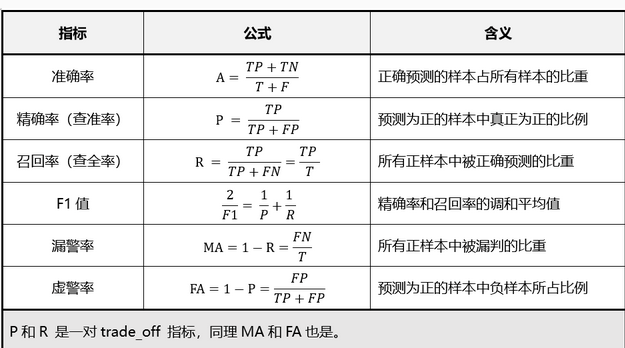
准确率 (Accuracy),混淆矩阵 (Confusion Matrix),精确率(Precision),召回率(Recall),平均正确率(AP),mean Average Precision(mAP),交除并(IoU),ROC + AUC,非极大值抑制(NMS)。
首先再回顾一下基础的评价标准三件套(假设一共一百学生,男女各半,检测的时候男生全部检测正确,女生有25人分为男生):
1. 准确率 accuracy:分类对的样本除以总样本个数,这个一般是针对于整个分类任务说的,这里一共分对了男生50人加女生25人也就是分对了75人,acc=0.75
2. 召回率recall,这个是针对某一类来说的,也就是一般说男生的recall,女生的recall,通俗来讲,recall总是偏心于自己这一类,就像孙子的奶奶一样,我孙子好了就行,其他人爱咋咋的,也就是他只管自己负责的这一类有多少被检测出来了,而不管其他类有多少误分成我这一类,比如本例中男生的recall是1,因为男生全部被检测出来了,所以男生的recall就高,女生只有一半被检测出来了,所以她的recall就是0.5
3.精确率precision(蛇皮翻译,和准确率有个naizi区别),这个也是针对某一类来说的,这个相对于recall这个亲奶奶,就是后奶奶了,就会鸡蛋里挑骨头,好不容易有一些分成本类的,她还要挑挑捡捡,看是不是真的本类,也就是代表了被检出的某一类中,真正是该类的样本占的概率,本例中男生的precision是50/75=0.666,女生的precision就是25/25=1啦
1、准确率 (Accuracy)
分对的样本数除以所有的样本数 ,即:准确(分类)率 = 正确预测的正反例数 / 总数。
准确率一般用来评估模型的全局准确程度,不能包含太多信息,无法全面评价一个模型性能。
Accuracy:也是对模型预测准确的整体评估, 通常用到的准确率计算公式如下:
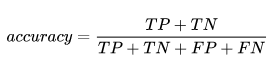
2、混淆矩阵 (Confusion Matrix)
混淆矩阵中的横轴是模型预测的类别数量统计,纵轴是数据真实标签的数量统计。
对角线,表示模型预测和数据标签一致的数目,所以对角线之和除以测试集总数就是准确率。对角线上数字越大越好,在可视化结果中颜色越深,说明模型在该类的预测准确率越高。如果按行来看,每行不在对角线位置的就是错误预测的类别。总的来说,我们希望对角线越高越好,非对角线越低越好。
3、精确率(Precision)与召回率(Recall)
准确率与召回率(Precision & Recall)
准确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。其中精度是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。
一般来说,Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
正确率、召回率和 F 值是在鱼龙混杂的环境中,选出目标的重要评价指标。不妨看看这些指标的定义先:
1. 正确率 = 提取出的正确信息条数 / 提取出的信息条数
2. 召回率 = 提取出的正确信息条数 / 样本中的信息条数
两者取值在0和1之间,数值越接近1,查准率或查全率就越高。
3. F值 = 正确率 * 召回率 * 2 / (正确率 + 召回率) (F 值即为正确率和召回率的调和平均值)
不妨举这样一个例子:某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
不妨看看如果把池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标又有何变化:
正确率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
F值 = 70% * 100% * 2 / (70% + 100%) = 82.35%
由此可见,正确率是评估捕获的成果中目标成果所占得比例;召回率,顾名思义,就是从关注领域中,召回目标类别的比例;而F值,则是综合这二者指标的评估指标,用于综合反映整体的指标。
