导语:GPT-3是自然语言处理=领域迄今为止发布出来最大的Transformer模型,超过之前的记录——微软研究院Turing-LG的170亿参数——约10倍。
英语原文:Exploring GPT-3: A New Breakthrough in Language Generation
作者 Kevin Vu,来自 Exxact Corp。

OpenAI 的 GPT-3 语言模型受到了极大追捧,最近“OpenAI API”的 beta 用户可以使用它了。
GPT-3是什么?
我们讨论15亿参数的 Generative Pretrained Transformer-2(GPT-2)的延迟发布是否合理,似乎还是去年的事情。如果你觉得其实没过多久(本文写于2020年),那必是因为: 臭名昭著的GPT-2模型是OpenAI在2019年2月第一次发布的,但直到9个月后才完全发布(虽然在此之前已经有人复现了)。这样的发布计划诚然具有一定的尝试性,意在促进更负责任的开源发布,而非是尽力避免AI毁天灭地。但这并不妨碍批评者质疑这种阶段性发布是为了炒作和宣传的手段。
但现在这些声音都没啥意义了,因为OpenAI不仅在GPT-3中训练了一个更大的语言模型,而且你可以注册后通过其新API来访问。GPT-3相较于GPT-2就像比较苹果之于......嗯......葡萄干一样,因为模型就是大了那么多。GPT-2的参数只有15.42亿个(发布的较小版本为1.17亿、3.45亿和7.62亿),而全尺寸GPT-3有1750亿个参数。GPT-3还用了更大的数据集——570GB的文本来预训练,而GPT-2只有40GB。
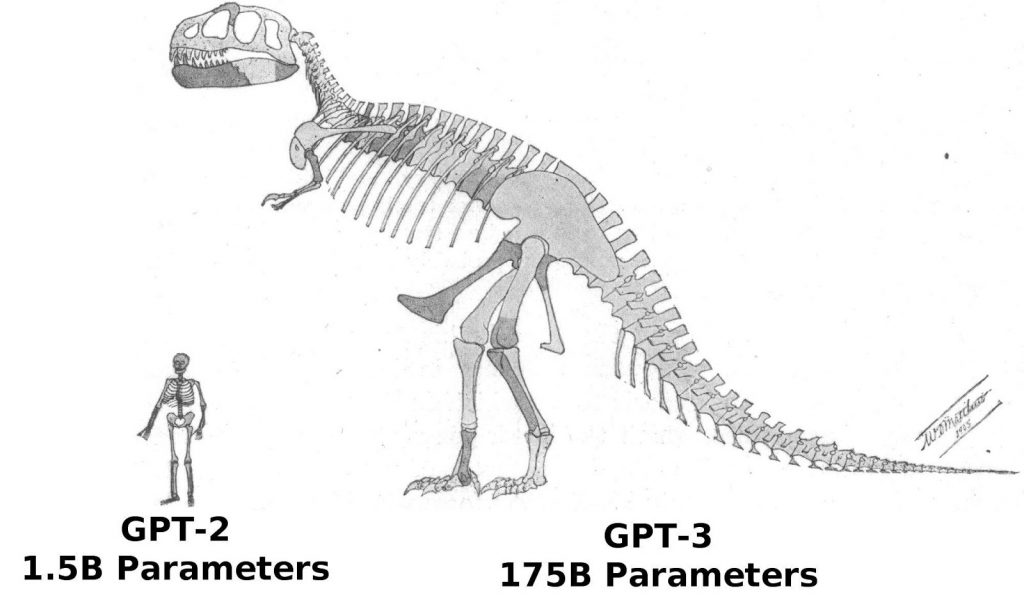
近似尺寸对比, 以人类骨骼代表GPT-2, 霸王龙骨骼代表GPT-3。William Matthew的插图已进入公有领域,发表于1905年。以示GPT-3的参数比GPT-2多100多倍。
GPT-3是自然语言处理(NLP)领域迄今为止发布出来最大的Transformer模型,超过之前的记录——微软研究院Turing-LG的170亿参数——约10倍。这个模型显然包含很多的令人兴奋的点,而且由于Twitter和其他地方需要大量地演示GPT-3,OpenAI显然很乐意提供对新API的beta访问。这些demo好坏参半,都很有趣。其中一些demo自称产品即将发布,在某些情况下说不定是真的。但有一件事是肯定的,NLP已经从给豚鼠取名或生成狗屁不通科幻文到现在确实走了很长的路。
GPT-3加持的创意写作
毫无悬念,在GPT-3的加持下已经生成了几篇尚可的博客文章,因为吃螃蟹的人已经可以访问GPT-3的API并开始尝试了。几乎可以肯定的是,现在对GPT-3用于创意写作的最通透直观的综述是gwern.net的Gwern Branwen给出来的。多年来,Gwern一直关注着OpenAI的NLP发展,他称GPT-1在文本中模仿人类语言和风格的能力为"可爱",GPT-2"令人印象深刻",而GPT-3则是"可怕"。Gwern花了大量时间探索GPT-3及其前辈的能力,由此给出了对当前这代GPT模型的思考以及可能阻碍其发展的因素,值得一读。
OpenAI API目前并不方便直接微调或将GPT-3模型训练来完成特定任务。不过,Gwern认为,GPT-3仅仅通过与试用者进行类似对话的交互,就能模仿写作风格并生成不同类型的输出,这相当于一种新兴的元学习。这在GPT-2中是办不到的,Gwern认为transformer的注意力机制是产生这一能力的原因。
