大数据无处不在。在时下这个年代,不管你喜欢与否,在运营一个成功的商业的过程中都有可能会遇到它。
什么是大数据?
大数据就像它看起来那样——有大量的数据。单独而言,你能从单一的数据获取的洞见穷其有限。但是结合复杂数学模型以及强大计算能力的TB级数据,却能创造出人类无法制造的洞见。大数据分析提供给商业的价值是无形的,并且每天都在超越人类的能力。
大数据分析的第一步就是要收集数据本身,也就是众所周知的“数据挖掘”。大部分的企业处理着GB级的数据,这些数据有用户数据、产品数据和地理位置数据。今天,我将会带着大家一起探索如何用Python进行大数据挖掘和分析?

为什么选择Python?
Python最大的优点就是简单易用。这个语言有着直观的语法并且还是个强大的多用途语言。这一点在大数据分析环境中很重要,并且许多企业内部已经在使用Python了,比如Google,YouTube,迪士尼等。还有,Python是开源的,并且有很多用于数据科学的类库。
现在,如果你真的要用Python进行大数据分析的话,毫无疑问你需要了解Python的语法,理解正则表达式,知道什么是元组、字符串、字典、字典推导式、列表和列表推导式——这只是开始。
数据分析流程
一般可以按“数据获取-数据存储与提取-数据预处理-数据建模与分析-数据可视化”这样的步骤来实施一个数据分析项目。按照这个流程,每个部分需要掌握的细分知识点如下:
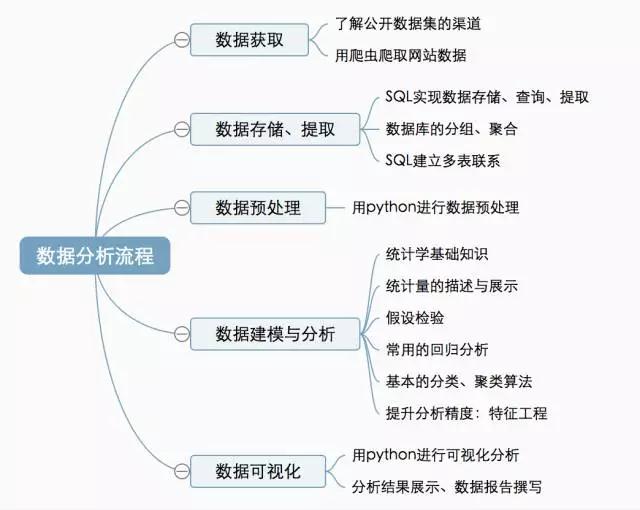
数据获取:公开数据、Python爬虫
外部数据的获取方式主要有以下两种。
第一种是获取外部的公开数据集,一些科研机构、企业、政府会开放一些数据,你需要到特定的网站去下载这些数据。这些数据集通常比较完善、质量相对较高。
另一种获取外部数据的方式就是爬虫。
比如你可以通过爬虫获取招聘网站某一职位的招聘信息,爬取租房网站上某城市的租房信息,爬取豆瓣评分评分最高的电影列表,获取知乎点赞排行、网易云音乐评论排行列表。基于互联网爬取的数据,你可以对某个行业、某种人群进行分析。
在爬虫之前你需要先了解一些 Python 的基础知识:元素(列表、字典、元组等)、变量、循环、函数………
以及,如何用 Python 库(urllib、BeautifulSoup、requests、scrapy)实现网页爬虫。
掌握基础的爬虫之后,你还需要一些高级技巧,比如正则表达式、使用cookie信息、模拟用户登录、抓包分析、搭建代理池等等,来应对不同网站的反爬虫限制。
数据存取:SQL语言
在应对万以内的数据的时候,Excel对于一般的分析没有问题,一旦数据量大,就会力不从心,数据库就能够很好地解决这个问题。而且大多数的企业,都会以SQL的形式来存储数据。
SQL作为最经典的数据库工具,为海量数据的存储与管理提供可能,并且使数据的提取的效率大大提升。你需要掌握以下技能:
提取特定情况下的数据
数据库的增、删、查、改
数据的分组聚合、如何建立多个表之间的联系
数据预处理:Python(pandas)
很多时候我们拿到的数据是不干净的,数据的重复、缺失、异常值等等,这时候就需要进行数据的清洗,把这些影响分析的数据处理好,才能获得更加精确地分析结果。
对于数据预处理,学会 pandas (Python包)的用法,应对一般的数据清洗就完全没问题了。需要掌握的知识点如下:
选择:数据访问
缺失值处理:对缺失数据行进行删除或填充
重复值处理:重复值的判断与删除
异常值处理:清除不必要的空格和极端、异常数据
相关操作:描述性统计、Apply、直方图等
合并:符合各种逻辑关系的合并操作
分组:数据划分、分别执行函数、数据重组
Reshaping:快速生成数据透视表
概率论及统计学知识
需要掌握的知识点如下:
基本统计量:均值、中位数、众数、百分位数、极值等
其他描述性统计量:偏度、方差、标准差、显著性等
其他统计知识:总体和样本、参数和统计量、ErrorBar
概率分布与假设检验:各种分布、假设检验流程
其他概率论知识:条件概率、贝叶斯等
有了统计学的基本知识,你就可以用这些统计量做基本的分析了。你可以使用 Seaborn、matplotlib 等(python包)做一些可视化的分析,通过各种可视化统计图,并得出具有指导意义的结果。
Python 数据分析
掌握回归分析的方法,通过线性回归和逻辑回归,其实你就可以对大多数的数据进行回归分析,并得出相对精确地结论。这部分需要掌握的知识点如下:
回归分析:线性回归、逻辑回归
基本的分类算法:决策树、随机森林……
基本的聚类算法:k-means……
特征工程基础:如何用特征选择优化模型
调参方法:如何调节参数优化模型
Python 数据分析包:scipy、numpy、scikit-learn等
在数据分析的这个阶段,重点了解回归分析的方法,大多数的问题可以得以解决,利用描述性的统计分析和回归分析,你完全可以得到一个不错的分析结论。
当然,随着你实践量的增多,可能会遇到一些复杂的问题,你就可能需要去了解一些更高级的算法:分类、聚类。
然后你会知道面对不同类型的问题的时候更适合用哪种算法模型,对于模型的优化,你需要去了解如何通过特征提取、参数调节来提升预测的精度。
你可以通过 Python 中的 scikit-learn 库来实现数据分析、数据挖掘建模和分析的全过程。
读者福利:知道你对Python感兴趣,便准备了这套python学习资料
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)