文章转自:微信公众号【机器学习炼丹术】。文章转载或者交流联系作者微信:cyx645016617
Unet其实挺简单的,所以今天的文章并不会很长。
喜欢的话可以参与文中的讨论、在文章末尾点赞、在看点一下呗。
0 概述
语义分割(Semantic Segmentation)是图像处理和机器视觉一个重要分支。与分类任务不同,语义分割需要判断图像每个像素点的类别,进行精确分割。语义分割目前在自动驾驶、自动抠图、医疗影像等领域有着比较广泛的应用。

上图为自动驾驶中的移动分割任务的分割结果,可以从一张图片中有效的识别出汽车(深蓝色),行人(红色),红绿灯(黄色),道路(浅紫色)等
Unet可以说是最常用、最简单的一种分割模型了,它简单、高效、易懂、容易构建、可以从小数据集中训练。
Unet已经是非常老的分割模型了,是2015年《U-Net: Convolutional Networks for Biomedical Image Segmentation》提出的模型
论文连接:https://arxiv.org/abs/1505.04597
在Unet之前,则是更老的FCN网络,FCN是Fully Convolutional Netowkrs的碎屑,不过这个基本上是一个框架,到现在的分割网络,谁敢说用不到卷积层呢。 不过FCN网络的准确度较低,不比Unet好用。现在还有Segnet,Mask RCNN,DeepLabv3+等网络,不过今天我先介绍Unet,毕竟一口吃不成胖子。
1 Unet
Unet其实挺简单的,所以今天的文章并不会很长。
1.1 提出初衷(不重要)
- Unet提出的初衷是为了解决医学图像分割的问题;
- 一种U型的网络结构来获取上下文的信息和位置信息;
- 在2015年的ISBI cell tracking比赛中获得了多个第一,一开始这是为了解决细胞层面的分割的任务的
1.2 网络结构
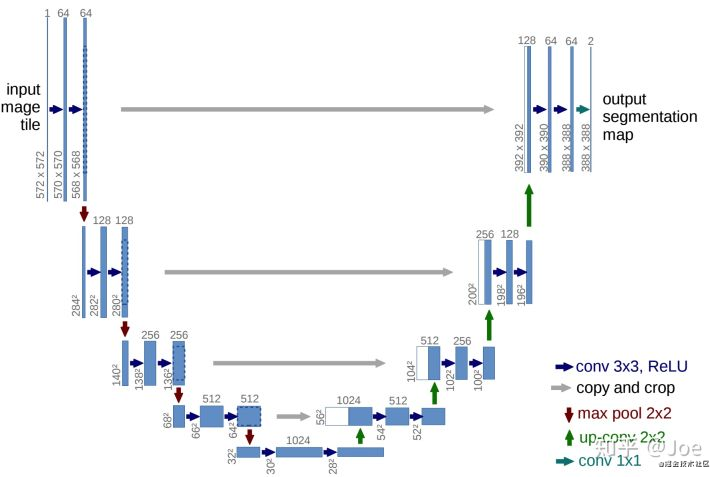
这个结构就是先对图片进行卷积和池化,在Unet论文中是池化4次,比方说一开始的图片是224x224的,那么就会变成112x112,56x56,28x28,14x14四个不同尺寸的特征。然后我们对14x14的特征图做上采样或者反卷积,得到28x28的特征图,这个28x28的特征图与之前的28x28的特征图进行通道伤的拼接concat,然后再对拼接之后的特征图做卷积和上采样,得到56x56的特征图,再与之前的56x56的特征拼接,卷积,再上采样,经过四次上采样可以得到一个与输入图像尺寸相同的224x224的预测结果。
其实整体来看,这个也是一个Encoder-Decoder的结构:
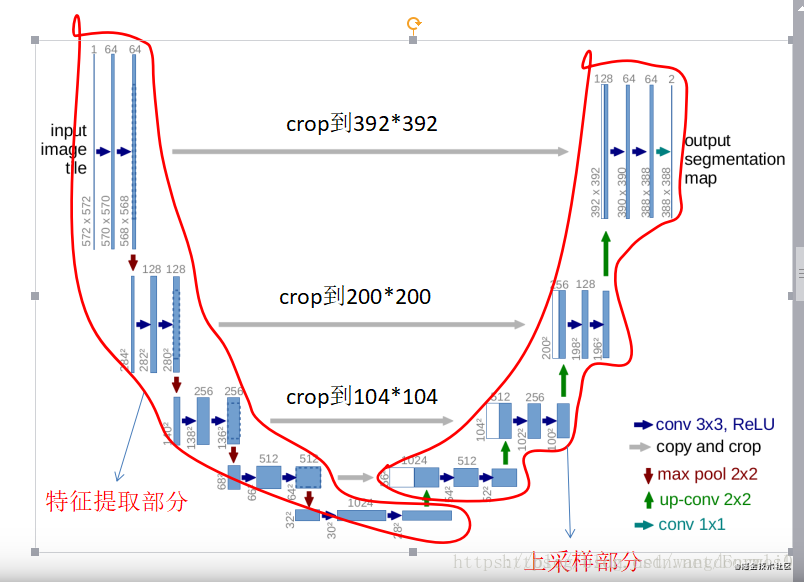
Unet网络非常的简单,前半部分就是特征提取,后半部分是上采样。在一些文献中把这种结构叫做编码器-解码器结构,由于网络的整体结构是一个大些的英文字母U,所以叫做U-net。
- Encoder:左半部分,由两个3x3的卷积层(RELU)再加上一个2x2的maxpooling层组成一个下采样的模块(后面代码可以看出);
- Decoder:有半部分,由一个上采样的卷积层(去卷积层)+特征拼接concat+两个3x3的卷积层(ReLU)反复构成(代码中可以看出来);
在当时,Unet相比更早提出的FCN网络,使用拼接来作为特征图的融合方式。
- FCN是通过特征图对应像素值的相加来融合特征的;
- U-net通过通道数的拼接,这样可以形成更厚的特征,当然这样会更佳消耗显存;
Unet的好处我感觉是:网络层越深得到的特征图,有着更大的视野域,浅层卷积关注纹理特征,深层网络关注本质的那种特征,所以深层浅层特征都是有格子的意义的;另外一点是通过反卷积得到的更大的尺寸的特征图的边缘,是缺少信息的,毕竟每一次下采样提炼特征的同时,也必然会损失一些边缘特征,而失去的特征并不能从上采样中找回,因此通过特征的拼接,来实现边缘特征的一个找回。
