Towards Automatic Screening of Typical and Atypical Behaviors in Children With Autism
Authors Andrew Cook, Bappaditya Mandal, Donna Berry, Matthew Johnson
自闭症谱系障碍ASD影响个体的认知,社交,交流和行为能力。新的临床决策支持系统的开发对于减少症状表现和准确诊断之间的延迟具有重要意义。在这项工作中,我们提供了一个新的数据库,其中包括从YouTube视频网站收集的自然环境中显示的典型正常和非典型视频剪辑,如手拍,旋转或摇摆行为。我们提出了一种基于骨架关键点识别的初步非侵入式方法,该方法使用人体视频剪辑上的预训练深度神经网络来提取特征并执行区分儿童典型和非典型行为的身体运动分析。新贡献的数据库的实验结果表明,与其他流行的方法相比,我们的平台在决策树作为分类器时表现最佳,并提供了可以开发和测试替代方法的基线。
|
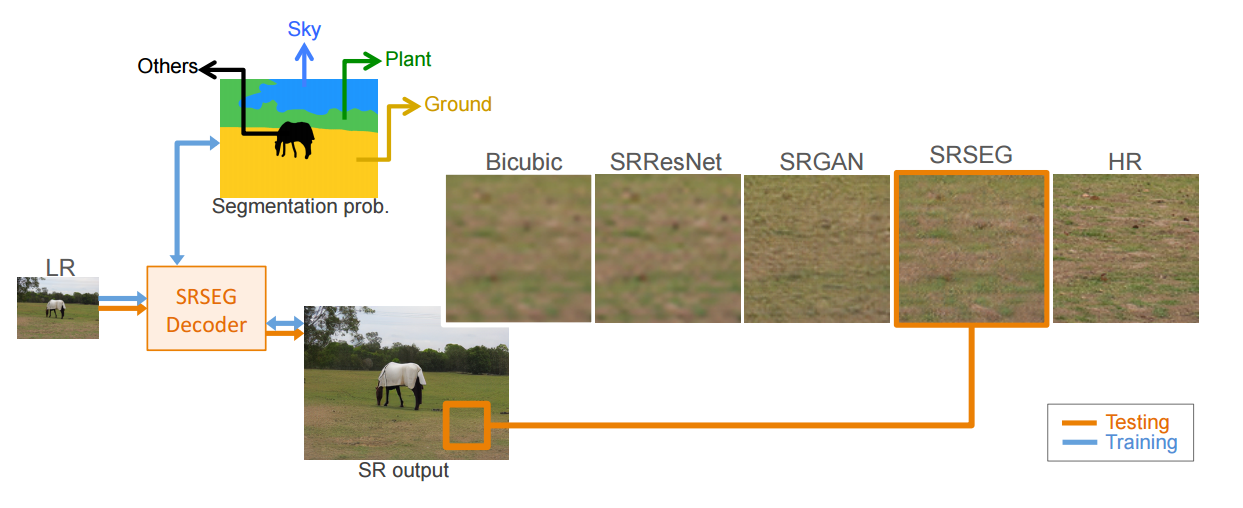
Benefiting from Multitask Learning to Improve Single Image Super-Resolution
Authors Mohammad Saeed Rad, Behzad Bozorgtabar, Claudiu Musat, Urs Viktor Marti, Max Basler, Hazim Kemal Ekenel, Jean Philippe Thiran
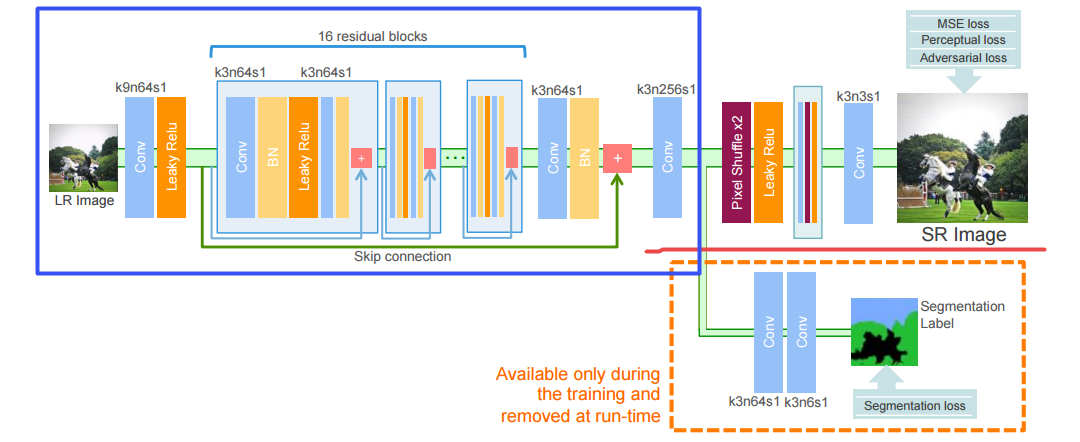
尽管通过更深层的卷积神经网络CNN超级分辨更逼真的图像取得了重大进展,但重建精细和自然纹理仍然是一个具有挑战性的问题。最近关于单图像超分辨率SISR的工作主要基于优化恢复的和高分辨率HR图像之间的像素和内容相似性,并且不受益于语义类的可识别性。在本文中,我们介绍了一种使用分类信息来解决SISR问题的新方法,我们提出了一种解码器架构,能够提取和使用语义信息,通过多任务学习来超分辨给定图像,同时用于图像超分辨率和语义分割。为了在训练期间探索分类信息,所提出的解码器仅针对两个任务特定输出层使用一个共享深度网络。在运行时,仅使用产生HR图像的层,并且不需要分段标签。广泛的感知实验和从COCO Stuff数据集中随机选择的图像的用户研究证明了我们提出的方法的有效性,并且它优于现有技术方法。
|
++基于交叉线分割实现航拍飞行器检测X-LineNet: Detecting Aircraft in Remote Sensing Images by a pair of Intersecting Line Segments
Authors Haoran Wei, Wang Bing, Zhang Yue
在飞机探测领域,深度卷积神经网络DCNN的发展已经取得了巨大的进步。目前,基于DCNN的大多数现有技术模型属于自上而下的方法,其广泛使用锚机制。在它们中获得高精度依赖于以矩形边界框的形式列举物体的大量潜在位置,这是浪费且不太精细。在本文中,我们以自下而上的方式提出了一种新颖的飞机检测模型,其任务是检测每个目标内部的两个交叉线段并将它们分组,因此我们将其命名为X LineNet。作为学习更精细的飞机视觉语法信息的结果,X LineNet可以获得具有更多具体细节和更高精度的检测结果。正是为了这些优点,我们设计了一种新颖的检测结果五边形面罩,它具有较少的冗余度,能够比遥感图像中的矩形盒更好地代表飞机。
https://github.com/Ucas-HaoranWei Airplane-KP dataset UCAS-AOD[28] NWPU VHR-10[29]
|
+点云加密Self-Supervised Learning for Stereo Reconstruction on Aerial Images
Authors Patrick Kn belreiter, Christoph Vogel, Thomas Pock
最近的发展使深度学习成为提高密集匹配和立体声估计性能的必然工具。在缺点方面,学习这些网络需要大量的培训数据才能获得成功。因此,在实验室之外应用这些模型远非直截了当。在这项工作中,我们提出了一种自我监督的训练程序,使我们能够使我们的网络适应手头数据集的特定成像特征,而无需外部地面实况数据。我们通过在整个数据集上运行我们的中间网络,然后进行保守的异常值过滤来生成临时训练数据。从我们的混合CNN CRF模型的预训练版本引导,我们交替生成训练数据和网络训练。通过这个简单的概念,我们能够显着提升预训练版本的完整性和准确性。我们还表明,我们的最终模型与航空数据集上的其他流行的立体声估计算法相比毫不逊色。
ref:https://github.com/VLOGroup/cnn-crf-stereo
|
Salient Slices: Improved Neural Network Training and Performance with Image Entropy
Authors Steven J. Frank, Andrea M. Frank
作为卷积神经网络CNN的训练和分析策略,我们将图像切割成平铺的片段,并且用于训练和预测,既满足信息多样性标准又包含足够内容以支持分类的片段。特别是,我们利用图像熵作为多样性标准。这确保了每个区块携带与原始图像一样多的信息多样性,并且对于许多应用来说,其用作分类中的有用性的指示符。为了进行预测,将概率聚合框架应用于由CNN分配给输入图像瓦片的概率。该技术有助于使用大的高分辨率图像,这对于分析未修改的提供用于训练的数据增加是不切实际的,这在图像可用性受限并且用于预测的输入的整体性质增强其准确性时特别有价值。
|
++多密度分布人群密度估计Learn to Scale: Generating Multipolar Normalized Density Map for Crowd Counting
Authors Chenfeng Xu, Kai Qiu, Jianlong Fu, Song Bai, Yongchao Xu, Xiang Bai
密集人群计数旨在通过计算图像像素上的密度图的积分来从图像预测数千个人类实例。现有方法主要受到极端密度差异的影响。即使对于多尺度模型集合,这种密度模式偏移也提出了挑战。在本文中,我们提出了一种简单而有效的方法来解决这个问题。首先,通过密度估计模型提取补丁级密度图,并进一步分组为在完整数据集上确定的若干密度级。其次,每个贴片密度图由具有多极中心损失MPCL的在线中心学习策略自动标准化。这样的设计可以将密度分布显着地浓缩成几个簇,并且使得能够通过单个模型学习密度方差。大量实验表明,在上海技术A部分,B部分,UCF CC 50,UCF QNRF中,所提出的框架在几个人群计数数据集中的最佳准确度,相对准确度增益为4.2,14.3,27.1,20.1,超过了现有技术方法。数据集,分别。
|
++基于一致性特征的场景解译Consensus Feature Network for Scene Parsing
Authors Tianyi Wu, Sheng Tang, Rui Zhang, Guodong Guo, Yongdong Zhang
场景解析具有挑战性,因为它旨在将一个语义类别分配给场景图像中的每个像素。因此,像素级特征是场景解析所需的。然而,分类网络由判别部分支配,因此直接将分类网络应用于场景解析将导致一个实例内和相同类别的实例之间的解析预测不一致。为了解决这个问题,我们提出了两个变换单元来学习像素级共识特征。一个是实例共识转换ICT单元,通过聚合同一实例中的功能来学习实例级别的共识功能。另一个是类别共识变换CCT单元,通过在场景图像中保持相同类别的实例之间的特征的一致性来追求类别级别共识特征。拟议的ICT和CCT单元是轻量级,数据驱动和端到端可训练的。两个单元学到的特征在实例级别和类别级别上更加一致。此外,我们根据提议的ICT和CCT单元提出共识特征网络CFNet。四个场景解析基准测试的实验,包括Cityscapes,Pascal Context,CamVid和COCO Stuff,表明所提出的CFNet学习像素级共识特征并获得一致的解析结果。
|
++基于闪光和反射的人脸活体检测Specular- and Diffuse-reflection-based Face Liveness Detection for Mobile Devices
Authors Akinori F. Ebihara, Kazuyuki Sakurai, Hitoshi Imaoka
鉴于对生物认证系统的需求不断增长,防止面部欺骗攻击是人脸识别系统安全部署的关键问题。在这里,我们提出了一种高效的活动检测算法,该算法只需要最少的硬件和小型数据库,因此适用于资源受限的设备,如手机。利用一个单目可见光相机,该算法拍摄两张面部照片,一张用闪光灯拍摄,另一张没有闪光灯。所提出的SpecDiff描述符是通过利用两种类型的反射来构建的,来自虹膜区域的镜面反射具有取决于活性的特定强度分布,以及来自整个面部区域的漫反射,其表示主体面部的3D结构。使用SpecDiff描述符训练的分类器在内部数据库和公开可用的NUAA和重放攻击数据库上优于其他基于闪存的活动检测算法。此外,所提出的算法实现了与端到端深度神经网络分类器相当的精度,同时执行速度大约快十倍。
|
Recursive Cascaded Networks for Unsupervised Medical Image Registration
Authors Shengyu Zhao, Yue Dong, Eric I Chao Chang, Yan Xu
我们提出递归级联网络,一种能够学习深级联的通用架构,用于可变形图像配准。所提出的架构设计简单,可以在任何基础网络上构建。运动图像通过每个级联连续变形,并最终与固定图像对齐,该过程以每个级联学习对当前变形图像执行渐进变形的方式递归。整个系统是端到端的,并以无人监督的方式共同训练。此外,通过递归架构,在测试期间可以多次迭代地应用一个级联,这在每个图像对之间接近更好的拟合。我们在3D医学图像上评估我们的方法,其中最常应用可变形配准。我们证明了递归级联网络实现了一致的,显着的增益,并且优于现有技术的方法。只要训练更多的级联,性能就会显示出增加的趋势,而没有观察到极限。我们的代码将公开发布。
|
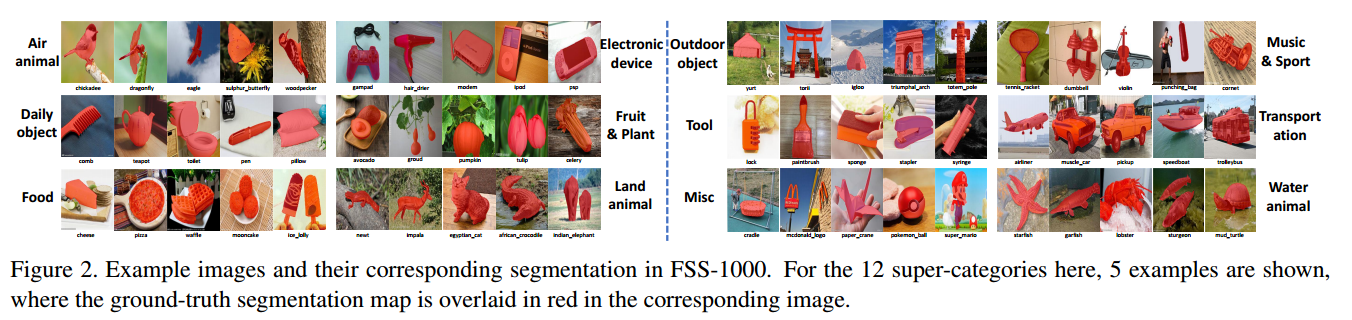