当然希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的,那么Precision就是100%,但是Recall就很低;而如果我们把所有结果都返回,那么比如Recall是100%,但是Precision就会很低。因此在不同的场合中需要自己判断希望Precision比较高或是Recall比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。

一些相关的定义。假设现在有这样一个测试集,测试集中的图片只由大雁和飞机两种图片组成,假设你的分类系统最终的目的是:能取出测试集中所有飞机的图片,而不是大雁的图片。
- True positives : 正样本被正确识别为正样本,飞机的图片被正确的识别成了飞机。
- True negatives: 负样本被正确识别为负样本,大雁的图片没有被识别出来,系统正确地认为它们是大雁。
- False positives: 假的正样本,即负样本被错误识别为正样本,大雁的图片被错误地识别成了飞机。
- False negatives: 假的负样本,即正样本被错误识别为负样本,飞机的图片没有被识别出来,系统错误地认为它们是大雁。
Precision其实就是在识别出来的图片中,True positives所占的比率。也就是本假设中,所有被识别出来的飞机中,真正的飞机所占的比例。
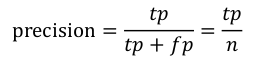
Recall 是测试集中所有正样本样例中,被正确识别为正样本的比例。也就是本假设中,被正确识别出来的飞机个数与测试集中所有真实飞机的个数的比值。
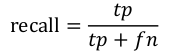
如果一个分类器的性能比较好,那么它应该有如下的表现:在Recall值增长的同时,Precision的值保持在一个很高的水平。而性能比较差的分类器可能会损失很多Precision值才能换来Recall值的提高。通常情况下,文章中都会使用Precision-recall曲线,来显示出分类器在Precision与Recall之间的权衡
4、平均精度(Average-Precision,AP)与 mean Average Precision(mAP)
AP就是Precision-recall 曲线下面的面积,通常来说一个越好的分类器,AP值越高。
mAP是多个类别AP的平均值。这个mean的意思是对每个类的AP再求平均,得到的就是mAP的值,mAP的大小一定在[0,1]区间,越大越好。该指标是目标检测算法中最重要的一个。
在正样本非常少的情况下,PR表现的效果会更好。
mAP指的是各类别的AP平均值,而AP指PR曲线的面积(precision和Recall关系曲线),因此得先了解下precision(精确率)和recall(召回率),以及相关的accuracy(准确度), F-measurement(F值), ROC曲线等。
recall和precision是二分类问题中常用的评价指标,通常以关注的类为正类,其他类为负类,分类器的结果在测试数据上有4种情况:

Precision和Recall计算举例:
假设我们在数据集上训练了一个识别猫咪的模型,测试集包含100个样本,其中猫咪60张,另外40张为小狗。测试结果显示为猫咪的一共有52张图片,其中确实为猫咪的共50张,也就是有10张猫咪没有被模型检测出来,而且在检测结果中有2张为误检。因为猫咪更可爱,我们更关注猫咪的检测情况,所以这里将猫咪认为是正类:所以TP=50,TN=38,FN=10,FP=2,P=50/52,R=50/60,acc=(50+38)/(50+38+10+2)
为什么引入Precision和Recall:
recall和precision是模型性能两个不同维度的度量:在图像分类任务中,虽然很多时候考察的是accuracy,比如ImageNet的评价标准。但具体到单个类别,如果recall比较高,但precision较低,比如大部分的汽车都被识别出来了,但把很多卡车也误识别为了汽车,这时候对应一个原因。如果recall较低,precision较高,比如检测出的飞机结果很准确,但是有很多的飞机没有被识别出来,这时候又有一个原因.