2 为什么Unet在医疗图像分割种表现好
这是一个开放性的问题,大家如果有什么看法欢迎回复讨论。
大多数医疗影像语义分割任务都会首先用Unet作为baseline,当然上一章节讲解的Unet的优点肯定是可以当作这个问题的答案,这里谈一谈医疗影像的特点
根据网友的讨论,得到的结果:
-
医疗影像语义较为简单、结构固定。因此语义信息相比自动驾驶等较为单一,因此并不需要去筛选过滤无用的信息。医疗影像的所有特征都很重要,因此低级特征和高级语义特征都很重要,所以U型结构的skip connection结构(特征拼接)更好派上用场
-
医学影像的数据较少,获取难度大,数据量可能只有几百甚至不到100,因此如果使用大型的网络例如DeepLabv3+等模型,很容易过拟合。大型网络的优点是更强的图像表述能力,而较为简单、数量少的医学影像并没有那么多的内容需要表述,因此也有人发现在小数量级中,分割的SOTA模型与轻量的Unet并没有神恶魔优势
-
医学影像往往是多模态的。比方说ISLES脑梗竞赛中,官方提供了CBF,MTT,CBV等多中模态的数据(这一点听不懂也无妨)。因此医学影像任务中,往往需要自己设计网络去提取不同的模态特征,因此轻量结构简单的Unet可以有更大的操作空间。
3 Pytorch模型代码
这个是我自己写的代码,所以并不是很精简,但是应该很好理解,和我之前讲解的完全一致,(有任何问题都可以和我交流:cyx645016617):
import torch
import torch.nn as nn
import torch.nn.functional as F
class double_conv2d_bn(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size=3,strides=1,padding=1):
super(double_conv2d_bn,self).__init__()
self.conv1 = nn.Conv2d(in_channels,out_channels,
kernel_size=kernel_size,
stride = strides,padding=padding,bias=True)
self.conv2 = nn.Conv2d(out_channels,out_channels,
kernel_size = kernel_size,
stride = strides,padding=padding,bias=True)
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self,x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
return out
class deconv2d_bn(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size=2,strides=2):
super(deconv2d_bn,self).__init__()
self.conv1 = nn.ConvTranspose2d(in_channels,out_channels,
kernel_size = kernel_size,
stride = strides,bias=True)
self.bn1 = nn.BatchNorm2d(out_channels)
def forward(self,x):
out = F.relu(self.bn1(self.conv1(x)))
return out
class Unet(nn.Module):
def __init__(self):
super(Unet,self).__init__()
self.layer1_conv = double_conv2d_bn(1,8)
self.layer2_conv = double_conv2d_bn(8,16)
