文章目录
- 1.数据预处理
-
- 2.主题建模Topic modelling
- 3.情感分析
- 4.观察结果
原文章地址
当创建一个成功的商业,其中最重要的元素是与顾客的沟通和关系。然而主要挑战是,随着用户基数的不断提升,产生的数据量也越来越庞大,而且大部分是以自然语言的形式存在。这些数据来自用户的反馈会来自社交媒体,顾客传达他们的想法和意见。
而真正的挑战是自动将这些数据解析并组织成更易消化和可行的见解。其中一种方法是情感分析。
一个意见opinion可以定义为四种元素的组合(实体,意见持有者,主张,情感)entity, holder, claim, and sentiment。
意见持有者对一个实体有一种主张,在多数情况下,伴随有情感。
Aspect-Based sentiment analysis 就是要提取文本中所描述的实体以及,对这实体所持有的情感
1.数据预处理
1.1数据集
数据主要用的是这个数据集Julian McAuley. 数据集包含了来自亚马逊的评论和元数据,有1.4亿个评论,跨度从1996年到2014年,数据集包括了评论文本,打分,是否有帮助投票,产品形容,类别信息,价格,品牌,图像还有链接。我们使用的是对手机和配件的评论数据。这类评论数据集有194439个样本
1.2 数据预处理步骤
我们会执行标准的数据预处理技术:
1.将文本小写化
2.去除标点符号以及多余的空格
3.分词
4.去除停用词
5.词干还原
最后一步是将评论文本向量化,变成数字格式,这样模型才能处理。这里用的是最简单的词袋模型,用的是sklearn中的CounterVectorizer方法。
vectorizer = CountVectorizer(analyzer = 'word', ngram_range = (1, 2))
vectors = []
for index, row in df.iterrows():
vectors.append(", ".join(row[1]))
vectorised = vectorizer.fit_transform(vectors)
print(vectorised)
2.主题建模Topic modelling
Topic modelling 是一个非监督学习方法,用于将文本分配到最能表征此类文档的组中。这个概念也可以用于提取文本aspect
Sklearn 有LDA文档主题生成模型。我们希望抽取5个方向aspect,一旦参数设置好了,我们可以将LDA应用于文本的词向量
为了便于更好的的阅读结果,我们将输出的相关score附加在每个评论的后面,并选取最高relevance score的topic作为dominant topic主要主题
lda_model = LatentDirichletAllocation(n_components = 5,
random_state = 10,
evaluate_every = -1,
n_jobs = -1,
)
lda_output = lda_model.fit_transform(vectorised)
topic_names = ["Topic" + str(i) for i in range(1, lda_model.n_components + 1)]
df_document_topic = pd.DataFrame(np.round(lda_output, 2), columns = topic_names)
dominant_topic = (np.argmax(df_document_topic.values, axis=1)+1)
df_document_topic['Dominant_topic'] = dominant_topic
df = pd.merge(df, df_document_topic, left_index = True, right_index = True, how = 'outer')
display(df.head(10))

