Hierarchical Text-Conditional Image Generation with CLIP Latents
前言
本篇工作是BERT和ViT在多模态领域的结合,在大大提高模型轻量性的同时又保证了性能,是多模态领域里程碑具有意义的工作。
Abstract
视觉和语言的预训练(VLP)提高了各个VL下游任务的性能,当前的VLP严重依赖图像特征的抽取,包括区域监督和卷积架构,导致在时效(计算量大,时间长)和表征能力(效果好坏取决于表征好坏)上存在问题。本文提出ViLT,将视觉的输入简化为和文本输入相同的无卷积方式,作者证明ViLT的速度比以前的VLP快了数10倍,并且在下游任务上仍有一定的竞争性,甚至更好。
1. Introduction
预训练微调范式扩展到视觉语言多模态领域,催生了VLP,这些模型通过文本匹配和图像对齐的掩码语言建模目标进行预训练,并针对不同的下游任务进行微调。
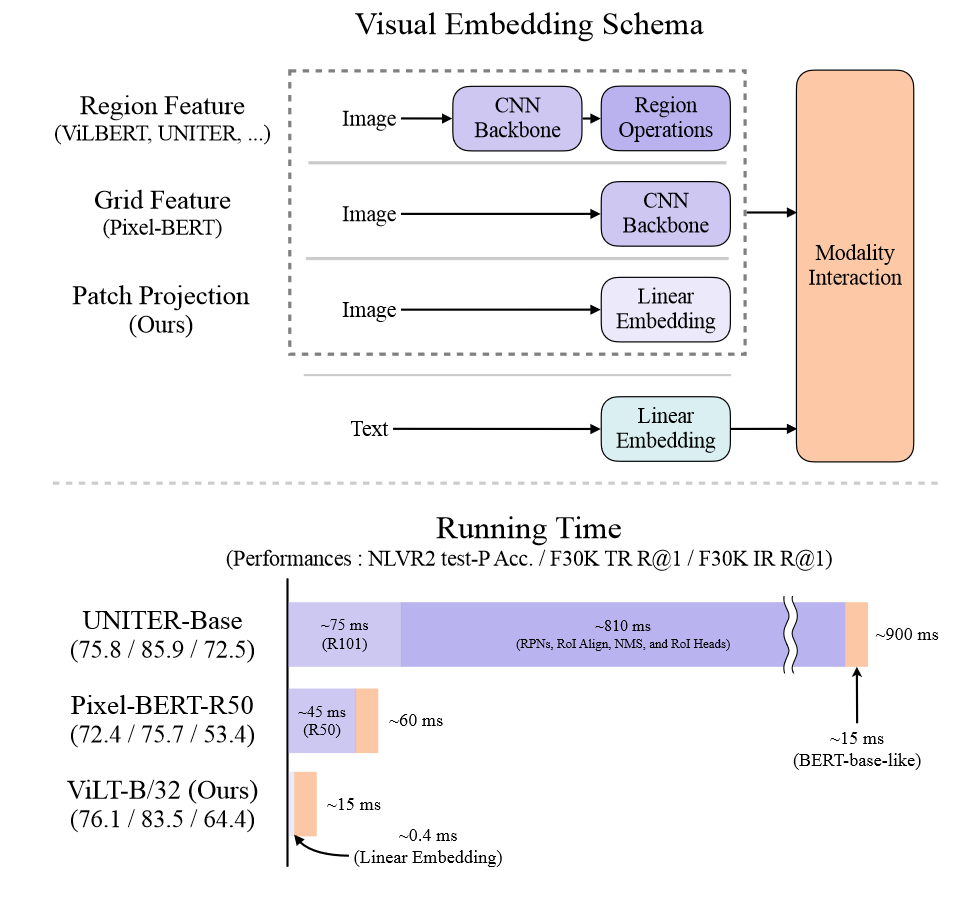
为了将文图数据喂入VLP中,图像像素和文本token首先都需要编码成embedding向量。此前,视觉信息必须通过深度卷积神经网络进行表征,大部分VLP模型预训练都采用了基于目标检测的数据,但是时间成本高,为此,Pixel-BERT采用ResNet抽取的特征图代替目标检测模块,但是性能严重下滑。
当前的VLP的研究关注于利用视觉表征提升性能,由于视觉的表征信息可以提前缓存,因此视觉特征抽取的时间损耗往往被忽略。但是在现实应用中无法提前抽取未见的图像特征,缓慢的抽取速度成为模型落地的挑战。
为此,作者将目光转向轻量化和快速化的视觉特征提取。最近的工作将像素通过线性投影输入到Transformer中,因此作者进行了尝试,提出了ViLT,它移除了视觉上常用的卷积模块,显著地减少了模型大小和运行时间。上图中,ViLT比具有区域特征的VLP模型快了10倍,比具有网格特征的VLP模型快至少4倍,同时在下游任务上表现出类似甚至更好的性能。
