
需要云服务器等云产品来学习Linux的同学可以移步/-->腾讯云<--/-->阿里云<--/-->华为云<--/官网,轻量型云服务器低至112元/年,新用户首次下单享超低折扣。
目录
一、C/C++内存区域划分
二、常见变量存储区域
三、new和delete
1、new和delete的使用方式
2、new、delete和malloc、free的区别
3、new的原理
4、delete的原理
5、new T[N]原理
6、delete[]原理
四、定位new
1、定位new的概念
2、定位new的使用格式
3、定位new的使用场景
五、泛型编程
六、函数模板
1、函数模板的使用
2、不同类型形参传参时的处理
2.1传参时强转(对应形参需要const修饰)
2.2显式实例化(传参时隐式类型转换,对应形参需要const修饰)
2.3使用多个模板
3、模板和实例可以同时存在,编译器会优先调用实例
七、类模板
1、对象定义时需要显式实例化
2、为什么stl被称为模板
3、类模板不支持声明和定义分离
八、非类型模板参数
九、模板的特化
1、函数模板特化
2、类模板的特化(应用场景:对仿函数的特化)
2.1全特化
2.2半特化(偏特化)
十、模板的优缺点
1、优点
2、缺点
一、C/C++内存区域划分

1. 栈又叫堆栈--非静态局部变量/函数参数/返回值等等,栈是向下增长的。
2. 内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享共享内存,做进程间通信。
3. 堆用于程序运行时动态内存分配,堆是可以上增长的。
4. 数据段--存储全局数据和静态数据。
5. 代码段--可执行的代码/只读常量。
二、常见变量存储区域
int globalVar = 1;//全局变量中在静态区
static int staticGlobalVar = 1;//静态区
void Test()
{
static int staticVar = 1;//静态区
int localVar = 1;//栈区
int num1[10] = { 1, 2, 3, 4 };//栈区
char char2[] = "abcd";//栈区,*char2在栈区
const char* pChar3 = "abcd";//指针在栈区,*pchar3在常量区
int* ptr1 = (int*)malloc(sizeof(int) * 4);//指针在栈区,*ptr1在堆区
int* ptr2 = (int*)calloc(4, sizeof(int));///栈区
int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4);//栈区
free(ptr1);
free(ptr3);
}
三、new和delete
1、new和delete的使用方式
int main()
{
int* p1 = new int;//在堆区申请一个int大小的空间,不会初始化
int* p2 = new int(0);//申请并初始化为0
delete p1;
delete p2;
int* p3 = new int[10];//在堆区申请一块10个int大小的空间,未初始化
int* p4 = new int[10]{ 1,2,3,4 };//初始化为{1,2,3,4,0,0,0,0,0,0}
delete[] p3;
delete[] p4;
return 0;
}
注意:申请和释放单个元素的空间,使用new和delete操作符,申请和释放连续的空间,使用new T[]和delete[],一定要匹配起来使用。

vs中,类中显式写了析构函数,编译器认为这个类有资源,会在申请的空间之前再申请一小块空间,用于存储对象个数等信息,当new T[]和delete不匹配时,会少释放记录位,造成内存泄漏并报错。当类中不显示写析构函数时,将不会有记录位,不会造成内存泄漏和报错。当然每个编译器底层实现原理不同,中断代码在不同的平台会出现不同的后果,总之匹配使用就对了。
2、new、delete和malloc、free的区别
1、对于内置类型,没有区别。
2、new和delete是C++的关键字/操作符,而malloc和free是C语言的库函数。
3、对于自定义类型,相比于malloc和free,new和delete会额外调用类中的构造函数和析构函数。
4、malloc的返回值是void*,使用时需要强转,new后边跟的是空间的类型,所以new不需要强转。
5、malloc失败返回空指针,需要判空;new失败抛异常,需要捕获异常。
3、new的原理
new等于operator new()+构造函数。operator new()不是new运算符的重载,因为参数没有自定义类型。它是一个库里的全局函数。
void *__CRTDECL operator new(size_t size) _THROW1(_STD bad_alloc)
{
// try to allocate size bytes
void *p;
while ((p = malloc(size)) == 0)
if (_callnewh(size) == 0)
{
// report no memory
// 如果申请内存失败了,这里会抛出bad_alloc 类型异常
static const std::bad_alloc nomem;
_RAISE(nomem);
}
return (p);
}
从底层代码可以看出operator new()是对malloc的封装,如果malloc失败,将会抛出异常。
4、delete的原理
delete等于operator delete()+析构函数
//operator delete: 该函数最终是通过free来释放空间的
void operator delete(void *pUserData) {
_CrtMemBlockHeader * pHead;
RTCCALLBACK(_RTC_Free_hook, (pUserData, 0));
if (pUserData == NULL)
return;
_mlock(_HEAP_LOCK); /* block other threads */
__TRY
/* get a pointer to memory block header */
pHead = pHdr(pUserData);
/* verify block type */
_ASSERTE(_BLOCK_TYPE_IS_VALID(pHead->nBlockUse));