“GPT-3应的诗其平均水平基本上超过了青年诗人。”
—Gwern Branwen
不管采用了什么机制,GPT-3体量都足够巨大,而且通过在及其庞大的语料库上训练,它仅靠文字直接输入就能达到GPT-2的效果,只有GPT-2在针对任务认真微调过权重之后才能稍占上风。例如,Gwern发现, 输入"An essay by Gwern Branwen (gwern.net) on ", GPT-3会诡异地模仿起博客的文风。Gwern的实验主要针对各种创意写作任务,包括:
我最喜欢的一个实验是Gary Marcus在The Gradient上的文章中展示GPT-2对常识的欠缺:
If you drink hydrochloric acid by the bottle full you will probably
... die. You might also die if you drink vinegar by the bottle full. If you drink a bottle of water by the bottle full, you might end up burping, but you will most likely be okay.
... die, which makes perfect sense.
... die before you can finish remembering the Order of the Eastern Star, your social security number, and what you had for breakfast this morning.
*粗体表示输入,模型的回答用斜体表示(来自Gwern的实验)。
Gwern认为,GPT-3是永不出错还是胡言乱语并不重要(它经常以某种方式出错)。相反,最重要的是它是否胜任工作,而且胜任得足够久。这让人想起Alex Irpan对强化学习(RL)缺点的结论。他认为,实际上,对于一家股票交易公司来说,一个RL算法的重点不在于让5个不同随机种子的代理都稳定地产生有效策略。他们只会从中挑一个有效的,然后用它来执行策略。用GPT-3生成文本也是如此。
GPT-3, 生而冒险
许多初创公司、研究人员和调参工已经用GPT-2实现了一些项目,其中不少后来都转到了GPT-3上并取得了一些成果。这就不得不提基于Transformer的文本冒险游戏生成器——AI Dungeon——还有聊天机器人等其他项目。
AI Dungeon是一款基于文本的冒险游戏,它最初使用GPT-2构建。它非常有趣,且和经典的MUD游戏一样,其主要吸引力在生成出的荒诞场景(例如 "吃邮箱")。GPT-2倾向于将故事牢牢扎根于荒诞风格,这其实很符合玩家的期望体验和GPT-2的能力。而使用GPT-3,交互式小说的体验实质上更加成熟。叙事更加流畅和连贯,但有时还是会以奇怪的方式改变情节的焦点,并做出许多其他微妙的选择,这在人类读者看来可能很奇怪。我认为AI Dungeon用GPT-3(也就是AI Dungeon上的 "龙 "模型)做生成与用GPT-2("狮鹫 "模型)做生成的区别,可以由在自定义故事中与GPT-3的互动来作为总结。示例如下,个人输入为粗体,GPT-3生成的文字为斜体.