本文主要贡献如下:
- ViLT是当前最简单的VLP模型,只采用Transformer提取视觉特征,去除了耗时的卷积模块。
- 在不使用区域特征卷积情况下,仍得到有竞争力的性能表现。
- 首次证明了在VLP训练中,全单词掩码和图像增强可以提升性能。
2. Background
2.1. Taxonomy of Vision-and-Language Models
作者根据VLP的两个特点为其进行分类:
- 两种模态在参数和计算量上是否有相同的表达能力。
- 两种模态的交互方式。
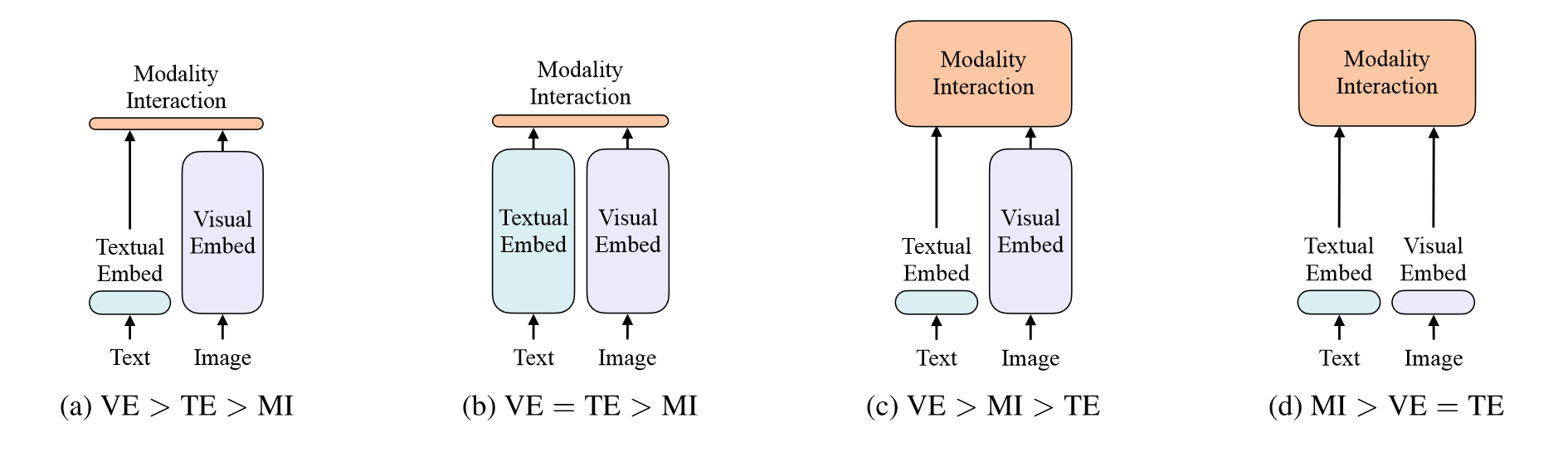
VSE模型如VSE++和SCAN都属于(a)中的模型,它们对图像的比重更大,图文的表征通过简单的点积或者浅层的Transformer来表示来自两个模态嵌入特征的相似性。
(b)的代表是CLIP模型,它为每个模态使用同样的Transformer,池化后的文图表征通过简单的点积融合。虽然CLIP在图生文零样本上有突出的表现,但是由于融合不足,无法在现有的多模态任务上表现良好。这表明,即使是将高性能的单模态嵌入进行简单融合也不足以学习复杂的视觉和语言任务,因此需要在模态融合上提出更高的要求。
与浅层交互的模型不同,(c)使用深层Transformer对图像和文本的特征进行交互,但是在图像特征提取上占据了大部分的计算量。
本文提出的ViLT的架构如(d)所示,其中原始的像素和文本token一样都采用浅层且轻量的嵌入,因此,GIA架构将大部分计算集中在模态的交互上。
2.2. Modality Interaction Schema