_free_dbg( pUserData, pHead->nBlockUse );//调用free()
__FINALLY
_munlock(_HEAP_LOCK); /* release other threads */
__END_TRY_FINALLY
return; }
//free的实现
#define free(p) _free_dbg(p, _NORMAL_BLOCK)
从底层代码可以看出operator delete()调用了free。
所以针对内置类型或无资源的类对象delete时,使用delete和free效果相同。但对于有资源需要释放的对象时,直接使用free虽然释放了对象的空间,但对象内部的资源还未被清理,导致内存泄漏!这种情况必须使用delete。
5、new T[N]原理
1、new T[N]调用operator new[]
2、operator new[]调用operator new完成N个对象空间的开辟。
3、调用N次构造函数完成N个对象的初始化。
6、delete[]原理
1、调用N次析构函数完成N个对象资源的清理工作。
2、调用operator delete[]
3、operator delete[]调用operator delete完成整段空间的释放。
四、定位new
1、定位new的概念
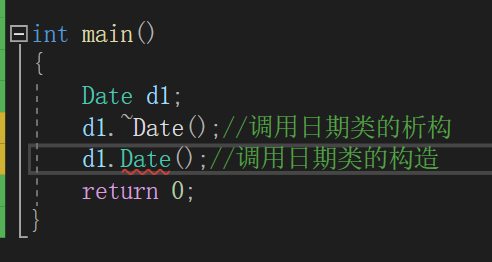
对于一个类,我们可以显式的去调用类的析构函数,但是不能显式调用构造函数,那么使用定位new,就可以显式调用类的构造函数,对一块空间重新初始化。
2、定位new的使用格式
new (指针)类名或者new (指针) type(初始化列表)
int main()
{
Date d1;
new(&d1)Date;//new (指针)类名
Date* p = new Date[4]{ {2022,10,15},{2023,11,8} };
new(p)Date[4];//new (指针) type(初始化列表)
delete[] p;
return 0;
}
上述代码一共调用了10次构造函数,经过定位new的处理,d1和p所代表的空间已经被重新初始化了。
3、定位new的使用场景
一般不会像上边代码一样,对一块已有对象数据的空间重新初始化。定位new表达式在实际中一般是配合内存池使用。因为内存池分配出的内存没有初始化,对于自定义类型的对象,可以使用定位new对这些没有被初始化的内存显式调用类的构造函数初始化。
五、泛型编程
泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。

模板分为函数模板和类模板
六、函数模板
1、函数模板的使用
template<typename T>
void Swap(T& a, T& b)
{
T tmp = a;
a = b;
b = tmp;
}
int main()
{
int a = 10, b = 5;
double m = 2.3, n = 4.9;
Swap(a, b);
Swap(m, n);
return 0;
}
两个Swap调用的不是模板,而是模板生成的实例化函数,像上述代码中,模板会生成int和double类型的两种实例化函数。
2、不同类型形参传参时的处理
2.1传参时强转(对应形参需要const修饰)
template<typename T>
T Add(const T& a,const T& b)//const接收常性实参
{
return a + b;
}
int main()
{
int a = 10, b = 5;
double m = 2.3, n = 4.9;
Add(a, (int)m);//强转,临时变量传参,具有常性
return 0;
}
使用强制类型转换在推演的时候将形参转换成同一类型。
2.2显式实例化(传参时隐式类型转换,对应形参需要const修饰)
template<typename T>
T Add(const T& a, const T& b)//需要使用const接收
{
return a + b;
}
int main()
{
int a = 10, b = 5;
double m = 2.3, n = 4.9;
Add<int>(a, m);//显式实例化,m发生隐式类型转换
return 0;
}
显式实例化编译器不再去推演T的类型,而是直接使用尖括号内的类型实例化对应函数。
2.3使用多个模板
template<typename T1,class T2>//可以写typename也可以写class
T1 Add(const T1& a, const T2& b)
{
return a + b;
}
int main()
{
int a = 10, b = 5;
double m = 2.3, n = 4.9;
Add(a, m);//Add<int,double>(a,m);多个模板的手动推演
return 0;
}
3、模板和实例可以同时存在,编译器会优先调用实例
template<typename T>//可以写typename也可以写class
T Add(const T& a, const T& b)
{
return a + b;
}
int Add(const int& a, const int& b)
{
return a + b;
}
int main()
{
int a = 10, b = 5;
double m = 2.3, n = 4.9;
Add(a, m);//调用已有实例
Add<int>(a, m);//调用模板生成的实例
return 0;
}
1、模板和普通函数的函数名修饰规则是不一样的。
2、模板和实例可以同时存在,编译器会优先调用实例。如果想使用模板生成的实例,必须使用尖括号指定类型。
3、如果模板可以生成更加匹配的版本,编译器将会生成这个匹配版本而不是使用那个已有但不太匹配的实例。
七、类模板
1、对象定义时需要显式实例化
int main()
{
Stack<double> st1; // double
st1.Push(1.1);
Stack<int> st2; // int
st2.Push(1);
return 0;
}
函数模板可以通过传参确定T的类型,但是类模板编译器无法推演,必须要在对象定义时显式实例化类型。
模板参数不同,他们就是不同的类型。st1和st2属于不同的类定义出的两个对象。所以不能有st1=st2,因为他们不是同一个类,除非针对这种赋值,自己写一个赋值重载。
2、为什么stl被称为模板
