边缘→部分→整体,这个和我们人类的学习,认识过程是类似的,对于新鲜的事物,先拿起来,捧在手里看一看,有总体的轮廓上的认识,然后在敲一敲,拆一拆,分解一下,了解它的组成部门,每个部分的工作原理,最后在把东西拼成完整的整体,进而形成了一个统一的认识。
21:关于CONV3-512的表达解释,可以看下图:

22:神经网络学习过程本质就是为了学习数据分布.
23:

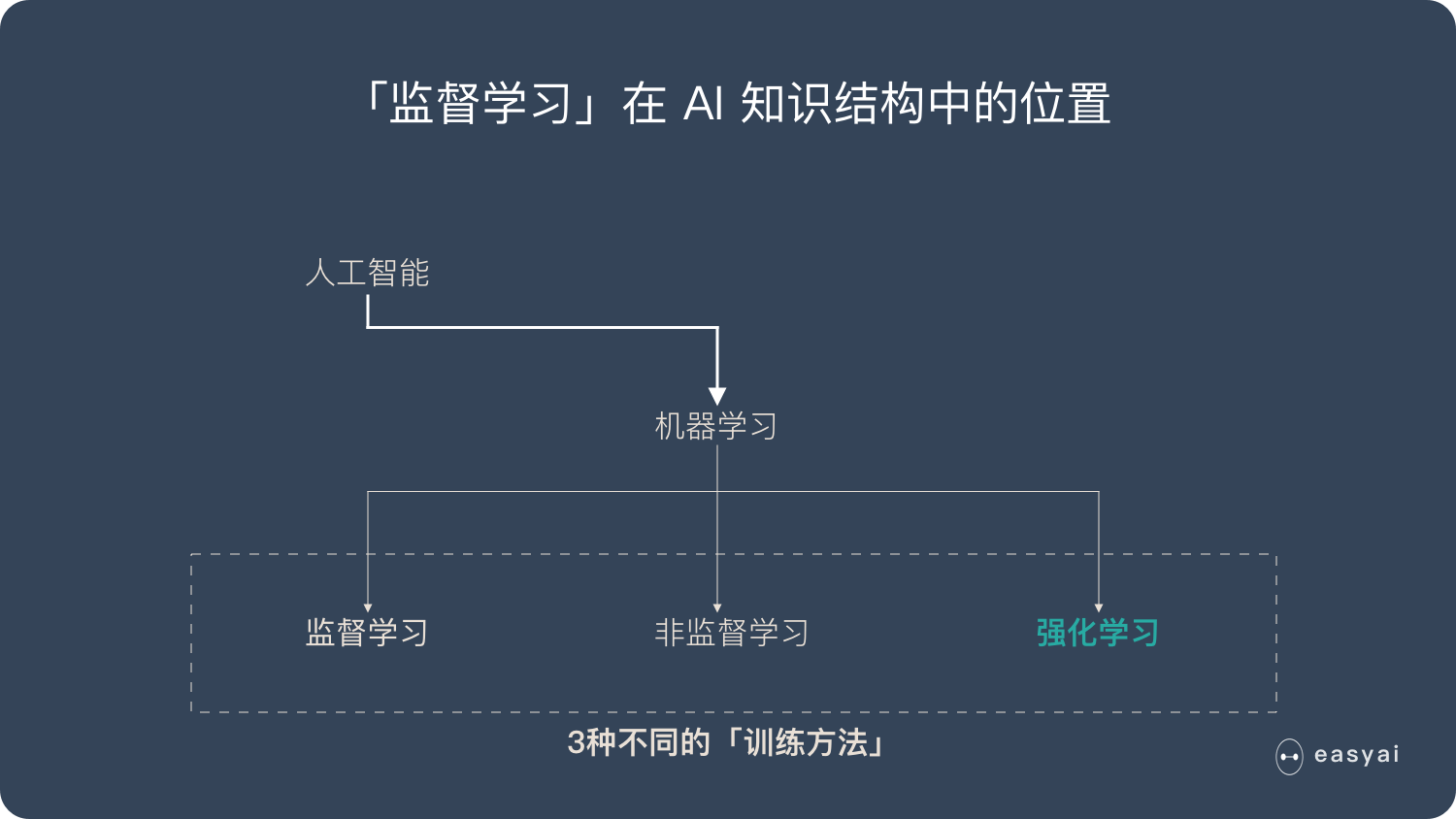
监督学习 (Supervised Learning): 这应当是应用最多的领域了,例如人脸识别,我提前先给你大量的图片,然后告诉你当中哪些包含了人脸,哪些不包含,你从我给的照片中总结出人脸的特征,这就是训练过程。最后我再提供一些从来没有见过的图片,如果算法训练得好的话,就能很好的区分一张图片中是否包含人脸。所以监督学习最大的特点就是有训练集,告诉模型什么是对的,什么是错的。
非监督学习 (Unsupervised Learning): 例如网上购物的推荐系统,模型会对我的浏览记录进行分类,然后自动向我推荐相关的商品。非监督学习最大的特点就是没有一个标准答案,比如水杯既可以分类为日用品,也可以分类为礼品,都没有问题。
强化学习 (Reinforcement Learnong): 强化学习应当是机器学习当中最吸引人的一个部分了,例如 Gym 上就有很多训练电脑自己玩游戏最后拿高分的例子。强化学习主要就是通过试错 (Action),找到能让自己收益最大的方法,这也是为什么很多都例子都是电脑玩游戏。
分类 (Classification): 例如手写体识别,这类问题的特点在于最后的结果是离散的,最后分类的数字只能是 0, 1, 2, 3 而不会是 1.414, 1.732 这样的小数。
回归 (Regression): 例如经典的房价预测,这类问题得到的结果是连续的,例如房价是会连续变化的,有无限多种可能,不像手写体识别那样只有 0-9 这 10 种类别。
这样看来,接下来介绍的手写体识别是一个 分类问题。但是做分类算法也非常多。
人工神经网络 (Artifitial Neural Network):这是个比较通用的方法,可以应用在各个领域做数据拟合,但是像图像和语音也有各自更适合的算法。
卷积神经网络 (Convolutional Neural Network):主要应用在图像领域,后面也会详细介绍。
循环神经网络 (Recurrent Neural Network):比较适用于像声音这样的序列输入,因此在语言识别领域应用比较多。
24:机器学习的原理/思路,让机器产生规则