当前VLP的核心是Transformer,输入文本和图像的嵌入,模型对模态间和模态内信息进行选择性建模,然后输出上下文特征序列。
模态交互的方法可以分为两个类别:
- 单流方法,如VisualBERT,UNITER,它们将图文连接起来输入到同一个模型中处理。
- 双流方法,如ViLBERT和LXMERT,两个模态嵌入分别进行处理再融合。
本文的交互采用单流的方法,避免引入额外的参数。
2.3. Visual Embedding Schema
所有的VLP模型都采用BERT预训练的tokenizer作为文本token的编码,因此视觉嵌入是VLP的瓶颈。本文采用图像块代替区域特征提取,因为后者使用了大量抽取模块。
Region Feature.
区域特征从Faster R-CNN等现成的目标检测器中获得。区域特征的生成步骤如下:
- RPN基于CNN汇聚的网格特征提提取出感兴趣的区域(RoI)。
- NMS则将RoIs的数量减少到几千个。经过RoI Align等汇聚操作,RoI经过RoI头得到区域特征。
- NMS应用到每一个类,最后将特征数量降至100以内。
影响特征提取的性能和时间的因素包括主干网络、NMS风格和RoI头。
- Backbone:ResNet-101或ResNet-152。
- NMS:以每类的方式进行。
- RoIhead:C4 heads和FPN-MLP heads,由于每个头对每个RAOI进行操作,这是巨大的负担。‘
但是轻量级的目标检测不太可能比单独的卷积更快。如果提前冻结视觉的权重,提前缓存区域特征,只能对训练阶段有所帮助而对推理无用。
Grid Feature.
除了检测头,通过卷积神经网络输出的特征图也可以作为VLP预训练的特征,典型的方法是Pixel-BERT,虽然大大提升了视觉特征抽取的速度,但是性能严重下降。
Patch Projection.
