0 总结
总结
- 深度很重要。主要contribution在于对网络depth作用的全面evaluation。使用堆叠3x3小卷积,depth达到16-19。
- 用全卷积之后求和,而不是crop(OverFeat)进行测试。注意multi crop测试数据略好。
- multi scale jittering能带来明显提升。
- 只需要传统的CNN架构,不需要很宽,但很深,可以取得SOTA效果。
- VGG的可以拓展到很多任务,经典backbone。
其他博客
1 Intro
–
2 ConvNet Config
参考了Ciresan & Alexnet.
2.1 Architecture
说明
- 预处理减去训练集RGB均值
- 只用最小的3x3卷积
- 也用到了1x1卷积,只是进行线性变换+非线性激活
- stride固定为1
- padding设置成使输入输出尺寸一致(3x3的,padding1)
- max pooling,s=2, z=2
- 比较不同卷积层数
- 最后3层FC,在不同网络下都一样
- 每个hidden layer都接了ReLU
- 没有用到LRN (Local Response Normalization),在这里说没有用

2.2 Configuration
配置了A-E不同深度网络,深度从11到19。
卷积层的宽度 (通道数目或者kernel数目) 都很小,每次max pooling之后放大一倍,直到最后512。
在这种配置下,没有用很大的卷积核、也没有用很多的卷积核,参数少,但可以获得很深的网络。
VGG16是138M,VGG19是144M。
2.3 Discussion
相比其他网络的第一级Conv的receptive field都比较大,比如Alexnet的11x11,这里使用3x3网络但stride=1的方式。
2层3x3卷积的堆叠,其中不带pooling操作,receptive field等效于5x5。而3层等效于7x7。这种堆叠的区别:
- 在多层中间,通过ReLU加入了多次非线性rectification操作。
- 相比7x7卷积的
7
2
C
2
=
49
C
2
7^2 C^2=49C^2
72C2=49C2参数,3层3x3卷积只有
3
(
3
2
C
2
)
=
27
C
2
3(3^2 C^2) = 27C^2
3(32C2)=27C2参数。可以看成是对一个7x7的卷积进行了regularization,使其分散到多个3x3卷积上。
3 Classifcation Framework
分类用ConvNet的training和evaluation
3.1 Traning
训练参数
- batch size 256
- momentum 0.9
- weight decay
L
2
L_2
L2 penalty
5
⋅
1
0
−
4
5 \cdot 10^{-4}
5⋅10−4
- dropout for 前两个FC
- learning rate 初始0.01,并在validation error不降低时除10。总共降低了3次
- 训练了370K循环,74 epoch
- 相比AlexNet,需要更少epochs,因为
- a) implicit regularization by更多depth和更小卷积
- b) pre-initialization 某些层
Initialization
- 先训练11层的配置A,用它的前4层Conv和后3层FC来初始化其他网络。防止stall和梯度的不稳定。
- 其他层随机初始化,0均值0.01方差的Gaussian
- biases初始化为0
- 其实可以用Bengio2010的方式进行随机初始化,不一定需要用配置A
输入数据预处理
- 图片rescale后随机crop除224x224
- 和Alexnet一样进行水平翻转和RGB PCA shift
- Rescale方式,可以是固定256/384或者随机[256,512]。固定方式下,先pre-train 256的,初始化384的。对于随机multi-scale,用384的初始化。
3.2 Testing
测试数据处理
- Rescale
- FC层转变成Conv. (第一个FC->7x7 Conv,后两个FC -> 1x1 Conv.)
- 不需要crop,全卷积网络处理Rescale图片
- 输出的是一个map,大小取决于输入网络,channel数是类别数,map上每个位置对应某类别-原始图像S尺寸的分数。对这个score map(也是一个image)进行平均,就是这个类别的平均score,再进行softmax。
- 原图和翻转图的softmax后验,进行平均后作为final score。
用FCN相比crop的不同(注意,经过验证,multi crop效果还是更好点)
- 避免每个crop都运算一次,高效
- crop更多,实际上对应更精细地近似全卷积
- 相比crop,全卷积可以用原图信息实现padding,实现更大的receptive field
3.3 Implementation Detail
Caffe,改成支持多GPU。对一个batch,每个GPU处理分出的一部分,对梯度进行平均,因此和单GPU处理结果完全一样。
4 Classification Experiment
ILSVRC-2012数据集,参加ILSVRC-2014比赛。
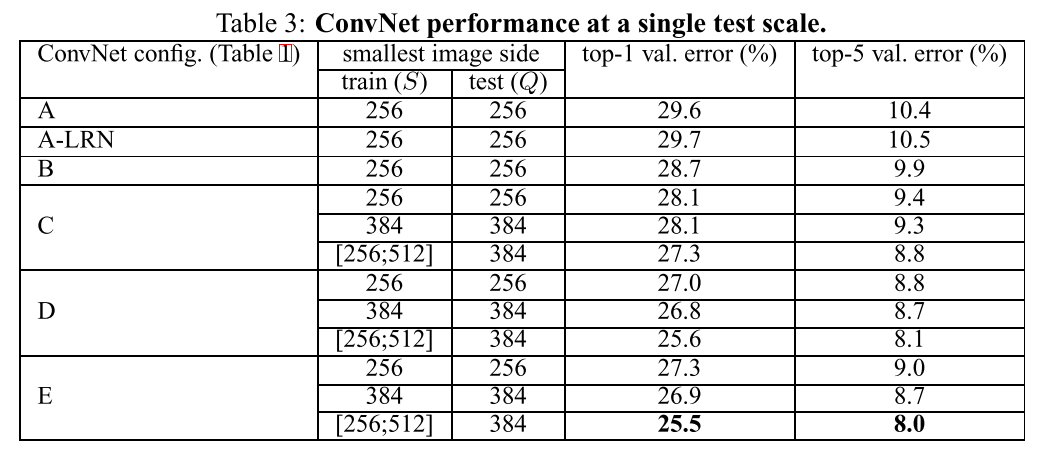
4.1 Single Scale
单scale的testing处理
- LRN对11层网络就没有作用。
- 随着深度增大,错误率下降。
- 用3x3卷积相比单个1x1卷积,有提升。说明receptive field来捕获spatial context是很重要的。
- 一对3x3卷积,相比单个5x5卷积,相同receptive field,但深度更大错误率更低。
- 多scale训练更有效,大约能降低1%的错误率。
4.2 Multi-Scale
多scale的testing处理
证明在测试时,使用scale jittering也有效。VGG16 top-5从8.1%降低到7.5%,而且VGG16和19效果类似。