self.layer3_conv = double_conv2d_bn(16,32)
self.layer4_conv = double_conv2d_bn(32,64)
self.layer5_conv = double_conv2d_bn(64,128)
self.layer6_conv = double_conv2d_bn(128,64)
self.layer7_conv = double_conv2d_bn(64,32)
self.layer8_conv = double_conv2d_bn(32,16)
self.layer9_conv = double_conv2d_bn(16,8)
self.layer10_conv = nn.Conv2d(8,1,kernel_size=3,
stride=1,padding=1,bias=True)
self.deconv1 = deconv2d_bn(128,64)
self.deconv2 = deconv2d_bn(64,32)
self.deconv3 = deconv2d_bn(32,16)
self.deconv4 = deconv2d_bn(16,8)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
conv1 = self.layer1_conv(x)
pool1 = F.max_pool2d(conv1,2)
conv2 = self.layer2_conv(pool1)
pool2 = F.max_pool2d(conv2,2)
conv3 = self.layer3_conv(pool2)
pool3 = F.max_pool2d(conv3,2)
conv4 = self.layer4_conv(pool3)
pool4 = F.max_pool2d(conv4,2)
conv5 = self.layer5_conv(pool4)
convt1 = self.deconv1(conv5)
concat1 = torch.cat([convt1,conv4],dim=1)
conv6 = self.layer6_conv(concat1)
convt2 = self.deconv2(conv6)
concat2 = torch.cat([convt2,conv3],dim=1)
conv7 = self.layer7_conv(concat2)
convt3 = self.deconv3(conv7)
concat3 = torch.cat([convt3,conv2],dim=1)
conv8 = self.layer8_conv(concat3)
convt4 = self.deconv4(conv8)
concat4 = torch.cat([convt4,conv1],dim=1)
conv9 = self.layer9_conv(concat4)
outp = self.layer10_conv(conv9)
outp = self.sigmoid(outp)
return outp
model = Unet()
inp = torch.rand(10,1,224,224)
outp = model(inp)
print(outp.shape)
==> torch.Size([10, 1, 224, 224])
先把上采样和两个卷积层分别构建好,供Unet模型构建中重复使用。然后模型的输出和输入是相同的尺寸,说明模型可以运行。
参考博客:
- https://blog.csdn.net/wangdongwei0/article/details/82393275
- https://www.zhihu.com/question/269914775?sort=created
- https://zhuanlan.zhihu.com/p/90418337