为了最小化开销,作者采用了最简单的方案:将图像块进行线性投影得到embedding。该方法来自ViT,它将视觉嵌入步骤简化到文本token水平,作者采用32×32的图像块进行投影,只需2.4M的参数,与ResNe(X)t形成鲜明对比。
3. Vision-and-Language Transformer
3.1. Model Overview
ViLT具有简洁的架构和最小的视觉嵌入,遵循单流方法。作者用ViT权重初始化融合Transformer模型,利用交互层的能力来处理视觉特征。
t
ˉ
=
[
t
class
;
t
1
T
;
⋯
;
t
L
T
]
+
T
pos
v
ˉ
=
[
v
class
;
v
1
V
;
⋯
;
v
N
V
]
+
V
pos
z
0
=
[
t
ˉ
+
t
t
y
p
e
;
v
ˉ
+
v
t
y
p
e
]
z
^
d
=
MSA
(
LN
(
z
d
−
1
)
)
+
z
d
−
1
,
d
=
1
…
D
z
d
=
MLP
(
LN
(
z
^
d
)
)
+
z
^
d
,
d
=
1
…
D
p
=
tanh
(
z
0
D
W
pool
)
\begin{array}{l} \bar{t}=\left[t_{\text {class }} ; t_{1} T ; \cdots ; t_{L} T\right]+T^{\text {pos }} \\ \bar{v}=\left[v_{\text {class }} ; v_{1} V ; \cdots ; v_{N} V\right]+V^{\text {pos }} \\ z^{0}=\left[\bar{t}+t^{\mathrm{type}} ; \bar{v}+v^{\mathrm{type}}\right] \\ \hat{z}^{d}=\operatorname{MSA}\left(\operatorname{LN}\left(z^{d-1}\right)\right)+z^{d-1}, \quad d=1 \ldots D \\ z^{d}=\operatorname{MLP}\left(\operatorname{LN}\left(\hat{z}^{d}\right)\right)+\hat{z}^{d}, \quad d=1 \ldots D \\ p=\tanh \left(z_{0}^{D} W_{\text {pool }}\right) \\ \end{array}
tˉ=[tclass ;t1T;⋯;tLT]+Tpos vˉ=[vclass ;v1V;⋯;vNV]+Vpos z0=[tˉ+ttype;vˉ+vtype]z^d=MSA(LN(zd−1))+zd−1,d=1…Dzd=MLP(LN(z^d))+z^d,d=1…Dp=tanh(z0DWpool )
上面的公式是文本和图像块token通过ViT的过程。具体如下图所示:
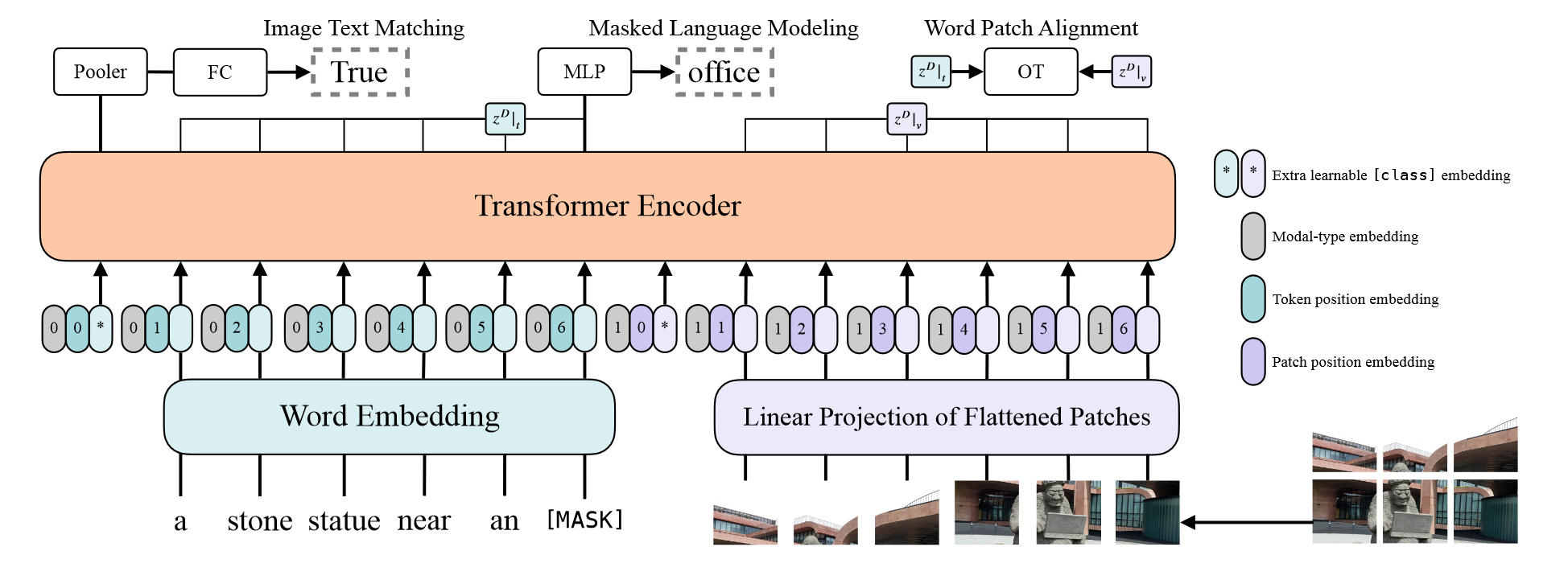
文本token输入到BERT tokenizer得到文本的embedding,图像块输入到线性投影层得到图像块的表征,此外在各自序列前面还加上了cls token。对于文本序列中的每个token embedding,是由模态embedding、位置embedding和文本token embedding相加得到,而对于图像块序列的embedding,是由模态embedding、位置embedding和图像块token embedding相加得到。两个序列拼接到一起输入Transformer编码器中,将得到的输出根据不同的训练任务进行参数的更新。
3.2. Pre-training Objectives
作者采用两个常见的预训练目标:图像文本匹配(ITM)和MLM。
Image Text Matching.
作者以50%的概率用不同的图像替换对齐的图像。ITM head将池化输出特征投影到二进制类上的logits,即执行二分类任务。此外还受到单词区域对齐目标的启发,设计了词块对齐任务。
Masked Language Modeling.
目标是根据上下文向量预测mask的文本token真实标签,以15%的概率随机mask文本token。作者采用两层MLP的MLM头,将mask的token最后一层输出映射到词表上得到logits。