+++用于小样本分割学习的数据集FSS-1000: A 1000-Class Dataset for Few-Shot Segmentation
Authors Tianhan Wei, Xiang Li, Yau Pun Chen, Yu Wing Tai, Chi Keung Tang
在过去几年中,由于PASCAL VOC,ImageNet和COCO等大规模人类注释数据集的可用性,我们目睹了图像识别中深度学习的成功。尽管这些数据集涵盖了广泛的对象类别,但仍然存在大量未包含的对象。我们可以在没有大量人工注释的情况下执行相同的任务在本文中,我们对几个镜头对象分割感兴趣,其中注释训练示例的数量仅限于5。为了评估和验证我们的方法的性能,我们构建了一些镜头分割数据集FSS 1000,它由1000个对象类和地面真实分割的像素注释组成。 FSS 1000中的独特之处,我们的数据集包含大量在以前的数据集中从未见过或注释过的对象,例如微小的日常物品,商品,卡通人物,徽标等。我们使用标准骨干网络(如VGG)构建我们的基线模型16,ResNet 101和Inception。令我们惊讶的是,我们发现使用FSS 1000从头开始训练我们的模型可以获得与ImageNet预训练的训练相比甚至更好的结果,ImageNet比FSS 1000大100倍。我们的方法和数据集都很简单,有效,在很少注释的训练样例的情况下,可以轻松扩展以学习新对象类的分段。数据集可在
|
Meta Learning for Task-Driven Video Summarization
Authors Xuelong Li, Hongli Li, Yongsheng Dong
现有的视频摘要方法主要集中在视频数据的顺序或结构特征上。但是,他们对视频摘要任务本身没有给予足够的重视。在本文中,我们提出了一种用于执行任务驱动的视频摘要的元学习方法,由MetaL TDVS表示,以明确地探索在不同视频的概括过程中的视频摘要机制。特别是,MetaL TDVS旨在通过将视频摘要重新制定为元学习问题来挖掘潜在的视频概括机制,并提升训练模型的泛化能力。 MetaL TDVS将每个视频的总结视为一项任务,以便更好地利用从总结其他视频的过程中学到的经验和知识来总结新视频。此外,MetaL TDVS通过双向反向传播更新模型,这迫使在一个视频上优化的模型在每个训练步骤中在另一个视频上获得高精度。对基准数据集的大量实验证明了MetaL TDVS对几种最先进方法的优越性和更好的泛化能力。
|
Goal-Driven Sequential Data Abstraction
Authors Umar Riaz Muhammad, Yongxin Yang, Timothy M. Hospedales, Tao Xiang, Yi Zhe Song
自动数据抽象是基准测试机器智能和支持摘要应用程序的重要功能。在前者中,询问机器是否能够充分了解输入数据的含义,以产生有意义但更紧凑的抽象。在后者中,通过总结输入数据的本质来利用这种能力来节省空间或人力时间。在本文中,我们研究了一个基于强化学习的总体框架,用于学习以目标驱动的方式抽象顺序数据。定义不同抽象目标的能力唯一地允许根据抽象的最终目的保留输入数据的不同方面。我们的强化学习目标不需要人类定义的理想抽象的例子。重要的是,我们的模型整体处理输入序列,而不受原始输入顺序的约束。我们的框架也是领域不可知的,我们展示了草图,视频和文本数据的应用,并在所有领域取得了可喜的成果。
|
Multi-Task Attention-Based Semi-Supervised Learning for Medical Image Segmentation
Authors Shuai Chen, Gerda Bortsova, Antonio Garcia Uceda Juarez, Gijs van Tulder, Marleen de Bruijne
我们提出了一种新颖的半监督图像分割方法,该方法同时优化了监督分割和无监督重建目标。重建目标使用注意机制来分离对应于不同类别的图像区域的重建。所提出的方法评估了两种应用脑肿瘤和白质高信号分割。我们的方法,在未标记和少量标记图像上训练,优于使用相同数量的图像训练的受监督CNN和在未标记数据上预训练的CNN。在消融实验中,我们观察到所提出的注意机制显着改善了分割性能。我们探索两种多任务训练策略联合训练和交替训练。交替训练需要较少的超参数,并且比联合训练获得更好,更稳定的性能。最后,我们分析了不同方法学到的特征,发现注意机制有助于在更深层的编码器中学习更多的判别特征。
|
A Two Stage GAN for High Resolution Retinal Image Generation and Segmentation
Authors Paolo Andreini, Simone Bonechi, Monica Bianchini, Alessandro Mecocci, Franco Scarselli, Andrea Sodi
近年来,深度学习的使用在计算机视觉中变得越来越流行。但是,深层体系结构的有效培训通常依赖于大量注释数据。这在医学领域中是至关重要的,其中获得注释图像是困难且昂贵的。在本文中,我们使用生成对抗网络GAN来合成高质量的视网膜图像,以及相应的语义标签图,以在训练过程中使用而不是真实图像。与其他先前的提议不同,我们首先建议采用两步法,逐步增长的GAN被训练以生成语义标签图,其描述血管结构,即脉管系统第二,图像到图像的翻译方法用于获得逼真的视网膜图像。从产生的脉管系统。通过仅使用少量训练样本,我们的方法可生成逼真的高分辨率图像,可有效地用于放大小的可用数据集。在训练期间使用所生成的图像代替实际数据已经获得了可比较的结果。通过将其应用于视网膜血管分割的两个完善的基准集,已经证明了所提出的方法的实际可行性,两者都包含非常少量的训练样本。我们的方法在现有技术方面获得了更好的性能。
|
Regularizing Proxies with Multi-Adversarial Training for Unsupervised Domain-Adaptive Semantic Segmentation
Authors Tong Shen, Dong Gong, Wei Zhang, Chunhua Shen, Tao Mei
训练语义分割模型需要大量的像素级注释,从而大规模地妨碍其应用。通过计算机图形学,我们可以使用精确的注释生成几乎无限的训练数据。然而,由于域移位,使用合成数据训练的深度模型通常不能直接概括为逼真的图像。已经观察到,可以依赖于标记的合成数据来预测未标记的真实图像的高度自信的标签。为了解决无监督的域适应问题,我们探索了生成高质量标签作为代理标签来监督目标数据培训的可能性。具体而言,我们提出了一种使用多对抗训练的基于代理的新方法。我们首先使用合成数据源域训练模型。多个鉴别器用于在不同级别的源和目标域真实图像之间对齐特征。然后,我们通过结合类预测器的置信度和来自对抗性鉴别器的置信度,专注于获得和选择高质量的代理标签。我们的鉴别器不仅可以作为规范器来鼓励功能对齐,还可以为生成代理标签提供替代的置信度。依靠生成的高质量代理,我们的模型可以在目标主体上以受监督的方式进行训练。在两个主要任务,GTA5 Cityscapes和SYNTHIA Cityscapes,我们的方法达到了最先进的结果,大大超过了之前的水平。
|
Interlaced Sparse Self-Attention for Semantic Segmentation
Authors Lang Huang, Yuhui Yuan, Jianyuan Guo, Chao Zhang, Xilin Chen, Jingdong Wang
在本文中,我们提出了一种所谓的交错稀疏自我注意方法,以提高语义分割的自我注意机制的效率。主要思想是我们将密集亲和度矩阵分解为两个稀疏亲和度矩阵的乘积。有两个连续的注意模块,每个模块估计稀疏亲和度矩阵。第一注意模块用于估计具有长空间间隔距离的位置子集内的亲和度,第二注意模块用于估计具有短空间间隔距离的位置子集内的亲和度。这两个注意模块的设计使每个位置都能够从所有其他位置接收信息。与原始自我关注模块相比,我们的方法显着降低了计算和存储器复杂性,尤其是在处理高分辨率特征映射时。我们凭经验验证了我们的方法在六个具有挑战性的语义分段基准上的有效性。
|
++V-PROM: A Benchmark for Visual Reasoning Using Visual Progressive Matrices
Authors Damien Teney, Peng Wang, Jiewei Cao, Lingqiao Liu, Chunhua Shen, Anton van den Hengel
深度学习面临的主要挑战之一是当前方法利用表面统计和数据集偏差的程度,而不是学习如何概括他们所经历的具体表征。这是一个至关重要的问题,因为泛化能够对看不见的数据进行强有力的推理,而利用表面统计数据对于数据分布的微小变化来说是脆弱的。为了阐明问题并推动解决方案的进展,我们提出了一种测试,明确评估可视化数据的抽象推理。我们引入了一个大规模的视觉问题基准,其涉及许多高级视觉任务的基本操作,例如计数和复杂视觉属性的逻辑运算的比较。基准测试直接测量方法推断高级关系并将其概括为基于图像的概念的能力。它包括多个训练测试分割,需要受控的泛化水平。我们评估了一系列深度学习架构,并发现现有模型(包括那些流行于视觉和语言任务的模型)无法解决看似简单的实例。使用关系网络的模型表现更好,但仍有很大的改进空间。
Australian Institute for Machine Learning
|
+x新型损失函数Li-ArcFace的人脸识别AirFace:Lightweight and Efficient Model for Face Recognition
Authors Xianyang Li
随着卷积神经网络的发展,计算机视觉任务取得了重大进展。然而,常见的视觉任务的常用损耗函数softmax损失和高效网络架构对于人脸识别并不那么有效。在本文中,我们提出了一种基于ArcFace的名为Li ArcFace的新型损失函数。 Li ArcFace通过线性函数将角度值作为目标logit,而不是通过余弦函数,它在人脸识别的低维嵌入特征学习中具有更好的收敛性和性能。在网络架构方面,我们通过增加网络深度,宽度和增加注意模块来改进MobileFaceNet的性能。此外,我们还发现了一些有用的人脸识别训练技巧。综合以上结果,我们在LFR2019的深度光挑战中获得第二名。
