1.介绍
1.1任务描述
商品同款挖掘:同款商品是指商品的重要属性完全相同且客观可比的商品,商品同款识别的主要目的是从海量结构化和无结构化的商品图文数据库中匹配得到同款商品,是构建电商产品关系的一个重要环节。商品同款作为商品知识图谱的重要组成部分,有很多应用场景,如同款商品发现等。任务数据集来自CCKS2022面向数字商务的知识处理与应用评测任务二:基于知识图谱的商品同款挖掘。
1.2任务说明
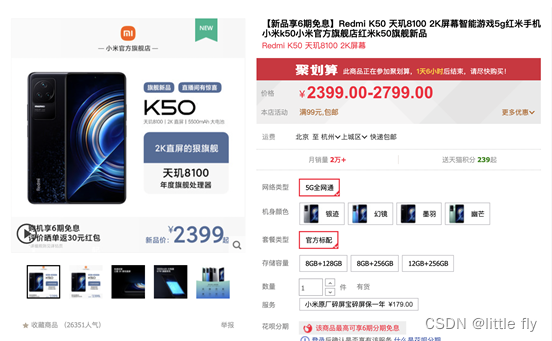
商品定义: 商品(即item)通常由多个sku构成,其基础信息包括item级信息(主图、标题、类目、属性及属性值)以及sku级信息(sku图片、sku销售属性),例如:Redmi K50 是一个item(见图1),(Redmi K50,银迹,8GB+128GB)是一个sku。从消费者视角出发,对于手机类目,品牌+型号一致的商品可以认定是同款商品。
但由于商家个性化发布导致商品标准化、结构化程度差,且不同类目下的商品关注的重要属性不一,给细粒度同款对齐带来了困难。为了简化问题,我们将商品同款识别任务定义为二分类任务,即给定商品对信息,判断是否item同款,如下例所示:
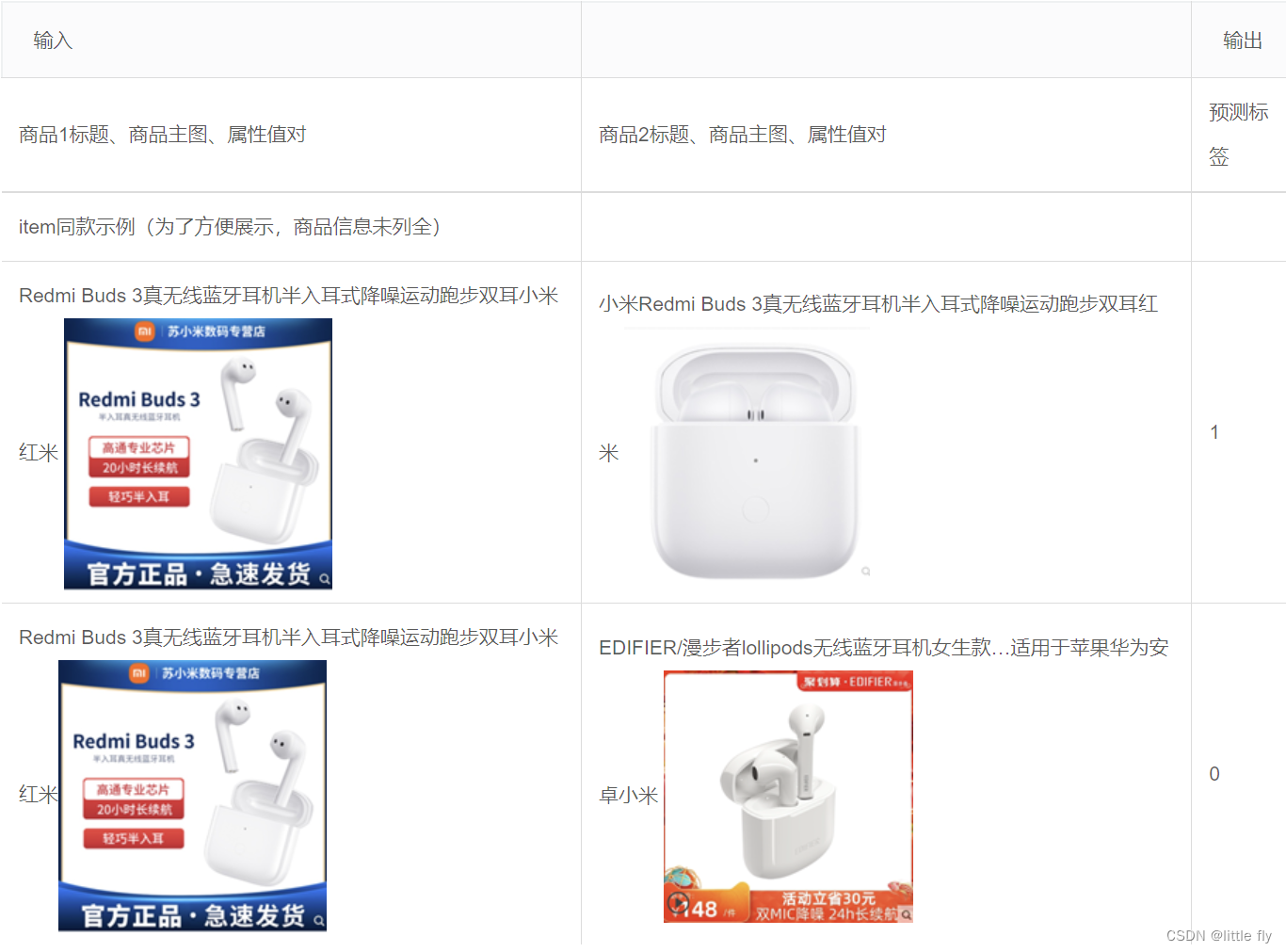
字段说明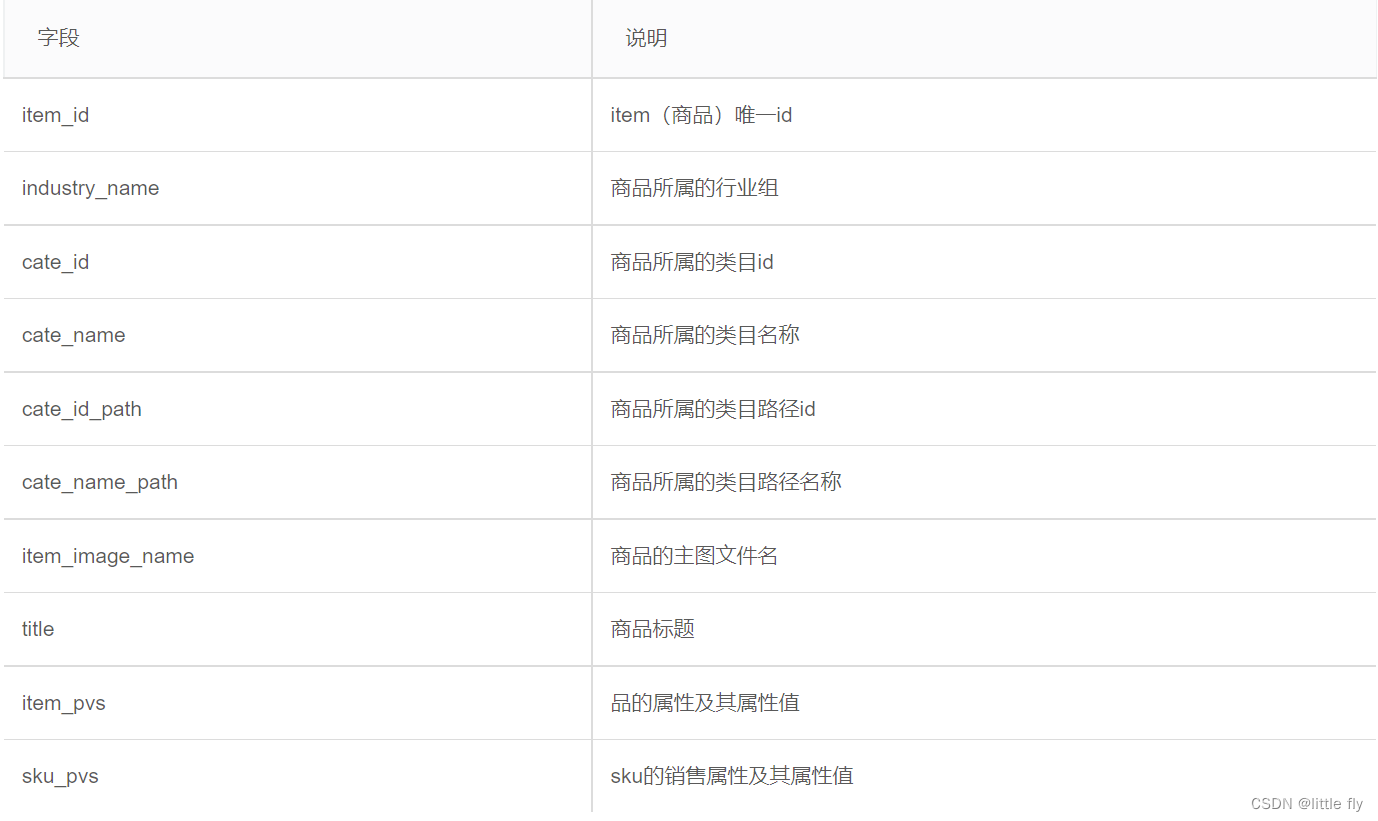
2.建立模型
model = build_transformer_model(
config_path,
checkpoint_path,
with_mlm=True,
keep_tokens=keep_tokens, # 只保留keep_tokens中的字,精简原字表
)
output = Lambda(lambda x: x[:, 5:6])(model.output)
model = Model(model.input, output)
model.summary()
def masked_cross_entropy(y_true, y_pred):
"""交叉熵作为loss,并mask掉padding部分的预测
"""
y_true = K.reshape(y_true, [K.shape(y_true)[0], -1])
y_mask = K.cast(K.not_equal(y_true, 0), K.floatx())
cross_entropy = K.sparse_categorical_crossentropy(y_true, y_pred)
cross_entropy = K.sum(cross_entropy * y_mask) / K.sum(y_mask)
return cross_entropy
model.compile(loss=masked_cross_entropy, optimizer=Adam(2e-5))