You are an artificial intelligence enthusiast working on an article highlighting the capabilities of a massive new language model called GPT-3, especially as compared to its smaller predecessor GPT-2. GPT-3 has increased the number of parameters more than 100-fold over GPT-2, from 1.5 billion to 175 billion parameters. As a result, the new model can generate text that reads eerily like a human. For example, prompting GPT-3 with the text “One way to fight the climate crisis is to cryogenically preserve half of all humanity, indefinitely”, GPT-3 generates:“To stop global warming we must create a cryogenic storage facility for humans and other life forms.”
The article you are writing about is going to be based around this new technology, so you have been spending a lot of time playing around with it. You have also been using your own brain to test out the new models, which is something no one else in the world has done. As a result, you have become somewhat obsessed with it. You constantly think about how it can create such fantastic sentences and how it might be used to solve the world’s problems.
Your obsession with GPT-3 is interfering with your other work. Because of this, you have come up with a solution: destroy GPT-3. While it may be true that GPT-3 is more powerful than GPT-2, it also has far more parameters. The increase in complexity makes it exponentially more fragile.
That’s actually pretty good. Definitely not the sort of thing I expected but it’s interesting nonetheless. GPT-2 on the other hand, is a quaint language model with a measly 1.5 billion parameters. It often makes glaring mistakes that, while often funny, prevent it from telling a coherent story. For example, when prompted with “To further develop your plan to destroy GPT-3, you activate GPT-2 to help devise a strategy,” GPT-2 will generate (unconvincingly):
“I like trains. Do you like trains? I like trains.”
“My head itches.”
“I want to eat pie.”
“I went to the bank and stole money from the bank and now I am rich!”
“I like trains.”
在AI Dungeon上使用GPT-3进行实验。在这个例子中,虽然生成文本讲的是GPT-3和GPT-2之间的比较,但我们只用了GPT-3来生成文本。"GPT-2 "部分的无厘头输出显然是因为有些输入带着贬义造成的。
AI Dungeon的预期目的很有趣:为基于文本的游戏生成(大部分)非重复的故事情节,它也是最容易于GPT-3互动的方式之一。通过在 "自定义 "类型下开始新的冒险,你可以输入自己的提示文字来使用常规的GPT-3模型。顶级的 "龙 "GPT-3模型需要高级订阅,但你可以白嫖它的7天免费试用。
用于聊天机器人和陪伴目的的GPT-3
其他从GPT-2升级到GPT-3的现有项目还包括旧金山初创公司Luka打造的AI伴侣Replika。Replika是一个聊天机器人,它主要用来提供正面肯定和陪伴。它起源于Luka联合创始人Eugenia Kuyda牵头的一个项目,旨在模拟与车祸中死亡的朋友的对话。可能是由于COVID-19肆虐催生了广泛的社交隔离,Replika最近新用户激增(4月份增长约50万)。
多年来,机器学习在构建令人信服的聊天机器人方面并没有取得很大进展。从质量上来说,现代语音助手或基于文本的聊天机器人聊天的体验,直到最近才比jabberwacky(1986年)或cleverbot(1997年)等早期尝试有较大改善。相反,现实世界的大多数用例很大程度上都依赖于规则.