25:关于数据集的逻辑

27:卷积神经网络结构

28:基因决定上限,读书决定下限. 模型决定了上限,数据决定下限.
人消化能力强,几张图片就训练好了,模型胃口大,吃成千上万张图片,才能训练好。
29:输出层所用的激活函数,要根据求解问题的性质决定,一般回归问题用恒等函数,二元分类问题可以使用sigmoid函数,多元分类问题问题可以使用softmax函数.
输出层神经元的数量,需要根据待解决的问题决定,对于分类问题,输出层神经元的数量一般为类别的数量,比如,对于某个图像,预测它是0到9中哪个的问题,10类别分类问题,可以设定输出神经元的数量为10个。
30:神经网络里面,算法即模型,模型即算法,算法训练好之后会保存为模型何权重,模型之外还会有一些前后处理。
31:饼的画法-商汤饼

32:TVM is what?
这是一个试图一统AI框架前端到不同NNA加速器的设计框架,原理和思想和GCC, LLVM等想通,可以参考,
官网文档在:Introduction — tvm 0.8.dev0 documentation https://tvm.apache.org/docs/tutorial/introduction.html#sphx-glr-tutorial-introduction-py
https://tvm.apache.org/docs/tutorial/introduction.html#sphx-glr-tutorial-introduction-py

33:目标检测,物体检测,object detection, od
这几个概念是等价的,他们都等价于what and where?
what? 识别, recognition. 分类问题。
Where? 定位,localization.回归问题。
34:关于卷积核的形状,可以这样理解:
shape=[batch_size,width,height,channels]
35:方舟编译器的架构

