前两天 SEBASTIAN RASCHKA 博士发了一篇博客介绍了使用LoRA微调大模型的一些实践经验,个人觉得有一定参考价值。总结一下分享给大家。
喜欢记得收藏、点赞、关注。
文末附上原文,欢迎品读
简单介绍下什么是LoRA
在深度学习领域,特别是在大型语言模型(LLM)领域,模型的大小导致更新模型权重的成本非常高。
假设我们有一个含有70亿参数的LLM,这些参数被表示在一个权重矩阵W中。在训练中,为了最小化损失函数,我们会计算一个ΔW矩阵,里面包含了对原始权重的更新信息。
通常的权重更新过程如下:
如果权重矩阵W包含70亿参数,那么权重更新矩阵ΔW也将包含70亿参数,计算ΔW将消耗巨大的计算和内存资源。
为了解决这一问题,Hu等人提出了LoRA方法,该方法通过分解权重变化ΔW到一个低秩表示。更确切地说,LoRA在训练过程中直接学习ΔW的分解表示,从而节省了内存和计算资源。
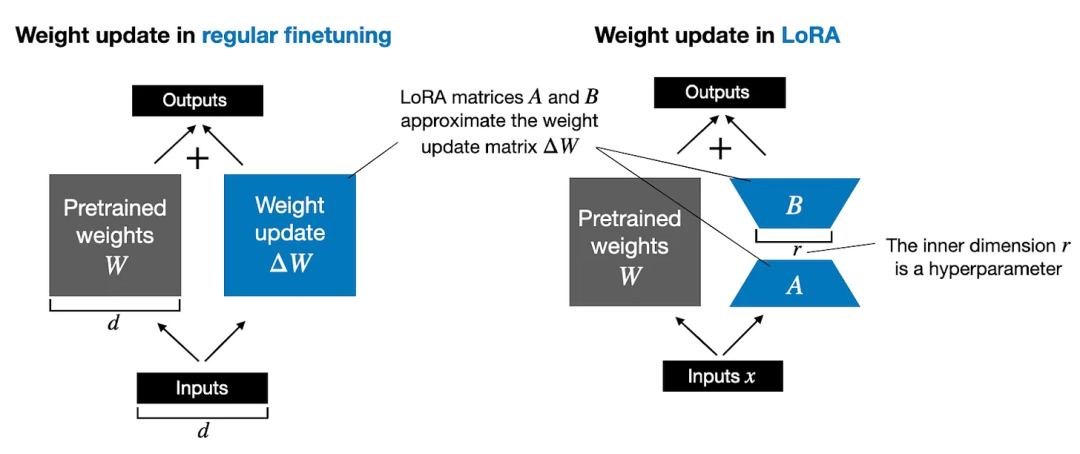
如上所示,ΔW的分解意味着我们用两个较小的LoRA矩阵A和B来表示大矩阵ΔW。如果A的行数与ΔW相同,B的列数与ΔW相同,我们可以将分解写成ΔW = AB。(AB是矩阵A和B的矩阵乘积结果。)
这样做能节省多少内存呢?这取决于超参数r的秩。例如,如果ΔW有10,000行和20,000列,它存储了2亿参数。如果我们选择的A和B的r=8,那么A有10,000行和8列,B有8行和20,000列,那就是10,000×8 + 8×20,000 = 240,000参数,大约比2亿参数少了830倍。
当然,A和B无法捕捉ΔW所能捕捉的所有信息,因此LoRA其实就是牺牲一定性能来降低计算成本。
主要实验结论
LoRA的一致性
:尽管训练模型通常具有随机性,但是多次进行LoRA微调的实验结果在测试集上的效果十分稳定。
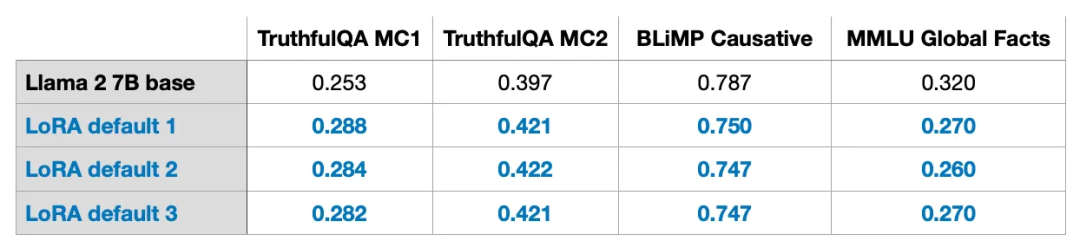
QLoRA的计算与内存权衡
:QLoRA是一种在微调时进一步降低内存使用的技术,通过将预训练的权重量化为4位精度,并使用分页优化器来处理内存峰值。QLoRA可以节省33%的GPU内存,但增加了39%的训练时间。
-
默认的16位浮点LoRA:
-
训练时间:1.85小时
-
内存使用:21.33GB
-
4位浮点QLoRA:
-
训练时间:2.79小时
-
内存使用:14.18GB