recall度量的是「查全率」,所有的正样本是不是都被检测出来了。比如在肿瘤预测场景中,要求模型有更高的recall,不能放过每一个肿瘤。
precision度量的是「查准率」,在所有检测出的正样本中是不是实际都为正样本。比如在垃圾邮件判断等场景中,要求有更高的precision,确保放到回收站的都是垃圾邮件。
F-score/F-measurement:
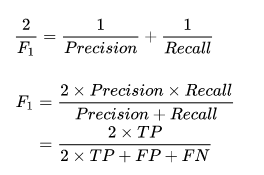
上面分析发现,精确率和召回率反映了分类器性能的两个方面,单一依靠某个指标并不能较为全面地评价一个分类器的性能。一般情况下,精确率越高,召回率越低;反之,召回率越高,精确率越低。为了平衡精确率和召回率的影响,较为全面地评价一个分类器,引入了F-score这个综合指标。
F-score是精确率和召回率的调和均值,计算公式如下:

其中, 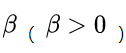 的取值反映了精确率和召回率在性能评估中的相对重要性具体,通常情况下,取值为1。描述如下:
的取值反映了精确率和召回率在性能评估中的相对重要性具体,通常情况下,取值为1。描述如下:
(1) ,表明精确率和召回率一样重要,计算公式如下:
,表明精确率和召回率一样重要,计算公式如下:

AP/PR曲线:
即recall为横坐标,precision为纵坐标,绘制不同recall下的precison值,可以得到一条Precisoin和recall的曲线,AP就是这个P-R曲线下的面积,定义:
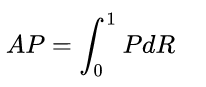
举例子比较好理解,
分类问题:
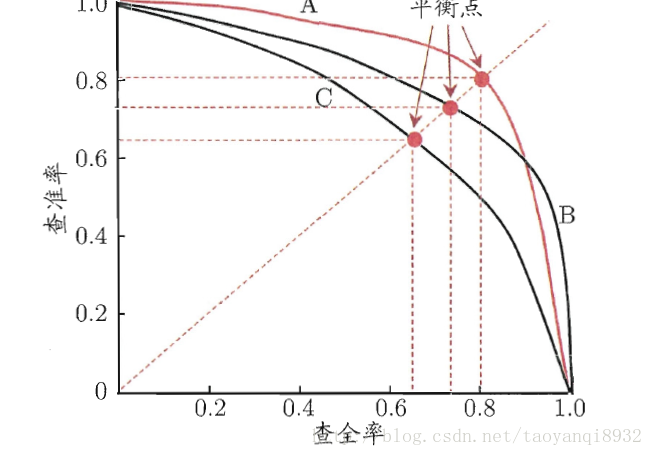
假设有100张图片,要分成猫,狗,鸡三类,100张图片对应100个真实值,模型分类后我们会得到对应的100个预测值。这里我们可以只取前10个预测值出来,计算10个值中猫预测出几张,预测对几张,从而能计算出猫的precison和recall;接着我们可以取前20个预测值同样能计算出一组猫的precison和recall;这样一直增加到取100个预测值,就能得到猫的10组(recall, precision)值来绘制曲线。这里要注意的是:随着选取预测值增加,recall肯定是增加或不变的(选取的预测值越多,预测出来的猫越多,即查全率肯定是在增加或不变),若增加选取预测值后,recall不变,一个recall会对应两个precison值,一般选取较大的那个precision值。 如果我们每次只增加一个预测值,就会得到大约100对(recall, precisoin)值,然后就能绘制猫的PR曲线,计算出其下方的面积,就是猫对应的AP值(Average Precision)。 如果我们接着对狗和鸡也采用相同方法绘制出PR曲线, 就能得到猫,狗, 鸡三个AP值,取平均值即得到了整个模型最终的mAP(mean Average Precsion)。如下图中A, B, C三条PR曲线:
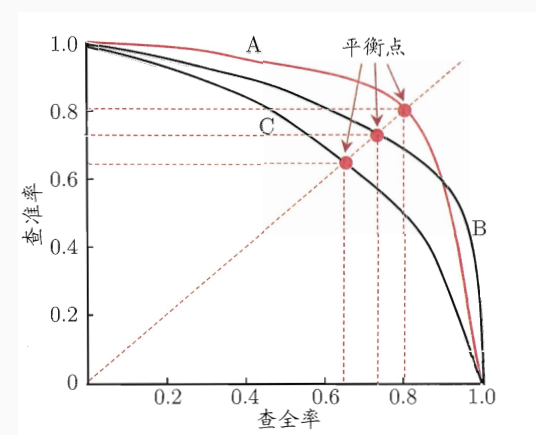
P-R曲线
P-R曲线,即以precision和recall作为纵、横轴坐标的二维曲线。越凸越右上方效果越好。通过选取不同阈值时对应的精度和召回率画出总体趋势,精度越高,召回越低,当召回达到1时,对应概率分数最低的正样本,这个时候正样本数量除以所有大于等于该阈值的样本数量就是最低的精度值。P-R曲线围起来的面积就是AP值,面积越大,识别精度也就越高,AP值越高,反之越低。

根据逐个样本作为阈值划分点的方法,可以推敲出,recall值是递增的(但并非严格递增),随着阈值越来越小,正例被判别为正例的越来越多,不会减少。而精确率precision并非递减,有可能是振荡的,虽然正例被判为正例的变多,但负例被判为正例的也变多了,因此precision会振荡,但整体趋势是下降。一般来说,precision和recall是鱼与熊掌的关系,往往召回率越高,准确率越低。
