Hadoop
Hadoop是一个开源框架来存储和处理大型数据在分布式环境中。它包含两个模块,一个是MapReduce,另外一个是Hadoop分布式文件系统(HDFS)。
- MapReduce:它是一种并行编程模型在大型集群普通硬件可用于处理大型结构化,半结构化和非结构化数据。
- HDFS:Hadoop分布式文件系统是Hadoop的框架的一部分,用于存储和处理数据集。它提供了一个容错文件系统在普通硬件上运行。
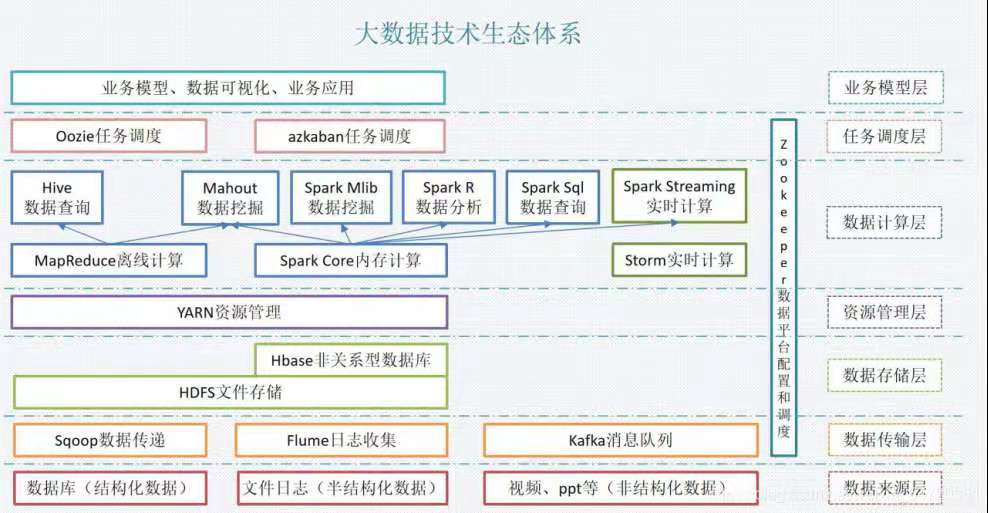
Hadoop生态系统包含了用于协助Hadoop的不同的子项目(工具)模块,如Sqoop, Pig 和 Hive。
- Sqoop: 它是用来在HDFS和RDBMS之间来回导入和导出数据。
- Pig: 它是用于开发MapReduce操作的脚本程序语言的平台。
- Hive: 它是用来开发SQL类型脚本用于做MapReduce操作的平台。
注:有多种方法来执行MapReduce作业:
- 传统的方法是使用Java MapReduce程序结构化,半结构化和非结构化数据。
- 针对MapReduce的脚本的方式,使用Pig来处理结构化和半结构化数据。
- Hive查询语言(HiveQL或HQL)采用Hive为MapReduce的处理结构化数据。
数据仓库
数据仓库(Data Warehousing, DW) 的本质,其实就是整合多个数据源的历史数据进行细粒度的、多维的分析,帮助高层管理者或者业务分析人员做出商业战略决策或商业报表。这里面就涉及到了数据仓库的分层方法:
- 数据运营层:ODS(Operational Data Store):存放原始数据,直接加载原始日志、数据,数据保存原貌不做处理。
- 数据仓库层:DW(Data Warehouse)
数据仓库层是我们在做数据仓库时要核心设计的一层,在这里,从 ODS 层中获得的数据按照主题建立各种数据模型。DW层又细分为 DWD(Data Warehouse Detail)层、DWM(Data WareHouse Middle)层和DWS(Data WareHouse Servce)层。
- 数据明细层:DWD(Data Warehouse Detail):结构与粒度与原始表保持一致,对ODS层数据进行ETL清洗
- 数据服务层:DWS(Data WareHouse Servce):以DWD为基础,进行轻度汇总
- 数据应用层: ADS(Application Data Servce):主要是提供给数据产品和数据分析使用的数据
- 维表层(Dimension)
如何搭建数据仓库
1、 分析业务需求,确定数据仓库主题
2、 构建逻辑模型:明确需求目标、维度、指标、方法、源数据等
3、 逻辑模型转换为物理模型:事实表表名,包括列名、数据类型、是否是空值以及长度等
4、 ETL过程
5、 OLAP建模,报表设计,数据展示
OLAP(Online analytical processing),即联机分析处理,主要用于支持企业决策管理分析
ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),Kettle就是强大的ETL工具。

Hadoop安装配置
HIVE安装配置