一. Transformer诞生背景
Transformer模型是解决序列转录问题的一大创新。在Transformer模型之前,序列转录模型都或多或少的基于复杂的循环或卷积神经网络。
循环神经网络的计算是时序性的, 位置的计算必须基于之前所有位置的计算结果,因此循环神经网络上的计算难以并行,效率较低。而且在翻译长句时,循环或卷积神经网络对之前文本的“记忆”是有限的,采用时序计算很可能丢掉之前的重要信息。
位置的计算必须基于之前所有位置的计算结果,因此循环神经网络上的计算难以并行,效率较低。而且在翻译长句时,循环或卷积神经网络对之前文本的“记忆”是有限的,采用时序计算很可能丢掉之前的重要信息。
为了改善长句翻译过程中信息丢失的问题,诞生了Attention注意力机制。注意力机制使得模型能够不断吸收输入序列上下文中的有用信息,且与当前词汇关联性越强的词汇,注意力得分越高,对该词汇影响越大。理论上只要拥有足够的算力,便能够兼顾无限长的句子信息。
Transformer的革新性在于,完全基于注意力机制来解决序列转录问题,彻底丢弃了传统模型中循环或卷积的部分,使得序列转录工作能够并行实现,大大提高了工作效率。Transformer模型应用了两种注意力机制,一是Encoder、Decoder中都存在的Self-attention机制,使每一层编(解)码器能够兼顾上一次编(解)码器的全部输出信息;二是仅存在与Decoder中的Encoder-Decoder Attention机制,使每一层解码器能够兼顾编码器的全部输出信息,提高了信息利用率,综合了上下文对翻译结果的影响。
二. Transformer结构
整体结构:Encoder+Decoder


(一)编码器Encoder
1. 结构
(1)编码器由N层相同的编码结构(Layer)垂直叠加构成。
Transformer原论文中设定N=6,在实际应用中可以调整编码器的层数以适应具体问题。
多层相同编码器叠加的作用:每一层能够学习不同的内容,如某些层学习词汇,某些层学习语法,某些层学习逻辑。
(2)每一层编码器分为两个子层(Sublayer):
- 自注意力(Self Attention) ——通过样本自身词汇之间的关系得到注意力值(Attention);挖掘某个词汇A与该句子中其他词汇的联系,在编码词汇A时,对句子中其他不同词汇投入不同的“注意力”,从而能够起到联系上下文的效果,不断调整词汇A的编码结果。
- 全连接的前馈神经网络(Feed Forward Neural Network)——由于在之前的Self-attention中已经考虑了不同向量直接的联系,因此在FFNN层中,数据可以相互独立地并行流动。
2. 作用
编码器将输入序列转化为浮点数编码,并通过Multi-head Attention调整编码内容。
(二)解码器 Decoder
1. 结构
(1)与编码器一致,解码器由N层相同的编码结构(Layer)垂直叠加构成。
(2)每层解码器分为3个子层(Sublayer)
- Self-attention:与编码器结构相同
- FFNN:与编码器结构相同
- Encoder-Decoder Attention:与Self-attention相似,只是计算的是上一层解码器的输出对编码器最终输出的注意力
2. 作用
译码器将输入的编码转化为目标“语言”的词向量,输出序列翻译的结果。
三. 数据流动过程
(一)数据准备——位置编码
Transformer丢失了时序信息,无法捕捉序列顺序,输出结果也与输入序列中词汇的顺序关系不大。然而,在实际应用中,序列中词汇的位置也是重要信息,因此Transformer模型设计了如下编码规则,对序列中词汇的位置进行编码:

选用正余弦函数进行位置编码的原因是正余弦函数具有如下性质:


说明位置 的位置编码能够由位置
的位置编码能够由位置 的正余弦线性表示,因此用正余弦函数编码便于反应词汇的相对位置关系。
的正余弦线性表示,因此用正余弦函数编码便于反应词汇的相对位置关系。
(二)编码
1. Word Embedding 词嵌入
用词嵌入算法将词汇转化成词向量,词向量作为最底层编码器的输入。原论文使用的词向量维度为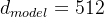 。
。
2. 编码器数据输入
每个编码器的输入是一个向量列表
- 最底层编码器:输入为词向量列表
- 其他编码器:输入为紧邻的下一层编码器的输出
- 向量长度等于词向量维度,为512,列表长度一般设置为最长语句(Sequence)中单词个数
3. Self-attention 自注意力计算
核心内容:通过整个输入样本本身,为每个输入向量x(对应一个词)学习一个权重,作为衡量词y与词x关联性的标准——注意力
输出结果:将输入向量x转化为一个新向量z,z为所有词汇生成的Value以注意力为权重的加权总和。
(1)数据结构 => q、k、v向量
根据输入向量[x1,x2,...,xn],通过矩阵乘法(输入向量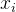 与相应的权重矩阵
与相应的权重矩阵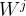 相乘)生成3个新向量:Query(q)、Key(k)、Value(v)。
相乘)生成3个新向量:Query(q)、Key(k)、Value(v)。
其中权重矩阵维度是512×64 => 向量q、k、v长度缩短为64