3.3. Whole Word Masking
全单词屏蔽是对整个单词进行mask,当应用于原始BERT或者中文BERT中,在下游任务上有效。
在ViLT中,全单词屏蔽极其重要,可以充分利用多模态的信息。比如一张图像是一只长颈鹿站在树下,文本将长颈鹿整个单词mask,如果没有图像,那么预测出的对象可以是各种生物或者其他物体,但是图像模态的信息提供了长颈鹿的信息,因此这里mask的预测只能是长颈鹿。如果没有对giraffe进行全部掩码,那么文本很容易预测出giraffe,即使没有利用图像模态信息。
3.4. Image Augmentation
图像增强可以提高视觉模型的泛化能力,但是在多模态模型并没有探索使用,因为之前的方法都是把特征提前抽取缓存下来,并且一些图像增强的方法会导致语义信息发生变化,如裁剪和改变颜色。作为端到端的模型,ViLT采用了不包含裁剪和改变颜色二等图像增强,在实验中提高了模型的性能。
4. Experiments
预训练部分采用MSCOCO、VG、SBU和GCC数据集,合成4million数据集。

评估部分采用两种图文任务,分类和检索。分类任务进行了三次微调,而检索只采用一次。
4.2. Implementation Details
略。
4.3. Classification Tasks
分类任务在VQAv2和NLVR2上进行评估。微调采用两层MLP。VQA任务是给出图像和自然语言问题对的答案。NLVR2是二分类任务,给定两个图像和一个自然语言问题的三元组。
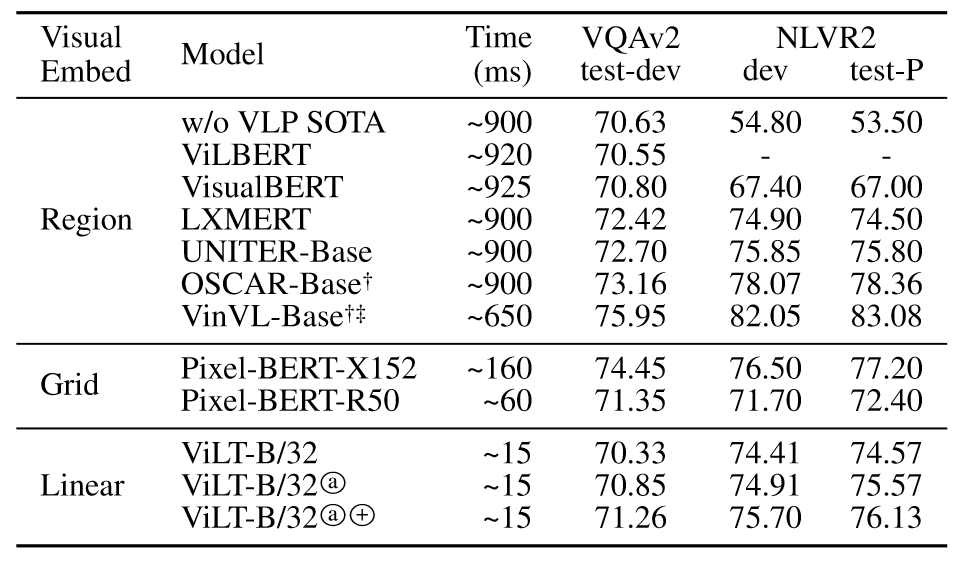
结果如上表所示,ViLT在VQAv2任务上表现不佳,可能的原因是目标检测器可以简化VQA的训练,因为VQA中问题通常询问对象。ViLT在NLVR2上表现出一定的竞争力。
4.4. Retrieval Tasks
对于图像到文本和文本到图像的检索任务,作者测量了零样本和微调的性能,结果分别如下:

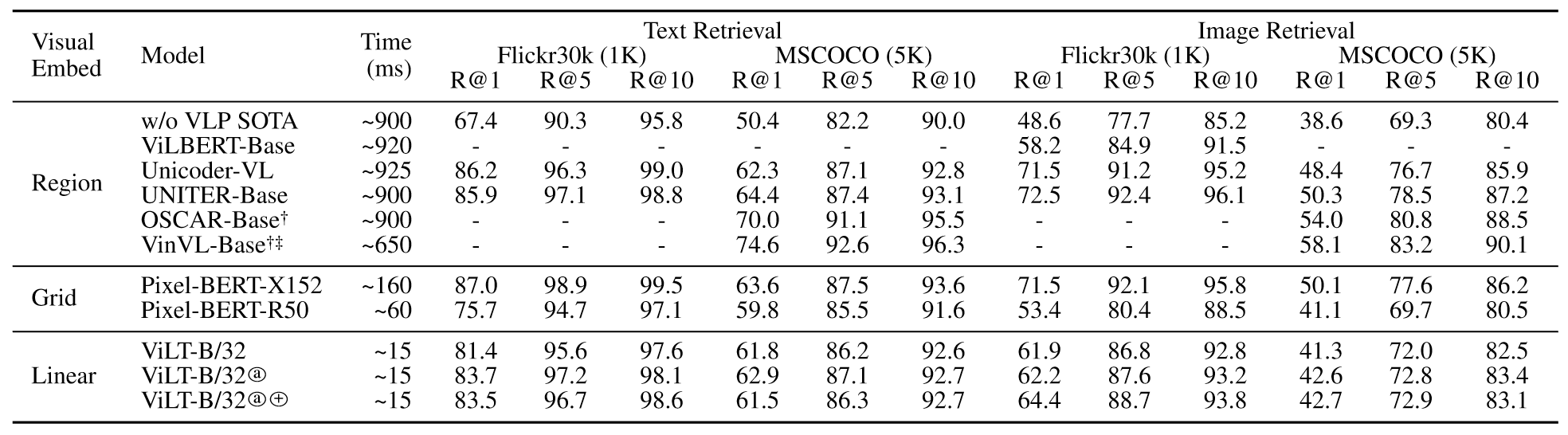