现在我们能看到每个评论属于哪个topic了,但是LDA从这些评论中到底抽取出了哪些关键词?
我们可以通过调用vectoriser的get_feature_names()来观察
并且用LDA的componets 函数来看 aspect对应的relevance score相关性分数
docnames = ['Doc' + str(i) for i in range(len(data))]
df_document_topic = pd.DataFrame(np.round(lda_output, 2), columns=topic_names, index=docnames)
dominant_topic = np.argmax(df_document_topic.values, axis=1)
df_document_topic['dominant_topic'] = dominant_topic
df_topic_keywords = pd.DataFrame(lda_model.components_)
df_topic_keywords.columns = vectorizer.get_feature_names()
df_topic_keywords.index = topicnames
df_topic_no = pd.DataFrame(df_topic_keywords.idxmax())
df_scores = pd.DataFrame(df_topic_keywords.max())
tmp = pd.merge(df_topic_no, df_scores, left_index=True, right_index=True)
tmp.columns = ['topic', 'relevance_score']
display(tmp)
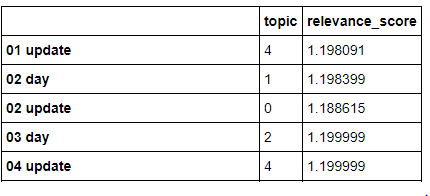
我们通过获取5个最高相关性分数来确定关键词keyword属于哪个aspect方面。然后,对于每个aspect,我们可以对dataframe进行排列,,选择得分最高的关键字。
ll_topics = []
for i in tmp['topic'].unique():
tmp_1 = tmp.loc[tmp['topic'] == i].reset_index()
tmp_1 = tmp_1.sort_values('relevance_score', ascending=False).head(1)
tmp_1['topic'] = tmp_1['topic'] + 1
tmp_2 = []
tmp_2.append(tmp_1['topic'].unique()[0])
tmp_2.append(list(tmp_1['index'].unique()))
all_topics.append(tmp_2)
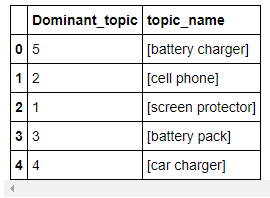
all_topics = pd.DataFrame(all_topics, columns=['Dominant_topic', 'topic_name'])
display(all_topics)
获得5个aspect
3.情感分析
文中用的是VADER,一个python的情感那分析库,将句子分类成正负中,三个类
最简单的方式是使用情感词典,每个词都有情感分数,VADER就是使用这种方法,给每个句子里的词打分,然后计算这句话有多少概率是什么情感。并且提供一个总分,-1到1之间,表示这个句子的情感极性
VADER的好处之一是,不需要任何预处理文本的过程。直接将raw data 放进取就好。
首先引入VADER的SentimentIntensityAnalyzer函数
然后设置阈值,来将获得的分数分成正,中,负
这里设置分数大于0.05就为正,小于-0.05都为负,中间的是中性。
analyser = SentimentIntensityAnalyzer()
sentiment_score_list = []
sentiment_label_list = []
for i in df['remove_lower_punct'].values.tolist():
sentiment_score = analyser.polarity_scores(i)
if sentiment_score['compound'] >= 0.05:
sentiment_score_list.append(sentiment_score['compound'])
sentiment_label_list.append('Positive')
elif sentiment_score['compound'] > -0.05 and sentiment_score['compound'] < 0.05:
sentiment_score_list.append(sentiment_score['compound'])
sentiment_label_list.append('Neutral')
elif sentiment_score['compound'] <= -0.05:
sentiment_score_list.append(sentiment_score['compound'])
sentiment_label_list.append('Negative')
df['sentiment'] = sentiment_label_list
df['sentiment score'] = sentiment_score_list
display(df.head(10))
4.观察结果
当我们提取每个评论的情感后,我们就可以为5个aspect画图

这幅图显示了,对于每个aspect,大部分评论是正面的,尤其是83000个screen protector评论中约5万个评论是正面的。对于一个生意来说,超过50%的正面评论,代表着,顾客对你的产品有较好的印象。
除了情感分类,每个文本中的词也很重要,这些情感词汇通常由特殊的词典提供。情感词汇通常是形容词,good,bad;或副词,weirdly,cheerfully,形容词:blessing,rubbish,动词,love hate
情感,可能也会通过比较词来传达,比如说worse,better。要找出这些个形容词,副词,名词。。我们可以用POS词性标注,
这里使用的是NLTK的词性标注,因为我们有着一个很大的数据集,我们希望自动将情感词的范围缩小。这里使用SentiWordNet,为每个词提供情感分类,正面,负面,客观性
客观词是定义那些不会影响个人情感的词,或者是对事实的客观陈述。相反的就是主观词。根据打分,我们希望找出那些客观性打分低的那些词。但是并不是所有的主观词都是情感词。
为了从主观词中抓取出情感词,我们使用另一种词汇资源WordNet-Affect
一旦检查出主观词,就有把握确定他们是情感词,基于SentiWordNet,我们对他进行情感极性打分,然后在计算,这些词的词频。
from nltk.corpus import wordnet
def get_wordnet_pos(treebank_tag):
if treebank_tag.startswith('J'):
return wordnet.ADJ
elif treebank_tag.startswith('V'):
return wordnet.VERB
elif treebank_tag.startswith('N'):
return wordnet.NOUN
elif treebank_tag.startswith('R'):
return wordnet.ADV
else:
pass
positive_words = []
negative_words = []
for i in df['Dominant_topic'].unique():
if i == 1:
tmp_1 = df.loc[df['Dominant_topic'] == i]
for j in tmp_1['tokenise'].values.tolist():
for p in nltk.pos_tag(j):
get_pos_tag = get_wordnet_pos(p[1])
if type(get_pos_tag) == str:
try:
synset = swn.senti_synset(p[0] + '.' + get_pos_tag +'.01')
if synset.obj_score() <= 0.49:
if synset.pos_score() > synset.neg_score() and p[0] in wn_affect:
positive_words.append(p[0])
elif synset.neg_score() > synset.pos_score() and p[0] in wn_affect:
negative_words.append(p[0])
except:
pass
就能生成词云

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)