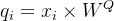
Query是信息检索的目标,在Self-attention模型中,Query是由样本通过空间变换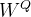 提取得到的。
提取得到的。
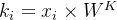
在信息检索领域,Key是检索的关键词,计算Query与Key的匹配程度score,匹配程度score最高的Key对应的Value即为所求。
在Self-attention模型中,Key是由样本通过空间变换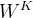 得到的。
得到的。
score的计算方法为向量内积: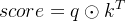 ,当两向量正交时score为0,认为q与k无关。
,当两向量正交时score为0,认为q与k无关。
用这种方法计算出的score,进行归一化与Softmax函数的处理,即可得到注意力Attention。
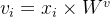
Value是Query的检索结果,由样本通过空间变换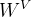 得到。
得到。
一般地信息检索问题中,系统只要根据Query给出一系列Value即可完成任务,但Transformer模型并不是要得到一系列Value的值,而是要为每个Value提供一个权重,并计算所有Value的加权和。
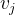 的权重
的权重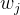 计算公式如下:
计算公式如下:
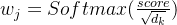
从Query、Key、Value的生成方式可以得出“自注意力”一词的本质——Query、Key、Value全部都是基于样本x本身生成的,所有的注意力都是基于样本本身进行计算,因此称为自注意力机制。
(2)Self-Attention算法
实际算法实现以矩阵形式进行:
- 词向量构成输入矩阵
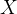 ,输入矩阵的每一行为一个词
,输入矩阵的每一行为一个词
- 根据输入,生成向量矩阵
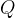 、
、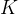 、
、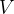

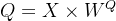
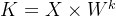
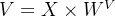
- 计算每条Query
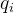 与矩阵中所有向量
与矩阵中所有向量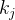 的匹配度得分
的匹配度得分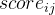 ,生成匹配度得分矩阵
,生成匹配度得分矩阵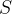
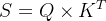
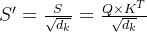
这里的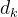 是指Key的长度,在Transformer模型中,Query、Key、Value是等长的,维度均为64。归一化的目的是缩小激活函数Softmax输出的差距,获得更稳定的梯度。若不做归一化,则会出现Softmax函数输出集中在0和1两端的现象。
是指Key的长度,在Transformer模型中,Query、Key、Value是等长的,维度均为64。归一化的目的是缩小激活函数Softmax输出的差距,获得更稳定的梯度。若不做归一化,则会出现Softmax函数输出集中在0和1两端的现象。

如上图所示,经过归一化
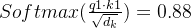
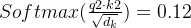
若不经过归一化
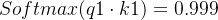
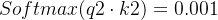
经过Softmax函数预测的概率值过于集中在0和1两端,不能充分吸收其他词汇中的有用信息,也就不能发挥Attention机制的优势。
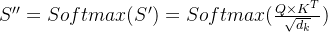
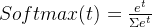
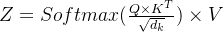

(3)Multi-head Attention 多头注意力机制
将分别输入到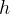 个Self-attention系统,得到个输出矩阵
个Self-attention系统,得到个输出矩阵 ,将所有输出矩阵拼接在一起得到整个输出矩阵
,将所有输出矩阵拼接在一起得到整个输出矩阵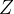 。拼接方法如下:
。拼接方法如下:

首先将矩阵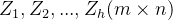 水平联结成一个矩阵
水平联结成一个矩阵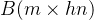 ,再用该矩阵乘输出权重矩阵
,再用该矩阵乘输出权重矩阵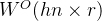 ,即可得到总的输出矩阵
,即可得到总的输出矩阵
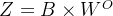
的维度为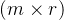 。
。
4. 前馈神经网络 FFNN
每个位置分量(position)对应一个完全相同的全连接前馈神经网络,对Self-attention层的输出作独立的并行处理。
激活函数如下:

共包含两次线性变换和一次ReLU变换。
ReLU激活函数:

ReLU函数是分段线性函数,将负值处理成0;在Transformer模型中,将ReLU函数中的线性部分从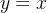 扩充为
扩充为 。
。
【注意】同一层中所有FFNN网络,参数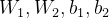 均相同,而不同层次,参数值可不同。
均相同,而不同层次,参数值可不同。
(三)解码
1. 解码器数据输入
编码器的输出结果作为编码器的输入。
2. Encoder-Decoder注意力机制
与自注意力机制类似,也是通过、、矩阵计算注意力值,并通过注意力加权调整编码。与自注意力机制的区别在于,Encoder-Decoder注意力机制中,矩阵由编码器的最终输出矩阵生成,和矩阵由上一层解码器的输出矩阵生成。
由此可知,Encoder-Decoder机制的作用是,使每一层解码器在解码的过程中能够兼顾编码器输出的全部信息,也就是兼顾所有输入序列的信息。
3. Masked Multi-head Attention
在解码器的Self-attention层,学习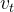 的注意力权重时应避免并能吸收位置之后的信息,因此需要将
的注意力权重时应避免并能吸收位置之后的信息,因此需要将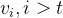 的权值设置为
的权值设置为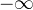 ,从而经过Softmax函数得到的权重为0,如此便可消除
,从而经过Softmax函数得到的权重为0,如此便可消除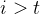 位置的影响,称为Masked Multi-head Attention。
位置的影响,称为Masked Multi-head Attention。
四. 未解决的问题
1.计算q、k、v时,用到的对x实施空间变换的权重矩阵W是什么?
2.为什么q、k、v可以由同一个向量经过不同的空间变换得到,他们的内在联系是什么?
3.为什么编码时学习的注意力权重能够吸收位置之后的信息,而解码时却不可以,需要采用“Mask”方式呢?
4. 残差连接方法还需要进一步理解和学习。
参考资料:
1. Vaswani A , Shazeer N , Parmar N , et al. Attention Is All You Need[J]. arXiv, 2017.详解Transformer (Attention Is All You Need) - 知乎2. The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.详解Transformer (Attention Is All You Need) - 知乎
4. 如何理解 Transformer 中的 Query、Key 与 Value_yafee123的博客-CSDN博客_key query value5. ReLU激活函数:简单之美_对半独白的博客-CSDN博客_relu激活函数