http://www.airia.cn/
|
+++基于轮廓引导的遮挡点云重建算法Silhouette Guided Point Cloud Reconstruction beyond Occlusion
Authors Chuhang Zou, Derek Hoiem
3D重建的一个主要挑战是从部分前景遮挡中推断出完整的形状几何形状。在本文中,我们提出了一种从单个RGB图像重建物体的完整3D形状的方法,具有对遮挡的鲁棒性。给定图像和可见区域的轮廓,我们的方法完成遮挡区域的轮廓,然后生成点云。我们通过提供预测的完整轮廓作为指导,显示了对非遮挡和部分遮挡物体的重建的改进。我们还通过来自多个合成视图的2D重投影损失和基于表面的平滑和细化步骤来改进3D形状预测的现有技术。实验证明了我们的方法在合成和真实场景数据集上的定量和定性效果。
https://github.com/zouchuhang/Silhouette-Guided-3D
|
Automatic Registration between Cone-Beam CT and Scanned Surface via Deep-Pose Regression Neural Networks and Clustered Similarities
Authors Minyoung Chung, Jingyu Lee, Wisoo Song, Youngchan Song, Il Hyung Yang, Jeongjin Lee, Yeong Gil Shin
颌面锥形束计算机断层扫描CT图像和扫描牙科模型之间的计算机配准是牙科植入物或正颌外科手术计划的必要先决条件。我们提出了一种在锥形束CT图像和光学扫描模型之间进行全自动配准的新方法。为了构建鲁棒且自动的初始配准方法,我们的方法在缩减域即2维图像中应用深度姿态回归神经网络。随后,通过最佳聚类执行精确配准。多数投票系统实现全局最优变换,而每个集群都试图优化局部变换参数。群集的一致性决定了他们对最优群集的候选资格。基于最佳聚类之间的一致性,有效地去除了iso表面中的外围区域。登记的准确性通过扫描模型上的10个地标的欧几里德距离来评估,这些地标由该领域的专家注释。实验表明,以地标距离测量的方法的配准精度优于其他现有方法30.77至70。除了实现高精度之外,我们提出的方法既不需要人类相互作用也不需要先验,例如,等表面提取。我们研究的主要意义在于双重加权神经网络的应用,表明神经网络在提取易于获得的姿态线索方面的适用性,2引入了一种可以避免金属伪影的最优基于聚类的配准方法。匹配程序。
|
A Fine-Grain Error Map Prediction and Segmentation Quality Assessment Framework for Whole-Heart Segmentation
Authors Rongzhao Zhang, Albert C.S. Chung
当将高级图像计算算法(例如,整个心脏分割)引入临床实践时,常见的怀疑是自动计算结果的可靠性。实际上,重要的是找出失败案例并识别错误分类的像素,以便可以排除或纠正它们以用于后续分析或诊断。然而,当通常由专家注释的地面实况不存在时,预测分割掩模中的错误并不是一个小问题。在这项工作中,我们尝试使用统一的深度学习DL框架解决像素明智的错误图预测问题和每个案例的掩模质量评估问题。具体来说,我们首先将错误图预测问题形式化,然后将其转换为分段问题并构建DL网络来解决它。我们还从预测的误差图中导出质量指标QI,以测量分割掩模的整体质量。为了评估所提出的框架,我们在公共全心脏分割数据集上进行了广泛的实验,即MICCAI 2017 MMWHS。通过5次交叉验证,我们得到误差图预测任务的总体Dice得分为0.626,并观察到QI与实际分割精度Acc之间的高Pearson相关系数PCC为0.972,以及低的平均绝对误差MAE它们之间为0.0048,这证明了我们的方法在误差图预测和质量评估中的有效性。
|
+膝盖关键点检测KNEEL: Knee Anatomical Landmark Localization Using Hourglass Networks
Authors Aleksei Tiulpin, Iaroslav Melekhov, Simo Saarakkala
本文讨论了骨关节炎OA不同阶段膝关节X线图像中解剖标志定位的挑战。可以将地标定位视为回归问题,其中通过使用感兴趣区域或甚至全尺寸图像直接预测地标位置,导致大的存储器占用,尤其是在高分辨率医学图像的情况下。在这项工作中,我们提出了一种有效的深度神经网络框架,其沙漏架构利用软argmax层直接预测标志点的标准化坐标。我们对不同的正则化技术和各种损失函数进行了广泛的评估,以了解它们对本地化性能的影响。此外,我们从低预算注释中引入转移学习的概念,并通过实验证明这种方法正在提高标志性本地化的准确性。与现有方法相比,我们在两个独立于列车数据的数据集上验证我们的模型,并评估该方法在OA严重程度的不同阶段的性能。与现有技术相比,所提出的方法表现出更好的泛化性能。http://will.be.placed.after.review/
|
Multi-Granularity Fusion Network for Proposal and Activity Localization: Submission to ActivityNet Challenge 2019 Task 1 and Task 2
Authors Haisheng Su, Xu Zhao, Shuming Liu
本技术报告概述了我们提交给ActivityNet Challenge 2019任务1 textbf时间行动建议生成和任务2 textbf时间动作本地化检测时使用的解决方案。时间行动提议表明包含动作的时间间隔,并在时间动作定位中起重要作用。自上而下和自下而上的方法是现有文献中用于提议生成的两个主要类别。在本文中,我们设计了一种新颖的多粒度融合网络MGFN,将不同框架产生的提议结合起来进行互补过滤和置信度排序。具体而言,我们从多个角度全面考虑多样性,例如:特征方面,数据方面,模型方面和结果方面。我们的MGFN在时间动作提议任务上实现了最先进的性能,具有69.85 AUC分数和时间动作本地化任务,在挑战测试集上具有38.90 mAP。
|
Automatic Text Line Segmentation Directly in JPEG Compressed Document Images
Authors Bulla Rajesh, Mohammed Javed, P Nagabhushan
JPEG是一种流行的图像压缩算法,可在消费电子产品中提供高效的存储和传输功能,因此它是互联网世界中最受欢迎的图像格式。在当前的数字和大数据时代,大量的JPEG压缩文档图像被存档并通过消费电子产品每天进行通信。尽管在一侧具有压缩形式的数据是有利的,但是另一方面,现成方法的处理在计算上变得昂贵,因为它需要解压缩和再压缩操作。因此,如果压缩数据直接在它们各自的消费电子产品的压缩域中处理,那将是新颖和有效的。在本研究报告中,我们建议以印刷文本行分割的案例研究来证明这一想法。由于JPEG通过将图像划分为像素域中的非重叠8x8块并使用离散余弦变换DCT来实现压缩,因此分区的8x8 DCT块很可能与两个相邻文本行的内容重叠,而不会留下线分隔符的任何线索从而使文本行分割成为具有挑战性的问题。这里使用每个8×8DCT块的DC投影轮廓和AC系数提出了两种分割方法。第一种方法基于所选DCT块的部分解压缩策略,第二种方法是对F10和F11 AC系数进行智能分析,而不使用任何类型的解压缩。已经使用可变字体大小,字体样式和行间距来测试所提出的方法,并且报告了良好的性能。
|
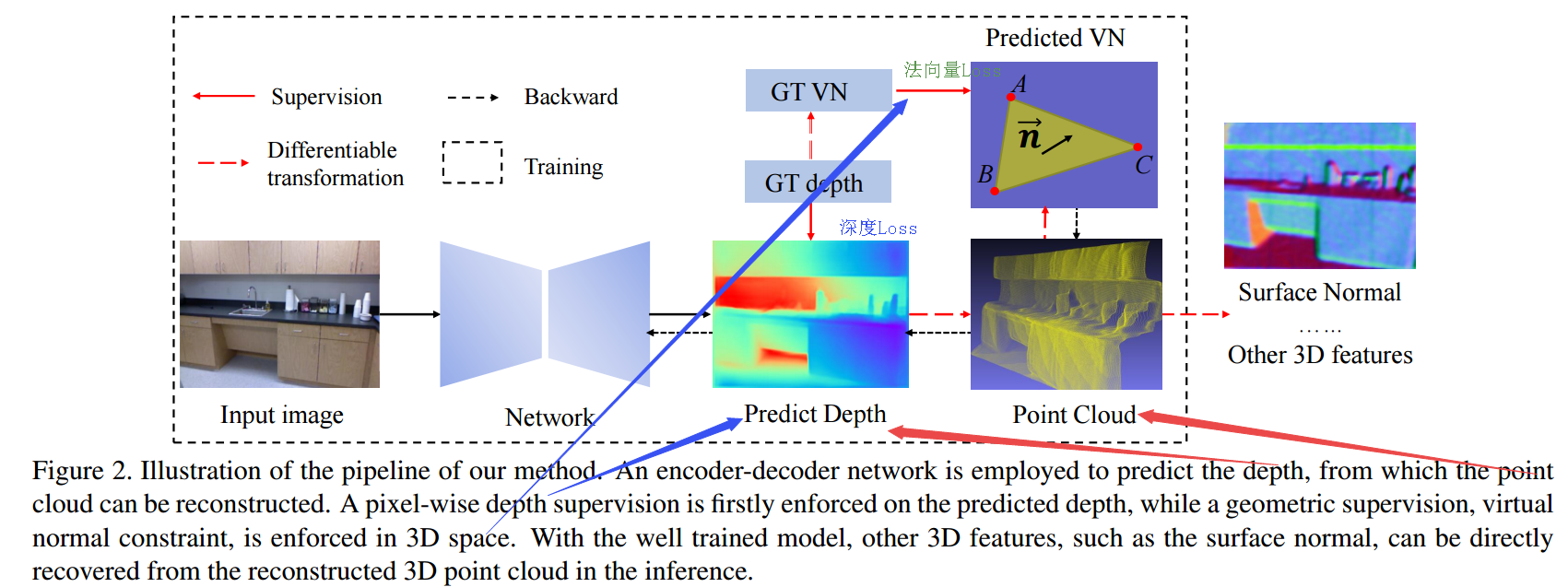
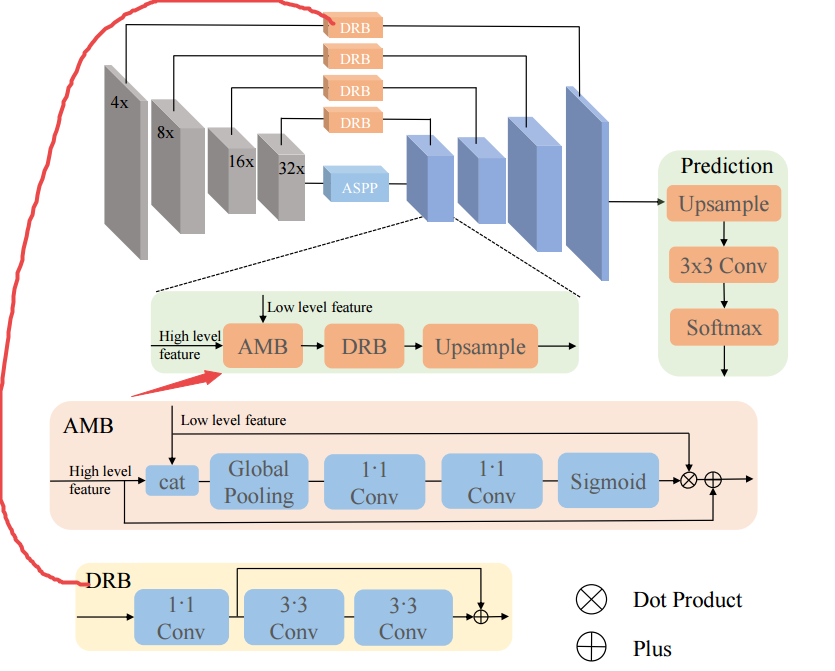
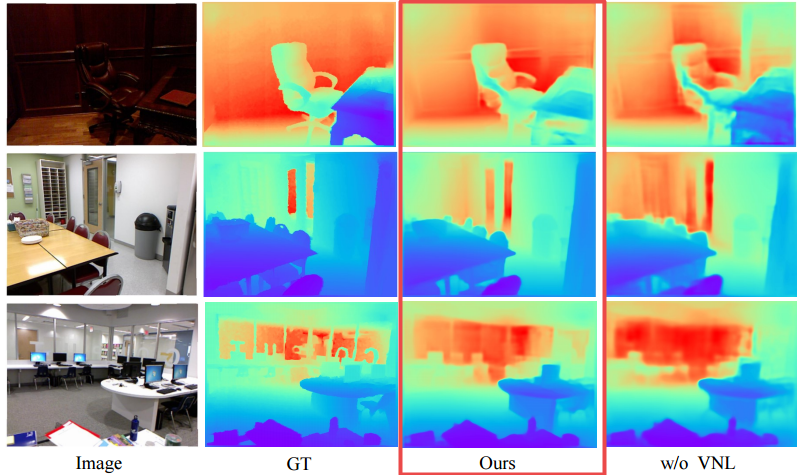
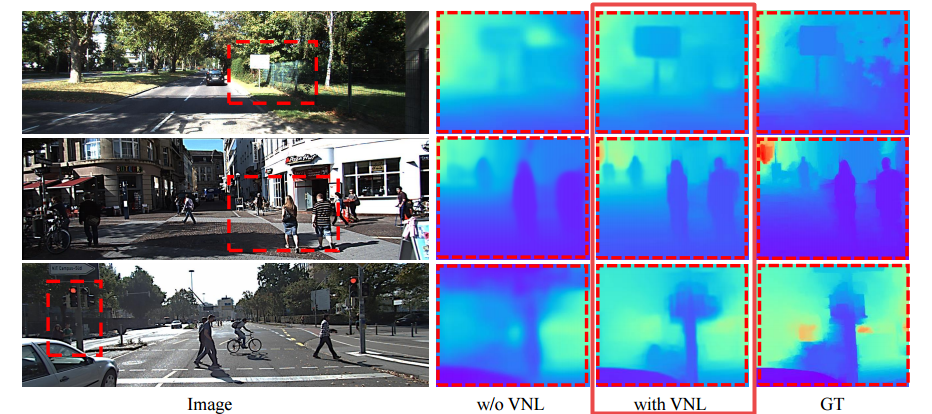
Enforcing geometric constraints of virtual normal for depth prediction
Authors Yin Wei, Yifan Liu, Chunhua Shen, Youliang Yan
单目深度预测在理解3D场景几何中起着至关重要的作用。尽管最近的方法在诸如像素相对误差的评估度量方面取得了令人印象深刻的进步,但是大多数方法忽略了3D空间中的几何约束。在这项工作中,我们展示了高阶3D几何约束对深度预测的重要性。通过设计实施一种简单类型的几何约束的损失项,即由重建的3D空间中的随机采样的三个点确定的虚拟法线方向,我们可以显着提高深度预测精度。值得注意的是,这个预测深度的副产品足够准确,我们现在能够直接从深度恢复场景的良好3D结构,例如点云和表面法线,从而消除了像以前那样训练新子模型的必要性。 。两个基准的实验NYU Depth V2和KITTI证明了我们的方法和最先进的性能的有效性。
|
+稀疏时域重建感知Seeing Things in Random-Dot Videos
Authors Thomas Dag s, Michael Lindenbaum, Alfred M. Bruckstein
人类视觉系统正确地分组特征并解释显示由成像自然动态场景引起的非持久和嘈杂随机点数据的视频。值得注意的是,即使在逐帧呈现相同信息时感知完全失败,也会发生这种情况。我们研究了令人惊讶的动态感知的这种特性,第一个目标是当每帧,对象的信息是随机的和稀疏的时,为这样的信号提出新的检测和时空分组算法。算法的性能与人类观察者的感知之间惊人的相似性,正如所进行的一系列心理物理实验所证明的那样,使我们在其中看到一个基于时间整合和不可靠性的统计测试的人类感知的简单计算格式塔模型。 ,一个相反的框架。
|
ChaLearn Looking at People: IsoGD and ConGD Large-scale RGB-D Gesture Recognition
