GDB的功能及其丰富,我们按照调试的流程进行说明。基本用法很简单。
流程如下所示:
- 带着调试选项编译、构建调试对象。
- 启动调试器(GDB)
- 设置断点。
- 显示栈帧。
- 显示值。
- 继续执行。
一、准备
通过 gcc 的 -g 选项生成调试信息
gcc -Wall -O2 -g 源文件
如果使用Makefile 构建,一般要给CFLAGS中指定 -g 选项。
CFLAGS = -Wall -O2 -g
如果用configure 脚本生成 Makefile,可以这样用。
./configure CFLAGS=-Wall -O2 -g
构建方法通常会写在 INSTALL、README 等文件中,参考即可。
编译器含有针对源代码中的各种各样的错误输出信息的功能,称为警告选项(Warning Option)。这些信息并一定是错误,但却指出了容易引发bug的编码方式。
要用心写出整洁的代码,编译时不要出现警告甚至错误信息。编译错误是bug的最大来源。
-Werror 选项可以在警告发生时,将其当作错误来处理。
此外,发生编译器错误时不会生成可执行文件。
编译器GCC加上优化选项后,实际的执行顺序可能由于优化与源代码顺序不同,因此利用调试器跟踪运行时,有时会执行到莫名其妙的地方,从而造成混乱。比如内联(inline)函数优化(去掉函数调用,而将函数代码在调用处展开),该函数名上就无法设置断点。这是因为内联优化从目标文件中去掉了该函数的入口点,符号表中也没有改函数的名称。
优化还会将局部变量保存到寄存器中,因此无法显示该局部变量的内容,必须直接查看寄存器的值。由于这些副作用,有些人建议在调试时去掉优化选项进行编译和构建,但是我们不推荐这样做。
为什么呢?
使用C、C++ 这些过程式编程语言编程,就是利用编译器这个工具把我们期待的行为告诉计算机。尽管无需详细了解编译器优化选项的方方面面,但至少应当知道,优化编译选项可能会让执行顺序和源代码顺序不同。而优化选项就是在理解这一点的基础之上添加的,用来加快只想速度,所以没有必要特意去除。
如果只是调试时去掉优化选项,那就必须管理有优化编译选项和无优化编译选项两种可执行文件。管理对象增加会导致管理成本增加,并不是好事。这会消耗大量成本,比如花费大量时间对没有优化选项的可执行文件进行调试,但实际上优化后的可执行文件中的bug并不存在;那么怎么管理同一源代码进行编译、构建出不同可执行文件呢?
而且准备两个可执行文件的话,测试工作量肯定回变成两倍,管理成本也会上升。
二、启动
gdb 可执行文件名
通过emacs启动的方法是M-x gdb。
启动后显示下述信息,出现gdb提示符。
skyesysi@VM-8-95-centos ~/hack_test]$ gdb a.out
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-120.tl2
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /data/home/skyesysi/hack_test/a.out...done.
(gdb)
设置断点
可以在函数名和行号等上设置断点,程序运行后,到达断点就会自动暂停运行。此时可以查看该时刻的变量值,显示栈帧、重新设置断点或重新运行等。断点命令(break)可以简写为b。
格式:
break 断点
(gdb) b main
Breakpoint 1 at 0x400400: file assemble.c, line 17.
断点可以通过函数名、当前文件内的行号来设置,也可以先制定文件名再指定行号,还可以指定与暂停位置的偏移量,或者用地址来设置。
格式:
break 函数名
break 行号
break 文件名:行号
break 文件名:函数名
break +偏移量
break - 偏移量
break *地址
【例】

上面例子中,分别对iseq_compile()函数、compile.c的516行、暂停往后3行、地址(0x8116d6)设置断点。
如果不指定断点位置,就在下一行代码上设置断点。