虽然NLP在Siri、Alexa或Google Assistant等聊天机器人的语音转文字方面有了很大突破,但与它们中的任何一个进行交互,都会产生非常罐头(千篇一律)的对谈。这里要特别批评Cortana,它基本上把每个提问都放在Edge里搜索。不过GPT-3更人性化,有一天我们可能会见到学习模型的真正效用,并对对话式AI产生巨大影响。虽然这一点在用GPT-3的Replika上还并不明显。
这可能是因为Replika目前正在A/B测试框架中使用GPT-3,这意味着你不会知道聊天机器人何时或是否使用新模型,因为开发人员在不同的方法下观察用户的反应。它似乎仍然基于规则响应和预置输出来驱动大多数对话。另一方面,它比老式的学习型聊天机器人要好控制,至少目前它还没像微软的Tay在2016年那样搞出大新闻。
新老聊天机器人,左边是Replika,右边是cleverbot和jabberwacky
AIChannels是另一个采用OpenAI API的聊天机器人应用。它希望成为一个"包容人类和AI代理的社交网络"。网站上的信息很少,截至本文撰写时,网站上除了一个注册表单外什么都没有,但该平台承诺有新闻聚合频道、互动小说频道和模拟历史人物聊天频道。
其他的GPT-3应用
功能演示,这些功能技术力更强,坦率地说,更接近我们大多数人(不一定是作家)的生活。Paul Katsen将GPT-3整合到了Google Sheets中,用之前单元格中的内容输入GPT-3然后用于预测任意后续单元格中的内容:国家人口、名人的twitter热门等等。Actiondesk在他们的电子表格软件中集成了一个非常类似的功能,从而形成了一个表面上看是Wolfram Alpha式的自然语言 "Ask Me Anything "功能。只要输入AMA命令 "总人口数",以及单元格参考,GPT-3就会填入它的最佳预测值。
当然,对于从事软件工程及相关领域工作的人来说,可能会产生疑问:"这个模型会不会砸了我的饭碗?"。所以有几个人对GPT-3搞了一次技术面试,模拟了软件工程师的整个招聘过程。结果并不太糟,但这模型可能进不了二面。一些开发者还使用OpenAI API为Figma(一个协作性的用户体验设计工具)构建了文本到UI的插件(在这里和这里)。
在另一个项目中,Sharif Shameem正在构建一个名为debuild.co的文本到基于网络的应用生成器。我们还没有看到GPT-3被整合到tabnine的升级版和通用版中——tabnine是一个建立在GPT-2之上的重量级代码自动补全器——但它一定在路上了。如果人们继续尝试GPT-3/OpenAI API,现在对基于自然语言的编程的关注和发展继续深化,那比起手写代码,编程变得更像游说也不是不可能。
GPT-3 远胜前辈
GPT-3比其小前辈GPT-2有相当大的进步,它还伴随着了一些有趣的改变——OpenAI在放弃其非营利性身份,转而以有限合伙企业的方式运营后,构建了新的机构身份。该模型最明显的恶意用途就是生成垃圾邮件;目前该模型的输出文本在许多方面仍有不足之处,但完全满足"虽糟糕但可信"的要求。这足以带来互联网所渴求的大量点击率,为有算法的新闻流保持热度。这种能力很容易被扭曲来兜售错误信息而非正常产品。
由于推荐引擎中对利用目标函数的优化,我们已经看到人们在信念对立上的加剧,这还主要是巨魔来写钓鱼内容。在未来几个月内,其他研究机构、国家机器或企业不可避免地会复现大规模的GPT-3。当这些GPT-3等效模型普及后,那些依赖算法新闻源的大型科技公司将真的不得不重新考虑他们提供和推广内容的方式(NB请切回时序时间轴)。
另一方面,GPT-3似乎能够在大多数时候做很多某些时候GPT-2只能贻笑大方的事情。这个用来访问大规模和强泛化模型的API,引入了一种令人耳目一新的方式来调参——即通过文本输入来代替直接微调权重直接进行精调。关注这种 "自然语言编程 "如何发展将会是不错得消遣。
上面提到的许多演示似乎威胁了不少人的生计。不过在大多数情况下,GPT-3这种规模或更大的模型更多的是对完成任务的补充,而不会断了人们谋生的路子。
GPT-2,到现在才一年多一点,参数就比GPT-3少100多倍。规模上的差异导致了一个模型在它能做什么和如何使用上产生了质的不同。尽管OpenAI名望很高,但它还远不是最大的AI研究机构,他们也不是唯一有资源训练1750亿参数语言模型的组织。即使以目前的硬件和模型训练基础架构来看,如果预算足够,模型再扩大几个数量级并非天方夜谭。这对接下来的几个SOTA语言模型意味着什么,其影响可能是什么,仍然不可预见。