Authors Jun Wan, Chi Lin, Longyin Wen, Yunan Li, Qiguang Miao, Sergio Escalera, Gholamreza Anbarjafari, Isabelle Guyon, Guodong Guo, Stan Z. Li
ChaLearn大规模手势识别挑战在两个研讨会上与2016年ICPR模式识别国际会议和2017年ICCV计算机视觉国际会议共同举办了两次,吸引了全球200多个团队。这个挑战有两个轨道,分别侧重于孤立和连续的手势识别。本文描述了两个基准数据集的创建,并分析了基于这两个数据集的大规模手势识别的进展。我们讨论了收集手势识别的大规模地面实况注释的挑战,并提供了基于RGB D视频序列的大规模隔离和连续手势识别的现有技术方法的详细分析。除了识别率和平均jaccard指数MJI作为我们先前挑战中使用的评估指标之外,我们还引入校正的分割率CSR度量以评估用于连续手势识别的时间分割的性能。此外,我们提出了一种双向长短期记忆Bi LSTM基线方法,根据卷积姿势机CPM提取的骨架点确定视频分割点。实验证明,所提出的Bi LSTM优于现有技术方法,从CSR的0.8917到0.9639的绝对改进为8.1。
|
End-to-End Learning Deep CRF models for Multi-Object Tracking
Authors Jun Xiang, Ma Chao, Guohan Xu, Jianhua Hou
现有的深度多目标跟踪MOT方法首先学习深度表示来描述目标对象,然后通过优化线性分配问题来关联检测结果。尽管已经证明了成功,但是在相互遮挡下区分目标物体或减少拥挤场景中的身份转换是具有挑战性的。在本文中,我们提出学习深度条件随机场CRF网络,旨在将分配成本建模为一元电位,并将检测结果之间的长期依赖性建模为成对电位。具体来说,我们使用双向长期短期内存LSTM网络来编码长期依赖关系。我们使用标准梯度下降算法将CRF推理作为递归神经网络学习过程,其中一元和成对电位以端到端方式联合优化。包括MOT 2015和MOT 2016在内的具有挑战性的MOT数据集的广泛实验结果表明,与两个基准的已发表作品相比,我们的方法实现了最先进的性能。
|
+圆谐函数变换的特征检测On the Realization and Analysis of Circular Harmonic Transforms for Feature Detection
Authors Hugh L Kennedy
给出了用于角谱估计的圆谐波分解的笛卡尔可分离实现,并提出了一种强大的图像旋转不变特征检测统计量。得到的具有有限脉冲响应FIR的可控滤波器具有低计算复杂度。测试统计量用于检测合成和真实图像中的楔形,即任意角度和未知方向的角。
|
Iris Recognition for Personal Identification using LAMSTAR neural network
Authors Shideh Homayon, Mahdi Salarian
虹膜识别是最重要的生物识别方法之一。这是因为虹膜质地提供了许多功能,如雀斑,冠状,条纹,皱纹,隐窝等。这些功能对于不同的人来说是独一无二的并且是可区分的。虹膜解剖结构中的这种独特特征使得个体之间的区分成为可能。因此,在过去几年中,大量人员一直在努力改善其绩效。在本文中,首先解释了虹膜识别系统的不同常见步骤。然后将一种特殊类型的神经网络用于识别部分。实验结果表明,当主要步骤完成时,可以获得高精度。
|
An Empirical Study on Leveraging Scene Graphs for Visual Question Answering
Authors Cheng Zhang, Wei Lun Chao, Dong Xuan
视觉问题回答这些年来,视觉质量保证引起了人们的极大关注。虽然已经提出了各种算法,但是它们中的大多数都是基于图像和语言特征的不同组合以及多模态注意和融合。在本文中,我们研究了一种替代方法,该方法受到在知识图上运行的传统QA系统的启发。具体来说,我们研究了从用于Visual QA的图像导出的场景图的使用,图像由具有对应于对象实体和边缘到对象关系的节点的图形抽象地表示。我们调整最近提出的图形网络GN来编码场景图并根据输入问题执行结构化推理。我们的实证研究表明,场景图已经可以捕获图像的基本信息,图形网络有可能超越最先进的Visual QA算法,但具有更清晰的架构。通过分析GNs生成的特征,我们可以进一步解释推理过程,为可解释的Visual QA提出了一个有希望的方向。
|
++尺度自适应的高效文本检测It's All About The Scale -- Efficient Text Detection Using Adaptive Scaling
Authors Elad Richardson, Yaniv Azar, Or Avioz, Niv Geron, Tomer Ronen, Zach Avraham, Stav Shapiro
文字可以出现在任此属性要求我们仔细处理图像中的所有像素,以便准确地本地化所有文本实例。特别是,对于本地化小文本区域的更困难的任务,许多方法使用放大的图像或甚至几个重新缩放的图像作为它们的输入。这显着增加了整个图像的处理时间并且不必要地扩大了背景区域。如果我们事先告诉我们图像中文本实例的粗略位置及其近似比例,我们可以自适应地选择要处理哪些区域以及如何重新缩放它们,从而显着减少处理时间。为了估计这个先验,我们提出了一种基于分段的网络,其具有附加的比例预测器,即预测每个文本段的比例的输出通道。网络被应用在按比例缩小的图像上以有效地近似期望的先验,而不处理原始图像的所有像素。然后使用近似的先验来创建仅包含文本区域的紧凑图像,调整大小到规范尺度,再次将其馈送到分割网络以进行细粒度检测。我们展示了我们的方法为固定缩放方案提供了强大的替代方案,在处理更少的像素时实现了与更大输入尺度的等效精度。定性和定量结果显示在ICDAR15和ICDAR17 MLT基准测试中,以验证我们的方法。
|
Real-time Tracking-by-Detection of Human Motion in RGB-D Camera Networks
Authors Alessandro Malaguti, Marco Carraro, Mattia Guidolin, Luca Tagliapietra, Emanuele Menegatti, Stefano Ghidoni
本文提出了一种新的实时跟踪系统,能够改善分布式摄像机网络中的人体姿态估计算法。我们的方法的第一阶段引入了在身体关节水平操作的线性卡尔曼滤波器,用于融合来自网络的不同检测节点的单视图身体姿势并确保它们之间的时间一致性。相反,第二阶段通过拟合具有约束链路大小的人体的分层模型来细化卡尔曼滤波器估计,以便确保跟踪的物理一致性。所提出的方法的有效性通过广泛的实验验证来证明,该验证在一组序列上执行,其基础事实参考由基于商业标记的运动捕捉系统生成。所获得的结果显示所提出的系统如何优于所考虑的现有技术方法,从而给出准确和可靠的估计。此外,所开发的方法既不限制跟踪的人数,也不限制所使用的RGB D相机的数量,位置,同步,帧速率和制造商。最后,系统的实时性能对于大量现实世界的应用程序来说至关重要。
|
FocusNet: Imbalanced Large and Small Organ Segmentation with an End-to-End Deep Neural Network for Head and Neck CT Images
Authors Yunhe Gao, Rui Huang, Ming Chen, Zhe Wang, Jincheng Deng, Yuanyuan Chen, Yiwei Yang, Jie Zhang, Chanjuan Tao, Hongsheng Li
在本文中,我们提出了一种端到端深度神经网络,用于解决头颈部HaN CT图像中大小器官分割不平衡的问题。为了进行鼻咽癌的放射治疗计划,需要事先准确分割10多个危险正常器官。然而,头部大小器官之间的尺寸比可达数百。直接使用这种不平衡器官注释来训练深度神经网络通常会导致不准确的小器官标签图。我们提出了一种新颖的端到端深度神经网络,通过自动定位,ROI汇集和使用专门设计的小器官子网络分割小器官,同时保持大器官分割的准确性来解决这一具有挑战性的问题。强大的主网络具有密集连接的剧烈空间金字塔池和挤压和激发模块,用于分割大器官,其中直接输出大器官标签图。对于小器官,主网络估计其概率位置而不是标签图。每个小器官的高分辨率和多尺度特征体积根据其位置进行ROI汇集,并被馈送到小器官网络中以准确分割小器官。我们提出的网络在收集的实际数据和MICCAI头颈部自动分割挑战2015数据集上进行了广泛测试,并且与现有的分割方法相比显示出优越的性能。
|
++扩大点云感受野的点膨胀卷积Dilated Point Convolutions: On the Receptive Field of Point Convolutions
Authors Francis Engelmann, Theodora Kontogianni, Bastian Leibe
在这项工作中,我们提出扩张点卷积DPC,它大大增加了3D点云上卷积的感受域。正如我们在实验中所展示的那样,感受野的大小与语义分割等密集任务的性能直接相关。我们研究了不同的网络架构和机制,以增加点卷积的感受域大小,并特别提出扩张点卷积。重要的是,我们的扩张机制可以很容易地使用基于最近邻点的点卷积集成到所有现有方法中。为了评估最终的网络架构,我们可视化感知领域并报告S3DIS和ScanNet数据集上3D语义分段任务的竞争分数。
|
DAR-Net: Dynamic Aggregation Network for Semantic Scene Segmentation
Authors Zongyue Zhao, Min Liu, Karthik Ramani
传统的基于网格邻居的静态池已经成为点云几何分析的约束。在本文中,我们提出了DAR Net,一种专注于动态特征聚合的新型网络架构。 DAR Net的核心思想是生成一个自适应池框架,该框架同时考虑场景复杂性和局部几何特征。提供可变的半局部感受域和权重,骨架充当连接局部卷积特征提取器和全局重复特征积分器的桥。与采用静态池化方法的现有技术架构相比,室内场景数据集的实验结果显示了所提出的方法的优点。
|