在不考虑预测样本量为0的情况下:
如果最前面几个点都是负例,那么曲线会从(0,0)点开始逐渐上升,随着阈值越来越小,precision初始很接近1,recall很接近0,因此有可能从(0,0)上升的线和坐标重合,不易区分。
如果最前面几个点都是正例,那么曲线会从(0,1)逐渐下降。
曲线最终不会到(1,0)点。很多P-R曲线的终点看着都是(1,0)点,这可能是因为负例远远多于正例。
在目标检测中,每一类都可以根据 recall 和 precision绘制P-R曲线,AP就是该曲线下的面积,mAP就是所有类AP的平均值。
2. FLOPs (浮点运算数)
FLOPs:(Floating Point Operations) s小写,指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。(模型) 在论文中常用GFLOPs(1 GFLOPs = 10^9 FLOPs)
FLOPS: (Floating Point operations per second), S大写, 指每秒浮点运算的次数,可以理解为运算的速度,是衡量硬件性能的一个指标。
一般计算FLOPs来衡量模型的复杂度,FLOPs越小时,表示模型所需计算量越小,运行起来时速度更快。对于卷积和全连接运算,其公式如下:
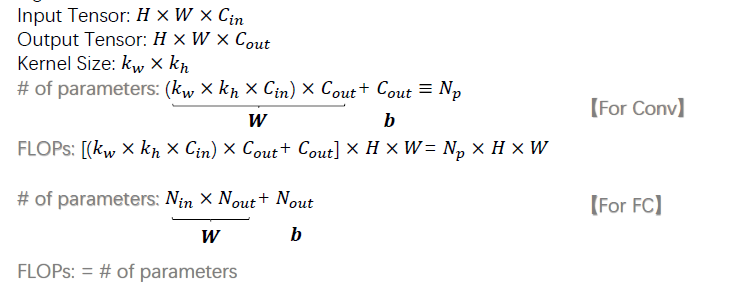
另外,MAC(memory access cost, 内存访问成本)也会被用来衡量模型的运行速度, 一般MAC=2*FLOPs (一次加法运算和一次乘法算法):
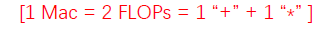
有一个基于pytorch的torchstat包,可以计算模型的FLOPs数,参数大小等指标,示例代码如下:
from torchstat import stat
import torchvision.models as models
model = model.alexnet()
stat(model, (3, 224, 224))
3. 模型参数大小
常用模型的参数所占大小来衡量模型所需内存大小,一般可分为Vgg, GoogleNet, Resnet等参数量大的模型,和squeezeNet,mobilerNet,shuffleNet等参数量小的轻量级模型,常用一些模型的参数量和FLOPs如下:
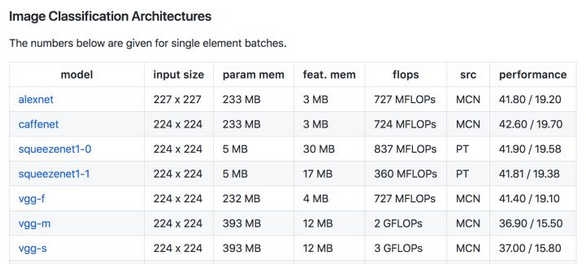
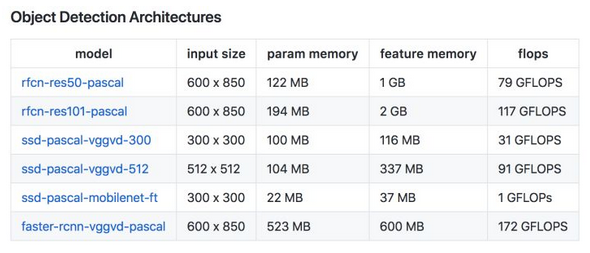
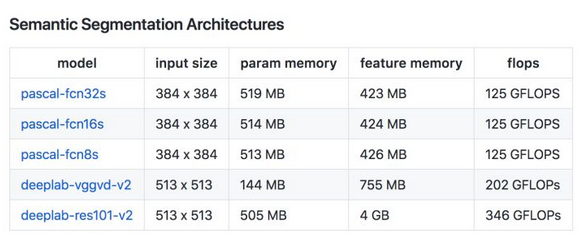
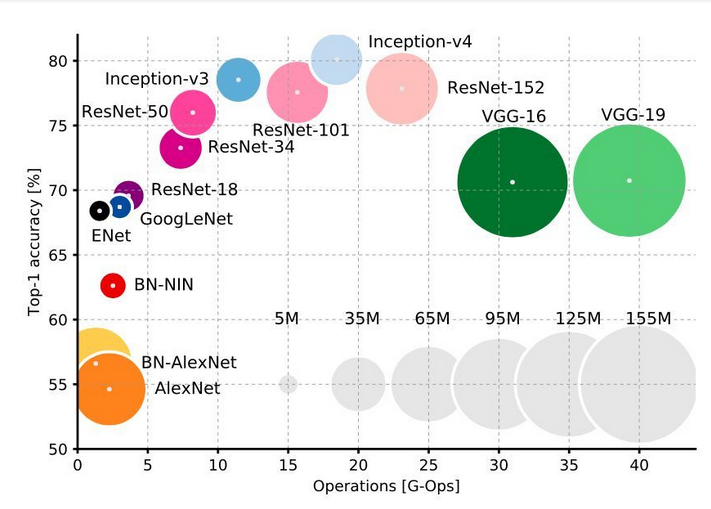
最后还有一张模型运算量(FLOPs), 参数大小(圆圈的面积),表现效果(Accuracy)的关系图如下:
5、IoU
IoU这一值,可以理解为系统预测出来的框与原来图片中标记的框的重合程度。 计算方法即检测结果Detection Result与 Ground Truth 的交集比上它们的并集,即为检测的准确率。
IOU正是表达这种bounding box和groundtruth的差异的指标:
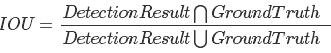
目标检测:
在目标检测中还有一个IoU(交并比、Intersection over Union、IoU), 通过比较检测bbox和真实bbox的IoU来判断是否属于TP(True Positive),例如设置IoU阈值为0.7,则IoU大于0.7的则判定为TP,否则为FP。因此当我们设置不同的IoU阈值时,也会得到不同的mAP值,再将这些mAP值进行平均就会得到mmAP,一般不做特别说明mmAP即指通常意义上的mAP。