36:强化学习.
37:卷积到底卷了啥
38:OCR

39:所有的机器学习模型都是错误的,但是它也是有用的,机器学习忽略了因果推理,由果推因。
40:归一化自适应滤波(NLMS)和自适应滤波(LMS)
41:
问:有些手机芯片上,有ARM提供的很强大的通用算力,包括NEON指令集,VFP指令集对算法进行加速,可是为什么一般还会集成一个类似HIFI5这样的DSP,从算力角度来讲,ARM的应该是够的吧。DSP的浮点精度是不是比NEON这些要高一些,音频,音质对计算的精度可能会高.
答:很多都是异构结构,各自有自己的专长,dsp可以做语音的一系列业务,相对ARM来说功耗低算力不差arm,而且也不占用arm的处理器资源,arm处理器可以做其他的业务(arm的处理业务总量是有限的,别的处理器分担了一些,arm就能做更多其他的事,性能也能上去)。精度不会差吧,单精度,dsp可能比arm多双精度(我没注意),应该都是32位、16位浮点吧,只是整点mac arm较neon,处理能力会强,hifi5的mac能力比arm的强,ai性能是要更好的
问:嗯,那么手机上放HIFI5,是为了功耗? 算力其实AP已经能够cover了么
答:应该是的,hifi5的能效比是比arm的好的
问:嗯嗯,可能整体上,DSP的算力功耗比要比ARM强
我们现在其实还没有很好的用起来,方案上还没落地应该,之前hifi4也没有用起来?
答:用起来指的是哪方面?我记得HIFI4在linux & freertos 双系统上,是跑音频解码算法的,
而且也没有吧整个音频的业务交到dsp上去处理吧
答:嗯,这个是没有,框架设计没有吧DSP的优势凸显出来,而且双核通信业务这块,没有标准做法,我们的做法效率不是很高
是啊,就异构之间的通信效率提升你们有什么好的方法和途径不?这个未来应该是要研究的,xPU不是你们的专题吗
嗯,是有团队在负责专题,后面异构算力是趋势,绕不开,V853也是异构算例
42:关于GPU的工作原理:
GPU就是用很多简单的计算单元去完成大量的计算任务,纯粹的人海战术。这种策略基于一个前提,就是小学生A和小学生B的工作没有什么依赖性,是互相独立的。
但有一点需要强调,虽然GPU是为了图像处理而生的,但是我们通过前面的介绍可以发现,它在结构上并没有专门为图像服务的部件,只是对CPU的结构进行了优化与调整,所以现在GPU不仅可以在图像处理领域大显身手,它还被用来科学计算、密码破解、数值分析,海量数据处理(排序,Map-Reduce等),金融分析等需要大规模并行计算的领域。
43:CPU和GPU的类比

44:inception的核心就是把google net的某一些大的卷积层换成1*1, 3*3, 5*5的小卷积,这样能够大大的减小权值参数数量。直接上一张完整的图片,比方说这一层本来是一个28*28大小的卷积核,一共输出224层,换成inception以后就是64层1*1, 128层3*3, 32层5*5。这样算到最后依然是224层,但是参数个数明显减少了,从28*28*224 = 9834496 变成了1*1*64+3*3*128+5*5*32 = 2089,减小了几个数量级。
再上一张形象的图:
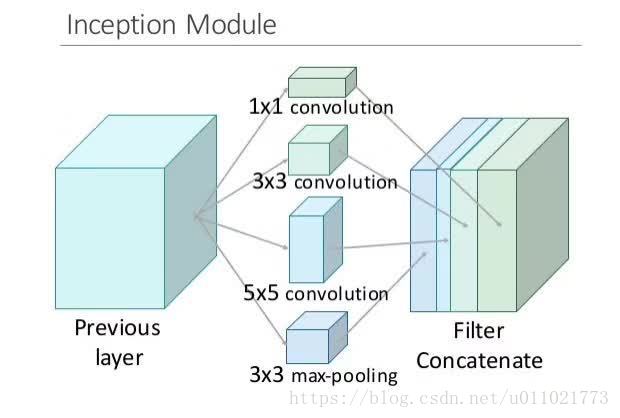
为什么不直接使用1*1的,而还需要3*3和5*5的呢,其实这样还是为了适应更多的尺度,保证输入图像即使被缩放也还是可以正常工作,毕竟相当于有个金字塔去检测了嘛。
这样输入图片的分辨率大小发生变化,也不影响识别效果,对精确度的影响降到最低。

45:在半导体行业,只要批量足够大,芯片的价格都将趋向于沙子的价格。据传闻,正是由于该公司不肯给「沙子的价格」 ,才选择了另一家公司。当然现在数据中心领域用两家公司 FPGA 的都有。只要规模足够大,对 FPGA 价格过高的担心将是不必要的。
46:寒武纪架构