+++多场景行人重识别问题Fairest of Them All: Establishing a Strong Baseline for Cross-Domain Person ReID
Authors Devinder Kumar, Parthipan Siva, Paul Marchwica, Alexander Wong
人员识别ReID仍然是计算机视觉中非常困难的挑战,对于大规模视频监控场景至关重要,其中个人可以在不同时间出现在不同的摄像机视图中。最近有兴趣使用跨域方法来应对这一挑战,该方法利用来自与目标域不同的源域的数据。这种方法对于现实世界的广泛部署更为实用,因为它们不需要现场培训,如无监督或域转移方法或现场手动注释和培训,如同监督方法。在本研究中,我们采用系统的方法为跨域人员ReID建立大型基线源域和目标域。我们通过综合分析来研究文献中提出的源域之间的相似性,并研究逐步增加源域大小的影响。这使我们能够建立平衡的源域和目标域分割,从而促进源域和目标域的多样性。此外,利用从最先进的监督人员识别方法中吸取的经验教训,我们为跨域人ReID建立了强有力的基线方法。实验表明,由两个最大的人ReID域SYSU和MSMT组成的源域在六个常用目标域中表现良好。此外,令人惊讶的是,我们表明,最近常用的两个域PRID和GRID的查询图像太少,无法提供有意义的见解。因此,根据我们的研究结果,我们提出以下跨域人员ReID的平衡基线,包括由SYSU,MSMT,机场和3DPeS组成的固定多源域,以及由市场1501,DukeMTMC reID组成的多目标域, CUHK03,PRID,GRID和VIPeR。
|
Optical Flow for Intermediate Frame Interpolation of Multispectral Geostationary Satellite Data
Authors Thomas Vandal, Ramakrishna Nemani
卫星数据在天气跟踪和建模,生态系统监测,野火探测和土地覆盖变化等领域的应用在很大程度上取决于与观测的空间,光谱和时间分辨率相关的权衡。例如,地球静止气象跟踪卫星设计为全天多次拍摄半球形快照,但传感器硬件限制数据收集。在这项工作中,我们通过开发一种使用光流视频插值深度卷积神经网络对多光谱卫星图像进行时间上采样的方法来解决这一局限。所提出的模型将Super SloMo SSM从单光流估计扩展到多通道,其中每个波长带计算流量。我们将此技术应用于GOES R Advanced Baseline Imager中尺度数据集的多达8个多光谱波段,以便在15分钟到1分钟的时间内将全盘半球快照暂时增强。通过大量实验,我们发现SSM大大优于线性插值基线,多通道光流改善了GOES ABI的性能。此外,我们讨论了与多光谱地球静止卫星图像的时间插值有关的挑战和开放性问题。
|
ROAM: Recurrently Optimizing Tracking Model
Authors Tianyu Yang, Pengfei Xu, Runbo Hu, Hua Chai, Antoni B. Chan
在线更新跟踪模型以适应对象外观变化是具有挑战性的。对于基于SGD的模型优化,使用较大的学习速率可能有助于更快地收敛模型,但存在让损失疯狂徘徊的风险。因此,传统的优化方法通常选择相对较小的学习速率并迭代以获得更多步骤来收敛模型,这是耗时的。在本文中,我们建议离线训练一个递归神经优化器来预测元学习设置中模型更新的自适应学习速率,这可以在几个梯度步骤中收敛模型。这大大提高了更新跟踪模型的收敛速度,同时实现了更好的性能。此外,我们还提出了一种简单而有效的训练技巧,称为随机滤波器缩放,以防止过度拟合,从而大大提高性能。最后,我们在OTB,VOT,GOT 10K,TrackingNet和LaSOT基准测试中广泛评估我们的跟踪器ROAM,我们的方法对最先进的算法表现出色。
|
++学习和重建鞋的磨损模式Learning Wear Patterns on Footwear Outsoles Using Convolutional Neural Networks
Authors Xavier Francis, Hamid Sharifzadeh, Angus Newton, Nilufar Baghaei, Soheil Varastehpour
随着时间的推移,鞋类外底获得了穿着它们的独特特征。法医科学家在很大程度上依靠他们通过多年经验获得的技能和知识来分析这些特征。在这项工作中,我们提出了一个卷积神经网络模型,可以预测一个独特的鞋子数据集的磨损模式,抓住一双鞋的生命和磨损。我们提出了一个额外的架构,能够在给定的一周内将外底重建回原始状态,并提供两种模型性能的实证评估。
|
++人脸识别红外偏振与可见光Attribute-Guided Deep Polarimetric Thermal-to-visible Face Recognition
Authors Seyed Mehdi Iranmanesh, Nasser M. Nasrabadi
在本文中,我们提出了一个属性引导深度耦合学习框架,以解决极化热面部照片与可见面部库相匹配的问题。耦合框架包含两个子网络,一个专用于可见光谱,另一个子网专用于极化热谱。每个子网络由生成的对抗性网络GAN架构组成。我们提出了一种新颖的属性引导耦合生成对抗网络AGC GAN架构,该架构利用面部属性来改善热到可见面部识别性能。所提出的AGC GAN利用面部属性并利用多个损失函数来学习公共嵌入子空间中的丰富的判别特征。为了在保留判别信息的同时实现逼真的照片重建,我们还在耦合损失函数中添加了感知损失项。进行消融研究以显示不同损失函数对优化所提出方法的有效性。此外,使用极化数据集证明了模型与现有技术模型相比的优越性。
Polarimetric Thermal Face dataset [7]
|
++人体姿态估计与配准Learning Body Shape and Pose from Dense Correspondences
Authors Yusuke Yoshiyasu, Lucas Gamez
在本文中,我们解决了从2D图像数据集学习3D人体姿势和体形的问题,而不必使用3D数据集的体形和姿势。这个想法是使用图像点和体表之间的密集对应,可以在野外2D图像中进行注释,并从中提取和聚合3D信息。为此,我们提出了一种称为变形的训练策略,并学习我们在哪里交替变形表面配准和深度卷积神经网络ConvNets的训练。与以前的方法不同,我们的方法不需要来自动作捕捉MoCap系统的3D姿势注释或人工干预来验证3D姿势注释。
|
Segmenting Hyperspectral Images Using Spectral-Spatial Convolutional Neural Networks With Training-Time Data Augmentation
Authors Jakub Nalepa, Lukasz Tulczyjew, Michal Myller, Michal Kawulok
高光谱成像提供有关扫描对象的详细信息,因为它捕获了大量波段内的光谱特征。由于其在各种领域中的广泛适用性,这种数据的分类已经成为一个活跃的研究课题。深度学习确立了该领域的最新技术水平,并构成了当前的研究主流。在这封信中,我们介绍了一种新的光谱空间卷积神经网络,它受益于一系列数据增强技术,这些技术有助于解决缺乏地面实况训练数据的现实生活问题。我们的严格实验表明,该方法优于文献中的其他光谱空间技术,可实时进行精确的高光谱分类。
|
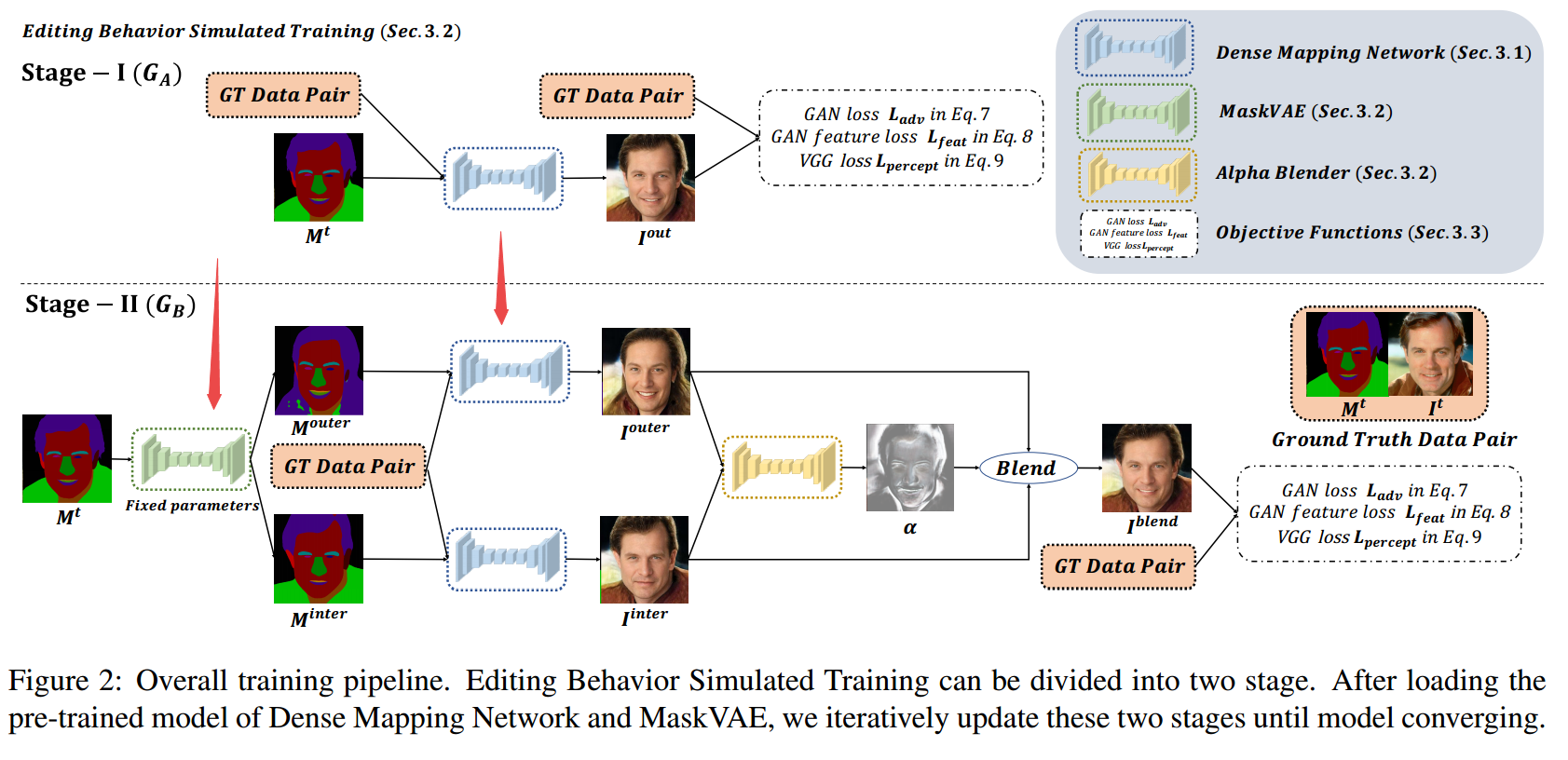
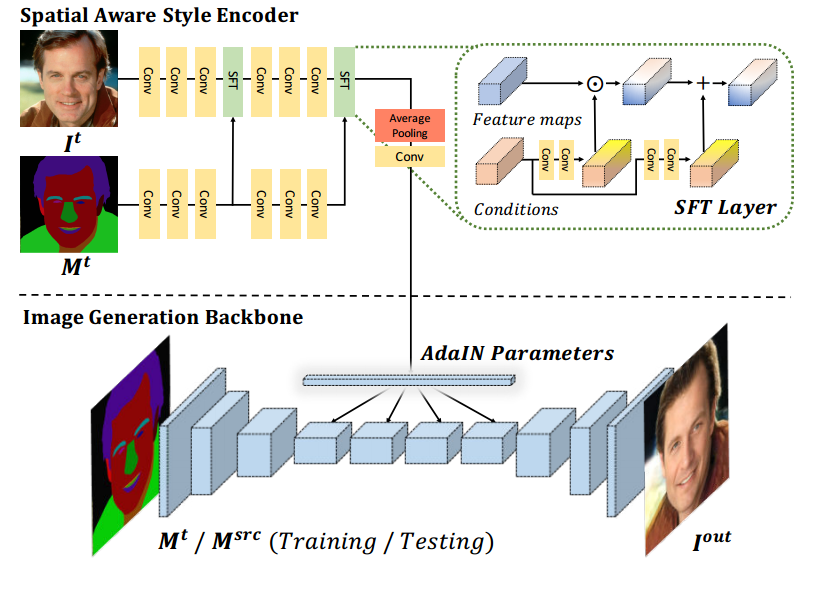
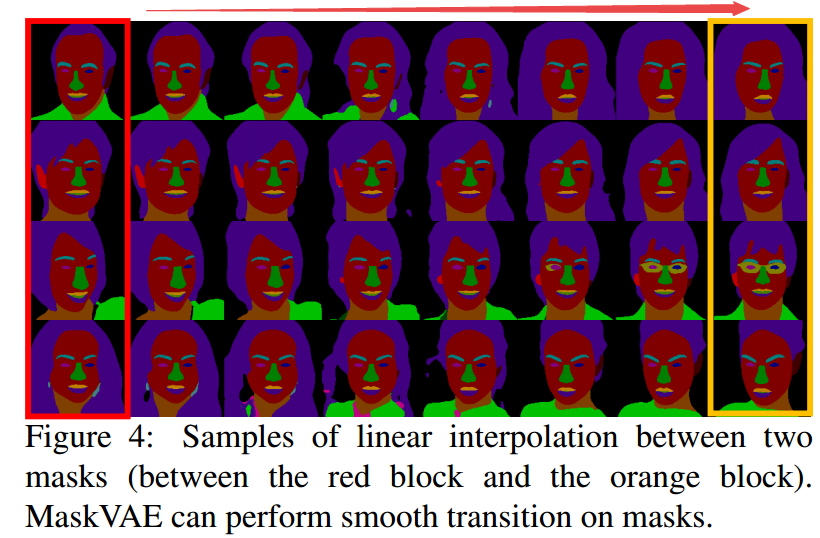
+++基于视觉的人脸解译和操作MaskGAN: Towards Diverse and Interactive Facial Image Manipulation
Authors Cheng Han Lee, Ziwei Liu, Lingyun Wu, Ping Luo
近年来,面部图像处理取得了很大进展。然而,先前的方法或者在预定义的一组面部属性上操作,或者使用户几乎不能自由地交互操纵图像。为了克服这些缺点,我们提出了一种称为MaskGAN的新型框架,可实现多样化和交互式的面部操作。我们的主要观点是语义掩模作为灵活的面部操作的适当中间表示,具有保真度。 MaskGAN有两个主要组件:1个密集映射网络和2个编辑行为模拟训练。具体而言,密集映射网络学习自由形式用户修改掩码和目标图像之间的样式映射,从而实现不同的生成结果。编辑行为模拟训练模拟源掩码上的用户编辑行为,使整个框架对各种操纵输入更加健壮。为了便于进行广泛的研究,我们构建了一个大型高分辨率人脸数据集,其中包含名为CelebAMask HQ的细粒度掩模注释。 MaskGAN在两个具有挑战性的任务属性转移和样式复制方面进行了全面评估,展示了优于其他最先进方法的卓越性能。代码,模型和数据集可在网址获得
|
++基于视频的心率测量Remote Heart Rate Measurement from Highly Compressed Facial Videos: an End-to-end Deep Learning Solution with Video Enhancement
Authors Zitong Yu, Wei Peng, Xiaobai Li, Xiaopeng Hong, Guoying Zhao
远程光电容积描记术rPPG旨在无需任何接触地测量心脏活动,在许多应用中具有很大的潜力,例如远程医疗保健。现有的rPPG方法依赖于分析面部视频的非常精细的细节,这些细节容易受到视频压缩的影响。在这里,我们提出了一个使用隐藏的rPPG信息增强和关注网络的两阶段端到端方法,这是第一次尝试对抗视频压缩丢失并从高度压缩的视频中恢复rPPG信号。该方法包括两个部分:1个用于视频增强的时空视频增强网络STVEN,以及2个用于rPPG信号恢复的rPPG网络rPPGNet。 rPPGNet可以独立工作以实现强大的rPPG测量,并且可以添加和联合培训STVEN网络,以进一步提高性能,尤其是在高度压缩的视频上。在两个基准数据集上进行了综合实验,表明1,所提出的方法不仅可以在具有高质量视频对的压缩视频上实现卓越的性能,而且还可以在仅有压缩视频的情况下很好地推广新颖数据,这意味着现实世界的应用。
|
Triangulation: Why Optimize?