因此目标检测mAP计算方法如下:给定一组IOU阈值,在每个IOU阈值下面,求所有类别的AP,并将其平均起来,作为这个IOU阈值下的检测性能,称为mAP(比如mAP@0.5就表示IOU阈值为0.5时的mAP);最后,将所有IOU阈值下的mAP进行平均,就得到了最终的性能评价指标:mmAP。
定位准确率
IOU
定位准确率可以通过检测窗口与我们自己标记的物体窗口的重叠度,即交并比,即Intersection-Over-Union(IOU)进行度量。设标记窗口为 A ,检测窗口为 B ,则 IOU 的计算公式如下:
I O U = A ⋂ B A ⋃ B IOU=\frac{A\bigcap B}{A\bigcup B}IOU=A⋃BA⋂B
其中分子部分表示 A 与 B 窗口的重叠部分面积,分母部分表示 A 与 B
窗口的面积总和。显而易见,IOU 的值在[0,1]之间,同时 IOU 越接近 1
表示两个窗口重叠部分越多,定位准确度也就越好,反之则越差。
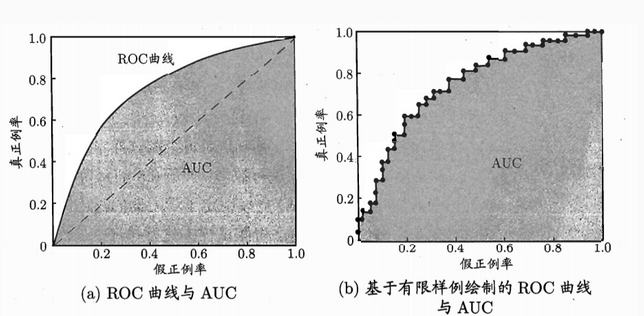
6、ROC(Receiver Operating Characteristic)曲线与AUC(Area Under Curve)

ROC曲线:
- 横坐标:假正率(False positive rate, FPR),FPR = FP / [ FP + TN] ,代表所有负样本中错误预测为正样本的概率,假警报率;
- 纵坐标:真正率(True positive rate, TPR),TPR = TP / [ TP + FN] ,代表所有正样本中预测正确的概率,命中率。
对角线对应于随机猜测模型,而(0,1)对应于所有整理排在所有反例之前的理想模型。曲线越接近左上角,分类器的性能越好。
ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
ROC曲线绘制:
(1)根据每个测试样本属于正样本的概率值从大到小排序;
(2)从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本;
(3)每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。
当我们将threshold设置为1和0时,分别可以得到ROC曲线上的(0,0)和(1,1)两个点。将这些(FPR,TPR)对连接起来,就得到了ROC曲线。当threshold取值越多,ROC曲线越平滑。
AUC(Area Under Curve)即为ROC曲线下的面积。AUC越接近于1,分类器性能越好。
物理意义:首先AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
计算公式:就是求曲线下矩形面积。

除了绘制PR曲线,计算AP,有时候也会绘制ROC曲线,计算AUC。(参考文章)
ROC(receiveroperating characteristic):接受者操作特征,指的是TPR和FPR间的关系,纵坐标为TPR, 横坐标为FPR, 计算公式如下:
AUC(area under curve):表示ROC曲线下的面积。

AUC
ROC曲线
简单易于理解的例子
某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
精确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F1值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