设置好的断点可以通过info break 确认。

运行
用 run 命令开始运行,不加参数执行run,就会执行到设置断点的位置后暂停执行,可以简写为r。
格式:
run 参数

经常遇到的操作是在main() 上设置断点,然后执行到main() 函数,start 命令能达到同样的效果。
格式:
start
显示栈帧
backtrace命令可以在遇到断点而暂停执行时显示栈帧。该命令简写为bt。次啊外,backtrace 的别名还有 where 和 info stack(简写为info s)。
格式:
backtrace
bt
显示所有栈桢
backtrace N
bt N
只显示开头N个栈桢
backtrace -N
bt -N
只显示最后N个栈桢
backtrace full
bt full
backtrace full N
bt full N
backtrace full -N
bt full -N
不仅显示backtrace,还要显示局部变量。
【例】

【例:只显示前三个栈帧】
【例:从外向内显示3个栈帧,及其局部变量】
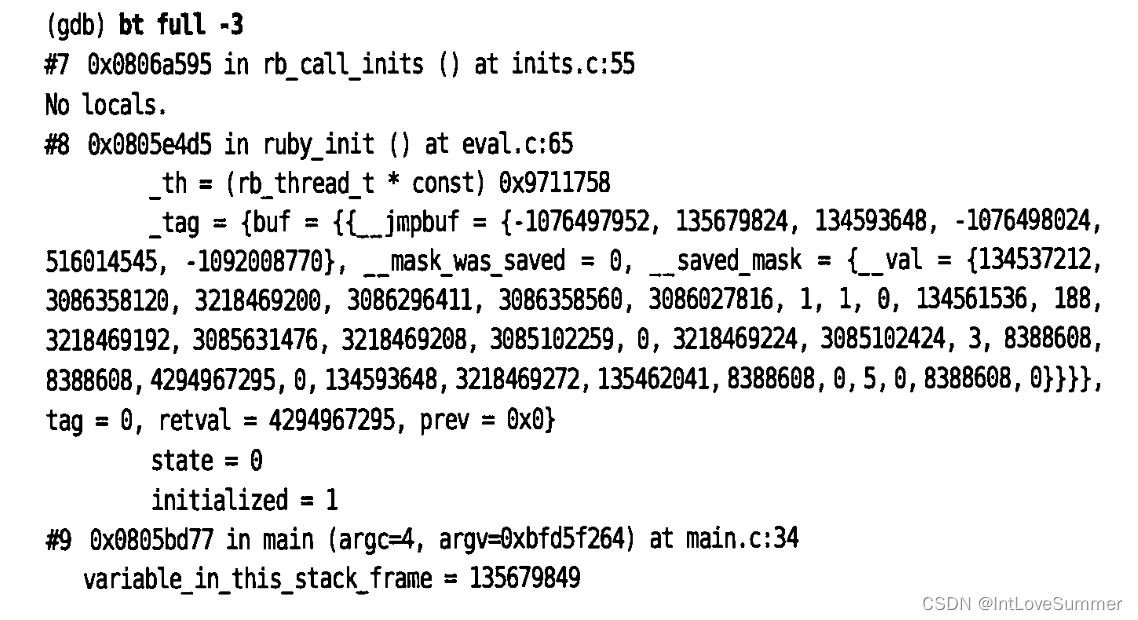
显示栈帧之后,就可以看到程序在何处停止(即断点位置),以及程序的调用路径。
显示变量
print 命令可以显示变量。print 可以简写为p。
格式:
print 变量

该例显示 argv[]。可以看出,argv[0] 中为可执行文件名(/home/hyoshiok/coreutils/src/uname),argv[1]中为第一个选项(-a)。
显示寄存器
info registers 可以显示寄存器,简写为info reg。
(gdb) info reg
rax 0x0 0
rbx 0x4f3c020 83083296
rcx 0x0 0
rdx 0x0 0
rsi 0x305c598 50709912
rdi 0x0 0
rbp 0x7f012b357870 0x7f012b357870
rsp 0x7f012b357860 0x7f012b357860
r8 0xffffffff 4294967295
r9 0x7f 127
r10 0x1 1
r11 0x246 582
r12 0x1 1
r13 0x4f6c068 83279976
r14 0x49d8710 77432592
r15 0x2ac3580 44840320
rip 0x43bdac 0x43bdac <qemu_bh_delete+28>
eflags 0x10246 [ PF ZF IF RF ]
cs 0x33 51
ss 0x2b 43
ds 0x2b 43
es 0x2b 43
fs 0x0 0
gs 0x0 0
在寄存器名之前添加$,即可显示各个寄存器的内容
(gdb) p $rax
$1 = 0
显示可以使用以下格式,如表2-3所示。
格式:
p / 格式 变量
表2-3 显示寄存器可使用的格式