Authors Seong Hun Lee, Javier Civera
几十年来,人们普遍认为,两种视图三角测量的黄金标准是基于重投影误差来最小化成本。在这项工作中,我们挑战这个想法。我们提出了一种新的经典中点方法的替代方案,可以显着降低2D误差和视差误差。它提供了一种数字稳定的封闭形式解决方案,仅基于一对背投射光线。由于我们的解决方案是旋转不变的,它也可以应用于鱼眼和全向摄像机。我们表明,对于小视差角,我们的方法在结合2D,3D和视差精度方面优于现有技术,同时实现相当的速度。
|
Rethinking Classification and Localization for Cascade R-CNN
Authors Ang Li, Xue Yang, Chongyang Zhang
我们通过简单的功能共享机制扩展了最先进的Cascade R CNN。我们的方法侧重于高IoU的性能提升,但低IoU阈值的降低是该检测器遭受的一个关键问题。特征共享非常有用,我们的结果表明,如果将这种机制嵌入到所有阶段,我们可以轻松缩小最低阶段和前阶段之间在低IoU阈值上的差距,而无需求助于常用的测试集合,而是求助于网络本身。我们还观察到从功能共享中受益的所有IoU阈值的明显改进,并且得到的级联结构可以轻松匹配或超过其对应物,只是引入了可忽略的额外参数。为了突破这个范围,我们在COCO对象检测上展示了43.2 AP,没有任何铃声和口哨声,包括测试集合,大大超过了之前的Cascade R CNN。我们的框架易于实施,我们希望它可以作为未来研究的一般和强大的基准。
|
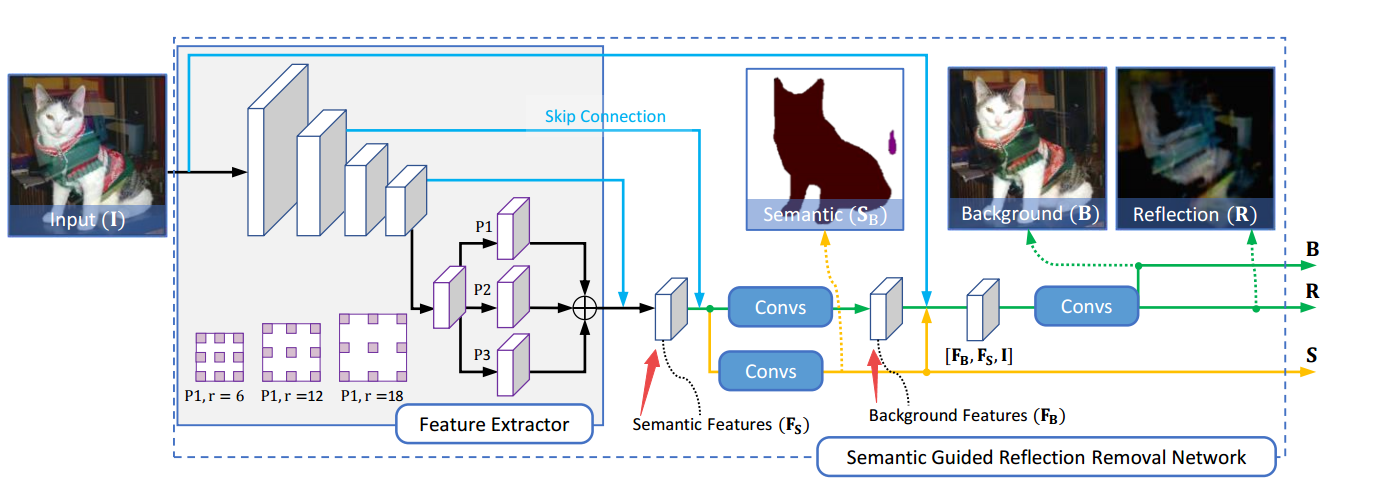
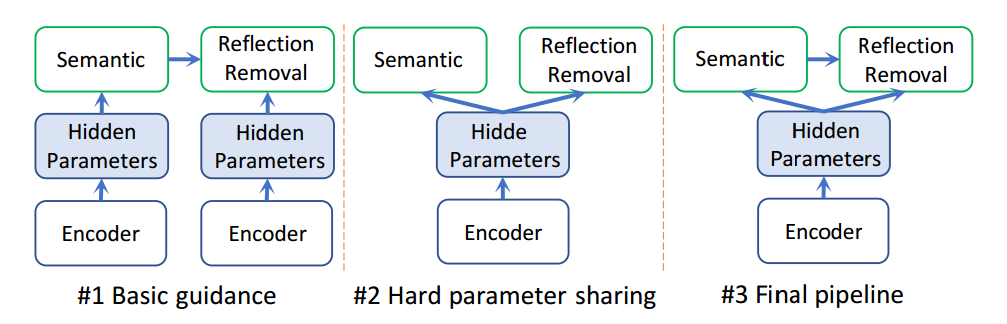
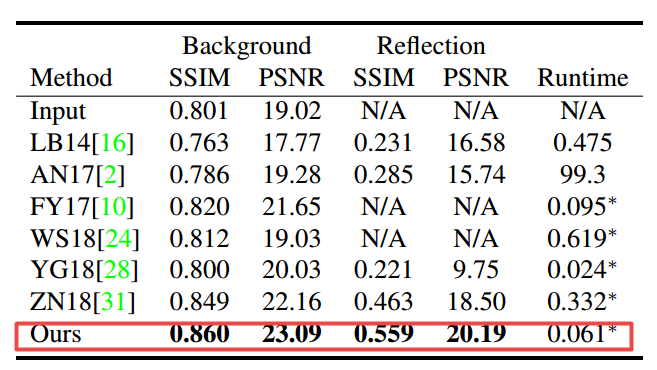
+++语义分割引导的反射去除模型Semantic Guided Single Image Reflection Removal
Authors Yunfei Liu, Yu Li, Shaodi You, Feng Lu
在捕获玻璃窗后面的场景的图像中反射是常见的,这不仅是视觉上的干扰,而且还影响其他计算机视觉算法的性能。单个图像反射消除是一个不适合的问题,因为每个像素的颜色需要分成两个值,即所需的清晰背景和
|
Context Model for Pedestrian Intention Prediction using Factored Latent-Dynamic Conditional Random Fields
Authors Satyajit Neogi, Michael Hoy, Kang Dang, Hang Yu, Justin Dauwels
行人互动的平稳处理是自动驾驶汽车AV和高级驾驶员辅助系统ADAS的关键要求。这种系统要求尽早准确地预测行人在车辆前方的交叉行为。行人行为预测的现有方法利用行人运动,她在场景中的位置以及静态环境变量,例如交通灯,斑马线等。我们强调必须尽早预测这些系统的平稳运行。为此,我们介绍了车辆互动对行人意图的影响。在本文中,我们通过包含这样的车辆交互环境来显示预测时间的明显进步。我们将方法应用于两个不同的数据集,一个是内部收集的NTU数据集,另一个是公共现实生活基准JAAD数据集。我们还提出了通用图形模型Factored Latent Dynamic Conditional Random Fields FLDCRF,用于单标签和多标签序列预测以及联合交互建模任务。 FLDCRF在数据集上优于长短期记忆LSTM网络,在相同的时间序列特征上,每个数据集可以扫描100个序列。虽然现有的最佳系统在实际事件发生前0.38秒以70精度预测行人停止行为,但我们的系统在跨数据集的实际事件之前平均达到至少0.9秒的准确度。
|
+Gan盲去噪 Blind Deblurring Using GANs
Authors Manoj Kumar Lenka, Anubha Pandey, Anurag Mittal
去模糊是将模糊图像恢复到清晰图像的任务,检索由于模糊而丢失的信息。在盲目去模糊中,我们没有关于模糊内核的信息。由于去模糊可以被视为图像到图像翻译任务,因此基于深度学习的解决方案(包括使用GAN生成对抗网络的解决方案)已被证明对去模糊有效。它们中的大多数具有编码器解码器结构。我们的目标是尝试不同的GAN结构,并通过对现有结构进行各种修改来改进其性能,以进行有监督的去模糊。在有监督的去模糊中,我们有成对的模糊和相应的清晰图像,而在无监督的情况下,我们有一组模糊和清晰的图像,但它们之间没有对应关系。对结构进行修改以改善模型的全局感知。由于模糊本质上是不均匀的,因此对于去模糊,我们需要整个图像的全局信息,而在CNN中使用的卷积仅能够提供局部感知。深度模型可用于改善全局感知,但由于大量参数使其难以收敛并且推理时间增加,为了解决这个问题,我们建议使用先前在语言翻译和其他中使用的注意模块非局部块。去模糊中的图像到图像翻译任务。使用残余连接还可以改善去模糊的性能,因为较低层的特征被添加到模型的上层。已经发现,诸如L1,L2和感知损失之类的经典损失在与对抗性损失一起加入时也有助于训练GAN。我们还连接图像的边缘信息,以观察其对去模糊的影响。我们还使用反馈模块来保留长期依赖性https://github.com/lenka98/Bind-Deblurring-using-GANs
|
A Benchmark on Tricks for Large-scale Image Retrieval
Authors ByungSoo Ko, Minchul Shin, Geonmo Gu, HeeJae Jun, Tae Kwan Lee, Youngjoon Kim
已经对度量学习进行了许多研究,这已经成为实例级图像检索的最佳表现方法的关键因素。同时,对预处理和后处理技巧的关注较少,可以显着提高性能。此外,我们发现大多数先前的研究使用小规模数据集来简化处理。因为深度学习模型中的特征表示的行为取决于域和数据,所以当使用适当的检索技巧组合时,理解模型在大规模环境中的行为是很重要的。在本文中,我们广泛分析了众所周知的预处理,后处理技巧及其组合对大规模图像检索的影响。我们发现正确使用这些技巧可以显着提高模型性能,而无需复杂的架构或引入损失,这可以通过在Google Landmark Retrieval Challenge 2019上获得竞争结果得到证实。
|
Genetic Deep Learning for Lung Cancer Screening
Authors Hunter Park, Connor Monahan
卷积神经网络CNN在改进计算机辅助检测CADe方面显示出巨大的希望。从通过乳房X线照相术发现的肿瘤分类为良性或恶性到CT结肠成像中自动检测结直肠息肉,这些进展有助于减少进行侵入性检测的进一步评估的需要,并通过在当今快节奏中充当第二观察者来防止错过诊断的错误和高容量的临床环境。由于过去几年的深度学习创新,CADe方法变得更快,更精确。随着诸如初始模块和剩余连接的利用之类的进步,设计CNN架构的方法已经成为一门艺术。习惯上使用经过验证的模型并根据数据集对特定任务进行微调,通常需要繁琐的工作。我们使用遗传算法GA进行了研究,以进行神经建筑搜索NAS,以生成新的CNN架构,以发现胸部X射线CXR中的早期肺癌。使用超过一万两千个活检证实的肺癌病例数据集,经过训练的分类模型达到了97.15的准确度,PPV为99.88,NPV为94.81,击败了初始V3和ResNet 152等模型,同时减少了参数数量因子分别为4和14。
|
Learning Instance-wise Sparsity for Accelerating Deep Models
Authors Chuanjian Liu, Yunhe Wang, Kai Han, Chunjing Xu, Chang Xu
探索高效率和低内存使用的深度卷积神经网络对于各种机器学习任务非常重要。大多数现有方法用于通过操纵没有数据的参数或滤波器来加速深度模型,例如修剪和分解。相反,我们通过尊重数据之间的差异从不同的角度研究这个问题。通过识别不同实例的信息特征来开发实例智能特征修剪。具体来说,通过研究特征衰减正则化,我们期望深度神经网络中每个实例的中间特征映射是稀疏的,同时保持整体网络性能。在在线推理期间,可以消除由训练有素的神经网络的中间层提取的输入图像的细微特征,以加速后续计算。我们进一步采用变异系数作为选择适合加速的层的度量。对基准数据集和网络进行的大量实验证明了所提方法的有效性。
|
Attribute Aware Pooling for Pedestrian Attribute Recognition
Authors Kai Han, Yunhe Wang, Han Shu, Chuanjian Liu, Chunjing Xu, Chang Xu
本文通过设计一种新的属性感知池算法,将深度卷积神经网络CNN的强度扩展到行人属性识别问题。由于较大的标签空间以及属性纠缠和相关性,现有的vanilla CNN不能直接应用于处理多属性数据。我们通过充分利用不同属性之间的相关性来应对阻碍多属性分类的CNN发展的这些挑战。采用多分支架构来融合不同区域的属性。除了基于每个分支本身的预测之外,还使用每个分支的上下文信息来进行决策。开发属性感知池以集成两种信息。因此,通过利用上下文信息,可以准确地识别与其他人不清楚或纠结的属性。对基准数据集的实验表明,所提出的汇集方法适当地探索和利用行人属性识别的属性之间的相关性。
|
Pick-and-Learn: Automatic Quality Evaluation for Noisy-Labeled Image Segmentation
Authors Haidong Zhu, Jialin Shi, Ji Wu
深度学习方法在许多领域取得了很好的成绩,但在训练过程中,他们仍然在嘈杂的标记图像上挣扎。考虑到注释质量必不可少地依赖于丰富的专业知识,这个问题在医学图像领域中更为重要。如何在没有进一步注释的情况下消除噪声标签对分段任务的干扰仍然是一个重大挑战。在本文中,我们介绍了我们的标签质量评估策略,用于深度神经网络自动评估每个标签的质量,这是没有明确提供的,以及关于清洁注释的标签的培训。我们提出了一种网络解决方案,可以自动评估训练集中标签的相对质量,并使用好的标准来调整网络参数。我们还设计了一个过度拟合的控制模块,让网络在训练过程中最大限度地学习精确的注释。对公共生物医学图像分割数据集的实验证明,该方法优于基线方法,在不同的噪声水平下保持了高精度和良好的泛化。
|
Hybrid-Attention based Decoupled Metric Learning for Zero-Shot Image Retrieval
Authors Binghui Chen, Weihong Deng
在零镜头图像检索ZSIR任务中,嵌入学习变得更具吸引力,然而,许多方法遵循传统的度量学习思想并省略了零镜头设置背后的问题。在本文中,我们首先强调学习视觉判别度量和防止学习者在ZSIR中的部分选择性学习行为的重要性,然后提出解耦度量学习DeML框架来单独实现这些。我们不是粗略地优化统一度量,而是将其分解为多个注意力特定部分,以便反复引发歧视并明确地增强泛化。它们主要由基于随机游走图传播的对象关注模块和基于对手约束的信道关注模块实现。我们证明了在流行的基准测试中解决ZSIR中的重要问题的必要性,大大超过了theart方法的状态。代码可在
|
Forced Spatial Attention for Driver Foot Activity Classification
Authors Akshay Rangesh, Mohan M. Trivedi