4.3 Multi-Crop
crop效果更好,并且crop+dense组合的方式最好(说明两者互补)。

4.4 ConvNet Fusion
多个模型ensemble,有更好的效果。
4.5 Comparison
ILSVRC-2014 单网络(无ensemble)SOTA。
5 Conclusion
6 Appendix. A Localization
用OverFeat的思路进行检测。
Backbone是VGG16,最后加一层输出4D vector代表bbox的中心、width、height。
A.1 Localization ConvNet
训练时,把logistic regression(softmax)目标函数,替换为了Euclidean loss。
用single scale,用分类模型训练对应scale的作为初值,最后一层bbox回归的参数随机初始化。尝试了fine tuning所有参数,也尝试了只fine tune最后一个FC层的参数。
测试时,用了两个方式。
- 只对中心crop图计算bbox,并且用GT类别,用来选择最好的网络和参数。
- 对全图计算。不同于class score map,这个的输出是一系列bbox预测结果。然后用OverFeat的方式进行merge。
A.2 Localization Experiment
IOU>0.5认为正确。
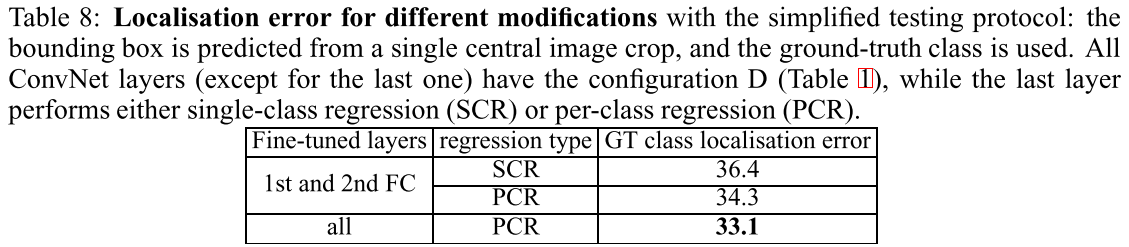
不同配置(使用GT类别)的比较结论:
- PCR (per-class regression) > SCR (single-class regression),和OverFeat不同。
- fine tune所有layer,比只fine tune FC层要明显更好
对于最终网络(PCR, fine tune所有层),使用top-5类别:
- 全图处理后merge,比中心crop的精度更高
- 融合多scale,效果更好
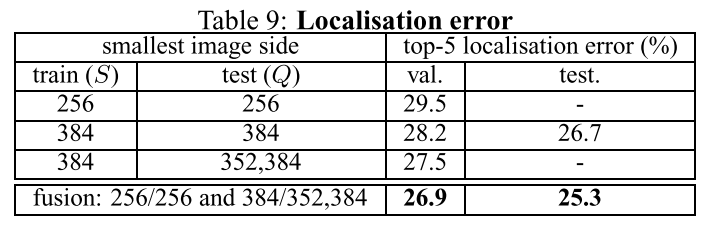
和SOTA(OverFeat)相比,更深的Conv网络,但更简单的localization方式,可以获得更好的效果。说明Deeper网络得到了更好的representation。
Appendix. B Generalization of Feature
使用FC层输出的4096维feature作为descriptor,加SVM在小数据集上进行训练(训练时卷积网络参数不变)。
数据集:Pascal VOC, Caltech
其他应用:detection,segmentation,image caption,texture & material recognition
都有明显提升
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)