十进制数的97为ASCII字符的 ‘a’ 。
程序指针可以写为$pc,也可写为eip,两者都可以显示。这是因为Intel IA-32 架构中的程序指针名为eip。
(gdb) p $pc
$2 = (void (*)()) 0x43bdac <qemu_bh_delete+28>
(gdb) p $rip
$3 = (void (*)()) 0x43bdac <qemu_bh_delete+28>
(gdb)
用 x 命令可以显示内存的内容。x 这个名字的由来是 eXaming。
格式:
x / 格式 地址
(gdb) x $pc
0x43bdac <qemu_bh_delete+28>: 0x001847c6
(gdb) x/i $pc
=> 0x43bdac <qemu_bh_delete+28>: movb $0x0,0x18(%rdi)
此处 x / i 意为显示汇编指令。
一般使用 x 命令时,格式为 x / NFU ADDR。此处ADDR 为希望显示的地址,N为重复次数,F为前面讲过的格式(x、d、u、o、t、a、c、f、s、i),U为表2-4 中所示的单位。

下面显示从 pc 所指的地址开始的10条指令。
(gdb) x/10i $pc
=> 0x43bdac <qemu_bh_delete+28>: movb $0x0,0x18(%rdi)
0x43bdb0 <qemu_bh_delete+32>: movb $0x1,0x1a(%rdi)
0x43bdb4 <qemu_bh_delete+36>: mov -0x8(%rbp),%rax
0x43bdb8 <qemu_bh_delete+40>: xor %fs:0x28,%rax
0x43bdc1 <qemu_bh_delete+49>: jne 0x43bdc5 <qemu_bh_delete+53>
0x43bdc3 <qemu_bh_delete+51>: leaveq
0x43bdc4 <qemu_bh_delete+52>: retq
0x43bdc5 <qemu_bh_delete+53>: callq 0x439308 <__stack_chk_fail@plt>
0x43bdca: nopw 0x0(%rax,%rax,1)
0x43bdd0 <qemu_bh_update_timeout>: push %rbp
也有反汇编的命令 disassemble,简写为disas
格式:
disassemble。
disassemble 程序计数器。
disassemble 开始地址 结束地址。
格式1 反汇编整个函数,2为反汇编程序计数器所在函数的整个函数,3为反汇编开始到结束的地址
(gdb)
Dump of assembler code for function qemu_bh_delete:
0x000000000043bd90 <+0>: push %rbp
0x000000000043bd91 <+1>: mov %rsp,%rbp
0x000000000043bd94 <+4>: sub $0x10,%rsp
0x000000000043bd98 <+8>: callq 0x529f40 <mcount>
0x000000000043bd9d <+13>: mov %fs:0x28,%rax
0x000000000043bda6 <+22>: mov %rax,-0x8(%rbp)
0x000000000043bdaa <+26>: xor %eax,%eax
=> 0x000000000043bdac <+28>: movb $0x0,0x18(%rdi)
0x000000000043bdb0 <+32>: movb $0x1,0x1a(%rdi)
0x000000000043bdb4 <+36>: mov -0x8(%rbp),%rax
0x000000000043bdb8 <+40>: xor %fs:0x28,%rax
0x000000000043bdc1 <+49>: jne 0x43bdc5 <qemu_bh_delete+53>
0x000000000043bdc3 <+51>: leaveq
0x000000000043bdc4 <+52>: retq
0x000000000043bdc5 <+53>: callq 0x439308 <__stack_chk_fail@plt>
End of assembler dump.
首先在任意位置暂停执行程序,即可像上例哪样自由显示任意变量和地址,通过确认其值与预期是否相同,以确认是否存在bug。
单步执行
单步执行的意思是根据源代码一行一行的执行。
执行源代码中的一行命令是next (简写为n)。执行时如果遇到函数调用,可能想执行到函数内部,此时可以用step(简写为s)命令。
例如,下例中