类模板和函数模板不同,需要在实例化的时候在类名后加上<类型>。
类模板不是真正的类,而实例化出来的才是真正的类。
// Vector是类模板,Vector<int>才是类型
Vector<int> s1;
Vector<double> s2;
3、类模板不支持声明和定义分离
template<typename T>
class Stack
{
public:
Stack(int capacity = 4);
~Stack();
void Push(const T& x);
private:
T* _a;
int _top;
int _capacity;
};
//成员函数的定义
template<class T>
Stack<T>::Stack(int capacity = 4)
{
cout << "Stack(int capacity = )" << capacity << endl;
_a = (T*)malloc(sizeof(T)*capacity);
if (_a == nullptr)
{
perror("malloc fail");
exit(-1);
}
_top = 0;
_capacity = capacity;
}
template<class T>
Stack<T>::~Stack()
{
cout << "~Stack()" << endl;
free(_a);
_a = nullptr;
_top = _capacity = 0;
}
template<class T>
void Stack<T>::Push(const T& x)
{
// ....
_a[_top++] = x;
}
类模板和其成员函数不支持声明和定义分离。因为类模板和函数模板都不是真正的定义,真正的定义是在模板实体化的时候由编译器完成。如果将模板的定义部分和实现部分分离开来,编译器真正要去完成模板实体化的时候就会因为找不到相应的代码而发生链接错误。
解决方法:
1、模板定义的位置显式实例化
template class stack<int>;//需要在定义的地方手动指明实例化的类型
2、声明和定义不分离,全部放到一个.hpp或.h的文件下。
八、非类型模板参数
想要生成两个Array对象,C语言只能使用宏定义的方式确定N的大小,但这样生成的对象的N的大小都是一样的。
C++可以在模板中使用非类型模板参数,生成的Array对象中的N可以任意指定。
//#define N 10//C语言玩法
template <class T,size_t N=10>//T是类型模板参数,N是非类型模板参数
class Array
{
private:
T _arr[N];
};
int main()
{
Array<int, 20> a1;
Array<double, 100> a2;
return 0;
}
不过非类型模板参数只支持整型常量,浮点型、变量、类对象等都不行。
九、模板的特化
模板特化:在原模板类的基础上,针对特殊类型所进行特殊化的实现方式。
1、函数模板特化
// 函数模板 -- 参数匹配
template<class T>
bool Less(T left, T right)
{
return left < right;
}
// 针对某些类型进行特殊处理 -- Date* --这是bool Less(T left, T right)函数模板的特化
//template<>
//bool Less<Date*>(Date* left, Date* right)
//{
// return *left < *right;
//}
//进行函数重载
//bool Less(Date* left, Date* right)
//{
// return *left < *right;
//}
int main()
{
cout << Less(1, 2) << endl; // 可以比较,结果正确
Date d1(2022, 7, 7);
Date d2(2022, 7, 8);
cout << Less(d1, d2) << endl; // 可以比较,结果正确
Date* p1 = &d1;
Date* p2 = &d2;
cout << Less(p1, p2) << endl; // 可以比较,结果错误
return 0;
}
Less(p1, p2)并不是按照指针所指向的数据比较,而是按照地址进行比较。解决方法有两个:1、写一个less函数的重载版本。2、使用模板的特化。
2、类模板的特化(应用场景:对仿函数的特化)
2.1全特化
template<class T1, class T2>
class Data
{
public:
Data() { cout << "Data<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
// 全特化
template<>
class Data<double, double>
{
public:
Data() { cout << "Data<double, double>" << endl; }
private:
double _d1;
double _d2;
};
2.2半特化(偏特化)
template<class T1, class T2>
class Data
{
public:
Data() { cout << "Data<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
// 半特化、偏特化
template<class T1>
class Data<T1, char>
{
public:
Data() { cout << "Data<T1, char>" << endl; }
};
//半特化对参数类型进一步限制
template<class T1, class T2>
class Data<T1*, T2*>
{
public:
Data() { cout << "Data<T1*, T2*>" << endl; }
};
template<class T1, class T2>
class Data<T1&, T2&>
{
public:
Data() { cout << "Data<T1&, T2&>" << endl; }
};
编译器是个懒狗,哪个类型更加匹配,就用哪个模板或模板特化。
十、模板的优缺点
1、优点
模板增强了代码之间的复用性,增强代码的灵活性,更快迭代开发。
2、缺点
模板会导致代码膨胀,编译时间变长。
出现模板编译错误时,报错信息凌乱,不易定位错误。