学习率调度器
:文章讨论了余弦退火学习率调度器如何调整学习率,模仿余弦曲线逐渐减少学习率以优化收敛并避免过度拟合。实验中引入这种调度器显著改善了SGD性能,但对Adam和AdamW优化器影响较小。
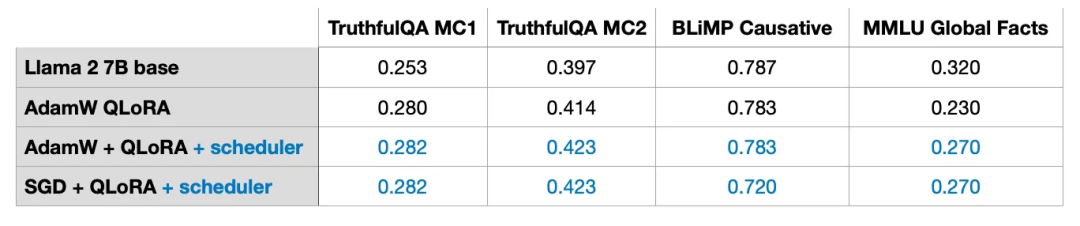
Adam与SGD的比较
:在7B参数的Llama 2模型训练中,使用AdamW和LoRA的默认设置(r=8)需要14.18GB的GPU内存,而使用SGD需要14.15GB的内存,节省非常有限。
多次训练epoch
:对于50k样本的Alpaca指令微调数据集,增加训练迭代次数后,模型性能出现下降,这表明多轮训练可能不适用于指令微调,因为可能会导致过拟合。

为更多层启用LoRA
:实验显示,如果为更多层启用LoRA,虽然内存需求从14.18GB增加到16.62GB,但模型性能有显著提升。

平衡LoRA超参数R和Alpha
:文章讨论了LoRA权重的缩放系数,发现虽然一般来说是较好的选择,但在某些情况下,不同的和组合可能会产生更好的性能。
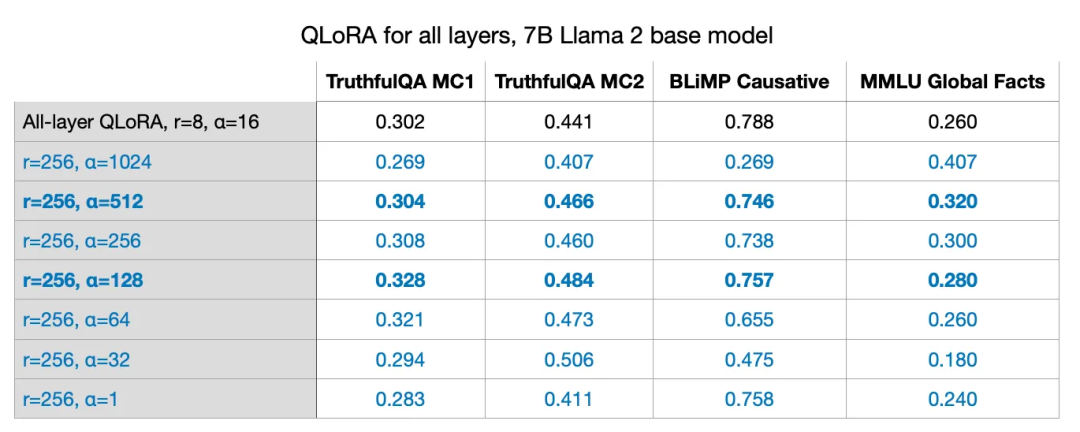
在单GPU上训练7B参数模型
:LoRA技术使得在单个GPU上微调7B参数的模型成为可能。使用QLoRA最优设置(r=256和alpha=512)时,训练一个7B参数模型在A100 GPU上需要大约3小时。

常见问题解答
Q1: 数据集有多重要?
答:数据集对实验至关重要。尽管Alpaca数据集受欢迎,且包含50k的数据,但是只有1k数据的LIMA数据集表现出了更好的性能。
Q2: LoRA是否适用于领域适应?
答:LoRA通常用于引导LLM遵循指令,而不是从预训练数据集中吸收知识。在内存有限时,可以用LoRA对特定领域数据集进行进一步的预训练。
Q3: 如何选择最佳的LoRA的参数r?
答:选择LoRA的参数r是个需要实验的超参数,太大可能导致过拟合,太小可能不足以处理数据集中的任务多样性。
Q4: 是否需要在所有层启用LoRA?
答:目前的研究仅限于在query和key权重矩阵启用LoRA以及在所有层启用。未来的实验可以探索其他层组合的影响。
Q5: 如何避免过拟合?
答:减小r或增加数据集大小可以帮助减少过拟合。还可以尝试增加优化器的权重衰减率或LoRA层的dropout值。
Q6: 其他优化器如何?
答:除了Adam和AdamW,其他优化器如Sophia也值得研究,它使用梯度曲率而非方差进行归一化,可能提高训练效率和模型性能。
Q7: 哪些因素会影响内存使用?
答:内存使用受到模型大小、批量大小、LoRA参数数量以及数据集特性的影响。例如,使用较短的训练序列可以节省内存。
Q8: LoRA与完全微调或RLHF比较如何?
答:虽未进行RLHF实验,但全微调需要更多资源,且可能因过拟合或非理想超参数而性能不佳。
Q9: LoRA权重是否可以合并?
答:可以将多套LoRA权重合并。训练中保持LoRA权重独立,并在前向传播时添加,训练后可以合并权重以简化操作。
Q10: 是否可以逐层调整LoRA的最优rank?
答:理论上,可以为不同层选择不同的LoRA rank,类似于为不同层设定不同学习率,但由于增加了调优复杂性,实际中很少执行。
原文链接
-
https://magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms
技术交流
建了技术交流群!想要进交流群、获取如下原版资料的同学,可以直接加微信号:dkl88194。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、添加微信号:dkl88194,备注:来自CSDN + 技术交流
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
资料1

资料2