本文提供了一种简单的解决方案,用于可靠地解决与场景中显着对象的空间位置相关的图像分类任务。与设计为对场景中的对象的平移不变的传统图像分类方法不同,我们关注于输出类相对于感兴趣对象位于图像内的位置而变化的任务。为了处理图像分类任务的这种变体,我们建议用依赖于域的强制空间注意FSA损失来增加标准交叉熵分类损失,其实质上迫使网络处理与期望输出类相关联的图像中的特定区域。为了证明这种损失函数的效用,我们考虑了驾驶员脚活动分类的任务,其中每个活动与驾驶员的脚在场景中的位置强烈相关。使用我们提出的损失函数进行训练可以显着提高精度,更好地推广和抗噪声,同时避免了对非常大的数据集的需求。
|
+++四叉树生成网络基于稀疏卷积用于高效场景分割Quadtree Generating Networks: Efficient Hierarchical Scene Parsing with Sparse Convolutions
Authors Kashyap Chitta, Jose M. Alvarez, Martial Hebert
由于特征图和输出预测的高空间分辨率,使用卷积神经网络的语义分割是一种记忆密集型任务。在本文中,我们提出了Quadtree Generating Networks QGNs,这是一种能够大幅减少现代语义分割网络内存占用的新方法。关键的想法是使用四叉树来表示预测和目标分割掩码而不是密集像素网格。我们的四叉树表示实现了输入图像的分层处理,其中计算要求最高的层仅用于包含类之间边界的图像中的区域。此外,给定训练模型,我们的表示使灵活的推理方案能够折衷准确性和计算成本,允许网络适应诸如嵌入式设备的受限情况。我们展示了我们的方法在Cityscapes,SUN RGBD和ADE20k数据集上的优势。在Cityscapes上,与具有相似内存消耗的扩张网络相比,我们获得了相对3 mIoU的改进,并且与大型扩张网络相比仅获得3相对mIoU下降,同时将内存消耗减少了4倍以上。
|
++葡萄图像分割Grape detection, segmentation and tracking using deep neural networks and three-dimensional association
Authors Thiago T. Santos, Leonardo L. de Souza, Andreza A. dos Santos, Sandra Avila
作为产量预测,精确农业和自动收获的农业应用需要能够从低成本传感装置推断培养状态的系统。使用经济实惠的相机与计算机视觉相结合的近端感应已经看到了一种很有前途的替代方案,在卷积神经网络CNN作为自然图像中挑战模式识别问题的替代方案之后得到了加强。考虑到水果种植监测和自动化,一个基本问题是果园中个别水果的检测,分割和计数。在这里,我们表明,对于葡萄酒,一种在形状,颜色,大小和紧凑性方面具有很大差异的作物,葡萄簇可以使用最先进的CNN成功检测,分割和跟踪。在包含来自田间拍摄的图像的408个葡萄簇的数据集中,我们已经达到了高达0.91的F1分数,例如分割,每个群集与图像中的其他结构的精细分离,其允许更准确地评估果实大小和形状。我们还表明,可以沿着记录果园行的视频序列识别和跟踪聚类。我们还提供了一个公共数据集,其中包含300个图像中正确注释的葡萄簇和用于在自然图像中分割复杂对象的新颖注释方法。所呈现的用于注释,培训,评估和跟踪图像中农业模式的管道可以复制用于不同的作物和生产系统。它可用于开发用于若干农业和环境应用的传感组件。https://github.com/thsant/wgisd
|
VITAL: A Visual Interpretation on Text with Adversarial Learning for Image Labeling
Authors Tao Hu, Chengjiang Long, Leheng Zhang, Chunxia Xiao
在本文中,我们提出了一种新的方法来解释文本信息,通过从文本生成的多个高分辨率和照片真实合成图像中提取视觉特征呈现生成对抗网络GAN,以提高图像标记的性能。首先,我们设计了堆叠的生成多对抗网络GMAN,StackGMAN,当前最新技术的修改版本文本到图像GAN,StackGAN,以生成具有以文本为条件的各种先前噪声的多个合成图像。然后我们从生成的合成图像中提取深层视觉特征,以探索文本的基本视觉概念。最后,我们将基于合成图像的图像级视觉特征,文本级特征和视觉特征组合在一起,以预测图像的标签。我们对两个基准数据集进行了实验,实验结果清楚地证明了我们提出的方法的有效性。
|
To Learn or Not to Learn: Analyzing the Role of Learning for Navigation in Virtual Environments
Authors Noriyuki Kojima, Jia Deng
在本文中,我们比较了基于学习的方法和经典的虚拟环境导航方法。我们构建了经典的导航代理,并证明它们在两个标准基准MINOS和斯坦福大型3D室内空间中胜过最先进的学习型代理。我们进行详细分析,以研究学习代理和经典代理的优缺点,以及虚拟环境的特征如何影响导航性能。我们的研究结果表明,学习代理具有较差的避碰和内存管理,但在处理歧义和噪声方面具有优势。这些结果可以为将来的导航代理设计提供信息
|
Tell Me What to Track
Authors Qi Feng, Vitaly Ablavsky, Qinxun Bai, Guorong Li, Stan Sclaroff
近年来,已经对基于深度学习的视觉对象跟踪器进行了彻底的研究,但是处理目标的遮挡和/或快速运动仍然具有挑战性。在这项工作中,我们认为对目标的自然语言NL描述进行调节可以提供长期不变性的信息,从而有助于应对典型的跟踪挑战。然而,推导出一种将基于外观的跟踪的强度与语言形态相结合的公式并不简单。我们通过检测公式提出了一种新的深度跟踪,可以利用NL描述。在跟踪器的检测阶段期间,由提议网络生成与给定NL描述相关的区域。然后,我们的基于LSTM的跟踪器预测基于NL的检测阶段提出的区域的目标更新。在基准测试中,我们的方法与最先进的跟踪器相比具有竞争力,同时它在具有明确和精确语言注释的目标上优于所有其他跟踪器。它在没有边界框的情况下初始化时也击败了最先进的NL跟踪器。我们的方法在单个GPU上以超过30 fps的速度运行。
|
Accurate and Robust Pulmonary Nodule Detection by 3D Feature Pyramid Network with Self-supervised Feature Learning
Authors Jingya Liu, Liangliang Cao, Oguz Akin, Yingli Tian
以高灵敏度和特异性准确检测肺结节对于CT扫描自动诊断肺癌至关重要。尽管许多基于深度学习的算法在提高结节检测的准确性方面取得了很大进展,但高假阳性率仍然是一个挑战性问题,限制了常规临床实践中的自动诊断。此外,由于强度等级和机器噪声的差异,从多个制造商收集的CT扫描可能影响计算机辅助诊断CAD的稳健性。在本文中,我们提出了一种基于3D特征金字塔网络3DFPN的新型自监督学习辅助肺结节检测框架,通过采用多尺度特征提高结节的分辨率以及平行自上而下来提高结节检测的灵敏度。传递高级语义特征的路径,以补充低级别的一般特征。此外,引入高灵敏度和特异性HS2网络以通过跟踪位置历史图像LHI上的每个结节候选者的连续CT切片中的外观变化来消除假阳性结节候选者。此外,为了在不使用额外注释的情况下跨不同CT扫描仪捕获的数据提高所提出的框架的性能一致性,应用有效的自监督学习模式来从大规模未标记数据中学习CT扫描的时空特征。我们的方法的性能和稳健性在几个公开可用的数据集上进行评估,并显着提高了性能。所提出的框架能够以高灵敏度和特异性准确地检测肺结节,并且实现90.6的灵敏度,每次扫描具有18个假阳性,其优于LUNA16数据集的现有技术结果15.8。
|
Automated Lesion Detection by Regressing Intensity-Based Distance with a Neural Network
Authors Kimberlin M.H. van Wijnen, Florian Dubost, Pinar Yilmaz, M. Arfan Ikram, Wiro J. Niessen, Hieab Adams, Meike W. Vernooij, Marleen de Bruijne
局灶性脑血管病灶的定位MRI是神经系统疾病病因学研究的重要组成部分。然而,手术注释病变可能具有挑战性,耗时且受观察者偏见的影响。自动检测方法通常需要用于训练的体素明智注释。我们提出了一种用于自动病变检测的新方法,该方法可以在仅用每个病灶点注释而不是完整分割的扫描上训练。根据点注释及其相应的强度图像,我们计算各种距离图DM,指示基于空间距离,强度距离或两者的到病变的距离。我们训练一个完全卷积的神经网络FCN来预测这些DM,以获得看不见的强度图像。预测的DM中的局部最佳值预计对应于病变位置。我们展示了这种方法在大脑MRI数据集上检测白质增大的血管周围空间的可能性,其中包括1000次扫描的独立测试集。我们的方法匹配在独立集合上计算的专家评估者的内部评估者表现。我们比较了不同类型的距离图,表明在用于训练FCN的距离图中加入强度信息可以大大提高性能。
|
Solving the Robot-World Hand-Eye(s) Calibration Problem with Iterative Methods
Authors Amy Tabb, Khalil M. Ahmad Yousef
机器人世界,手眼校准是确定机器人末端执行器和摄像机之间的变换以及机器人基座和世界坐标系之间的变换的问题。此关系已建模为mathbf AX mathbf ZB,其中mathbf X和mathbf Z是未知的齐次转换矩阵。许多机器人操作任务的成功执行取决于准确地确定这些矩阵,并且我们对使用校准用于视觉任务特别感兴趣。在这项工作中,我们描述了一组方法,包括两个成本函数类,三个不同的旋转组件参数,以及可分离与同时配方。我们在真实数据集和模拟数据集上探索这组方法的行为,并与其他七种最先进的方法进行比较。与现有技术相比,我们的方法集合在许多指标上返回更高的准确性。方法的集合扩展到机器人世界手多眼校准的问题,结果显示在同一机器人上安装的两个和三个摄像机。
|
+天文学太阳观测图像修复Solar Image Restoration with the Cycle-GAN Based on Multi-Fractal Properties of Texture Features
Authors Peng Jia, Yi Huang, Bojun Cai, Dongmei Cai
纹理是太阳图像中最明显的特征之一,它通常由纹理特征描述。由于来自相同波长的太阳图像的纹理相似,我们假设太阳图像的纹理特征是多分形。基于这个假设,我们提出了一种基于纯数据的图像恢复方法,以几个高分辨率太阳图像作为参考,我们使用周期一致性对抗网络来恢复相同稳定物理过程的毛刺图像,在同一望远镜获得的相同波长。我们用模拟和真实的观测数据测试我们的方法,发现我们的方法可以提高太阳图像的空间分辨率,而不会丢失任何帧。因为我们的方法不需要配对训练集或附加仪器,所以它可以用作通过观看有限望远镜或具有地层自适应光学系统的望远镜获得的太阳图像的后处理方法。
|
Charting the Right Manifold: Manifold Mixup for Few-shot Learning
Authors Puneet Mangla, Mayank Singh, Abhishek Sinha, Nupur Kumari, Vineeth N Balasubramanian, Balaji Krishnamurthy