3.数据加载
class data_generator(DataGenerator):
def __iter__(self, random=False):
"""单条样本格式为
输入:[CLS]两个商品[MASK]同,text1,text2[SEP]
输出:'相'或者'不'
"""
idxs = list(range(len(self.data)))
if random:
np.random.shuffle(idxs)
batch_token_ids, batch_segment_ids, batch_a_token_ids = [], [], []
for i in idxs:
data = self.data[i]
text = "两个商品相同"
text1 = data[1]
text2 = data[2]
label = data[0]
final_text = text + ':' + text1 + ',' + text2
token_ids, segment_ids = tokenizer.encode(
final_text, maxlen=maxlen)
# mask掉'相'字
token_ids[5] = tokenizer._token_mask_id
if label == 0:
a_token_ids, _ = tokenizer.encode('不')
else:
a_token_ids, _ = tokenizer.encode('相')
batch_token_ids.append(token_ids)
batch_segment_ids.append(segment_ids)
batch_a_token_ids.append(a_token_ids[1:])
if len(batch_token_ids) == self.batch_size or i == idxs[-1]:
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids = sequence_padding(batch_segment_ids)
batch_a_token_ids = sequence_padding(batch_a_token_ids, 1)
yield [batch_token_ids, batch_segment_ids], batch_a_token_ids
batch_token_ids, batch_segment_ids, batch_a_token_ids = [], [], []
4.训练
def predict(data):
"""
数据格式
text1 = data[0]
text2 = data[1]
label = data[2]
方便预测和训练时候评价
"""
text = "两句话意思相同"
text1 = data[1]