零样本上,ViLT比ImageBERT在更大的数据集上表现更好。微调表现上,ViLT的召回率大幅高于第二快的模型。
4.5. Ablation Study
下表展示了消融实验,更多的训练步数,全单词掩码和图像增强都对模型有增益,而额外的训练目标无济于事。
实际上这里额外的训练目标是图像块的掩码重建,只不过这篇文章出来的时候MAE还没有问世,因此对于图像块的掩码自监督训练还没有很好的解决方案,因此在这里没有增益不代表这个方法没有用。

4.6. Complexity Analysis of VLP Models
作者从不同角度分析了ViLT的复杂性。下表报告了参数量、浮点计算以及推理延迟。
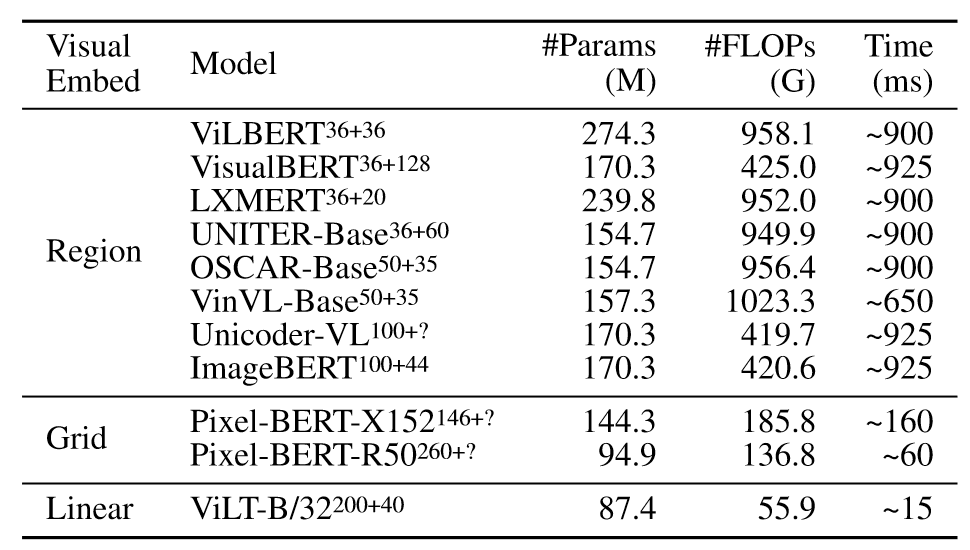
可以看出无论是参数量、FLOPs还是推理延迟,ViLT都极具优越性。
4.7. Visualization

上图是多模态对齐的示例,每个方形块对应图像块,文本中粉色部分是突出的文本token。可以看到,文本和图像块还是比较对齐的。
5. Conclusion and Future Work
本文提出了最小的VLP架构ViLT,轻量且高效,可以作为卷积视觉嵌入模型的平替,未来工作更多关注于Transformer内模态的交互,而不是仅仅拼接。下面是基于ViLT未来可以做的工作:
- 在更大的数据集下预训练会进一步提升模型性能。
- 视觉掩码目标理论上是可以达到文本掩码效果的。
- 可以补充增强策略来进一步提升模型效果。
阅读总结
一篇多模态领域的里程碑式的工作,其最大的卖点是将视觉特征提取领域耗时的ResNet完全剔除,将图像切分为图像块和文本一样,输入到相同的Transformer中进行处理,极大减少了特征提取过程的时间损耗,同时对性能也没有太大的影响。这样的工作将不同模态的模型进行了统一,也为之后多模态工作指明了新的道路。
文章的写作也很有技术,既然实验部分并没有太大的优势,那么就将重心放在轻量性上,第一页右上角的图像极具冲击力,近百倍的时间上的减少,更轻量的模型,端到端的训练,直接吊足了读者的胃口,此外结尾未来方向的展望,也为后序工作提供了方向。