很少有镜头学习算法旨在通过仅少数标记示例来学习能够适应看不见的类的模型参数。最近的正则化技术Manifold Mixup专注于学习通用表示,对数据分布的微小变化具有鲁棒性。由于少数镜头学习的目标与强大的表示学习密切相关,因此我们在此问题设置中研究Manifold Mixup。自我监督学习是另一种仅使用数据的固有结构来学习语义上有意义的特征的技术。这项工作使用自我监督和正规化技术研究了学习相关特征流形对于少数射击任务的作用。我们观察到,通过Manifold Mixup使通过自我监督技术丰富的特征流形正规化显着改善了很少的镜头学习性能。我们表明,我们提出的方法S2M2在标准的几个镜头学习数据集(如CIFAR FS,CUB和mini ImageNet)上击败了现有技术精度,达到了3 8。通过大量实验,我们发现使用我们的方法学习的特征可以推广到复杂的几个镜头评估任务,跨域方案,并且可以抵御数据分布的轻微变化。
|
Two-Stream CNN with Loose Pair Training for Multi-modal AMD Categorization
Authors Weisen Wang, Zhiyan Xu, Weihong Yu, Jianchun Zhao, Jingyuan Yang, Feng He, Zhikun Yang, Di Chen, Dayong Ding, Youxin Chen, Xirong Li
本文研究了一种多模态输入的年龄相关性黄斑变性AMD的自动分类,其包括彩色眼底图像和来自特定眼睛的光学相干断层扫描OCT图像。以前的工作使用传统方法,包括无法联合优化的特征提取和分类器训练。相比之下,我们提出了端到端的双流卷积神经网络CNN。 CNN的融合层适合于融合来自眼底和OCT流的信息的需要。为了生成更多的多模式训练实例,我们引入了松散对训练,其中眼底图像和OCT图像基于类标签而不是眼睛配对。此外,为了直观地解释各个模态如何做出贡献,我们将类激活映射技术扩展到多模态场景。从门诊诊所收集的真实世界数据集的实验证明了我们的多模式AMD分类提议的可行性。
|
What Should I Ask? Using Conversationally Informative Rewards for Goal-Oriented Visual Dialog
Authors Pushkar Shukla, Carlos Elmadjian, Richika Sharan, Vivek Kulkarni, Matthew Turk, William Yang Wang
参与目标导向对话的能力使人类能够获得知识,减少不确定性并更有效地执行任务。然而,人工代理人在进行目标驱动的对话时仍远远落后于人类。在这项工作中,我们专注于面向目标的视觉对话的任务,旨在自动生成一系列关于具有单一目标的图像的问题。这项任务具有挑战性,因为这些问题不仅必须与实现目标的策略一致,还要考虑图像中的上下文信息。我们提出了一种端到端的面向目标的视觉对话系统,它将强化学习与规范化信息增益相结合。与之前为该任务提出的方法不同,我们的工作受到Rational Speech Act框架的激励,该框架模拟了人类探究实现目标的过程。我们在GuessWhat数据集上测试了我们模型的两个版本,在生成问题以查找图像中未公开的对象的任务中获得了优于现有技术模型的重要结果。
|
++视觉任务间的二阶语义相似性Learnable Parameter Similarity
Authors Guangcong Wang, Jianhuang Lai, Wenqi Liang, Guangrun Wang
大多数现有方法都侧重于特定的视觉任务,而忽略了它们之间的关系。估计任务关系揭示了高阶语义概念的学习,例如转移学习。如何揭示不同视觉任务之间的潜在关系仍然很大程度上未被探索。在本文中,我们提出了一种新颖的textbf L可收费textbf P参数textbf Similarity textbf LPS方法,它学习有效度量来衡量隐藏在训练模型中的二阶语义的相似性。通过使用二阶神经网络来对齐高维模型参数并以端到端方式学习二阶相似性来实现LPS。此外,我们创建一个名为ModelSet500的模型集作为参数相似性学习基准,其中包含500个训练模型。 ModelSet500上的大量实验验证了该方法的有效性。代码将在url上发布:https://github.com/Wanggcong/learnable-parameter-similarity
|
Deep learning-based prediction of kinetic parameters from myocardial perfusion MRI
Authors Cian M. Scannell, Piet van den Bosch, Amedeo Chiribiri, Jack Lee, Marcel Breeuwer, Mitko Veta
心肌灌注MRI的量化有可能提供快速,自动化和用户独立的心肌缺血评估。然而,由于采集数据的相对高的噪声水平和低时间分辨率以及示踪动力学模型的复杂性,模型拟合可能产生不可靠的参数估计。该问题的解决方案是使用贝叶斯推断,其可以结合先验知识并提高参数估计的可靠性。然而,这使用马尔可夫链蒙特卡罗采样来近似动态参数的后验分布,这是非常耗时的。这项工作提出了训练卷积网络,以直接预测信号强度曲线的动力学参数,这些曲线是使用贝叶斯推断得到的估计进行训练的。这允许以与贝叶斯推断类似的性能快速估计动力学参数。
|
Effective and efficient ROI-wise visual encoding using an end-to-end CNN regression model and selective optimization
Authors Kai Qiao, Chi Zhang, Jian Chen, Linyuan Wang, Li Tong, Bin Yan
近年来,随着深度网络计算的快速发展,基于功能磁共振成像fMRI的可视化编码已经取得了许多成果。视觉编码模型旨在预测响应于呈现的图像刺激的大脑活动。目前,视觉编码主要是通过首先通过计算机视觉任务预训练的卷积神经网络CNN模型提取图像特征,其次训练线性回归模型,将CNN特征的特定层映射到每个体素,即体素编码。然而,基本上,两步方式模型难以确定哪种井特征与预先未知的fMRI数据线性匹配,而对人类视觉表示的理解很少。类比计算机视觉大多与人类视觉相关,我们提出了在感兴趣区域ROI明智方式的端到端卷积回归模型ETECRM,以实现有效和高效的视觉编码。引入端到端方式,使模型自动学习更好的匹配功能,提高编码性能。 ROI明智的方式用于提高许多体素的编码效率。此外,我们设计了包括自适应权重学习和加权相关损失,噪声正则化的选择性优化,以避免在ROI明智编码中干扰无效体素。实验证明,所提出的模型比编码模型的两步方式获得了更好的预测精度。比较分析表明,端到端的方式和大量的fMRI数据可能会推动视觉编码的未来发展。
|
+GAN生成手写字体Generative Adversarial Network for Handwritten Text
Authors Bo Ji, Tianyi Chen
生成的对抗性网络GAN已经证明在图像处理的各种应用中取得了巨大的成功。然而,由于难以通过卷积神经网络CNN处理顺序手写数据,用于手写的生成对抗网络在某种程度上相对罕见。在本文中,我们提出了一种用于合成手写笔画数据的手写生成对抗网络框架HWGAN。新框架的主要特征包括:i鉴别器包括基于CNN长短期存储器LSTM的特征提取,路径特征提取PSF作为输入,前馈神经网络基于FNN的二元分类器ii作为合成发生器的循环潜变量模型顺序手写数据。数值实验表明了新模型的有效性。此外,与唯一的手写生成器相比,HWGAN可以合成更自然逼真的手写文本。
|
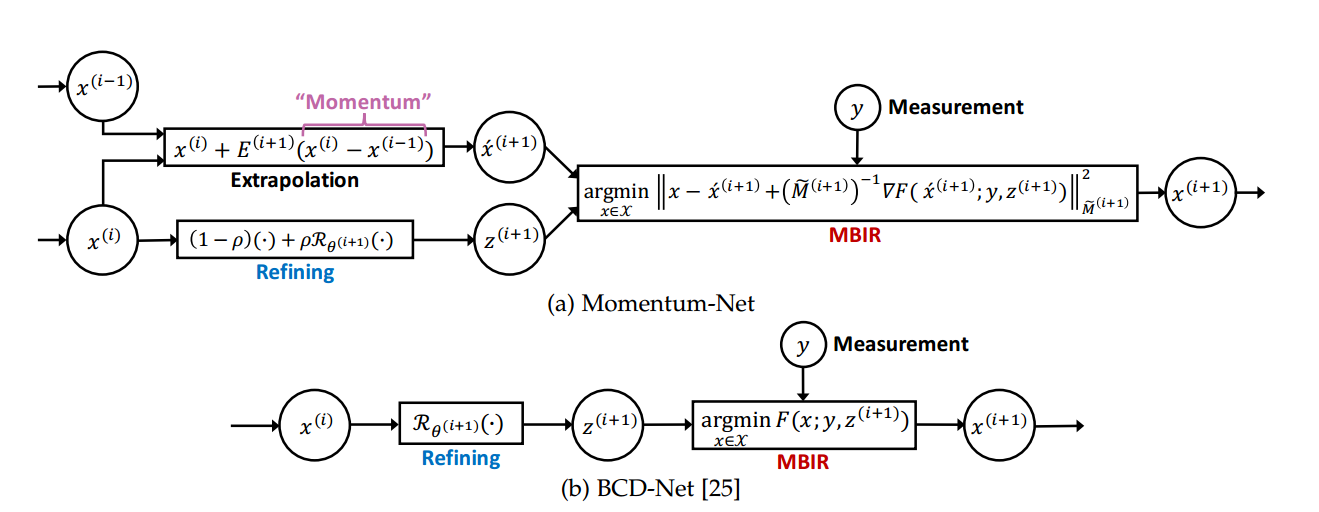
Momentum-Net: Fast and convergent iterative neural network for inverse problems
Authors Il Yong Chun, Zhengyu Huang, Hongki Lim, Jeffrey A. Fessler
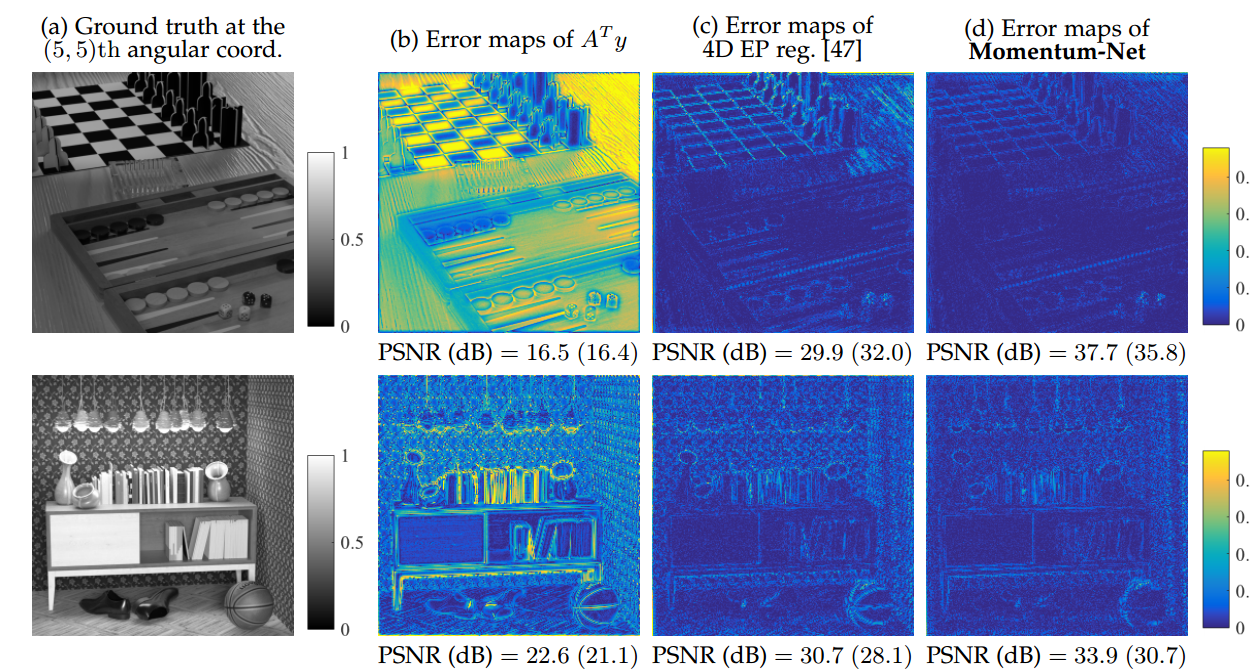
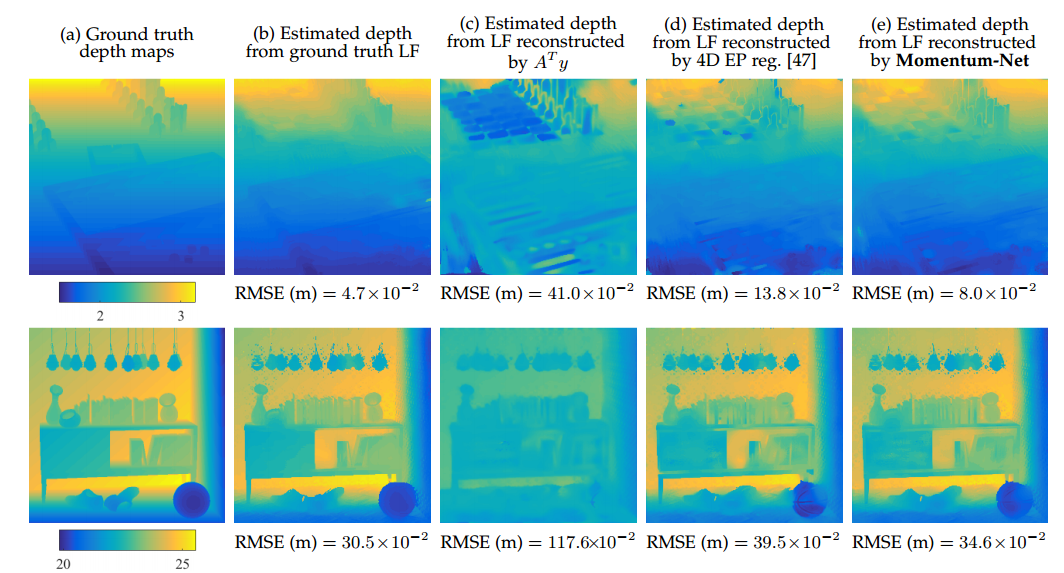
迭代神经网络INN正在迅速获得关注,以解决成像,图像处理和计算机视觉中的逆问题。 INN结合回归NN和基于迭代模型的图像重建MBIR算法,导致良好的泛化能力和优于现有MBIR优化模型的重建质量。本文提出了第一个快速和收敛的INN架构,Momentum Net,通过推广使用动量和主流化器与回归NN的块智能MBIR算法。对于快速MBIR,Momentum Net在外推模块中使用动量项,在每一层使用非主流MBIR模块,使用主流化器,其中每层Momentum Net由三个核心模块组成图像精炼,外推和MBIR。在两个无症状条件下,Momentum Net保证收敛到一般可微分非凸MBIR函数或数据拟合项和凸可行集的固定点。为了考虑训练和测试样本之间的数据拟合变化,我们还提出了基于主化矩阵的谱半径的正则化参数选择方案。使用焦点堆栈和稀疏视图计算层析成像的光场摄影的数值实验表明,给定相同的回归NN架构,Momentum Net显着提高了MBIR的速度和准确性,与现有的几种INN相比,它显着提高了重建质量,与现有技术的MBIR方法相比。每个申请。
|
Memory- and Communication-Aware Model Compression for Distributed Deep Learning Inference on IoT
Authors Kartikeya Bhardwaj, Chingyi Lin, Anderson Sartor, Radu Marculescu
模型压缩已成为在物联网物联网上部署深度学习模型的重要研究领域。但是,对于极其受内存限制的情况,即使压缩模型也无法放入单个设备的内存中,因此必须分布在多个设备上。这导致了分布式推理范例,其中存储器和通信成本代表了主要瓶颈。然而,现有的模型压缩技术不具有通信意识。因此,我们提出了神经网络NoNN网络,这是一种新的分布式物联网学习范例,它将大型预训练教师深度网络压缩成几个不相交且高度压缩的学生模块,而不会损失准确性。此外,我们为教师模型提出了一种基于网络科学的知识划分算法,然后对所得到的不相交分区进行培训。针对用户定义的内存性能预算,对五个图像分类数据集进行了广泛的实验,结果表明NoNN比几个基线和教师模型具有更高的准确度,同时在学生之间使用最少的通信。最后,作为案例研究,我们在边缘设备上部署了CIFAR 10数据集的建议模型,与大型教师模型相比,内存占用率显着提高了24倍,性能提高了12倍,节点能量提高了14倍。我们进一步表明,对于多边缘设备上的分布式推理,我们提出的NoNN模型导致总延迟降低33倍w.r.t。最先进的模型压缩基线。
|
+基于DNN从原始数据构建核磁共振图像Deep MRI Reconstruction: Unrolled Optimization Algorithms Meet Neural Networks
Authors Dong Liang, Jing Cheng, Ziwen Ke, Leslie Ying
来自欠采样k空间数据的图像重建一直在快速MRI中发挥重要作用。最近,深度学习已经在各个领域取得了巨大的成功,并且还显示出通过减少测量来显着加速MR重建的潜力。本文概述了基于深度学习的MRI图像重建方法。回顾了三种基于深度学习的方法,即数据驱动,模型驱动和集成方法。解释了三种方法中每个网络的主要结构,并重点分析了审查网络的共同部分及其间的差异。基于该综述,讨论了许多信号处理问题,以最大化快速MRI的深度重建的潜力。从理论的角度来看,讨论可能有助于进一步发展最佳网络和性能分析。
|
|
Chinese Abs From Machine Translation |












{kind=link}