不妨看看,如果把池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标又有何变化:
正确率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
F1值 = 70% * 100% * 2 / (70% + 100%) = 82.35%
随着召回率增大,精度
7、PR曲线和ROC曲线比较
ROC曲线特点:
(1)优点:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。因为TPR聚焦于正例,FPR聚焦于与负例,使其成为一个比较均衡的评估方法。
在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
(2)缺点:上文提到ROC曲线的优点是不会随着类别分布的改变而改变,但这在某种程度上也是其缺点。因为负例N增加了很多,而曲线却没变,这等于产生了大量FP。像信息检索中如果主要关心正例的预测准确性的话,这就不可接受了。在类别不平衡的背景下,负例的数目众多致使FPR的增长不明显,导致ROC曲线呈现一个过分乐观的效果估计。ROC曲线的横轴采用FPR,根据FPR ,当负例N的数量远超正例P时,FP的大幅增长只能换来FPR的微小改变。结果是虽然大量负例被错判成正例,在ROC曲线上却无法直观地看出来。(当然也可以只分析ROC曲线左边一小段)
PR曲线:
(1)PR曲线使用了Precision,因此PR曲线的两个指标都聚焦于正例。类别不平衡问题中由于主要关心正例,所以在此情况下PR曲线被广泛认为优于ROC曲线。
使用场景:
- ROC曲线由于兼顾正例与负例,所以适用于评估分类器的整体性能,相比而言PR曲线完全聚焦于正例。
- 如果有多份数据且存在不同的类别分布,比如信用卡欺诈问题中每个月正例和负例的比例可能都不相同,这时候如果只想单纯地比较分类器的性能且剔除类别分布改变的影响,则ROC曲线比较适合,因为类别分布改变可能使得PR曲线发生变化时好时坏,这种时候难以进行模型比较;反之,如果想测试不同类别分布下对分类器的性能的影响,则PR曲线比较适合。
- 如果想要评估在相同的类别分布下正例的预测情况,则宜选PR曲线。
- 类别不平衡问题中,ROC曲线通常会给出一个乐观的效果估计,所以大部分时候还是PR曲线更好。
- 最后可以根据具体的应用,在曲线上找到最优的点,得到相对应的precision,recall,f1 score等指标,去调整模型的阈值,从而得到一个符合具体应用的模型。
8、非极大值抑制(NMS)
Non-Maximum Suppression就是需要根据score矩阵和region的坐标信息,从中找到置信度比较高的bounding box。对于有重叠在一起的预测框,只保留得分最高的那个。
(1)NMS计算出每一个bounding box的面积,然后根据score进行排序,把score最大的bounding box作为队列中首个要比较的对象;
(2)计算其余bounding box与当前最大score与box的IoU,去除IoU大于设定的阈值的bounding box,保留小的IoU得预测框;
(3)然后重复上面的过程,直至候选bounding box为空。
最终,检测了bounding box的过程中有两个阈值,一个就是IoU,另一个是在过程之后,从候选的bounding box中剔除score小于阈值的bounding box。需要注意的是:Non-Maximum Suppression一次处理一个类别,如果有N个类别,Non-Maximum Suppression就需要执行N次。
速度
除了检测准确度,目标检测算法的另外一个重要性能指标是速度,只有速度快,才能实现实时检测,这对一些应用场景极其重要。评估速度的常用指标是每秒帧率(Frame Per Second,FPS),即每秒内可以处理的图片数量