text2 = data[2]
label = data[0]
final_text = text + ':' + text1 + ',' + text2
token_ids, segment_ids = tokenizer.encode(final_text, maxlen=maxlen)
# mask掉'相'字
token_ids[6] = tokenizer._token_mask_id
token_ids, segment_ids = to_array([token_ids], [segment_ids])
# 用mlm模型预测被mask掉的部分
probas = model.predict([token_ids, segment_ids])[0]
res = tokenizer.decode(probas.argmax(axis=1))
if res == '不' and label == 0:
return '正确'
elif res == '相' and label == 1:
return '正确'
elif res != '不' and res != '相':
return '超出范围'
else:
return '错误'
def evaluat_vail_data(valid_data):
right, out, all = 1, 1, 1
for valid in valid_data:
res = predict(valid)
if res == '正确':
right += 1
elif res == '超出范围':
out += 1
all += 1
return right / all, out
class Evaluator(keras.callbacks.Callback):
"""评估与保存
"""
def __init__(self):
self.lowest = 1e10
self.best = 0
def on_epoch_end(self, epoch, logs=None):
# 保存最优
# if logs['loss'] <= self.lowest:
# self.lowest = logs['loss']
# model.save_weights('./best_model.weights')
acc, out = evaluat_vail_data(valid_data)
print(acc, out)
if acc >= self.best:
self.best = acc
model.save_weights('./best_model.weights')
model.fit(
train_generator.forfit(),
steps_per_epoch=len(train_generator),
epochs=epochs,
callbacks=[evaluator])