scylladb号称世界上最快的nosql数据库,它使用c++语言编写,运用了seastar框架,和cassandra,dynamodb数据库相似,但是据说性能是cassandra的10倍以上,这里在centos7.2上通过yum方式安装。
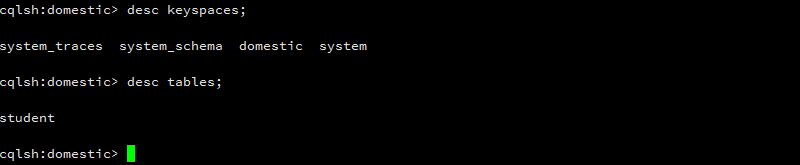
先给出一个scylladb通过cqlsh命令进入命令行的截图,感受一下scylladb和cassandra是多么的神奇相似:

scylladb官方网站上快速开始中说明,如果需要通过二进制方式安装,需要通过邮箱注册一下scylla账户,然后点击邮箱的链接,会给出scylladb安装的repo文件。
1、安装epel-release扩展包,如果已经安装可以跳过。
yum install epel-release
2、使用邮箱注册scylladb账户,然后点击邮箱中确认邮件,即可继续获得scylla的安装repo。
curl -o /etc/yum.repos.d/scylla.repo -L
http://repositories.scylladb.com/scylla/repo/f8bb7a46e42927231ac3445eb3d7fba4/centos/scylladb-2.1.repo
3、开始安装scylladb
yum install scylla -y
4、启动scylladb配置,按照提示一步一步回答yes or no
scylla_setup
[root@server scylla]# scylla_setup
Skip any of the following steps by answering 'no'
Do you want to run kernel version check?
Answer yes to have this script verify that the currently installed kernel is qualified to run Scylla;
answer no to skip this check.
[YES/no]yes
This is a supported kernel version.
Do you want to verify ScyllaDB packages installed?
Answer yes to have this script check that ScyllaDB is already installed; answer no to skip this check.
[YES/no]yes
Do you want to enable ScyllaDB services?
Answer yes to automatically start Scylla when the node boots; answer no to skip this step.
[YES/no]no
Do you want to setup NTP?
Answer yes to enable time synchronization at boot time. This keeps time right on the node. Answer no to
do nothing.
[YES/no]no
Do you want to setup RAID and XFS?
It is recommended to use RAID0 and XFS for Scylla data. If you select yes, you will be prompt to choose which
unmounted disks to use for Scylla data. Selected disks will be formatted in the process.
[YES/no]yes
Are you sure you want to setup RAID and XFS?
If you choose Yes, selected drive will be reformated, erasing existing data in the process.
[YES/no]no
Do you want to setup coredump?
Answer yes to enable core dumps; this allows to do post-mortem analysis of Scylla state after a crash. Answer
no to do nothing.
[YES/no]yes
kernel.core_pattern = |/usr/lib/systemd/systemd-coredump %p %u %g %s %t %e
Do you want to setup sysconfig?
Answer yes to do system wide configuration customized for Scylla. Answer no to do nothing.
[YES/no]yes
Please select NIC from following list:
docker0 eno1 veth2c42a5a veth86bc926
> eno1
Do you want to optimize NIC queue settings?
Answer yes to enable network card optimization and improve performance. Answer no to skip this optimization.
[YES/no]yes
Setting parameters on /etc/sysconfig/scylla-server
Do you want to setup IO configuration?
Answer yes to let iotune study what are your disks IO profile and adapt Scylla to it. Answer no to skip
this action.
[YES/no]yes
Generating evaluation file sized 10GB...10GB written in 134 seconds
Refining search for maximum. So far, 288 IOPS
Maximum throughput: 288 IOPS
Recommended --max-io-requests: 51
Written the above values to /etc/scylla.d/io.conf
Do you want to install node exporter and export Prometheus data from the node?
Answer yes to install it; answer no to skip this installation.
[YES/no] % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 628 0 628 0 0 847 0 --:--:-- --:--:-- --:--:-- 847
100 3925k 100 3925k 0 0 325k 0 0:00:12 0:00:12 --:--:-- 788k
node_exporter-0.14.0.linux-amd64/
node_exporter-0.14.0.linux-amd64/LICENSE
node_exporter-0.14.0.linux-amd64/NOTICE
node_exporter-0.14.0.linux-amd64/node_exporter
Created symlink from /etc/systemd/system/multi-user.target.wants/node-exporter.service to
/usr/lib/systemd/system/node-exporter.service.
node_exporter successfully installed
Do you want to setup CPU scaling governor?
Answer yes to set CPU scaling governor to performance at boot time. Answer no to do nothing.
[YES/no]yes
This computer doesn't supported CPU scaling configuration.
Do you want to enable fstrim service?
Answer yes to run fstrim on your SSD. Answer no to do nothing.
[YES/no]yes
ScyllaDB setup finished.
5、配置成功,即可启动scylla服务。
systemctl start scylla-server
6、启动cqlsh,进入命令行界面,就是前面刚开始给大家展示的界面。
先创建一个keyspace,这里keyspace就好比mysql的数据库名。后面创建表就是在keyspace中创建。
create keyspace domestic with replication = {'class':'SimpleStrategy','replication_factor':2}
class是副本策略,replication_factor是副本数。
注意,这里'class','replication_factor'均是使用的单引号,如果不小心写成了双引号,会报错no viable alternative at input ':'。

可以通过desc命令查看keyspace,table。desc keyspaces 和 desc tables
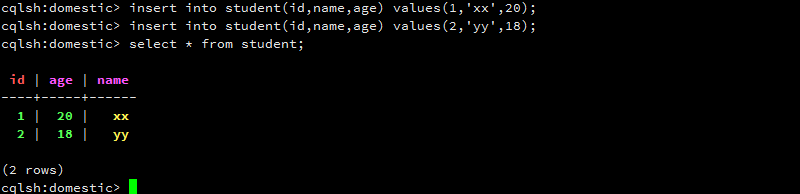
向表中插入数据,并查询。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)