在linux下,我们经常通过wget,curl等命令在某官方网站下载一个zip或者tar.gz格式文件,有时候,我们不会去关注这个下载文件后面的md5值和sha1值,这两个值其实有很大的用处,他可以帮助我们验证下载的文件是否经过人为篡改,或者下载是否完整。
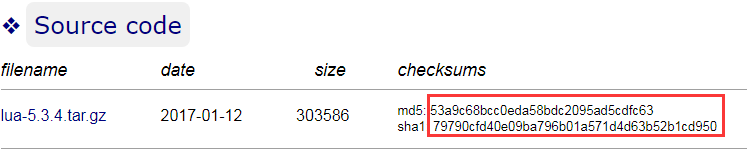
centos默认提供了md5sum,sha1sum方法可以帮助我们校验下载文件的正确性完整性。
[root@server software]# md5sum lua-5.3.4.tar.gz
53a9c68bcc0eda58bdc2095ad5cdfc63 lua-5.3.4.tar.gz
[root@server software]# md5sum lua-5.3.4.tar.gz > lua-md5.txt
[root@server software]# md5sum -c lua-md5.txt
lua-5.3.4.tar.gz: OK
[root@server software]#
从结果可以看出,直接运行md5sum lua-5.3.4.tar.gz命令就可以看出lua-5.3.4.tar.gz文件的md5值,通过对比发布者发布的md5就可以确定文件是否完整。
sha1sum检查方法和md5sum类似。另外,linux还提供了sha224sum,sha256sum,sha384sum,sha512sum方法。
[root@server software]# sha1sum lua-5.3.4.tar.gz
79790cfd40e09ba796b01a571d4d63b52b1cd950 lua-5.3.4.tar.gz
[root@server software]# sha1sum lua-5.3.4.tar.gz > lua-5.3.4.txt
[root@server software]# sha1sum -c lua-5.3.4.txt
lua-5.3.4.tar.gz: OK
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)